Wikipedia告诉我们:“在跟踪模式下,程序员可以在程序执行的这一步看到命令执行的顺序和变量的值,这使检测错误更加容易。” 作为Linux爱好者,我们经常会遇到一个问题,即哪种特定工具最适合实现它。 我们想分享推荐bpftrace的程序员Hongley Lai的文章翻译。 展望未来,我会说这篇文章简洁地结束了:“ bpftrace是未来”。 那他为什么给黎的同事留下深刻的印象? 切下的详细答案。
Linux上有两个主要的跟踪工具:
strace允许您查看正在进行哪些系统调用;
ltrace使您可以查看正在调用哪些动态库。
尽管它们有用,但是这些工具是有限的。 如果您需要找出系统或库调用中发生了什么? 并且,如果您不仅需要编译一个调用列表,还需要例如收集某些行为的统计信息? 如果需要跟踪多个流程并比较多个来源的数据?
在2019年,我们终于在Linux上对这些问题有了一个不错的答案:基于
eBPF技术的
bpftrace 。 Bpftrace允许您编写在每次事件发生时运行的小程序。
在本文中,我将描述如何安装bpftrace并教授其基本应用程序。 我还将概述跟踪生态系统的外观(例如,“ eBPF是什么?”)以及它如何演变成今天的状态。
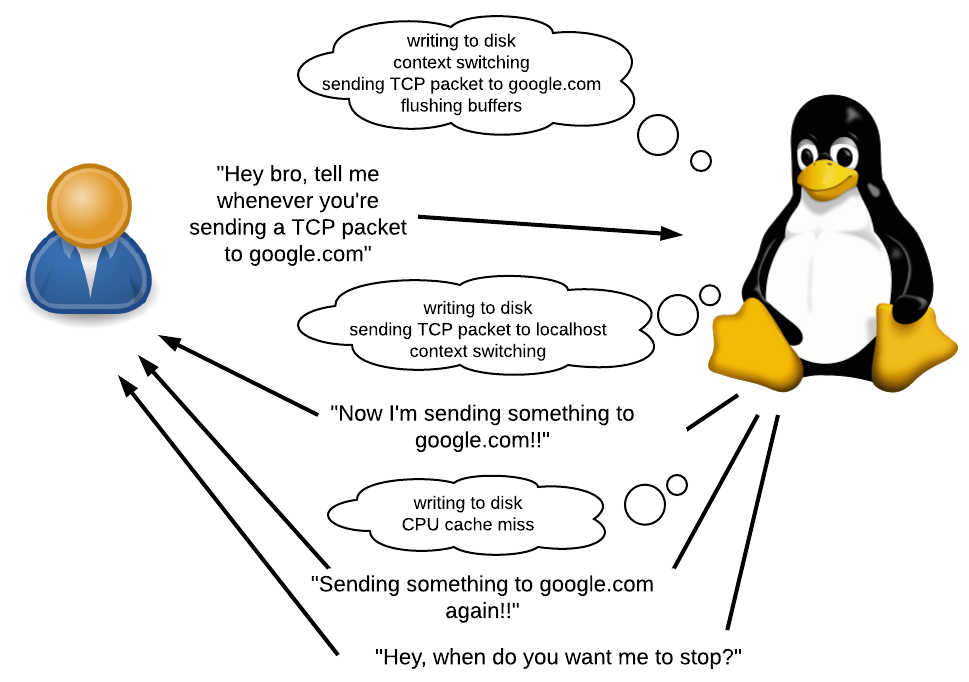
什么是痕迹?
