又一个周末到来了,这意味着我要编写另外几十行代码并进行一两幅插图。 在先前的文章中,我已经解释了如何进行
光线追踪 ,甚至
炸毁东西 。 这可能会让您感到惊讶,但是计算机图形非常简单:即使几百行裸C ++也会产生一些非常令人兴奋的图像。
今天的话题是双目视觉,我们甚至不会突破100行界限。 由于我们可以绘制3D场景,因此忽略立体声对是愚蠢的,因此今天我们将进行如下操作:
 Magic Carpet的
Magic Carpet的创作者们的疯狂仍然令我震惊。 对于那些不知道的人,该游戏允许您
从主设置菜单以立体图和立体图模式进行3D渲染! 这对我来说太疯狂了。
视差
因此,让我们开始吧。 首先,是什么导致我们的视觉设备感知物体的深度? 有一个聪明的词“视差”。 让我们集中在屏幕上。 屏幕平面内的所有内容都被我们的大脑记录为一个对象。 但是,如果苍蝇在我们的眼睛和屏幕之间飞行,那么大脑就会将其视为两个物体。 屏幕后面的蜘蛛也将加倍。
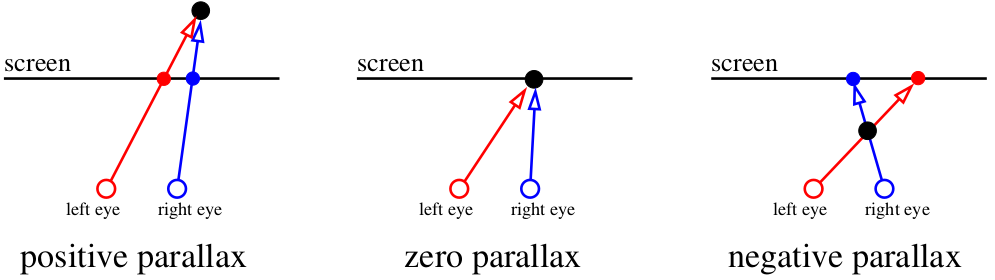
我们的大脑在分析略有不同的图像方面非常有效。 它使用
双眼视差通过
