几乎所有推荐系统都难以处理新内容或稀有内容-因为只有一小部分用户与之交互。 Daniil Burlakov
在Yandex Inside的报告中分享了一系列在音乐推荐中使用的技巧,并详细介绍了流行的模型奇异值分解(SVD)。
另外,我们有这样的表演者,他们被称为作曲家,通常像粉丝一样被版权持有者放下。 仅莫扎特就“录制”了超过一百万首作品。
大家好! 我叫Daniil Burlakov,我领导着媒体服务方面的建议小组。 今天,我想谈谈在处理“音乐”中的建议时我们要解决的一些问题。
我们有一支很棒的团队,不仅为Yandex.Music提出建议,而且还为所有媒体服务提出建议:这是Kinopoisk,海报。 我们解决的技术问题比建议的多。

今天,我想谈一谈中央产品Yandex.Music,我们最重要和最喜欢的产品是智能播放列表,也许很多人都知道和听过。

我将简要介绍一下它们是什么类型的播放列表以及我们使用的内容。
当天的播放列表被认为是每天都会为您创建的一组曲目,以便即使在没有Internet的情况下您也可以下载和收听它们。 但这对您来说将非常好,与您同在,并且应该每天进行更新并包含一些新内容。 什么适合你。
Deja Vu是一个更有趣的播放列表。 它每周更新一次,其中会有一些您从未听过的曲目,以及您几乎不认识或根本不了解的艺术家。 首映-您可能喜欢的艺术家精选的新产品。

第二个产品是Yandex.Radio。 于2015年推出,我们将继续开发它。
这个想法是允许用户不做任何事情就获得个性化的音频音乐流。 实际上,我按了一个按钮,就得到了一个永无止境的精彩视频,它将使您持续数小时。 与播放列表不同,它可以被标记。 例如,如果您不想在工作中分心,则可以按流派打开广播-摇滚或背景音乐。 或完全个性化的音频流-我们称之为“ On Wave”的广播。

提出这些建议时,我们会遇到什么问题? 我们面临着两个主要问题,这对于大多数推荐系统来说都是非常典型的。 这些是刚加入我们服务的冷用户,我们仍然对他们一无所知,还提供酷内容。 它不仅包括最近出现的曲目,还包括大量的稀有曲目。 Yandex.Music目录包含超过5000万首曲目,其中许多尚未被任何用户收听。 因此,出现了一个问题:不幸的是,即使音轨发出的时间足够长,我们可能对此音轨也不了解,也没有任何统计信息。
当Yandex.Music成为一项国际服务并开始向许多国家/地区传播时,这两个问题都变得尤为严重,并且对我们尤为重要。 进入每个国家/地区时,该国家/地区的本地内容首先变得非常重要。 很明显,当您进入一个新的国家时,忽略本地音乐是很不愉快的。 有必要进行推荐,适当地推荐并了解这种内部音乐的结构。 实际上,在俄罗斯,没有人听以色列的音乐,即使我们有这种音乐的内容,也很少有统计。
让我们来解决这些问题。 让我们从用户冷淡的问题开始。 如何解决?

第一个最简单的解决方案是不向冷用户推荐任何东西。 实际上,解决方案非常简单,您可以询问明确的首选项。 这些是可以提供给用户的众多向导。
在用户收到当天的第一个播放列表之前,我们要求用户经历这样的向导,以表明他的偏好,他想要的一组流派和艺术家。
结果,用户的第一个播放列表变得非常有意义,适合用户,并且很可能从第一个播放列表开始,用户就会爱上他。
不幸的是,这种方法不能总是做到的。

