窃听音乐以使派生内容民主化免责声明:本文中描述的所有知识产权,设计和方法已在US10014002B2和US9842609B2中公开。
我希望我能回到1965年,用通行证敲打Abby Road工作室的前门,走进去,听听列侬和麦卡特尼的真实声音……好吧,让我们尝试一下。 输入:甲壳虫平均质量的MP3
我们可以解决 。 上面的轨道是输入混音,下面的轨道是我们的神经网络突出显示的孤立的人声。
从形式上讲,此问题称为
声源 分离或
信号分离(音频源分离)。 它在于恢复或重建一个或多个原始信号,这些原始信号由于
线性或卷积过程而与其他信号混合。 该研究领域具有许多实际应用,包括改善声音(语音)质量和消除噪声,音乐混音,声音的空间分布,重制等。声音工程师有时将此技术称为混合。 这个主题有很多资源,从盲信号分离和独立分量分析(ICA)到非负矩阵的半控制因式分解,再到后来的基于神经网络的方法,都有很多资源。 您可以在CCRMA的
这些迷你指南中找到关于前两点的良好信息,
这些信息一次对我非常有用。
但是在开始开发之前...有相当多的应用机器学习哲学...甚至在“深度学习解决所有问题”的口号传播之前,我就从事信号和图像处理工作,因此我可以向您介绍一种
功能工程之旅解决方案,并
说明为什么神经网络是解决此特定问题的最佳方法 。 怎么了 我经常看到人们写这样的东西:
“通过深度学习,您不再需要担心选择功能; 它将为您做到。”或更糟糕的是...
“机器学习和深度学习之间的区别 [嘿...深度学习仍然是机器学习!]是
在ML中,您自己可以提取属性,而在深度学习中,这是在网络内自动发生的。”这些概括可能来自DNN在探索良好的隐藏空间方面非常有效的事实。 但是,不可能一概而论。 当最近的毕业生和从业人员屈服于上述误解并采用“全面学习”的方法时,我感到非常沮丧。 就像,抛出一堆原始数据(即使经过一些初步处理)就足够了-一切都会按预期进行。 在现实世界中,您需要注意性能,实时执行等问题,由于存在这样的误解,您将长期处于实验模式下……
特征工程在人工神经网络的设计中仍然是非常重要的学科。 像任何其他机器学习技术一样,在大多数情况下,是将生产水平的有效解决方案与不成功或无效的实验区分开来。 对数据及其性质的深刻理解仍然意味着很多...从A到Z
好的,我完成了讲道。 现在,让我们看看我们为什么在这里! 与任何数据处理问题一样,我们首先来看一下它的外观。 看看原始录音室录音中的下一个声音。
工作室主唱“最后一次”,阿丽亚娜·格兰德不太有趣吧? 好吧,这是因为我们
及时可视化了信号。 在这里,我们仅看到幅度随时间变化。 但是您可以提取其他各种信息,例如幅度包络(包络),均方根值(RMS),幅度从正值到负值的变化率(零交叉率)等,但是这些
符号太
原始且不够鲜明,帮助解决我们的问题。 如果要从音频信号中提取人声,则首先需要以某种方式确定人类语音的结构。 幸运的是,
傅立叶窗
变换 (STFT)得以解决。
STFT振幅谱-窗口大小= 2048,重叠= 75%,对数频率标度[Sonic Visualizer]尽管我喜欢语音处理,并且绝对喜欢玩
输入过滤器仿真,倒谱,sottotami,LPC,MFCC等
,但是我们将跳过所有这些废话,而将注意力集中在与我们的问题相关的主要元素上,以便使尽可能多的人理解本文,不只是信号处理专家。
那么人类语音的结构告诉我们什么?
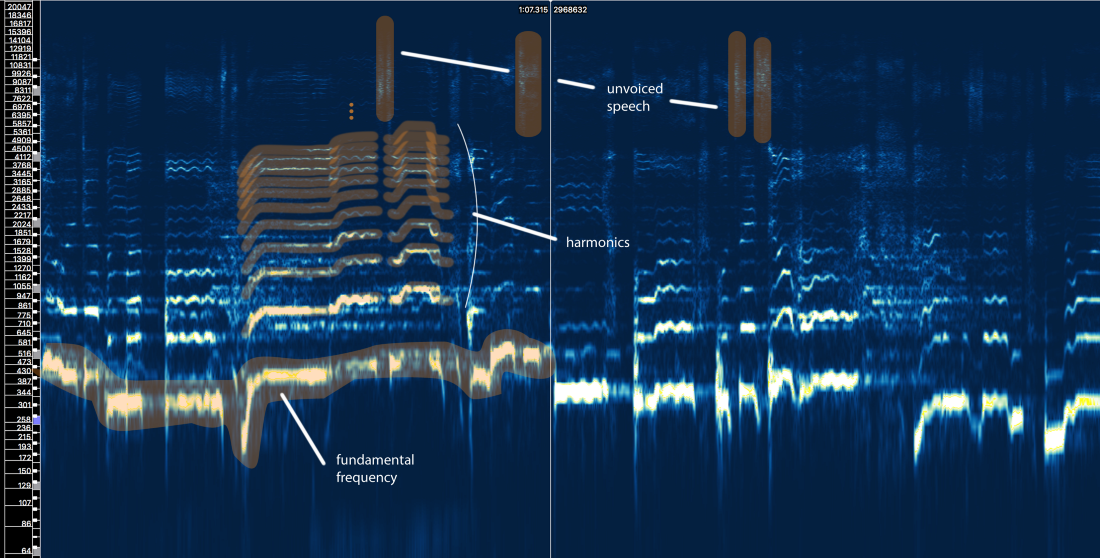
好吧,我们可以在此处定义三个主要元素:
- 基本频率 (f0),由我们声带的振动频率确定。 在这种情况下,Ariana的演唱频率为300-500 Hz。
- 在f0之上的一系列谐波 ,它们遵循相似的形状或样式。 这些谐波以f0的倍数出现。
- 语音清晰 ,包括诸如“ t”,“ p”,“ k”,“ s”(不是由声带的振动产生)之类的辅音,呼吸等。所有这些在高频区域以短脉冲形式出现。
首次尝试使用规则
让我们暂时忘记所谓的机器学习。 可以根据我们对信号的了解开发语音提取方法吗? 让我尝试...