如前所述,bpftrace允许您编写在每次事件发生时运行的小程序。
什么事 它可能是系统调用,函数调用,甚至是此类请求中发生的事情。 它也可以是计时器或硬件事件,例如,“自上一次相同事件以来已过去50毫秒”,“发生页面失败”,“发生上下文切换”或“发生了cashe-miss处理器”。
响应事件该怎么办? 您可以承诺一些事情,收集统计信息并执行任意的Shell命令。 您将可以访问各种上下文信息,例如当前的PID,堆栈跟踪,时间,调用参数,返回值等。
什么时候使用? 在许多。 您可以通过汇编最慢的调用列表来找出应用程序运行缓慢的原因。 您可以确定应用程序中是否存在内存泄漏,如果存在,则在何处。 我用它来理解为什么Ruby使用这么多内存。
bpftrace的最大优点是您不需要重新编译应用程序。 无需在正在研究的应用程序的源代码中手动编写打印调用或任何其他调试代码。 甚至不需要重新启动应用程序。 所有这一切都具有非常低的开销。 这使得bpftrace对于直接在产品上调试系统或在重新编译有困难的其他情况下特别有用。
DTrace:跟踪之父
长期以来,最好的跟踪工具是
DTrace ,它是最初由Sun Microsystems(Java的制造商)开发的完整的动态跟踪框架。 与bpftrace一样,DTrace允许您编写响应事件而运行的小型程序。 实际上,生态系统的许多关键要素很大程度上是由著名的DTrace专家
布伦丹·格雷格 (
Brendan Gregg)开发的,他目前在Netflix工作。 这就解释了DTrace和bpftrace之间的相似之处。
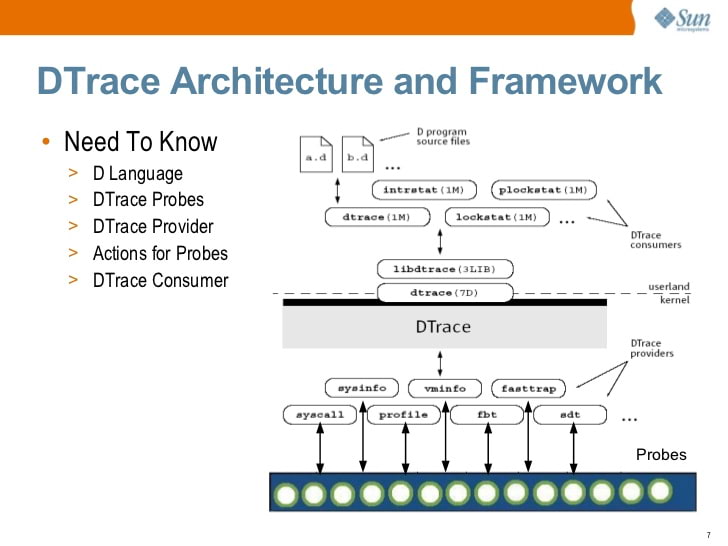 Sun Microsystems的S.Tripathi撰写的Solaris DTrace简介(2009)
Sun Microsystems的S.Tripathi撰写的Solaris DTrace简介(2009)在某个时候,Sun打开了DTrace的源。 如今,DTrace在Solaris,FreeBSD和macOS上可用(尽管macOS版本通常不可操作,因为系统完整性保护SIP破坏了DTrace运行的许多原理)。
是的,您正确地注意到了... Linux不在此列表中。 这不是工程问题,这是许可问题。 DTrace是在CDDL(而不是GPL)下打开的。
Linux DTrace端口从2011年开始可用,但是主要的Linux开发人员从未支持过
该端口 。 在2018年初,
Oracle在GPL下重新开放了DTrace ,但那时已经为时已晚。
Linux追踪生态系统
毫无疑问,跟踪非常有用,Linux社区已寻求开发针对此主题的自己的解决方案。 但是,与Solaris不同,Linux不受特定供应商的监管,因此没有刻意努力开发DTrace的全功能替代产品。 Linux跟踪生态系统已经缓慢自然地发展了,可以解决问题。 直到最近,这个生态系统才发展壮大,足以与DTrace竞争。
由于自然生长,该生态系统似乎有些混乱,由许多不同的组件组成。 幸运的是,朱莉娅·埃文斯
( Julia Evans
)对这个生态系统进行了评论 (注意,发布日期是bpftrace出现之前的2017年)。
 Julia Evans描述的Linux跟踪生态系统
Julia Evans描述的Linux跟踪生态系统并非所有元素都同样重要。 让我简要总结一下我认为最重要的元素。
事件来源事件数据可以来自内核或用户空间(应用程序和库)。 其中一些可以自动使用,而无需开发人员额外努力,而其他一些则需要手动发布。
 Linux中跟踪事件的最重要来源概述
Linux中跟踪事件的最重要来源概述在内核方面,有kprobes(
来自“内核探针”,“内核传感器”,大约每。 )-一种机制,可让您跟踪内核中的任何函数调用。 使用它,您不仅可以跟踪系统调用本身,还可以跟踪它们内部发生的事情(因为系统调用的入口点将调用其他内部函数)。 您还可以使用kprobes跟踪不是系统调用的内核事件,例如,“正在将缓冲数据写入磁盘”,“通过网络发送TCP数据包”或“正在进行上下文切换”。
内核跟踪点允许跟踪内核开发人员定义的非标准事件。 这些事件不在函数调用级别。 为了创建这样的点,内核开发人员将TRACE_EVENT宏手动放置在内核代码中。
两种来源都有其优缺点。 Kprobes可以“自动”工作,因为 不需要内核开发人员手动编码代码。 但是kprobe事件可以从内核的一个版本任意更改为另一个版本,因为功能不断变化-它们被添加,删除,重命名。
内核跟踪点通常会随着时间的推移更加稳定,并且可以提供有用的上下文信息,如果使用kprobes则可能不可用。 使用kprobes,您可以访问函数调用参数。 但是借助跟踪点,您可以获得内核开发人员决定手动描述的任何信息。
在用户空间中,有一个kprobes的类似物-uprobes。 它旨在跟踪用户空间中的函数调用。
USDT传感器(“静态定义的用户空间跟踪”)是用户空间中内核跟踪点的模拟。 应用程序开发人员需要手动将USDT传感器添加到其代码中。
有趣的事实:DTrace一直提供C API来定义自己的USDT传感器模拟(使用DTRACE_PROBE宏)。 Linux中的跟踪生态系统的开发人员决定使源代码与此API兼容,因此所有DTRACE_PROBE宏都会自动转换为USDT传感器!