我们的第二个产品Yandex.Radio被认为是不需要用户费力的产品。 他只想来不做任何事就打开音乐。 此外,Yandex.Radio嵌入在许多其他系统中,例如Yandex.Drive,在该系统中,仅迫使用户坐在车上,如果他第一次到达那里,请单击某种向导,这是很奇怪和不便的。
因此,我们走了另一条路。 假设我们从针对普通用户的建议开始,这样,从第一首曲目开始的大多数用户都会获得最大的愉悦感,并且他们喜欢音乐。 并且我们提供非常快速的个性化。 与您收到的播放列表不同,他整天都在您身边,您的60首曲目全都是。 并且,例如,如果我们没有想到您最喜欢的音乐类型是流行音乐(这将是一个很好的开端),那么所有60首曲目都将与您无关,那将是可悲的,而且很可能明天您不会回来
但是,如果我们在收音机上放置了流行音乐的第一首曲目,并且您说您不想听,那么我们会立即为您个性化下一首曲目,并提供其他内容,例如摇滚或其他流派。
实际上,实际上,这两种解决方案在某种程度上解决了冷用户的问题。
类比问题如何解决? 解决方案的第一点,以及关于用户的问题,都不是推荐酷内容。 但是,在这里,与用户不同,内容本身不会拾取,也不会发热。 因此,问题在于,如果我们自己不收集有关他的统计信息,那么将不会发布刚刚发行的艺术家的新产品,而未曾看到其艺术家新闻的用户很可能会感到沮丧。

具有国际内容的类似情况。 我们去了一个新国家,但不推荐这样做,实际上忽略了此内容显然不适合我们。
第二种解决方案,如果我们完全以类推的方式行事,则平均建议采用某种方式。 最简单的类比是连续向所有人推荐此内容,或将其推荐为流行音乐。 通常情况下,可以选择推荐的声音通常并不十分清楚。 这可以说是武力的流行音乐,但是几乎不能说所有音乐都如此相似,因此看起来就像流行音乐。 因此,如果您在流行音乐之间找到贝多芬作品,那么大多数人不太可能会乐于接受。 因此,该解决方案也不适合我们。

轨道还有什么呢? 除了曲目本身,版权持有人还提供了许多元数据,例如曲目的类型,艺术家,专辑和发行年份。 让我们过去。 如何使用它们? 例如,流派。 体裁是一种很好的信息,可以让我们或多或少地猜测。 例如,它解决了贝多芬或唱机的问题,而这可能是偶然出现在广播中的某人身上的:我们知道这首歌的曲风,不太可能将它滑到不适合的人身上。
但不幸的是,他不允许建立好的建议,因为体裁的概念本身是很主观的,并且不允许在此基础上建立任何好的建议。 自然,流派中有许多子流派,这正是版权所有者向我们发送的内容。

第二个问题是,普通人通常可以命名十几种类型,而版权所有者会向我们发送成千上万种类型,这是一个很大的问题,无法以某种方式将它们分组,在它们之间找到相似的类型,依此类推。 不幸的是,这个问题并不总是能够解决。
显然,不幸的是,版权所有者经常感到困惑并犯错。 而且,我们经常遇到问题,并且有报告称我们收集了广播摇滚中流行的曲目,而版权所有者将摇滚流派放在了摇滚上。 以此类推,我们收集爵士乐和其他广播电台。 而且我们经常有用户报告要求予以纠正,因为有错误的音轨已经飞到这些无线电台。
我想提供给您猜测曲目的类型。
这不是电影配乐。 这是金属。 当他们向我们发送此类标记时,我们遇到了一个大问题。
我建议转到下一部分,谈论该曲目的表演者。 我已经说过,有一个问题,那就是出现了新的艺术家,新的曲目或专辑,应该建议这样做。 特别是关于艺术家的信息将永远为我们提供帮助。 我们知道用户已经听过这位艺术家的音乐,因此我们可以向他推荐他。 我们照做。 但是,也有困难。 例如,如果我们对艺术家本人一无所知,或者用户不听他的话,那么该曲目所具有的信息以及该艺术家就不会告诉我们任何信息。 罕见的曲目也是如此。 有一首罕见的曲目来自一位罕见的艺术家,我们得知现在这首罕见的曲目已归他所有。 不幸的是,再次没有太多的信息可以使他以某种方式推荐给其他不熟悉他的工作的人。

