为什么通常从错误的方面来处理DDD? 您要哪一边? 长颈鹿和鸭嘴兽与这一切有什么关系?
特别是对于Habr-报告“域驱动设计:实用主义者的食谱”的文字记录。 该报告是在DotNext .NET会议上发布的,但它不仅对捐助者有用,而且对所有对DDD感兴趣的人也很有用(我们相信您将掌握一些C#代码示例)。 还附有报告的录像带。
大家好,我叫Alexey Merson。 我将告诉您什么是域驱动设计,其实质是什么,但是首先,让我们弄清楚为什么需要它。

马丁·福勒(Martin Fowler)说:“很少有事情比业务逻辑更不合逻辑。” 长颈鹿绝对是少数几只。 大脑和长颈鹿的喉头之间的距离只有几厘米。 但是,连接它们的神经达到4米。 首先,他穿过整个颈部,然后绕过动脉,然后几乎以相同的方式向后退。
乍一看,确实没有逻辑。 但这仅仅是古老鱼类留下的丰富遗产。 如您所知,在鱼类中没有脖子,因此该神经沿着最佳路径运行。 经过数百万年的重构,当哺乳动物出现时,必须延长神经以保持向后兼容性。 好吧,不要因为长颈鹿而重塑?
但是长颈鹿还可以,因为那里有鸭嘴兽。

想一想。 哺乳动物 带喙。 主要生活在水中。 下蛋。 而且,有毒。 似乎唯一合理的解释是他来自澳大利亚。
但是我认为一切都比较平淡。 承包商只是忘记了设计,而是用StackOverflow保存了,好了,还是那时候的东西。

我知道您现在在想什么:“ Alexey,好吧,您向我们承诺了域驱动设计,这就是某种“在动物世界中”!
同事,什么是发展? 开发是指我们将现实世界的某个部分,业务流程转化为代码,即构建软件模型。 一路上有什么问题等待着我们?
首先是业务流程本身的复杂性,也就是说,难以理解业务的运作方式,那里正在发生什么流程,通过什么逻辑构建。
第二个问题是以代码形式实现这些业务流程,使用正确的模式,正确的方法等等。 这也是一个相当复杂的话题。
看起来,业务流程就像长颈鹿一样:它们始于最简单的单细胞流程,然后“它”看着您,却没人能理解“它来自哪里”或“它是如何工作的”。
要建立这种过程的成功模型,您必须首先回答“为什么?”问题。 我们为什么要建立这个模型? 我们要实现什么目标? 毕竟,如果客户想要一头长颈鹿毛绒玩具,但是胆量大了,那他就会很沮丧,即使在这种模型中实现消化的目的是为了赏心悦目。 客户不仅会浪费金钱和时间,还会失去对我们作为开发人员的信心,我们也会失去我们的声誉和客户。
但是,即使我们确定了目标,也仍然不能保证不会因此而导致鸭嘴兽。 事实是目标很少了解。 必须实现目标。 这有助于我们进行领域驱动设计。

域驱动设计的主要目标是消除业务流程的复杂性及其在代码中的自动化和实现。 “域”翻译为“域”,并且在此方法框架内的开发和设计被推离域。
域驱动设计包括很多东西。 这项战略规划,人与人之间的互动,建筑方法和战术模式-这是一个真正有效的武器库,确实有助于制定项目。 只有一个“但是”。 在开始使用域驱动设计解决复杂性之前,您需要学习如何处理域驱动设计本身的复杂性。

当一个人开始研究这个话题时,他身上就会得到大量的信息:厚书,一堆文章,图案,例子。 所有这些都令人困惑,而且,正如他们所说,很容易不注意到森林树木的背后。 我曾经对自己有这种感觉,但是今天我想与您分享我的经验,并帮助您渡过这个丛林,最终开始使用域驱动设计。

领域驱动设计本身是Eric Evans于2003年在其不可发音的书中提出的,该书在社区中被简单称为蓝皮书。 问题在于,埃文斯(Evans)这本书的前半部分谈到了战术模式(大家都知道:战术是工厂,实体,存储库,服务),而人们通常不了解后半部分。 这个男人看上去:一切都很熟悉,我去获取DDD应用程序。

右边是如果您在编译器上疯狂地投掷战术模式会发生什么。 左-如果您使用战略模式。

自《蓝皮书》发行以来,已经形成了一个相当强大的DDD社区,许多事情都经过了重新思考。 是的,埃文斯本人也承认他不再理解如何结束战略设计这样重要的事情。
10年后的2013年,《红皮书》由沃恩·弗农(Vaughn Vernon)出版。 在本书中,演示文稿已经按照正确的顺序构建:它从战略设计和基础开始。 并且当读者获得必要的基础时,他们已经开始谈论战术模式和实施细节。
通常,在DDD上的报告中,他们建议阅读Evans,在Internet上甚至有整本手册,在这些手册中,您需要阅读各章以正确沉浸。 我建议您更轻松:先从红皮书开始阅读,然后再转到蓝皮书。
由于战略设计是如此重要,因此让我们谈谈其关键思想。
“战略设计的关键思想”
在任何业务自动化项目中,总会有领域专家。 这些人最了解要建模的业务流程如何工作。 这些可以是领先的开发人员,主管,高层管理人员。 一般而言,只要他了解我们需要处理的业务流程,任何人都可以。
另一方面,有技术专家:直接参与应用程序自动化和实现的开发人员,架构师。 在所示的示例中,客户可能想要一条儿童铁路,但事实证明这是一种怪物。
为什么会这样呢? 因为在典型情况下技术专家和领域专家之间的交互看起来像这样:他们之间有一堵大墙,而一位经理沿着这堵墙的顶部行走,首先尝试听到他们在墙的一侧大喊大叫,然后他试图将其喊叫到最大程度的韧带在墙壁的另一侧,依此类推。
有时经理失聪,那么可以建立起这样的经理的整个链条,这当然对项目的成功没有帮助。 怎么会呢?
必须保持不断的互动。 技术专家,领域专家-所有项目参与者都必须不断保持沟通,同步,讨论目标,实现目标的方式以及我们为什么要做所有这一切。
总体而言,在这里,我们谈到了战略设计和领域驱动设计的第一个,而且可能是最重要的关键点。

项目参与者之间的交流形成了领域驱动设计所称的普遍语言。 在所有场合他都是一体的意义上,他不是一个。 相反。 从所有参与者进行交流的意义上讲,这是单一的,所有讨论都以一种语言进行,所有工件都应以一种语言最大程度地进行,也就是说,从传统知识开始,以代码结尾。
业务场景
为了进一步讨论,我们需要某种业务场景。 让我们想象一下这种情况:

JUG.ru集团的负责人来找我们说:“伙计们,报告的流量在增长,总的来说,人们受到折磨的是手工做的每一件事……让会议的准备过程自动化。” 我们回答:“好吧!” -上班。
我们将自动化的第一种情况是:“演讲者在特定事件上提交报告申请,并添加有关其报告的信息。” 在这种情况下,我们看到了什么? 什么是发言人,有一个事件,有一份报告,这意味着已经可以构建第一个领域模型。

在这里,我们有一个域模型:发言人-发言人,对话-报告,事件-事件。 但是领域模型不能是无限的,不能涵盖所有内容,否则它将变得模糊并失去焦点,因此领域模型必须受到某些限制。 这是下一个关键点。

域模型和无处不在的语言都受域驱动设计称为有界上下文的上下文的限制。 他以这样一种方式来限制领域模型,即其中的所有概念都是明确的,并且每个人都知道危险所在。
如果他们说“用户”,那么所有内容都应该立即变得清晰,它应该具有可理解的作用,可理解的含义,从IT行业的角度来看,它不应是某种抽象的用户。
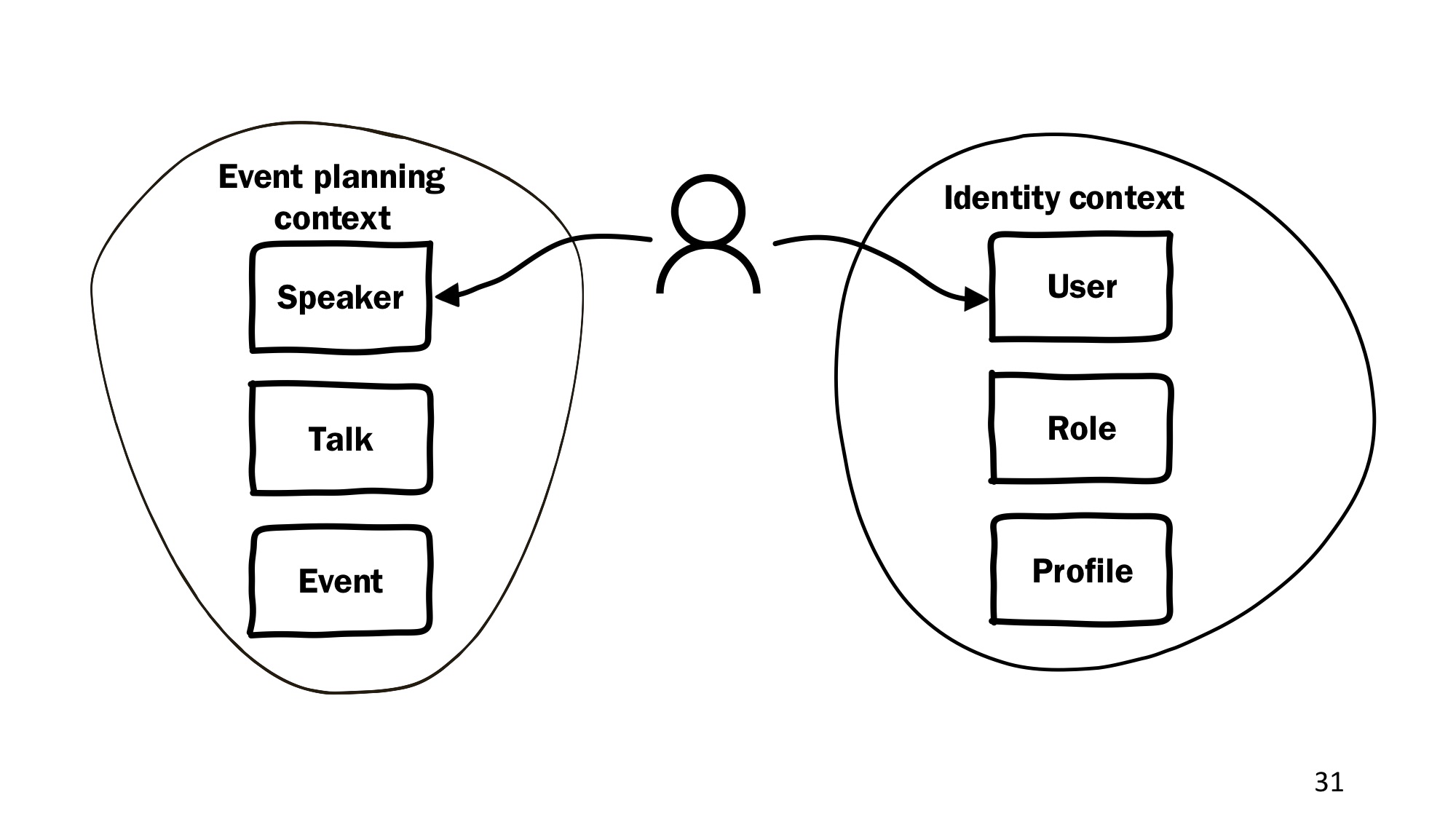
在我们的案例中,此域模型对于会议的准备工作有效,因此在这种情况下,我们将其称为“事件计划上下文”。 但是,要使发言人添加一些内容,更改信息,他必须以某种方式登录,并且需要授予他一些权利。 这已经是另一个上下文,“身份上下文”,其中将存在一些自己的实体:用户,角色,配置文件。
看看这里是什么。 当某人登录到系统并打算输入某种信息时,实际上这是同一个人,但是在不同的上下文中,他由不同的实体表示,并且这些实体没有直接关联。
例如,如果我们从User那里继承并继承了Speaker,那么我们将混合无法混合的内容,并且某些属性可能会被逻辑混合。 该模型将失去对特定含义的关注,将其分为多个上下文。
演示:销售服务
让我们从枯燥的理论中走一点,看看代码。
会议不仅是内容的准备,而且还是销售。 假设已经编写了一项售票服务,并且一位销售经理来到我们面前说:“伙计! 一旦有人写了这项服务,让我们弄清楚,对我而言,如何考虑普通客户的折扣尚不清楚。”
与经理交谈后,我们发现此服务的整个方案是这样的:通过单击“签出”,最终的机票价格将考虑到常规的客户折扣,并且订单进入“等待付款”状态。
我们现在将分析的代码可以在
存储库中单独查看。
打开解决方案,看一下结构:
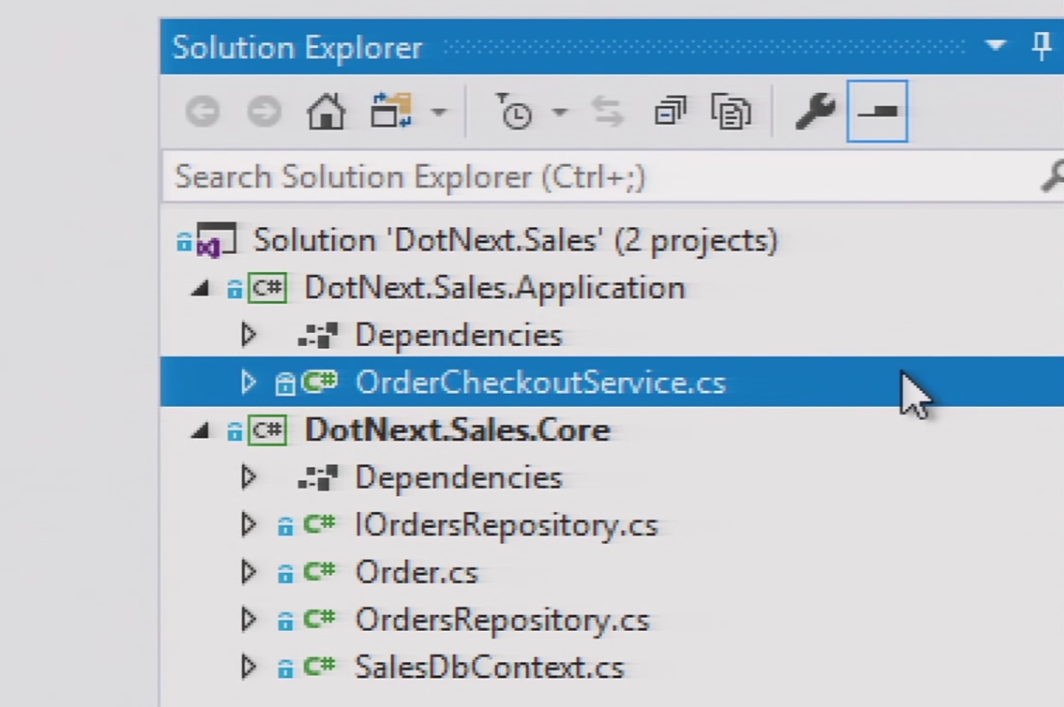
看起来一切看起来都不错:这里有应用程序和核心(显然,人们都知道层),存储库……显然,这个人掌握了Evans的上半部分。
打开OrderCheckoutService。 我们在那里看到什么? 这
是代码 :
public void Checkout(long id) { var ord = _ordersRepository.GetOrder(id); var orders = _ordersRepository.GetOrders() .Count(o => o.CustomerId == ord.CustomerId && o.StateId == 3 && o.OrderDate >= DateTime.UtcNow.AddYears(-3)); ord.Price *= (100 - (orders >= 5 ? 30m : orders >= 3 ? 20m : orders >= 1 ? 10m : 0)) / 100; ord.StateId = 1; _ordersRepository.SaveOrder(ord); }
我们看一下价格:这是价格变化。 我们打电话给销售经理,说:“总之,这里考虑了折扣,一切都清楚了”:
ord.Price *= (100 - (orders >= 5 ? 30m : orders >= 3 ? 20m : orders >= 1 ? 10m : 0)) / 100;
他看着他的肩膀:“哦! 这就是Brainfuck的样子! 他们告诉我,这些家伙正在用C#编写代码。
显然,此代码的开发人员对有关算法和数据结构的采访反应良好。 我在学校奥林匹克运动会上以大约相同的风格写作。 一段时间后,我们使用格式和
淫秽重构,弄清了什么,并向饱受苦难的销售经理解释了这样的逻辑:如果过去三年中的订单数量不少于一年,那么他将获得10%的折扣,不少于3-20%,且不少于5-30%。 他快乐地离开-现在很清楚一切如何运作。