因此,从理论上讲,strace可以使用kprobes来实现,而ltrace可以使用uprobes来实现。 我不确定这是否已经实施。
介面界面是允许用户轻松使用事件源的应用程序。
让我们看看事件源是如何工作的。 工作流程如下:
- 内核代表一种机制(通常是一个开放的用于编写的/ proc或/ sys文件),该机制既记录了跟踪事件的意图,又记录了事件发生的后果。
- 一旦注册,内核便将内核/函数定位在用户空间/跟踪点/ USDT传感器的内存中,并更改其代码,以便发生其他事情。
- 这个“其他”的结果可以稍后使用某种机制来收集。
我不想手动完成所有这些操作! 因此,接口可助您一臂之力:它们可以为您完成所有这些工作。
有各种口味和颜色的界面。 在
基于eBPF的接口领域中
,有一些底层
接口需要深入了解如何与事件源交互以及eBPF字节码如何工作。 并且存在高层且易于操作,尽管在它们存在期间并没有表现出很大的灵活性。
这就是为什么bpftrace-最新的界面-是我的最爱。 像DTrace一样,它是用户友好和灵活的。 但这是很新的,需要抛光。
eBPF
eBPF是bpftrace所基于的
新Linux跟踪明星 。 跟踪事件时,您希望内核中发生某些事情。 确定此“事物”是什么的灵活方法? 当然,可以使用编程语言(或使用机器代码)。
eBPF(伯克利数据包过滤器的增强版)。 这是在内核中运行的高性能虚拟机,具有以下属性/限制:
- 所有用户空间交互都是通过eBPF“卡”发生的,eBPF卡是键值数据存储。
- 没有周期,因此每个eBPF程序都在特定时间终止。
- 等一下,我们说批量过滤器? 没错:它们最初是用来过滤网络数据包的。 这是一个类似的任务:转发数据包(事件发生)时,您需要执行某种管理操作(接受,丢弃,记录或重定向数据包等)。为了加快此类操作的执行速度,发明了虚拟机(具有JIT功能)编译)。 之所以考虑使用“扩展”版本,是因为与伯克利数据包过滤器的原始版本相比,eBPF可以在网络环境之外使用。
你去。 使用bpftrace,您可以确定要跟踪的事件以及响应中应该发生的事件。 Bpftrace将您的高级bpftrace程序编译为eBPF字节码,跟踪事件,并将字节码加载到内核中。
eBPF之前的黑暗日子
坦率地说,在使用eBPF之前,解决方案选项很尴尬。
SystemTap是Linux家族bpftrace的“最严重”的前身。 SystemTap脚本被翻译成C语言,并作为模块加载到内核中。 然后加载生成的内核模块。
这种方法非常脆弱,并且在Red Hat Enterprise Linux之外很少得到支持。 对我来说,它在Ubuntu上运行不佳,由于内核数据结构的更改,它往往在每次内核更新时都破坏SystemTap。 也有人说,SystemTap在它成立之初
就很容易引起内核恐慌 。
Bpftrace安装
是时候卷起袖子了! 在本指南中,我们将研究在Ubuntu 18.04上安装bpftrace。 不希望使用较新版本的发行版,因为 在安装期间,我们将需要尚未为其编译的软件包。
依赖安装首先,安装Clang 5.0,lbclang 5.0和LLVM 5.0,包括所有头文件。 我们将使用llvm.org提供的软件包,因为Ubuntu存储库中的软件包存在
问题 。
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
下一个:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
最后,从上游而不是从Ubuntu存储库安装libbfcc-dev。 Ubuntu中的软件包中
没有头文件 。 而且这个问题甚至在18.10都没有解决。
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Bpftrace主要安装现在该从源代码安装bpftrace本身了! 让我们对其进行克隆,组装并将其安装在/ usr / local中:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
大功告成! 该可执行文件将安装在/ usr / local / bin / bpftrace中。 您可以使用cmake参数更改目标,默认情况下,该参数如下所示:
DCMAKE_INSTALL_PREFIX=/usr/local.
