
在过去的一年中,关于微服务的出版物如此之多,以至于浪费时间告诉它是什么以及为什么,所以其余的讨论将集中在如何实现这种架构以及为什么要正确面对它以及遇到什么问题这一问题上。
我们在一个小银行中遇到了大问题:3个python巨石通过大量的同步RPC交互与大量的遗留物相连。 为了至少部分解决同时出现的所有问题,决定切换到微服务架构。 但是在决定采取此步骤之前,您需要回答3个主要问题:
- 如何将整体拆分为微服务以及应遵循哪些标准。
- 微服务将如何相互作用?
- 如何监控?
实际上,这些问题的简短答案将专门用于本文。
如何将整体拆分为微服务以及应遵循哪些标准。
这个看似简单的问题最终决定了整个未来的体系结构。
我们是一家银行,因此整个系统围绕着财务和各种辅助事物的运作而展开。 当然可以通过sagas将金融ACID交易转移到分布式系统中 ,但是在一般情况下,这非常困难。 因此,我们制定了以下规则:
- 符合SOLID中针对微服务的S
- 交易应该完全在微服务中进行-不会对数据库造成破坏的分布式交易
- 为了工作,微服务需要来自其自己的数据库或来自请求的信息
- 尝试确保微服务的清洁度(从功能语言的角度而言)
自然地,同时不可能完全满足它们,但是即使是部分实现也大大简化了开发。
微服务将如何相互作用?
有很多选择,但是最后它们都可以通过简单的“微服务交换消息”抽象出来,但是如果您实现一个同步协议(例如,通过REST进行RPC),则仍然会保留整体的大多数缺点,但是微服务的优点几乎不会出现。 因此,显而易见的解决方案是开始使用任何消息代理。 在RabbitMQ和Kafka之间选择后者,这是为什么:
- Kafka更简单,并提供了单个消息传递模型- 发布-订阅
- 第二次从卡夫卡获取数据相对容易。 这对于在不正确的处理过程中调试或修复错误以及监视和记录非常方便。
- 扩展服务的一种简单明了的方法:在主题上添加分区,启动更多的订户-其余的将由kafka完成。
另外,我想提请注意非常高质量和详细的比较 。
卡夫卡+异步队列允许我们:
- 暂时关闭任何微服务以进行更新,而其余操作不会引起明显后果
- 长时间关闭任何服务,而不必理会数据恢复。 例如,最近的金融化微服务下降了。 2小时后修复完毕,他从卡夫卡(Kafka)取得了原始帐目并处理了所有东西。 像以前一样,没有必要恢复在那里应该发生的事情并手动执行HTTP日志和数据库中的单独表。