我认为许多人已经阅读了鲍勃·马丁的《清洁法》。 他在那儿谈到了童子军的规则:“离开后的停车场应该比到达那儿之前的停车场更干净。” 因此,让我们对该代码进行重构,使其看起来很人性化,并且与我们之前讨论的有关泛在语言及其在代码中的用法相对应。
这是重构的代码。
public class DiscountCalculator { private readonly IOrdersRepository _ordersRepository; public DiscountCalculator(IOrdersRepository ordersRepository) { _ordersRepository = ordersRepository; } public decimal CalculateDiscountBy(long customerId) { var completedOrdersCount = _ordersRepository.GetLast3YearsCompletedOrdersCountFor(customerId); return DiscountBy(completedOrdersCount); } private decimal DiscountBy(int completedOrdersCount) { if (completedOrdersCount >= 5) return 30; if (completedOrdersCount >= 3) return 20; if (completedOrdersCount >= 1) return 10; return 0; } }
我们要做的第一件事是将折扣计算转移到一个单独的DiscountCalculator,其中将出现CalculateDiscountBy customerId方法。 一切都是人为读取的,一切都很清楚:什么,为什么以及如何。 在此方法内部,我们看到我们在全局上有两个步骤来计算折扣。 首先:我们从订单存储库中获取一些东西,一切都取决于用户情况,如果这不是您现在感兴趣的部分,您甚至不必进入内部。 事实是,我们获得了一些已完成订单的数量,此后,我们立即将此数量的第二次折扣视为第二步。
如果我们想看看它是如何考虑的,请转到DiscountBy,在这里几乎用与人类的“脑干型”以前的人类英语相同的东西来书写,所有内容都是清晰准确的。
唯一可能出现的问题是折价的计量单位。 为了清楚起见,可以在方法名称中添加单词“ percent”,但是从上下文和所涉及的数字来看,很可能会猜测这些是百分比,为简洁起见,可以将其省略。 如果我们想查看那里的订单数量,那么我们将转到存储库代码并查看。 现在我们不会这样做。 在我们的服务中,我们需要添加一个新的DiscountCalculator依赖项。 让我们看看在第二版Checkout方法中得到的结果。
public void CheckoutV2(long orderId) { var order = _ordersRepository.GetOrder(orderId); var discount = _discountCalculator.CalculateDiscountBy(order.CustomerId); order.ApplyDiscount(discount); order.State = OrderState.AwaitingPayment; _ordersRepository.SaveOrder(order); }
看,Checkout方法接收orderId,然后接收一个orderId的orderId,根据该订单的CustomerId,它使用折扣计算器考虑折扣,将折扣应用于该订单,将状态设置为AwaitingPayment并保存该订单。 我们在幻灯片上有一个俄语脚本,但是在这里,我们实际上是将此脚本翻译成英语,一切都很清楚,一切都很明显。
你看到了什么魅力吗? 可以向所有人显示此代码:不仅是程序员,而且是质量检查人员,分析师和客户。 他们都将了解发生了什么,因为所有内容都是用人类语言编写的。 我在我们的项目中使用了它,真正的质量检查人员可以研究一些内容,与Wiki核对并了解其中存在某种错误。 因为Wiki是这样说的,并且代码有些不同,但是尽管他不是开发人员,但他了解那里发生了什么。 同样,我们可以与分析师讨论代码,并进行详细讨论。 我说:“瞧,这就是它在代码中的工作方式。” 我们的最后选择不是Wiki,而是代码。 一切正常,如代码中所写。 编写代码时使用普适语言非常重要。