一线示例让我们运行一些bpftrace单行代码来了解我们的功能。 我从
Brendan Gregg的
指南中获取了这些
指南 ,其中详细介绍了每个
指南 。
#1.显示传感器列表
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
#2.问候
bpftrace -e 'BEGIN { printf("hello world\n"); }'
#3.打开文件
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
#4.每个进程的系统调用数
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
#5.按字节数分配read()调用
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
#6.动态跟踪read()内容
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
#7.在read()调用上花费的时间
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
#8.计数流程级别的事件
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
#9.分析内核工作堆栈
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
#10.跟踪计划器
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
#11.跟踪阻止I / O
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
请访问Brendan Gregg的网站,以了解
上述团队可以产生什么样的输出 。
脚本语法和I / O时序示例通过'-e'开关传递的字符串是bpftrace脚本的内容。 在这种情况下,语法有条件地是一组构造:
<event source> /<optional filter>/ { <program body> }
让我们看一下第七个示例,有关文件系统读取操作的时间:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
我们从
kprobe机制跟踪事件,即,我们跟踪内核函数的开始。
用于跟踪的内核函数是
vfs_read ,当内核从文件系统(“虚拟文件系统”的VFS,内核内部文件系统的抽象)执行读取操作时,将调用此函数。
当
vfs_read开始
执行时 (即在函数完成任何有用的工作之前),bpftrace程序将启动。 它将当前时间戳(以纳秒为单位)保存到名为
st art的全局关联数组中。 关键是
tid ,它是对当前线程ID的引用。
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1.我们从
kretprobe机制中跟踪事件,该事件类似于
kprobe ,只是在函数返回执行结果时调用该事件。
2.跟踪的内核功能是
vfs_read 。
3.这是一个可选的过滤器。 它检查开始时间是否已预先记录。 如果没有此过滤器,则程序可以在读取时启动并仅捕获结尾,从而导致
估计时间为
nsecs-0而不是
nsecs-start 。
4.程序主体。
nsecs- st art [tid]计算自vfs_read函数启动以来经过了多少时间。
@ns [comm] = hist(...)将指定的数据添加到存储在
@ns中的二维直方图中。
comm键是指当前应用程序的名称。 因此,我们将通过命令获得一个直方图命令。
delete(...)从关联数组中删除开始时间,因为我们不再需要它。
这是最终结论。 请注意,所有直方图都会自动显示。 不需要显式使用print histogram命令。
@ns不是特殊变量,因此不会显示直方图。
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
USDT传感器示例让我们使用以下C代码并将其保存在
tracetest.c文件中:
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
通过每秒调用
myclock(),该程序将无限运行。
myclock()查询当前时间,并返回自时代开始以来的秒数。
此处对
DTRACE_PROBE1的调用定义了静态USDT跟踪点。
- 宏DTRACE_PROBE1来自sys /sdt.h。 这样做的官方USDT宏称为STAP_PROBE1 (SystemTap的STAP,这是USDT中支持的第一个Linux机制)。 但是由于USDT与DTrace用户空间传感器兼容, 所以DTRACE_PROBE1只是对STAP_PROBE1的引用。
- 第一个参数是提供者的名称。 我相信这是DTrace遗留下来的痕迹,因为bpftrace似乎并没有做任何有用的事情。 但是,有一个细微差别( 在应用程序328调试问题时发现的 ):提供程序名称必须与应用程序的二进制文件名称相同,否则bpftrace将无法找到跟踪点。
- 第二个参数是跟踪点的名称。
- 任何其他参数都是开发人员提供的上下文。 DTRACE_PROBE1中的数字1表示我们要传递一个附加参数。
让我们确保sys / sdt.h对我们可用,并将程序组合在一起:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
每当达到testprobe时,我们指示bpftrace输出PID和“时间为[数字]”:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
当我们按Ctrl-C时,Bpftrace继续工作。 因此,打开一个新终端并在其中运行