天真人声隔离V1.0:- 确定有声乐的地方。 原始信号中有很多东西。 我们希望专注于真正包含语音内容的区域,而忽略其他所有内容。
- 区分浊音和清音。 如我们所见,它们是非常不同的。 它们可能需要以不同的方式处理。
- 评估基本频率随时间的变化。
- 基于引脚3,应用某种掩模来捕获谐波。
- 用清晰的语音片段做一些事情...

如果我们做得不错,结果应该是
软 屏蔽或
位屏蔽 ,将其应用于STFT的振幅(逐元素相乘)可以大致重建STFT声音的振幅。 然后,我们将此人声STFT与有关原始信号相位的信息进行组合,计算逆STFT,并获得重构人声的时间信号。
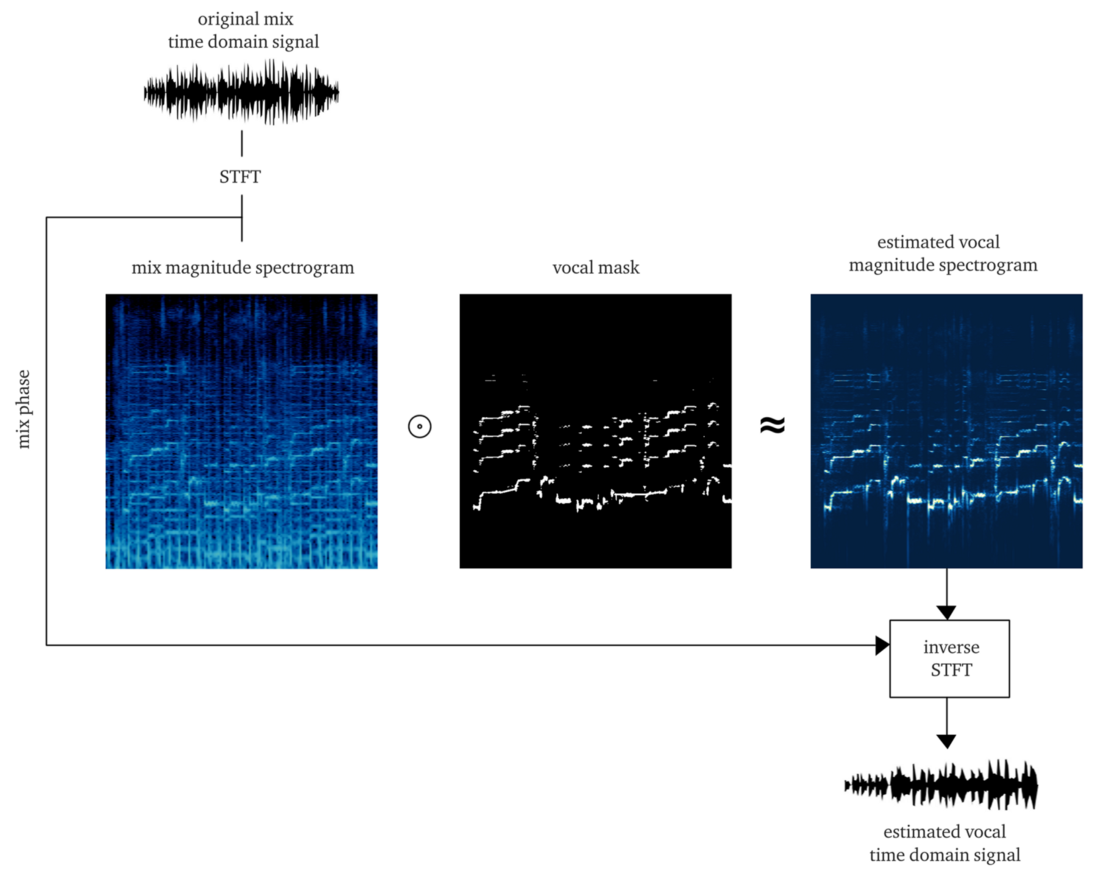
从头开始做到这一点已经是一项艰巨的任务。 但是为了演示,可以
使用pYIN算法的实现。 尽管打算解决步骤3,但是使用正确的设置,它可以很好地执行步骤1和2,即使在有音乐的情况下,也可以跟踪人声。 下面的示例包含处理此算法后的输出,但不处理清语音。
什么...? 他似乎已经完成了所有工作,但质量和亲密程度不高。 也许通过花费更多的时间,精力和金钱,我们将改善这种方法...