这是第三个关键点。
域驱动设计在诸如域,子域,有界上下文,它们与它们的含义之间的关系等方面存在太多混乱。 似乎每个人都在限制某些东西,所有人都以某种方式保持整洁。 但是,目前还不清楚有什么区别,为什么发明了如此不同的东西。

领域是全球性的事物,它是全球特定业务在其中赚钱的领域。 例如,对于DotNext,这是一次会议,对于Pyaterochka,这是商品的零售。
大公司可能有多个领域。 例如,亚马逊既通过互联网从事商品销售,又提供云服务,这是不同的主题领域。
然而,这是全局的,甚至无法进行调查也无法直接自动化。 为了进行分析,将域不可避免地分为子域,即子域。

用我们的语言,子域是业务的一部分,它们之间是高度关联的,也就是说,它们是某种孤立的逻辑流程,它们在某个主要级别上相互交互。
例如,如果我们在网上商店,它将是订单的形成和处理,它将是交货,这是与供应商合作,这是市场营销,这是会计。 以下是其中一些片段-这就是业务划分的内容。

从DDD的角度来看,子域分为三种类型。 在这里我想说一件事:通常在书籍和文章中,Subdomain只是简化为Domain,但通常是与Subdomain类型结合使用的情况。 也就是说,当他们说“核心域”时,它们的意思是核心子域,请不要对此感到困惑。 起初我大吃一惊。
子域分为三种类型。
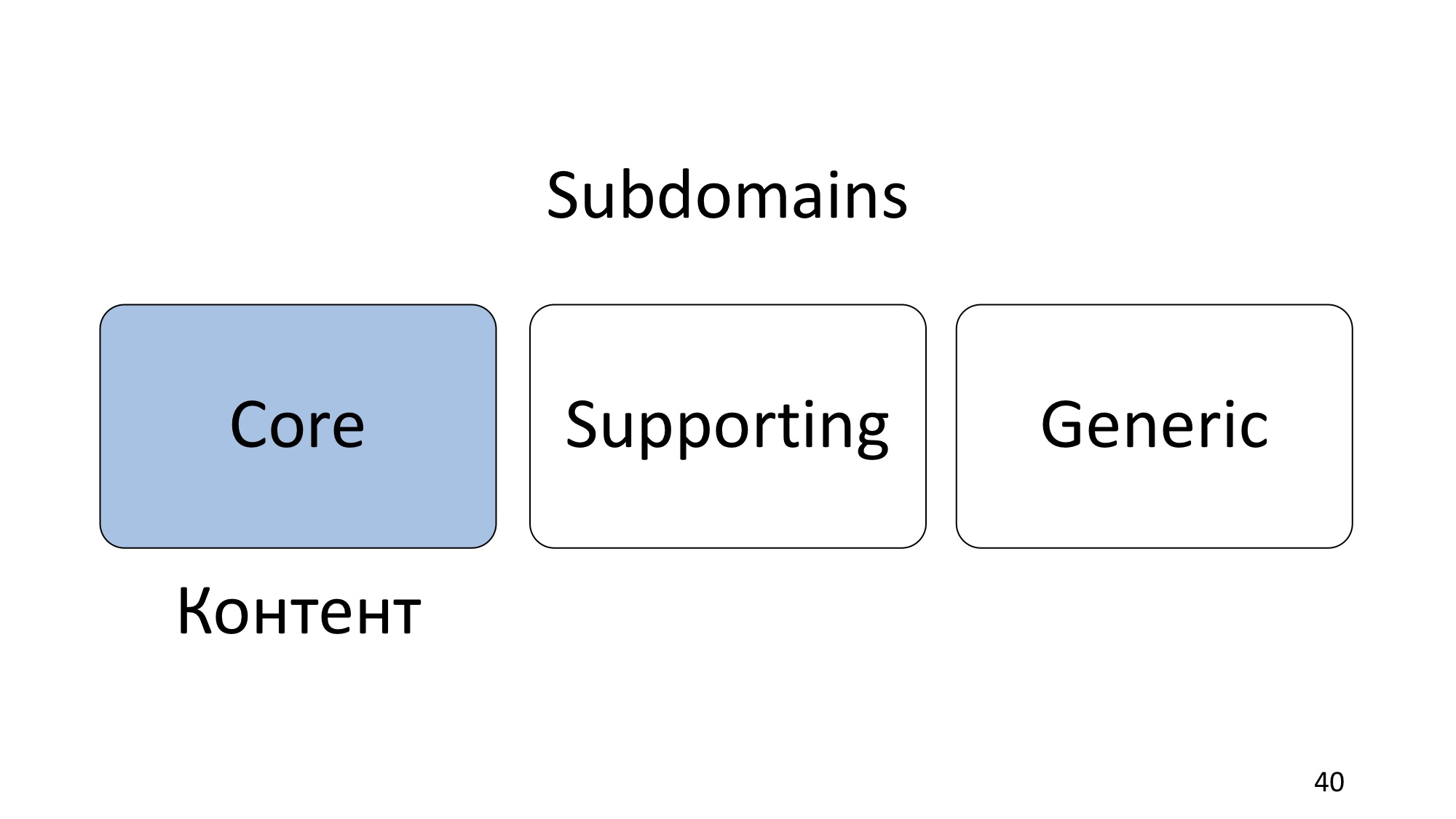
第一个也是最重要的是Core。 核心是主要的子域,这是公司的竞争优势,使公司赚钱的原因,与竞争对手的不同之处,专有技术,无论您如何称呼它。 如果我们参加DotNext会议,那么这就是内容。 大家都是来这里找内容的,如果这里没有这些内容,就不会去或参加另一个会议。 它所采用的形式不会有DotNext。