- 对销售中的当前数据运行服务的测试版本,并将其处理结果与销售中的服务版本进行比较。
作为数据序列化系统,我们选择了AVRO,为什么-在另一篇文章中进行了介绍 。
但是无论选择哪种序列化方法,了解协议的更新方式都非常重要。 尽管AVRO支持模式解析,但我们不使用它,而纯粹是在管理上做出决定:
- 主题中的数据只能通过AVRO进行写入和读取,主题的名称与方案的名称相对应(并且Confluent采用不同的方法 -他们在注册表的高字节中写入ID AVRO方案,因此它们可以在一个主题中使用不同类型的消息
- 如果您需要添加或更改数据,则会在kafka中使用新主题创建一个新方案,然后所有生产者都切换到新主题,然后订阅者
我们将AVRO电路本身存储在git子模块中,并连接到所有kafka项目。 他们决定不实施计划的集中登记册。
PS:同事选择了opensource选项,但仅使用JSON模式而不是AVRO 。
一些微妙之处
每个订阅者都收到该主题的所有消息
这就是“发布-订阅”交互模型的特殊性-订阅主题时,订阅者将全部收到它们。 结果,如果该服务仅需要一些消息,它将不得不将其过滤掉。 如果这成为问题,则可以创建一个单独的服务路由器,该路由器将在几个不同的主题中安排消息,从而实现不属于kafka的RabbitMQ功能的一部分。 现在,我们在一个线程上有一个python订阅者,每秒处理大约7-5千条消息,但是如果您通过PyPy运行,则速度会提高到11-15千/秒。
限制主题中指针的生命周期
在kafka的设置中,有一个参数会限制kafka“记住”阅读器停止的时间-默认值为2天。 最好将其提高到一周,这样,如果在假期期间出现问题并且2天仍未解决,则不会导致该主题的职位丧失。
读取确认时间限制
如果Kafka阅读器在30秒内未确认读取(可配置参数),则代理会认为出了点问题,并在尝试确认读取时发生错误。 为避免这种情况,当长时间处理消息时,我们发送已读确认而不移动指针。
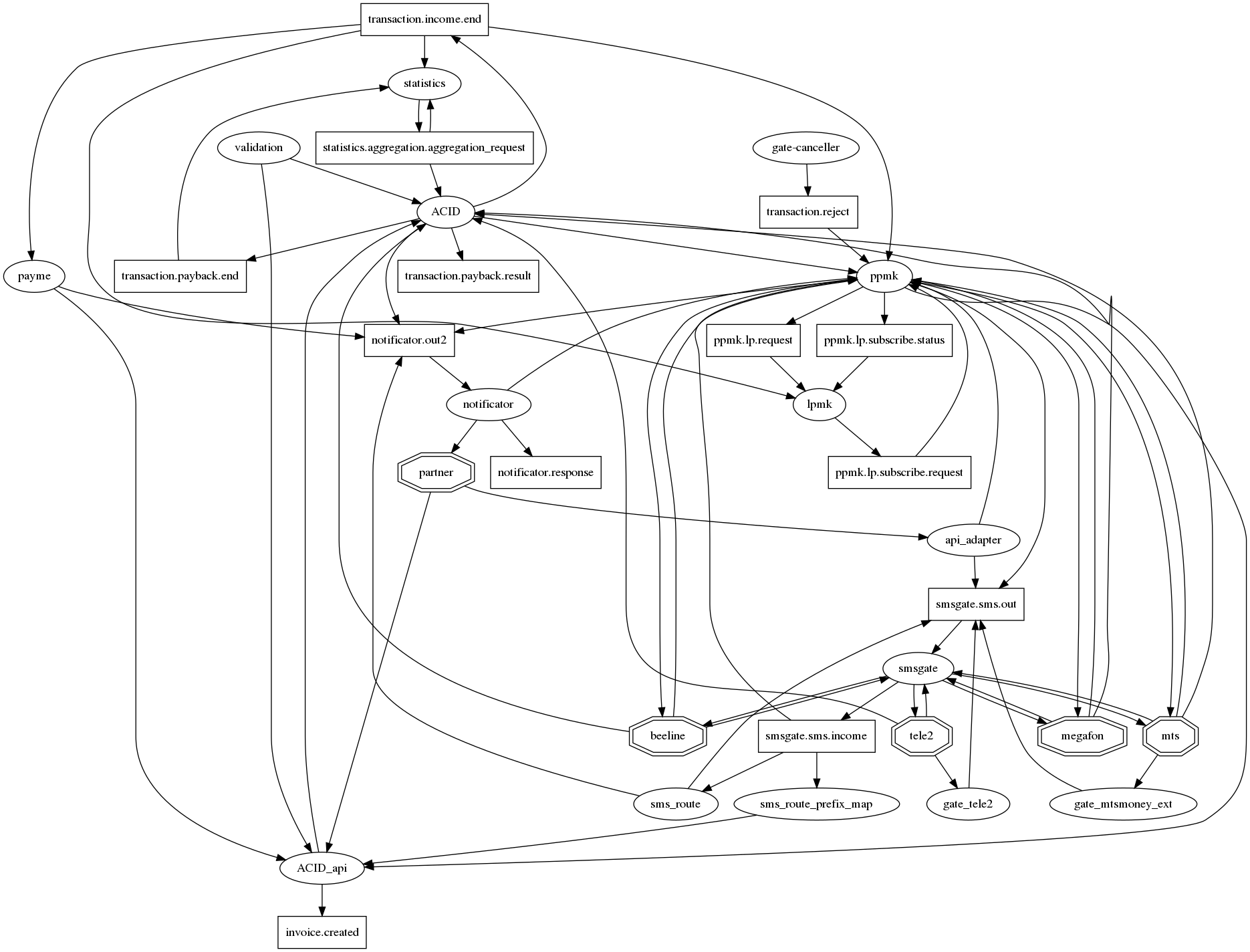
连接图很难理解。
如果您老实地在graphviz中绘制所有关系,那么对于微服务而言,这是传统上的刺猬,它在一个节点中具有数十个连接。 为了至少使它(连接图)可读,我们同意以下表示法:微服务-椭圆,kafka主题-矩形。 因此,可以在一张图上同时显示交互作用的事实及其类型。 但是,a,情况并没有好转。 因此,这个问题仍然悬而未决。
如何监控?