但是我问你...
如果在轨道上出现了
一些声音 ,却经常在至少50%的现代专业轨道上被发现,会发生什么?
如果通过
混响,延迟和其他效果处理人声,会发生什么? 让我们来看看这首歌中Ariana Grande的最后合唱。
您是否已经感到疼痛...? 我是
这种严格的规则方法很快就变成了纸牌屋。 这个问题太复杂了。 规则太多,例外太多,不同条件(效果和混合设置)太多。 多步骤方法还意味着一步中的错误会将问题扩展到下一步。 改善每个步骤将变得非常昂贵:需要大量的迭代才能使其正确。 最后但并非最不重要的一点是,最终我们可能会获得一个非常耗费资源的输送机,它本身可以抵消所有努力。
在这种情况下,是时候开始考虑一种更全面的方法了,让ML找到解决问题所必需的一些基本过程和操作。 但是我们仍然必须展示我们的技能并从事要素工程,您将明白原因。假设:使用神经网络作为传递函数,将混音转换为人声
看看卷积神经网络在处理照片方面的成就,为什么不在此应用相同的方法呢?
 神经网络成功解决了诸如图像着色,锐化和分辨率之类的问题。
神经网络成功解决了诸如图像着色,锐化和分辨率之类的问题。最后,您可以使用短期傅立叶变换将声音信号想象为“图像”,对吗? 尽管这些
声音图像不符合自然图像的统计分布,但是它们仍然具有在其上训练网络的空间模式(在时间和频率空间上)。
 左:鼓拍和基线以下,中间有几个合成器声音,所有声音都与人声混合。 右:只有人声
左:鼓拍和基线以下,中间有几个合成器声音,所有声音都与人声混合。 右:只有人声进行这样的实验将是一项昂贵的工作,因为很难获得或生成必要的训练数据。 但是在应用研究中,我总是尝试使用这种方法:首先,
确定一个更简单的问题,该问题可以确认相同的原理 ,但是并不需要很多工作。 这使您可以评估假设,更快地迭代并在模型无法正常运行的情况下以最小的损失对模型进行校正。
隐含的条件是
神经网络必须了解人类语音的结构 。 一个更简单的问题可能是:
神经网络可以确定在录音的任意片段上是否存在语音 。 我们正在谈论以二进制分类器形式实现的可靠
语音活动检测器(VAD) 。
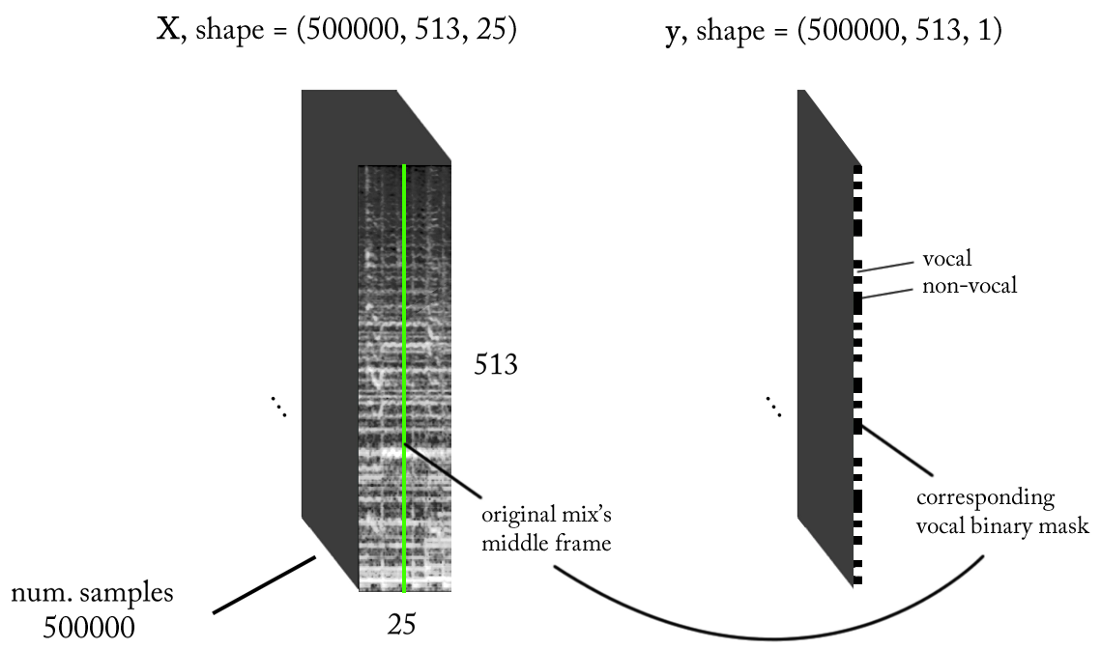
我们设计标牌的空间
我们知道声音信号(例如音乐和人类语音)是基于时间依赖性的。 简而言之,在给定的时间点没有孤立发生的事情。 如果我想知道特定录音片段上是否有声音,则需要查看相邻区域。 这样的
时间范围提供了有关感兴趣区域中正在发生的事情的良好信息。 同时,期望以非常小的时间增量执行分类,以便识别具有尽可能高的时间分辨率的人类语音。

让我们数点...