第二种类型是支持子域。 这对于赚钱也是重要的,没有它也是不可能的,但这不是某种专有技术,一种真正的竞争优势。 这就是Core Subdomain支持的内容。 从应用域驱动设计的角度来看,这意味着在支持子域上花费的精力更少,所有主要力量都投在了Core上。
相同的DotNext的一个示例是营销。 没有营销,这是不可能的,否则没人会知道会议,但是没有内容营销是不需要的。
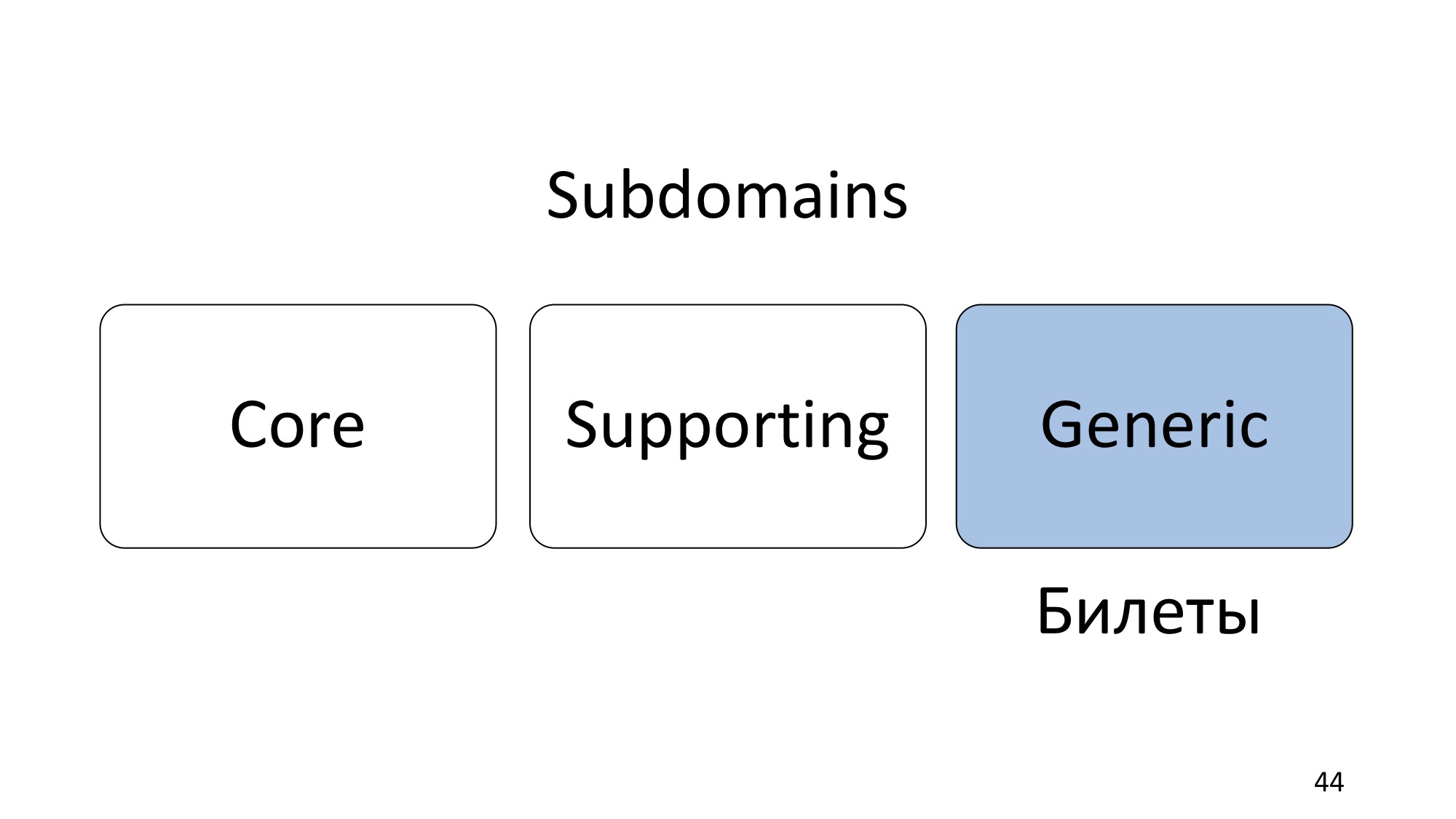
最后是通用子域。 通用是一些典型的业务任务,通常可以将其与成品自动化或外包。 这也是需要的,但是并不一定要求我们独立实施,甚至更重要的是,使用第三方产品通常是个好主意。