立体视从来自视网膜的2D图像中获取深度信息。 好吧,拧紧大字,让我们只绘制图像!
假设我们的监视器是虚拟世界的窗口:)
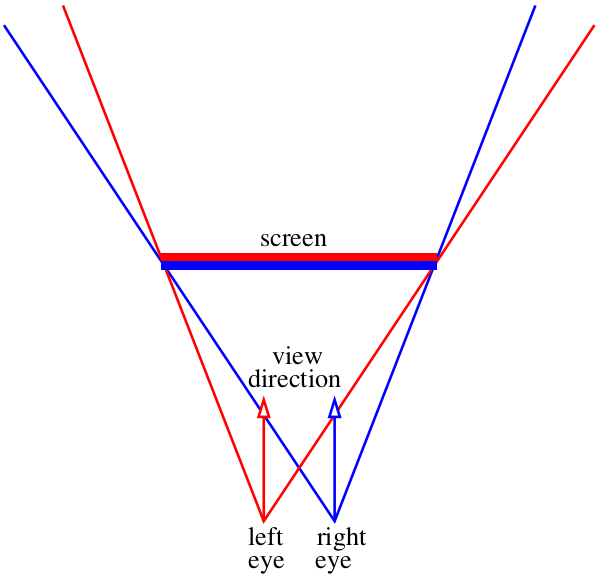
我们的任务是绘制通过“窗口”看到的两幅图像,每只眼睛一张。 在上面的图片中,红蓝色的“三明治”。 现在让我们忘记如何将这些图像传递到我们的大脑,在此阶段,我们只需要保存两个单独的文件。 特别是,我想知道如何使用
我的微型raytracer获得这些图像。
假设角度不变,并且是(0,0,-1)向量。 假设我们可以将相机移动到眼睛之间的区域,那又如何呢? 一个小细节:通过我们的“窗口”
看到的视锥是不对称的。 但是我们的光线跟踪器只能渲染对称的视锥:
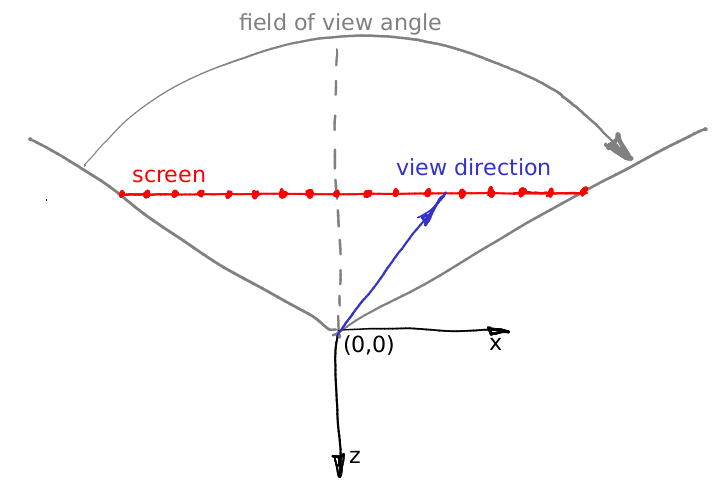
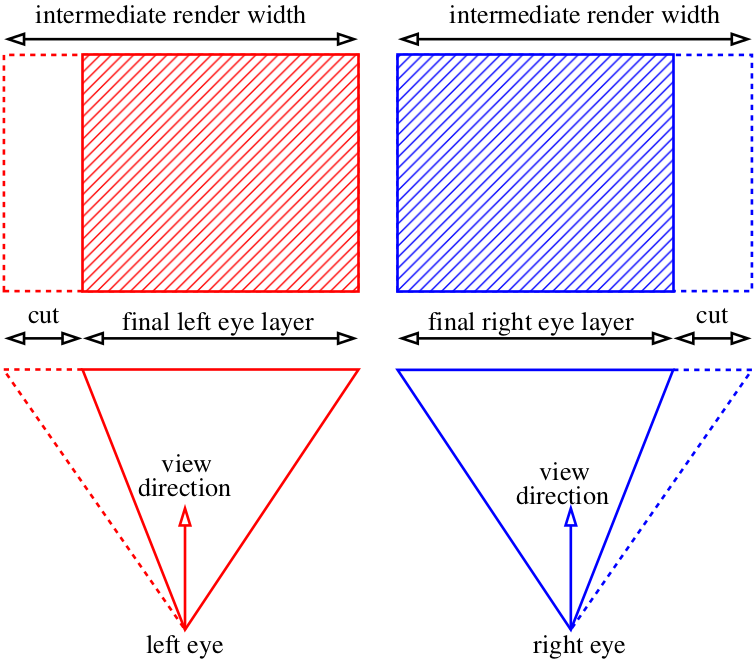
那我们现在呢? 作弊:)
我们可以渲染比我们需要的稍微宽一点的图像,然后只剪掉多余的部分:
浮雕
我认为我们已经介绍了基本的渲染机制,现在我们解决了将图像传递到大脑的问题。 最简单的方法是这种眼镜:

我们进行两个灰度渲染,并将左右图像分别分配给红色和蓝色通道。 这是我们得到的:

红色玻璃切出一个通道,蓝色玻璃切出另一个通道。 结合起来,眼睛会得到不同的图像,而我们会以3D方式感知它。
这是对tinyraytracer的主要提交的修改。 更改包括用于眼睛和通道组件的摄像头定位。
立体浮雕渲染是观看(计算机生成的)立体图像的最古老的方法之一。 它有很多缺点,例如不良的彩色传输。 但另一方面,它们很容易在家里创建。
如果您的计算机上没有编译器,那不是问题。 如果您拥有guithub帐户,则可以在浏览器中单击一下来查看,编辑和运行代码(原文如此!)。

当您打开此链接时,gitpod为您创建一个虚拟机,启动VS Code,并在远程计算机上打开一个终端。 在命令历史记录中(单击控制台并按向上键),有一整套命令,可用于编译代码,启动代码并打开生成的图像。
立体镜
随着智能手机成为主流,我们想起了19世纪称为立体镜的发明。 几年前,谷歌建议使用两个镜头(不幸的是,很难在家中制造,需要购买),使用一些硬纸板(可在任何地方买到)和一部智能手机(可以放在口袋里)来制造,令人难以置信VR眼镜。

他们在速卖通上花很多钱,每双价格约为3美元。 与浮雕渲染相比,我们什至没有太多要做:只需拍摄两张图片并排放置。
这是提交 。

严格来说,根据镜头的不同,我们可能需要
校正镜头的畸变 ,但我对此并不在意,因为无论如何它看起来都不错。 但是,如果我们真的需要应用镜筒预失真来补偿镜头的自然失真,那么这就是我的智能手机和眼镜的外观:

这是gitpod链接:
自动立体图
如果我们不想使用任何额外的设备,该怎么办? 然后只有一个选项-斜眼。 老实说,上一张图片足以观看立体图像,只需起眼睛即可(斜视或围住眼睛)。 这是一个方案,告诉我们如何观看上一个插图。 两行红线显示的图像由左视网膜感知,两行蓝线-右视网膜。
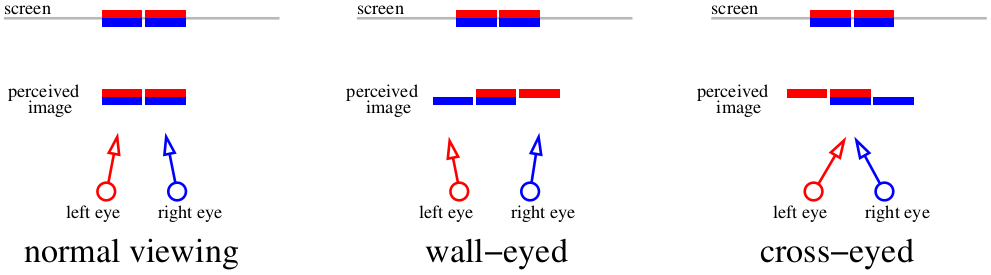
如果我们将焦点放在屏幕上,那么四个图像将合并为两个。 如果我们双眼,或者专注于远处的物体,则可以为大脑提供“三个”图像。 中央图像重叠,从而产生立体效果。
不同的人使用不同的方法:例如,我不能睁大眼睛,但容易遮住眼睛。 重要的是,仅应使用该方法查看为特定方法构建的自动立体图,否则我们将获得倒置的深度图(还记得正和负视差吗?)。 问题在于,很难使眼睛多睁开,因此仅适用于小图像。 但是,如果我们想要更大的呢? 让我们完全牺牲颜色,只专注于深度感知部分。 这是我们希望在本文结尾处看到的图片:

这是壁眼自动立体图。 对于那些喜欢其他方法的人,
这是一张图片 。 如果您不习惯自动立体图,请尝试其他条件:全屏,较小的图像,亮度,暗度。 我们的目标是遮住眼睛,以使附近的两个垂直条重叠。 最简单的方法是集中在图片的左上角,因为它很简单。 我个人以全屏方式打开图片。 不要忘记也删除鼠标光标!
不要停留在不完整的3D效果上。 如果模糊地看到圆形,并且3D效果很弱,则错觉是不完整的。 这些球体应该“跳出”屏幕,朝向观看者,效果必须稳定且可持续。 立体视有一种感觉:一旦获得稳定的图像,观察得越久,它就会越详细。 眼睛离屏幕越远,深度感知效果就越大。
此立体图是使用25年前在本文中建议的方法绘制的:“
显示3D图像:单图像随机点立体图的算法 ”。
让我们开始
渲染自动立体图的起点是深度图(因为我们放弃了颜色)。
该提交绘制以下图像:

越近越远的平面设置我们的深度:我的地图中最远的点的深度为0,而最接近的点的深度为1。
核心原则
假设我们的眼睛距离屏幕d距离。 我们将(假想的)远平面(z = 0)放置在屏幕“后”相同的距离处。 我们选择μ变量,该变量确定近平面(z = 1)的位置,该位置与远平面的距离为μd。 对于我的代码,我选择μ=⅓。 总体而言,我们整个“世界”的生存距离为d-μd到屏幕后方的d。 假设我们知道两眼之间的距离(以像素为单位,我选择了400像素):
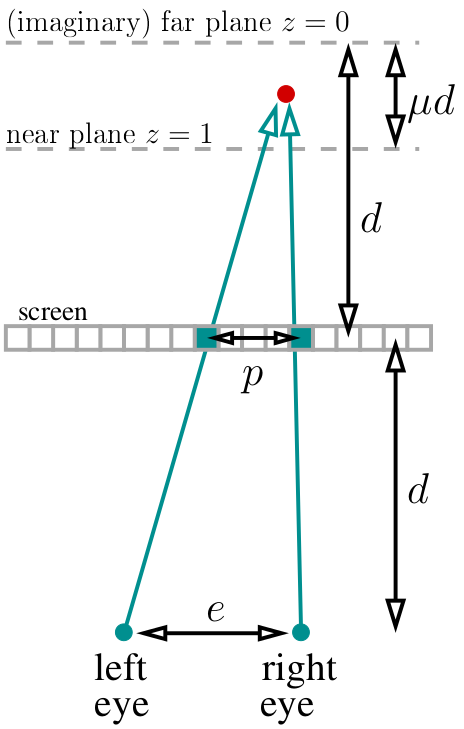
如果我们看红点,则两个标有绿色的像素在立体图中应具有相同的颜色。 如何计算它们之间的距离? 容易的 如果当前投影点的深度为z,则视差除以两眼之间的距离等于相应深度之间的分数:p / e =(d-dμz)/(2d-dμz)。 顺便说一下,请注意d被简化了,并且在其他任何地方都没有出现! 然后p / e =(1-μz)/(2-μz),这意味着视差等于p = e *(1-μz)/(2-μz)像素。
自动立体图背后的主要思想是:我们遍历整个深度图,对于每个深度值,我们确定哪些像素将具有相同的颜色,并将其放入约束系统中。 然后,我们从随机图像开始,尝试满足先前设置的所有约束。
准备源图像
在这里,我们准备图像,以后将受到视差约束。
这是commit ,它绘制如下:

请注意,除了我放置rand()* sin以创建周期性图案的红色通道以外,颜色大部分是随机的。 条纹相距200个像素,这是(给定的μ= 1/3,e = 400)我们世界(远平面)中的最大视差值。 该图案在技术上不是必需的,但可以帮助您聚焦眼睛。
自动立体图渲染
实际上,绘制自动立体图的完整代码如下所示:
int parallax(const float z) { const float eye_separation = 400.;
这是commit ,int视差(const float z)函数为我们提供了当前深度值相同颜色的像素之间的距离。 因为线彼此独立(我们没有垂直视差),所以我们逐行渲染立体图。 主循环简单地遍历每一行。 每次以无限制的像素集开始,然后为每个像素添加一个相等约束。 最后,它为我们提供了一定数量的相同颜色像素的簇。 例如,具有左和右索引的像素最终应相同。
如何存储这组约束? 最简单的方法是
联合查找数据结构 。 我不会详细介绍,只是去Wikipedia,实际上是三行代码。 要点是,对于每个群集,都有一个负责群集的“根”像素。 根像素保持其初始颜色,并且群集中的所有其他像素将被更新:
for (size_t i=0; i<width; i++) {
结论
就是这样。 二十行代码和我们的自动立体图已准备就绪,您可以大开眼界。 顺便说一句,如果我们尽力而为,就可以传输颜色信息。
我没有涉及
极化3D系统等其他立体系统,因为它们的制造成本要高得多。 如果我错过了什么,请随时纠正我!