tracetest :
#在新终端
./tracetest
回到带有bpftrace的第一个终端,在那里您应该看到类似以下内容:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
使用glibc ptmalloc的示例内存分配我使用bpftrace来了解为什么Ruby使用这么多内存。 作为研究的一部分,我需要了解glibc的内存分配器如何使用
内存区域 。
为了优化多核性能,glibc内存分配器从OS分配了几个“区域”。 当应用程序请求内存分配时,分配器选择一个未使用的区域,并将该区域的一部分标记为“已使用”。 由于线程使用不同的区域,因此减少了锁的数量,从而提高了多线程性能。
但是这种方法会产生大量垃圾,似乎Ruby中如此之高的内存消耗正是由于此原因。 为了更好地理解垃圾的性质,我想知道:“选择一个不使用的区域”是什么意思? 这可能意味着:
- 每次调用malloc()时 ,分配器都会遍历所有区域并找到当前未锁定的区域。 而且只有当所有这些都被阻止时,他才会尝试创建一个新的。
- 第一次在特定线程上(或在线程启动时)调用malloc()时,分配器将选择当前未阻塞的那个。 如果它们全部被阻止,他将尝试创建一个新的。
- 第一次在特定线程上(或在线程启动时)调用malloc()时,分配器将尝试创建一个新区域,而不管是否存在未锁定的区域。 仅当无法创建新区域(例如,当限制已用尽)时,它才会重用现有区域。
- 我可能还没有考虑更多选择。
文档中没有特定的答案,您可以使用其中的哪些功能选择未使用的区域。 我研究了glibc的源代码,这表明选项3可以做到这一点。 但是我想通过实验来验证我是否正确解释了源代码,而无需在glibc中调试代码。
这是创建新区域的glibc内存分配器函数。 但是您只能在检查限制后才能调用它。
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
我可以使用
uprob跟踪
_int_new_arena函数吗? 不幸的是,没有。 由于某些原因,该符号在glibc Ubuntu 18.04中不可用。 即使在安装调试符号之后。
幸运的是,此功能中有一个USDT传感器。
LIBC_PROBE是
STAP_PROBE的宏别名。
提供程序名称为libc。
传感器名称为memory_arena_new。
数字2表示开发人员指定了2个其他参数。
arena是从OS提取的区域的地址,大小是其大小。
在使用此传感器之前,我们需要
解决问题328 。 我们需要在glibc的名称为
libc的地方创建一个符号链接,因为bpftrace期望库名(否则为
libc-2.27.so )应与提供者的名称
(libc)相同 。
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
现在,我们指示bpftrace挂钩到供应商名称为
libc的 USDT memory_arena_new传感器:
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
在另一个终端中,我们将运行Ruby,它将创建三个不执行任何操作的线程,并在第二秒结束。 由于解释器的全局阻塞,Ruby的
malloc()不应由不同的线程并行调用。
ruby -e '3.times { Thread.new { } }; sleep 1'
返回到带有bpftrace的终端,我们将看到:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
这是我们问题的答案! 每次在Ruby中创建新线程时,无论竞争力如何,glibc都会突出显示一个新领域。
有哪些跟踪点可用? 我应该追踪什么?您可以通过运行以下命令列出所有硬件,计时器,kprobe和静态内核跟踪点:
sudo bpftrace -l
您可以通过执行以下操作列出应用程序或库的所有uprobe跟踪点(功能字符):
nm /path-to-binary
您可以通过运行以下命令列出USDT应用程序或库的所有跟踪点:
/usr/share/bcc/tools/tplist -l /path-to/binary
关于要使用的跟踪点:了解要跟踪的源代码不会有什么坏处。 我建议您研究源代码。
提示:内核中跟踪点的结构格式这是有关内核跟踪点的有用提示。 您可以通过读取文件/ sys / kernel / debug / tracing / events来检查哪些自变量字段可用!
例如,假设您要跟踪对
madvise(...,MADV_DONTNEED)的调用:
sudo bpftrace -l | grep madvise
-会告诉我们可以使用跟踪点:syscalls:sys_enter_madvise。
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
-将为我们提供以下信息:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
根据手册进行Madvise签名:(
无效* addr,size_t长度,int建议) 。 该结构的最后三个字段对应于这些参数!
MADV_DONTNEED是什么意思? 由grep MADV_DONTNEED / usr / include判断,它等于4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
因此,我们的bpftrace团队将成为:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
结论
Bpftrace很棒! Bpftrace是未来!
如果您想进一步了解他,我建议您熟悉
他的领导能力以及Brendan Gregg博客
上2019年的
第一篇文章 。
好调试!