例如,卖票。 DotNext通过TimePad销售门票。 该子域由TimePad完全自动化,您无需自己编写第二个TimePad。
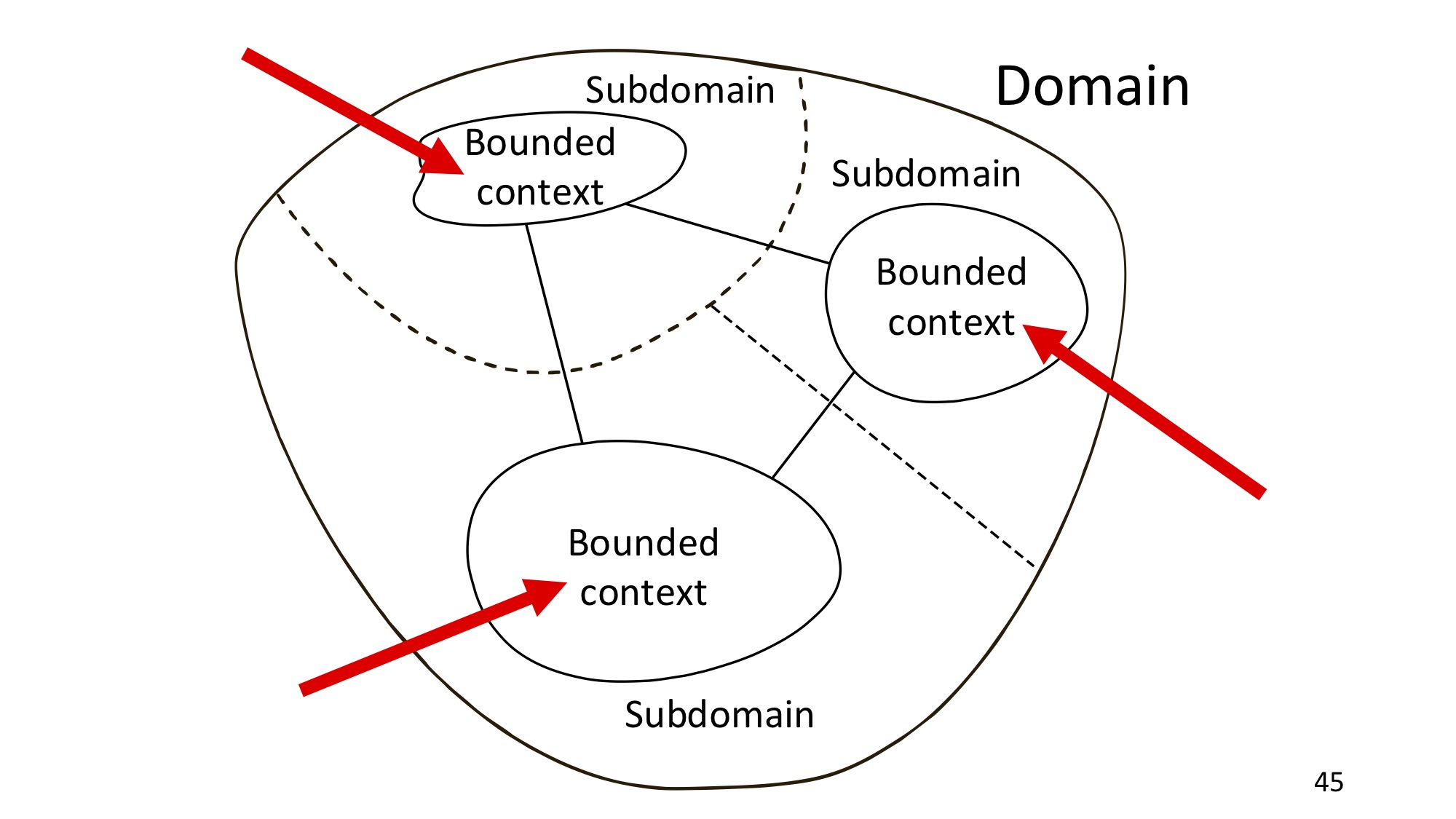
最后,有限的上下文。 有界上下文和子域始终在附近,但是它们之间存在显着差异。 这很重要。
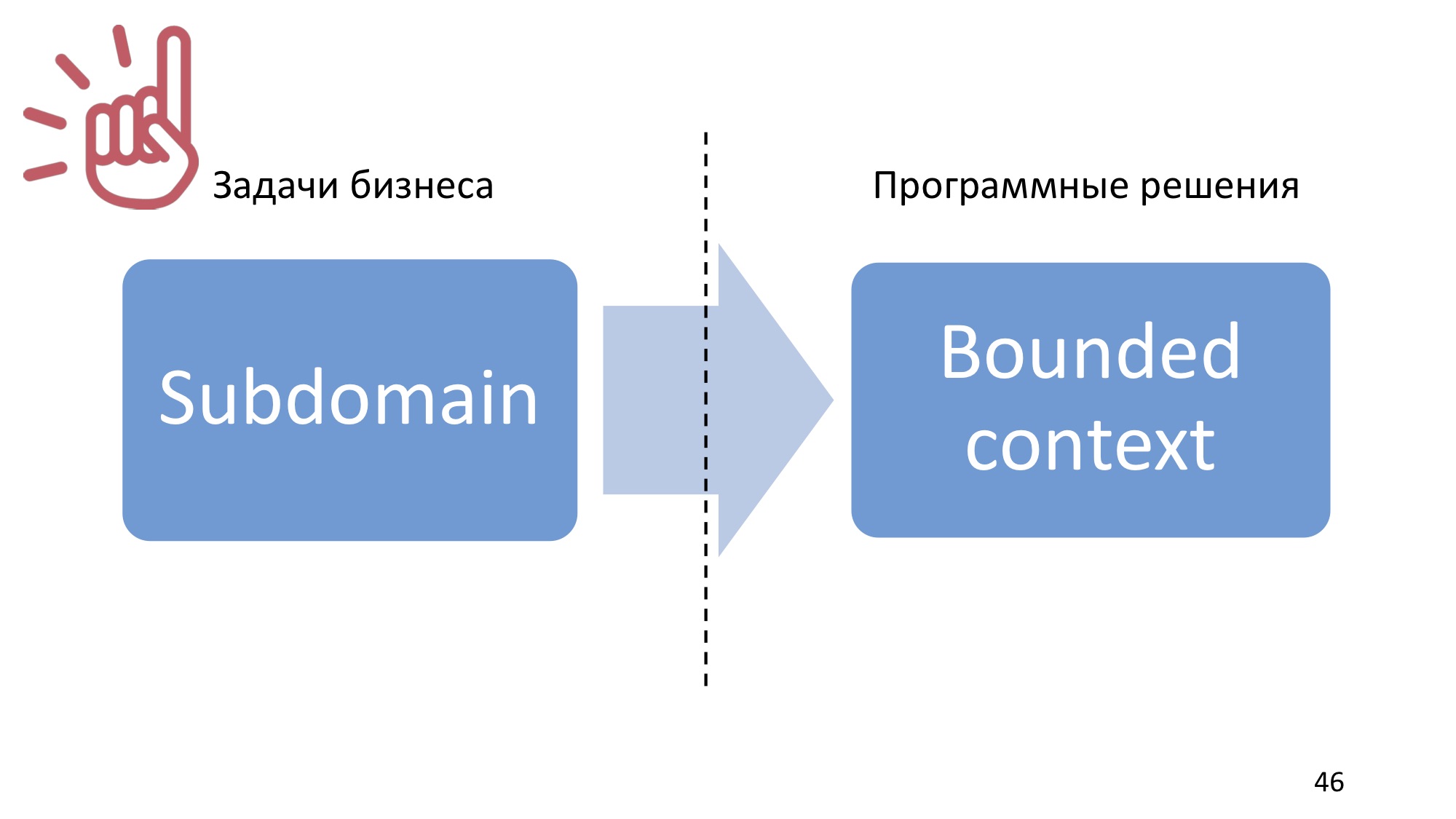
关于StackExchange,有一个问题是有界上下文与子域有何不同。 子域是业务的一部分,是现实世界的一部分,它是问题陈述空间的概念。 有界上下文限制了领域模型和普遍使用的语言,即建模的结果,因此,有界上下文是解决方案空间的概念。 在项目实施过程中,子域的一种映射发生在有限的上下文中。