甚至作为整体的一部分,我们都有日志文件和Sentry,但是当我们切换到通过Kafka进行交互并部署到k8s时,日志移到了ElasticSearch,因此我们首先监视了在Elastic中读取订户日志的过程。 没有日志-没有工作。
之后,他们开始使用Prometheus, kafka-exporter对其仪表板进行了一些修改: https : //github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
结果,我们得到了这些图片:
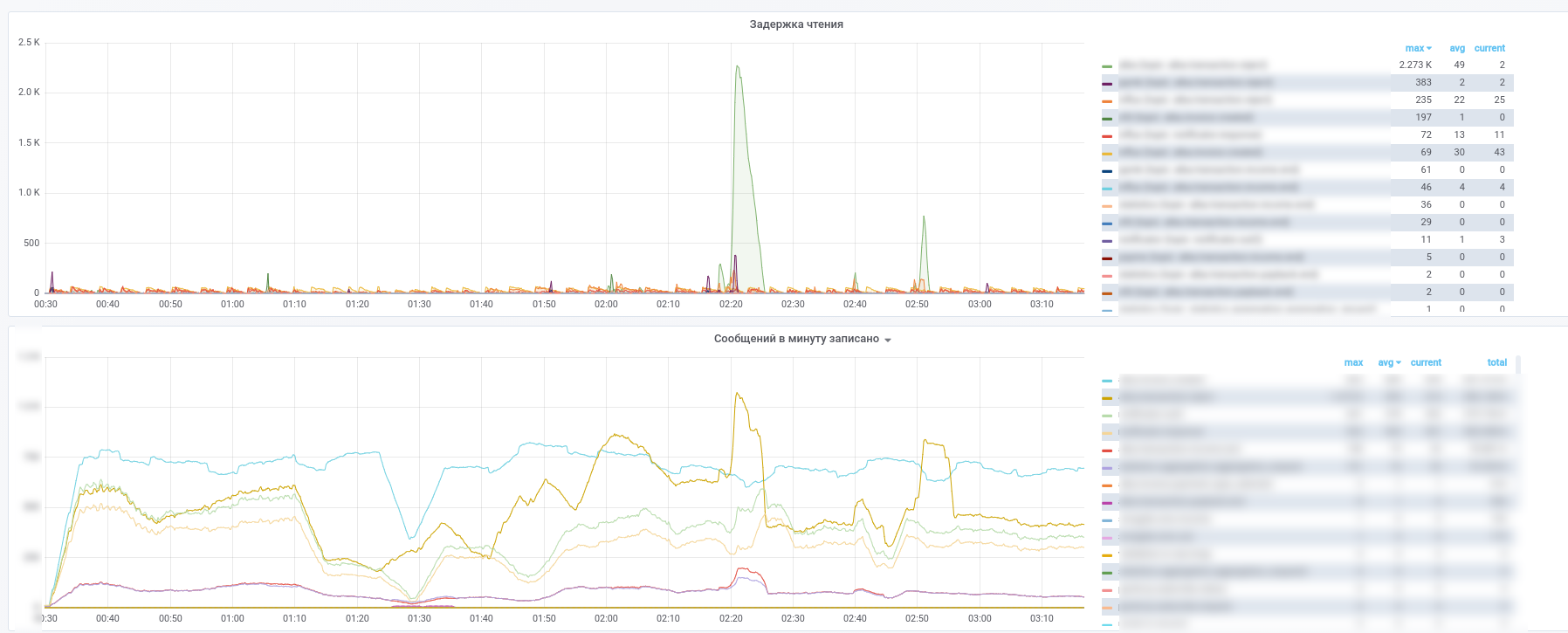
您可以看到哪个服务已停止处理哪些消息。
此外,来自关键(付款交易,合作伙伴的通知等)主题的所有消息都将复制到InfluxDB,该数据库在同一grafana中设置。 因此,我们不仅可以记录消息传递的事实,还可以根据内容进行各种采样。 因此,诸如“服务响应的平均延迟时间是多少”或“今天的交易量与昨天的交易量是否在这家商店中有很大不同”之类的问题总是可以得到解答。
另外,为了简化事件分析,我们使用以下方法:每个服务在处理消息时,都使用元信息来补充它,该信息包含系统显示类型的记录数组时发出的UUID:
- 服务名称
- 此微服务中处理过程的UUID
- 进程开始时间戳
- 处理时间
- 标签集
结果,当消息通过计算图时,消息将丰富有关在图上行进的路径的信息。 事实证明,MQ是zipkin / opentracing的一个类似物,它允许接收一条消息以轻松地在图形上恢复其路径。 当周期出现在图形上时,这将获得特殊的值。 记住一个小服务的示例,该服务的付款份额仅为0.0001%,通过分析消息中的元信息,他可以确定他们是否是付款的发起者,而无需联系数据库进行验证。