- 采样频率(fs):22050 Hz(我们从44100下采样到22050)
- STFT设计:窗口大小= 1024,跳数= 256,权重过滤器的粉笔刻度插值,同时考虑了感知。 由于我们的输入是真实的 ,因此您可以使用一半的STFT(解释超出了本文的范围...),同时保持DC分量(可选),这为我们提供了513个频点。
- 目标分类分辨率:一个STFT帧(〜11.6 ms = 256/22050)
- 目标时间范围:〜300毫秒= 25 STFT帧。
- 培训实例的目标数量:50万。
- 假设我们以1 STFT时间帧为增量使用滑动窗口来生成训练数据,则需要大约1.6个小时的标记声音才能生成50万个数据样本
基于上述要求,我们的二进制分类器的输入和输出如下:
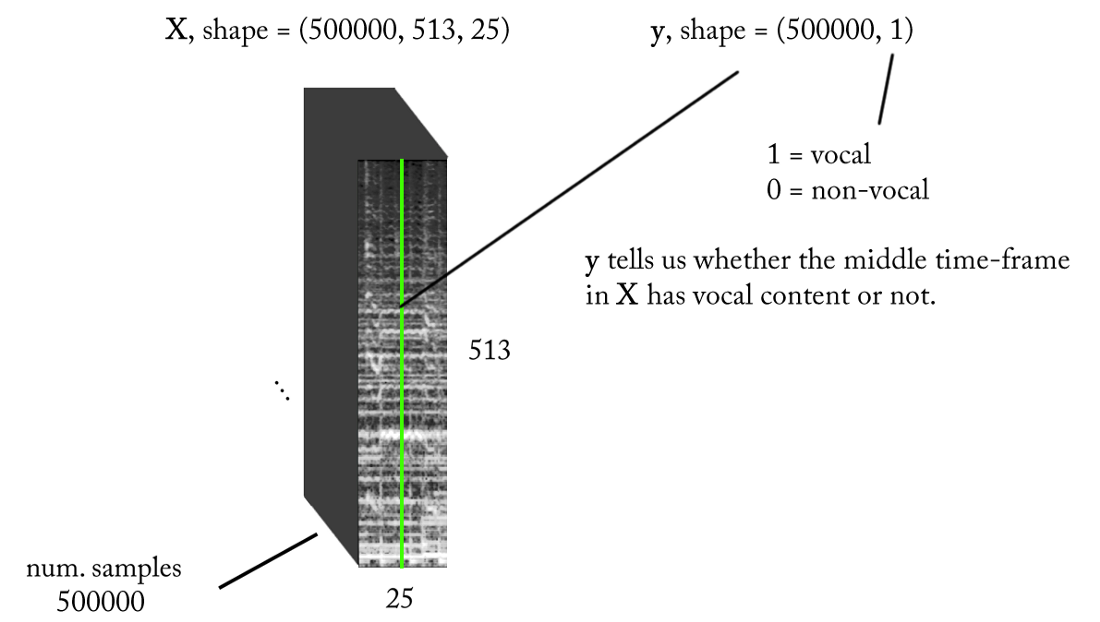
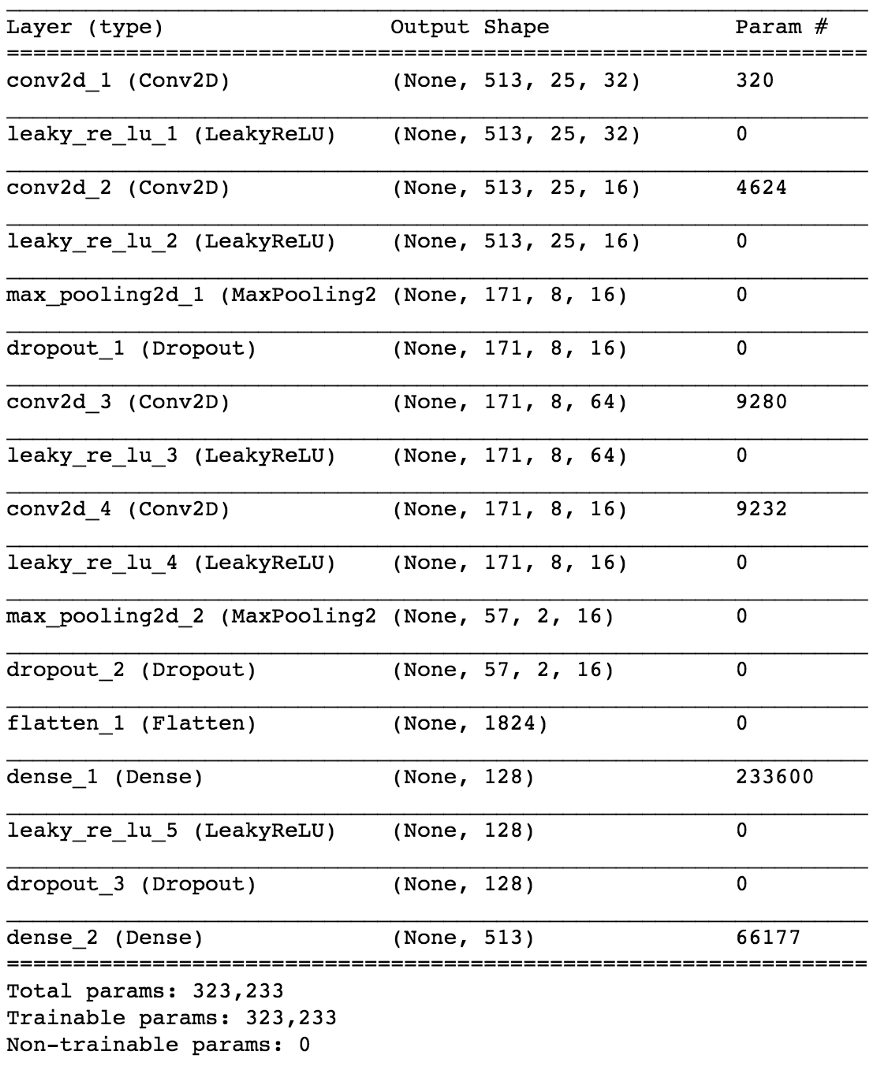
型号
使用Keras,我们将建立一个神经网络的小模型来检验我们的假设。
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
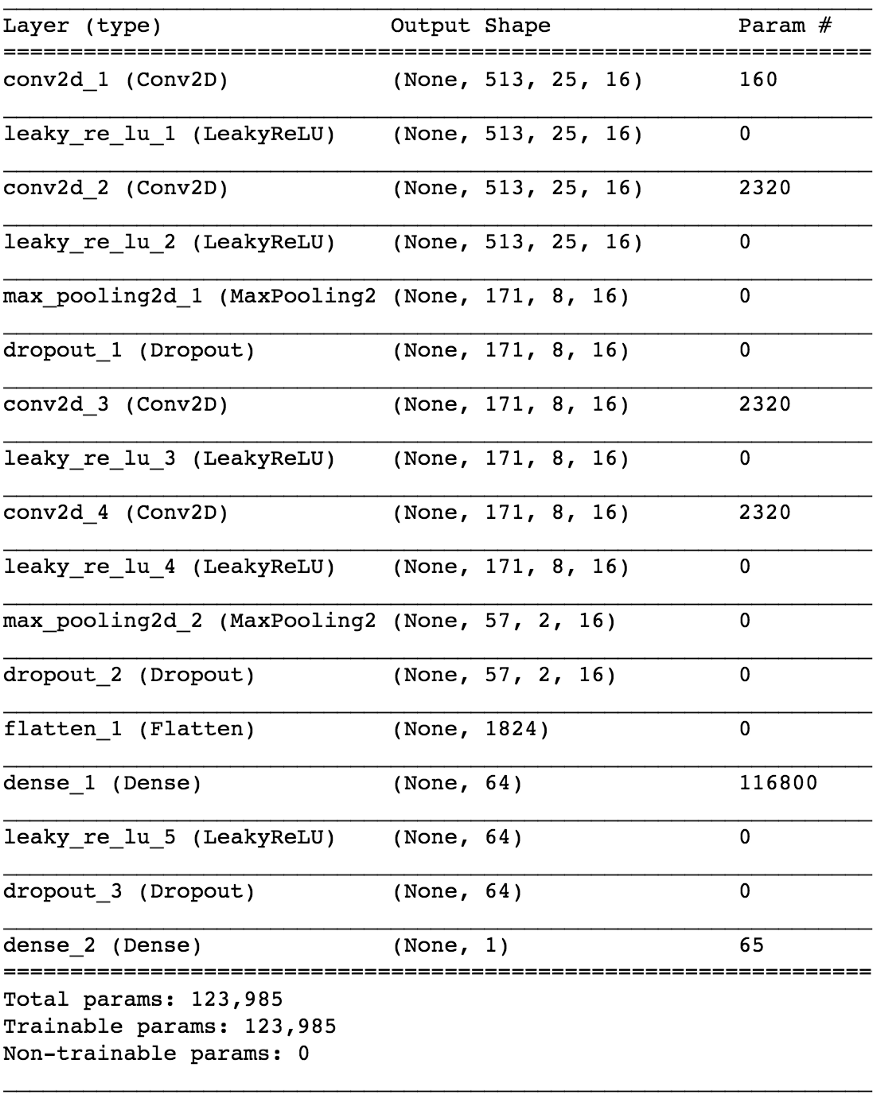
通过在约50个纪元后将80/20数据划分为训练和测试,我们可以得到
约97%的测试精度 。 这充分证明了我们的模型能够区分音乐声音片段中的人声(和没有人声的片段)。 如果我们从第四卷积层检查一些特征图,我们可以得出结论,神经网络似乎已经优化了其内核以执行两项任务:过滤音乐和过滤人声...