一个经典的例子:作为子域的簿记,流程的映射方式是自动化的,例如1C簿记,Elba或“我的生意”-某种产品是某种程度上是自动化的。 这是会计界,它有无处不在的语言和自己的术语。 那是他们之间的区别。

如果我们返回DotNext,则正如我所说,票证将映射到TimePad,而作为核心子域的内容将映射到我们为内容管理而开发的自定义应用程序。
有界上下文大小
有片刻引发了很多问题。 如何为有界上下文选择合适的大小? 在书中,可以找到这样的定义:“有限的上下文必须恰好使普遍存在的语言完整,一致,明确,一致。” 很酷的定义,就像一个著名笑话中的数学家一样:非常准确,但是没用。
让我们讨论一下我们如何完全理解:应该是解决方案,项目还是名称空间-应该将哪种比例尺附加到有界上下文?

您几乎可以在任何地方阅读的第一件事:理想情况下,
一个子域应该映射到一个有界上下文 ,即由一个有界上下文自动执行。 这听起来是合乎逻辑的,因为单独的业务流程存在局限性,在某些情况下,在某些业务术语中,都会出现一种语言。 但是在这里您需要了解这是一个理想的情况,您不一定需要这样做,也没有必要尝试实现这一目标。
因为,一方面,子域可能很大,并且可以获得将其自动化的多个应用程序或服务,因此可能会发现多个有界上下文对应于一个子域。
但是通常会有一种相反的情况,这对于传统来说是很典型的。 就是说,当他们制作一个大型的应用程序来自动化该企业的世界上所有事物时,情况就会相反。 一个应用程序是一个有界上下文,该模型很可能是某种模棱两可的,但是子域并没有因此而消失,一个有界上下文将对应于几个子域。
当微服务架构变得流行时,出现了另一项建议(尽管它们并不相互矛盾):
每个微服务一个有界上下文 。 同样,听起来确实合乎逻辑,人们确实做到了。 因为微服务必须承担一些明确的功能,该功能在内部具有较高的连通性,并通过某种交互方式与其他服务进行通信。 如果您使用微服务架构,则可以自己接受此建议。
但这还不是全部。 让我再次提醒您,领域驱动设计涉及很多方面:语言,人员。 而且您不能忽略人们,而只能在此事上做技术准则。 因此,我这样写:
一个上下文等于X-man 。 我以前以为x大约是10,但我们与Igor Labutin(
twitter.com/ilabutin )进行了交谈,问题仍然悬而未决。
在这里重要的是要理解这一点:一种语言保持统一,而所有参与者都在讲话,讨论,而每个人都明确地理解它。 显然,无数人不会说相同的语言。 我们人类的历史清楚地表明了这一点。 无论如何,都会出现一些方言,一些含义,现在您甚至可以添加模因等等。 一种或另一种方式,语言将变得模糊。
因此,必须理解,使用这种单一语言并因此参与自动化开发的人数是有限的。 这些书还讨论了一些政治原因:如果两个团队在不同经理人的领导下工作并在相同的有限范围内工作,并且由于某种原因这些经理人不是彼此的朋友,那么冲突将开始,并且焦点将丢失。 因此,为每个命令创建两个有界上下文而不尝试合并未合并的内容将更加简单,正确。
架构和依赖性管理
从域驱动设计的角度来看,选择哪种架构并不重要。 领域驱动的设计与之无关;领域驱动的设计与语言和交流有关。

但是,从域驱动设计的角度来看,从选择架构的标准出发,还有一个重要的观点:
我们的目标是最大限度地摆脱第三方依赖的业务逻辑 。 因为,一旦出现第三方依赖性,就会出现术语,出现的单词不会输入一种语言,而是开始乱我们的业务逻辑。

让我们看一下经典的架构示例:著名的三层架构。 一旦他们不调用域层(在这里是业务层):业务,核心和域都相同。 无论如何,这是业务逻辑所在的层,如果它依赖于数据层,则意味着来自数据层的某些概念将以某种方式流入域层并将其乱扔。
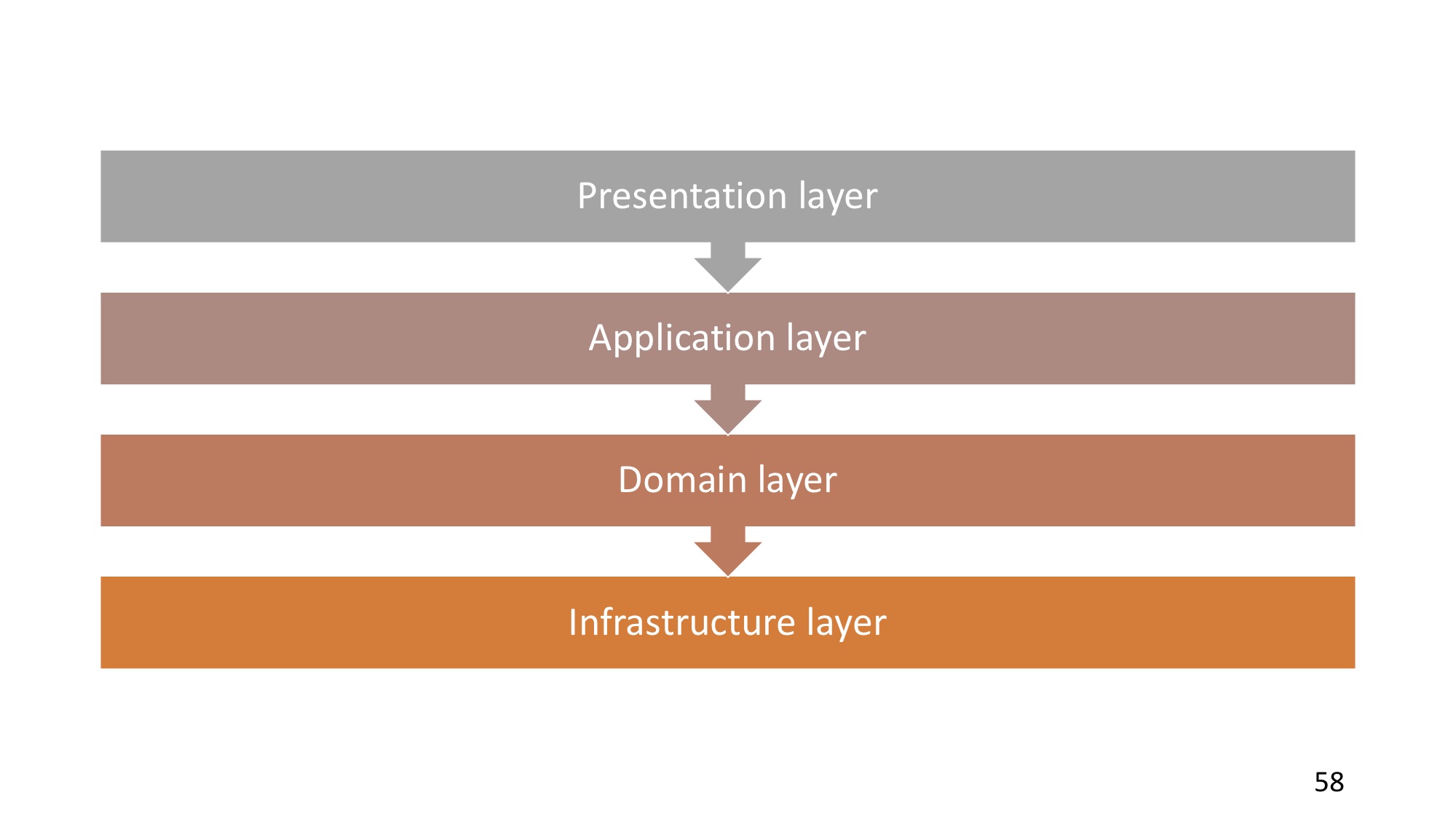
四层体系结构本质上是相同的,但是域层仍然是依赖的,并且由于依赖第三方,因此不必要的依赖关系也会逐渐走向它。

