最近,由于必要,我仔细检查了Go开发人员的所有空缺,其中有一半(至少)提到了
Apache Kafka消息处理平台和
Redis NoSQL数据库。 好吧,当然,每个人都希望候选人了解Docker和其他类似他的人。 对我们来说,所有这些要求,已经看过系统工程师的意见,似乎有些琐碎。 好吧,实际上,一条线与另一条线有何不同? 当然,NoSQL数据库的情况更加多样化,但它们似乎比任何MS SQL Server都更简单。 当然,所有这一切都是我个人在哈布雷(Habé)上多次提到的
邓宁-克鲁格效应 。
因此,由于所有雇主都要求,有必要研究这些技术。 但是从头到尾阅读所有文档开始并不是很有趣。 我认为,阅读介绍,制作可行的原型,修复错误,遇到问题,解决问题会更有效率。 在了解了所有这些内容之后,请阅读文档,甚至单独阅读一本书。

那些对在短时间内熟悉这些产品的基本功能感兴趣的人,请继续阅读。
培训计划将考虑数字。 它将包括一个大型数字生成器,一个数字处理器,一个队列,列存储和一个Web服务器。
在开发过程中,将应用以下设计模式:
系统架构将如下所示:
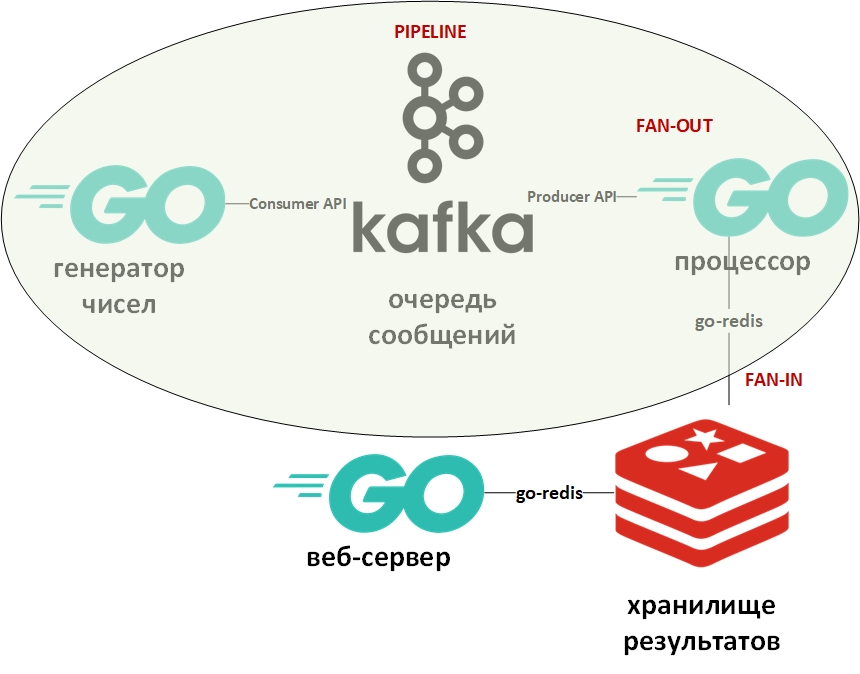
在图中,椭圆形表示输送机的设计图案。 我将更详细地介绍它。
模板“传送带”假定信息以流的形式出现并分阶段进行处理。 通常,有一些生成器(信息源)和一个或多个处理器(信息处理器)。 在这种情况下,生成器将是Go上的程序,该程序将随机大数排队。 处理器(唯一的处理器)将是一个从队列中获取数据并执行分解的程序。 在纯Go上,使用通道(chan)非常容易实现此模式。 上面有一个带有示例的指向我的github的链接。 在这里,消息队列将扮演通道的角色。
扇入-扇出模板通常一起使用,并且应用于Go时,意味着使用goroutine并行进行计算并行化,然后汇总结果并将其传输到下游。 上面也提供了示例的链接。 再次,通道被队列替换,goroutines保留在原处。
现在谈谈Apache Kafka。 Kafka是一个具有出色群集工具的消息管理系统,该系统使用事务日志(与RDBMS中的日志完全一样)来存储消息,并支持队列模型和发布者/订阅者模型。 后者是通过邮件收件人组实现的。 每条消息仅接收该组的一个成员(并行处理),但是该消息将被传递到每个组一次。 可以有许多这样的组,以及每个组中的收件人。
要使用Kafka,我将使用“ github.com/segmentio/kafka-go”软件包。
另一方面,Redis是内存中的键值列数据库,它支持永久存储数据的功能。 键和值的主要数据类型是字符串,但还有一些其他类型。 Redis被认为是同类产品中速度最快(或最多)的数据库之一。 最好存储各种统计信息,指标,消息流等。
要使用Redis,我将使用“ github.com/go-redis/redis”包。
由于本文是快速入门,因此我们将使用DockerHub中的现成映像使用Docker部署这两个系统。 我在Windows 10上的Linux VM(由Docker VM自动创建)上以容器模式使用docker-compose,并使用以下docker-compose.yml文件:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
保存此文件,转到文件目录并执行:
docker-compose up -d
应该下载并启动三个容器:Kafka(队列),Zookeeper(Kafka的配置服务器)和(Redis)。
您可以使用以下命令验证容器是否正常工作:
docker-compose ps
应该是这样的:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
根据yml文件,应该自动创建三个队列,您可以使用以下命令查看它们:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
应该有生成,已解决和未解决的队列(主题-用Kafka表示的主题)。
数据生成器无限随机地将数字排队。 它的代码非常简单。 您可以使用以下命令验证Generated队列中消息的存在:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
接下来是
处理器 -在这里您应该注意并行处理以下代码块中队列中的值:
var wg sync.WaitGroup c := 0
由于从消息队列中进行读取会阻止程序,因此我创建了一个超时为15秒的context.Context对象。 如果队列很长时间为空,则此超时将终止程序。
此外,对于将因子分解的每个gorutin,还将设置最大工作时间。 我希望将能够分解的数字写在一个数据库中。 并且在分配的时间内无法分解的数字被转移到另一个数据库。
为了确定大概的时间,使用了基准:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Go中的基准测试种类繁多,并与测试一起放置在文件中。 基于此测量,为随机数生成器选择了最大数。 在我的计算机上,部分数字有时间考虑,而部分时间没有。
那些可分解的数字写在DB No.0中,未分解的数字写在DB No.1中。
在这里我必须说,在Redis中没有古典意义上的表。 默认情况下,DBMS包含16个可供程序员使用的数据库。 这些基数的数量不同-从0到15。
使用上下文和select语句提供了处理器中goroutine的时间限制:
这是Go上另一种典型的开发技巧。 其含义是select语句遍历通道并执行与第一个活动通道相对应的代码。 在这种情况下,goroutine会将结果输出到其通道,或者超时的上下文通道将关闭。 除了上下文以外,您可以使用任意通道充当管理器并提供goroutine的强制终止。
用于写入数据库的子例程执行命令以选择所需的数据库(0或1),并为已解析的数字写成形式(数字-因数)或为未分解的数字写成(数字-数)形式的对。
func storeSolved(item data) (err error) {
最后一部分将是
Web服务器 ,它将以json的形式显示分解和未分解的数字的列表。 他将有两个端点:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
从Redis接收数据并以json形式返回的http请求处理程序如下所示:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
在以下位置的请求结果:
localhost /解决 [{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
现在,您可以深入研究文档和专业文献。 希望本文对您有所帮助。
我要求专家不要太懒惰,并指出我的错误。