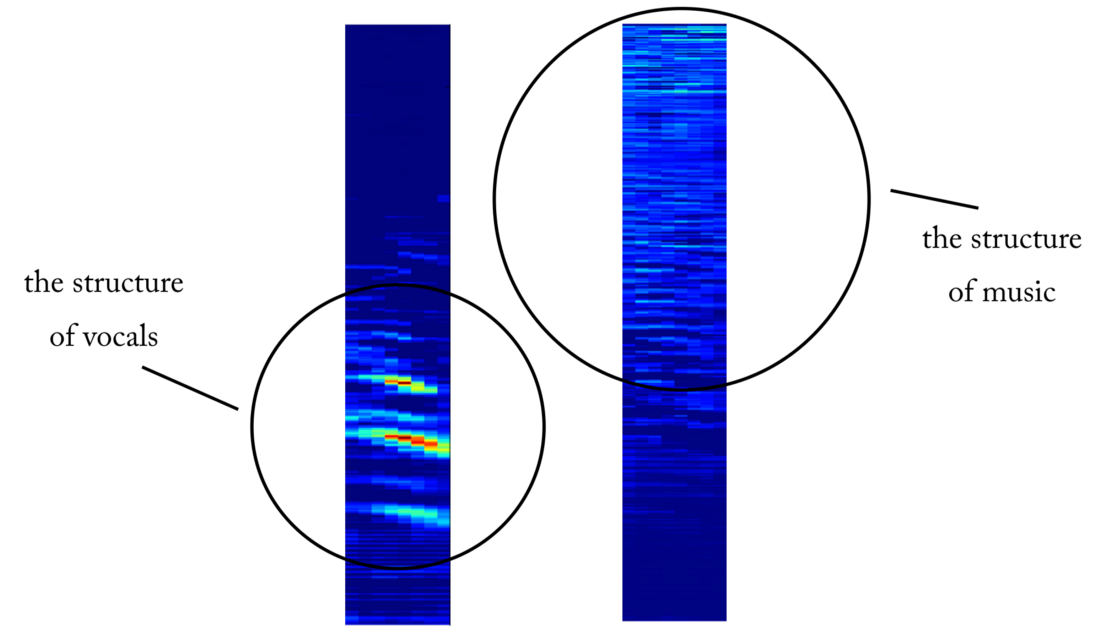 第四卷积层出口处的对象图的示例。 显然,左侧的输出是内核操作的结果,该操作旨在保留声音内容而忽略音乐。 高价值类似于人类言语的和谐结构。 右侧的对象图似乎是相反的结果
第四卷积层出口处的对象图的示例。 显然,左侧的输出是内核操作的结果,该操作旨在保留声音内容而忽略音乐。 高价值类似于人类言语的和谐结构。 右侧的对象图似乎是相反的结果从语音检测器到信号断开
解决了较简单的分类问题后,我们如何继续将人声与音乐真正分离? 好吧,看看第一种
幼稚的方法,我们仍然想以某种方式获得人声的振幅谱图。 现在,这已成为一项回归任务。 我们想要做的是从原始信号的STFT中的特定时间范围(即混合(具有足够的时间范围))中,为该时间范围内的人声计算合适的振幅谱。
训练数据集呢? (您现在可以问我)该死的...为什么这样。 我将在本文结尾处考虑这一点,以免使您分心!
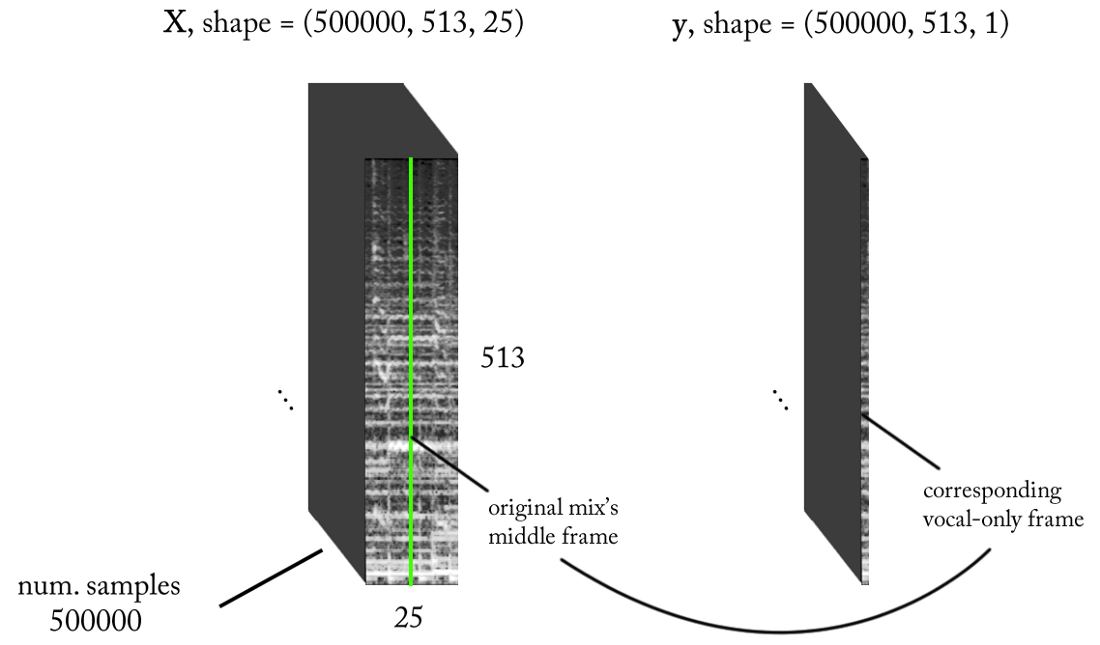
如果我们的模型训练有素,那么对于一个合理的结论,您只需要为STFT混合实现一个简单的滑动窗口即可。 每次预测后,将窗口向右移动1个时间范围,用声乐预测下一帧并将其与先前的预测相关联。 对于模型,让我们采用与语音检测器相同的模型并进行小的更改:输出波形现在为(513.1),输出处的线性激活,MSE是损耗的函数。 现在我们开始培训。
还不欢喜...尽管这种I / O表示很有意义,但是在对我们的模型进行了数次训练之后,使用各种参数和数据规范化,都没有结果。 看来我们要求太多了...