从这个意义上讲,存在可以避免这种情况的体系结构-它是洋葱体系结构(“ onion”)。 它的区别在于它由同心层组成,相关性从外部到中心。 也就是说,外层可以依赖于任何内层,内层不能依赖于外层。
最外层是全局意义上的用户界面(也就是说,它不一定是人类UI,它可以是REST API或其他任何东西)。 而且,通常通常也看起来像I / O的基础结构是同一数据库,实际上是数据层。 所有这些东西都在外层。 也就是说,由于该应用程序以某种方式接收了一些数据,命令等,因此将其取出,并且域层摆脱了对这些事物的依赖。
接下来是Application层-一个相当整体的主题,但这是脚本,用户案例所在的层。 该层使用域层来实现其概念。
中心是域层。 如我们所见,他不再依赖任何东西;他成为了自己的东西。 这就是为什么域层通常被称为“核心”的原因,因为它是核心,而是位于中心的那个,而不依赖第三方的东西。

实施这种洋葱体系结构的一种选择是六边形体系结构,即“端口和适配器”。 我把这张照片吓倒了,我不再赘述。 文章末尾有一个指向该架构的百万篇文章之一的链接,您可以阅读。
有关战术模式的一些知识:分离的界面
正如我所说,首先,大多数战术模式是每个人都熟悉的,其次,我报告的重点是它们不是本质。 但是我分别喜欢分离接口模式,我想分别谈一谈。
让我们回到微服务的代码,看看存储库发生了什么。

域层具有IOrdersRepository.cs
存储库接口及其
实现 OrdersRepository.cs。
using System.Linq; namespace DotNext.Sales.Core { public interface IOrdersRepository { Order GetOrder(long id); void SaveOrder(Order order); IQueryable<Order> GetOrders(); #region V2 int GetLast3YearsCompletedOrdersCountFor(long customerId); #endregion } }
在这里,我们在此处添加了某种用于接收最近三年GetLast3YearsCompletedOrdersCountFor的订单的方法。
他们以某种形式(在这种情况下,是通过Entity Framework实现的)实现的:
public int GetLast3YearsCompletedOrdersCountFor(long customerId) { var threeYearsAgo = DateTime.UtcNow.AddYears(-3); return _dbContext.Orders .Count(o => o.CustomerId == customerId && o.State == OrderState.Completed && o.OrderDate >= threeYearsAgo); }
看看问题出在哪里。 该存储库最终出现在域层中,其实现在域层中,但是以DateTime.UtcNow.AddYears(-3)开头的代码本质上不属于域层,并且不是业务逻辑。 是的,LINQ使它或多或少地变得人性化,但是,例如,如果这里有SQL查询,那么一切都会完全令人难过。
分离接口模式的含义是,我们在域逻辑中使用的服务接口是在域层中声明的。 我们谈论的是存储库和类似服务,其中这些服务的实现细节不是业务逻辑。 业务逻辑是这些服务的存在以及它们在域层中的调用和使用的事实。 因此,存储库接口保留在域层中,并且实现移至基础结构层。
我准备了另一个选择。 存储库接口保留在Core程序集中,但是实现移至Infrastructure.EF。
因此,我们将那些不是领域层特有的概念引入了基础架构。 副作用是,我们可以用其他一些实现来代替此基础架构。 但这不是主要目标,正如我所说的,主要目标是摆脱第三方依赖的领域逻辑。
再次关于语言
让我们一次又一次地谈论这种语言。
从一开始,我们就建立了域模型“扬声器-对话-事件”。 我认为没有人提出任何特殊问题。
这是我们构建此域模型所基于的场景:

看到,脚本是俄语的,而领域模型是英语的。
对于不讲英语的开发人员,这是您必须经常忍受的事情。
你们每个人都很可能会不断地执行此过程:将俄语翻译成英语,反之亦然。 与说英语的客户和项目工作的人要容易一些,因为需求是英语的,与客户进行的讨论通常是英语的,所有场景都是英语的,代码是英语的,并且团队内部只有俄语沟通,而英语沟通很快(客户-客户,订单-订单)。 不断转换产生的认知负荷和开销减少了一点。
, , , . , .
1, . , — , , .

1. PascalCase , , ,
, , , , - - .
, - ?

, use case, , .
, . C#, , , . , , , .
, , Domain-Driven Design. , , , , C# . .
, - Continuous Integration. , , , - - . , - , , . , 95% , , Continuous Integration, , TeamCity . .
, . . , 1-, , . «» , . , , .

, Domain-Driven Design.
— , . Domain-Driven Design — , . — , , ubiquitous language. , , . , , , .
. , . - , , , , , , , , , , — . .
. . . . , , . DSL-. .NET-, - , , , , . , .
, - . , , ubiquitous language -. .
- marshinov . , DDD: , « DDD, CQRS Event Sourcing » . , , .
- , AutoMapper MediatR. , Domain-Driven Design, .
- «F# for fun and profit» , , F# Domain-Driven Design. , , , .
- , , .
, ,
GitHub .
DotNext:
, « , ». DotNext ( 15-16 ) . , 1 , .