我们已经从二元分类器转向了513维向量的
回归 。 尽管网络正在某种程度上研究该问题,但是恢复的人声仍然具有明显的伪像和来自其他来源的干扰。 即使添加了额外的层并增加了模型参数的数量,结果也不会有太大变化。 然后出现一个问题:
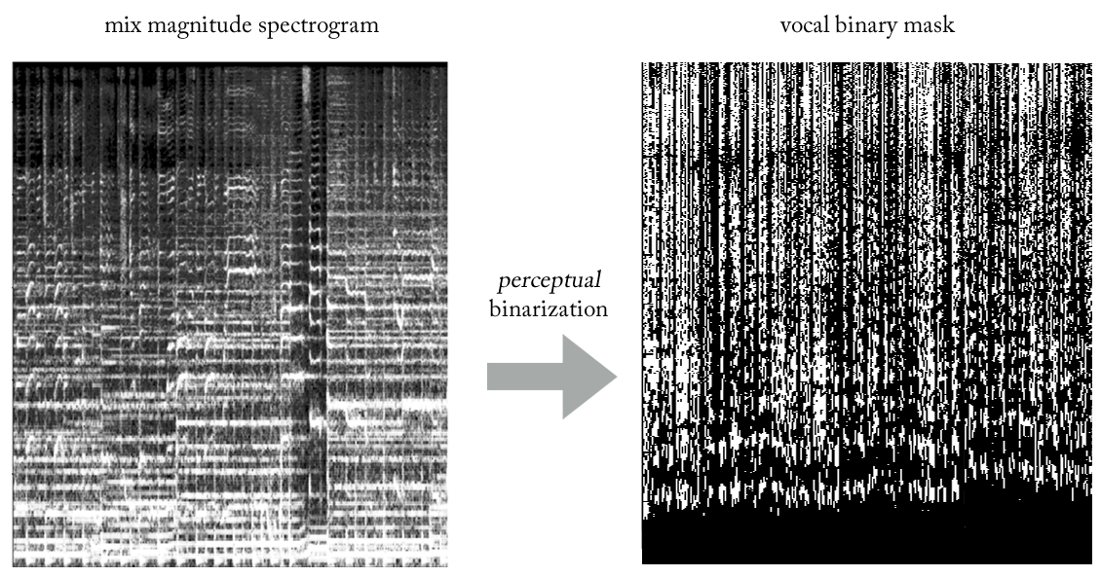
如何通过欺骗“简化”网络任务,同时达到预期的效果?如果不是训练STFT人声的振幅而不是估计STFT人声的振幅,该怎么办呢?我们训练网络以获得二进制掩码,将其应用于STFT混合后,我们得到人声的简化但在
感知上可接受的振幅频谱图?
通过尝试各种启发式方法,我们想到了一种非常简单的方法(在信号处理方面肯定是非正统的……),使用二进制掩码从混音中提取人声。 无需赘述,其实质如下。 将输出想象成二进制图像,其中值“ 1”表示在给定的频率和时间范围内
声音内容的
普遍存在 ,而值“ 0”指示在给定位置音乐的普遍存在。 我们可以称其
为知觉的
二值化 ,只是想出一个名字。 老实说,从外观上看,它看起来很丑陋,但结果出奇地好。
现在我们的问题变成了一种混合回归分类(非常粗略地……)。 我们要求模型将输出中的像素“分类为有声或无声”,尽管从概念上(以及从使用的MSE损失函数的角度来看),任务仍然是回归的。
尽管这种区分对于某些人来说似乎不合适,但实际上,对于模型研究任务的能力而言,这是非常重要的,第二种方法更简单,更受限制。 同时,考虑到任务的复杂性,这使我们可以在参数数量方面使模型保持相对较小,这对于实时工作非常理想,在这种情况下,这是设计要求。 经过一些细微的调整,最终模型看起来像这样。
如何恢复时域信号?
其实就像
天真的方法一样 。 在这种情况下,对于每次通过,我们都将预测二进制人声蒙版的一个时间范围。 同样,通过一个时间框架的步长实现一个简单的滑动窗口,我们将继续评估并组合连续的时间框架,最终构成整个人声二进制蒙版。

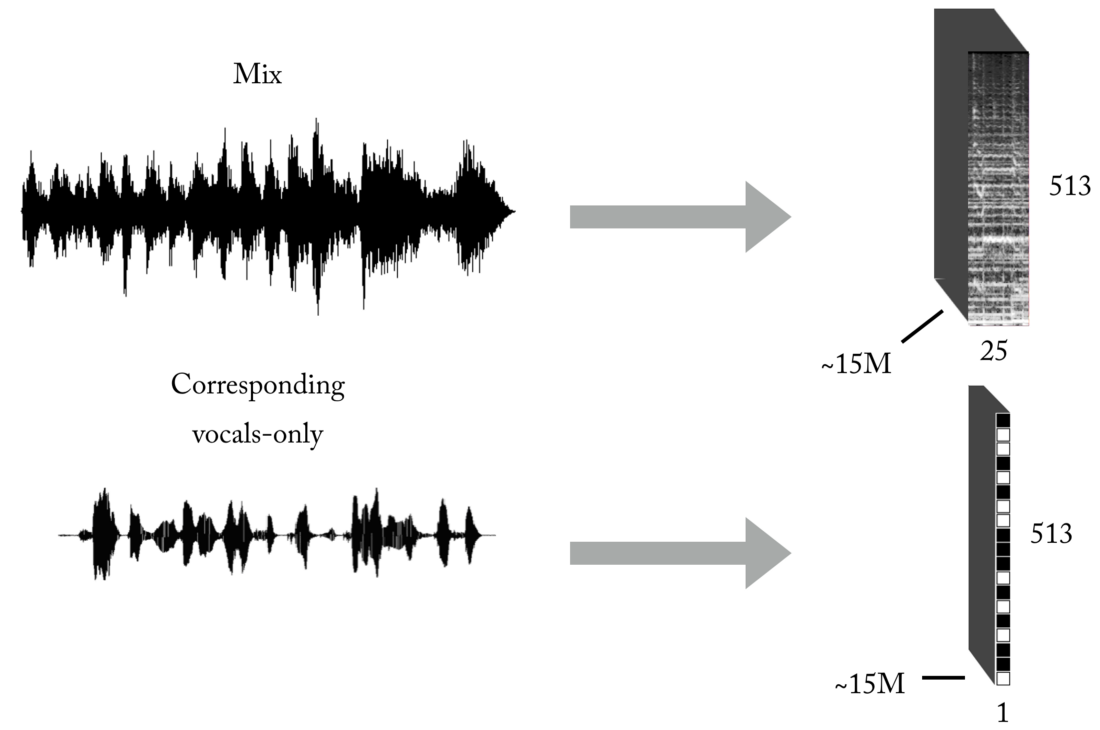
创建训练集
如您所知,与老师一起教学时的主要问题之一(将这些玩具示例保留在现成的数据集中)是针对您要解决的特定问题的正确数据(数量和质量)。 根据所描述的输入和输出表示,要训练我们的模型,您首先需要大量的混音及其对应的,完全对齐和归一化的人声轨。 可以通过多种方式来创建此音乐集,并且我们使用了多种策略的组合,从基于Internet上找到的几首手书手动创建对[mix <-> vocals],到搜索摇滚乐队的音乐资料和Youtube剪贴簿。 只是为了让您了解此过程的艰辛和痛苦,该项目的一部分是开发了一种用于自动创建对[mix <-> vocals]的工具:

神经网络需要非常大量的数据来学习传递混合声音到人声的传递函数。 我们的最后一组包括300万个混音的大约1500万个样本及其相应的人声二进制蒙版。
管道架构
您可能知道,为特定任务创建ML模型只是成功的一半。 在现实世界中,您需要考虑软件架构,尤其是当您需要实时或接近实时的工作时。
在此特定实现中,可以在预测完整的二进制人声蒙版(独立模式)后立即进行时域重构,或者更有趣的是,在多线程模式下,我们在其中接收和处理数据,还原人声并再现声音-都在小段内,接近流媒体,甚至几乎是实时的,以最小的延迟处理实时录制的音乐。 实际上,这是一个单独的主题,我将把它留给另一篇
有关实时ML管道的文章 ...
我想我已经说够了,那么为什么不听几个例子呢?
傻朋克-幸运(录音室录音)
在这里您可以听到鼓声的干扰最小...阿黛尔-放火烧雨(现场录音!)
请注意,我们的模型从一开始就将人群的尖叫声提取为语音内容:)。 在这种情况下,会受到其他来源的干扰。 由于这是现场录音,因此所提取的声音质量比以前的声音差是可以接受的。是的,还有“其他” ...
如果该系统适用于人声,为什么不将其应用于其他乐器...?
这篇文章已经很大了,但是鉴于已经完成的工作,您应该听听最新的演示。 利用与提取人声时完全相同的逻辑,我们可以尝试将立体声音乐划分为各个组成部分(鼓,贝斯,人声等),对我们的模型进行一些更改,当然,还要进行适当的训练:)。
感谢您的阅读。 最后一点:正如您所看到的,我们的卷积神经网络的实际模型并不是那么特别。 这项工作的成功取决于
功能工程和简洁的假设测试过程,我将在以后的文章中进行介绍!