第二个问题是封面和混音。 再次,卑鄙的版权所有者在这里介入并且经常犯错误。 尤其是,当我们拥有原始曲目及其封面时,版权所有者通常不会费心用不同的方式来命名这些曲目,以表明其中一个是混音,甚至只是为它们放下不同的艺术家。
我想向您提供两条轨道,以便了解被称为完全相同的轨道的声音有何不同。 因此,我们得到了两个可以称为相似的音轨,它们具有相对相似的节奏,相对相似的文本,但是它们是不同的。 对我们来说,这是一条相同的轨道,因为它的名称,艺术家和其他一切都完全一样。
另外,我们有如此卑鄙的表演者,他们被称为作曲家,通常像粉丝一样被版权持有者放下。 仅莫扎特就“录制”了超过一百万首作品。 显然,对于古典音乐爱好者来说,这是不可能的。 如果用户说他喜欢莫扎特,那么我们拥有数百万首曲目,各种重演标准古典旋律。 结果,我们几乎无能为力。

我想进一步告诉您如何解决此问题,但是首先让我们放宽我们的要求。 我们想推荐一个没人听过的曲目,现在让我们考虑如何推荐那些很少见的曲目。 协作过滤在这里为我们提供了帮助。 它是如何工作的,最终我们会得到什么?
首先,我们需要建立一个用户评分矩阵,在线上会有用户,列上会有轨迹,在列和线的交点处会有评分。 很显然,对于大多数矩阵我们都不了解用户反馈,用户甚至无法听完我们的整个目录。
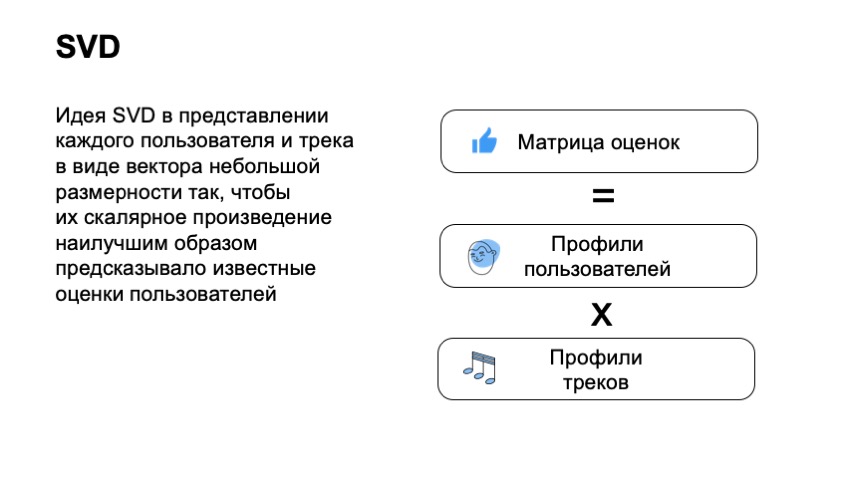
使用此矩阵,我们希望用户和轨道将足够短的小向量关联起来,以便用户向量和项目向量的标量积可以很好地预测用户的评分。 因此,对于每个项目和每个用户,我们都必须找到两个向量,以便它们的最终产品可以最好地预测我们的估计。 例如,如果在这种情况下,我们说用户喜欢该轨道,则为0;如果不喜欢,则为0。在这种情况下,我们可以实际应用标准技术SVD分解,并为用户和轨道获得最佳矢量。

这给了我们什么? 这为我们带来了下一个优势。 对于大多数方法,如果没有人一起听,我们不能说两条音轨是相似的。 通常,方法的重要部分是基于这样一个事实,即我们有一些用户与项目A和B进行了交互,因此我们发现他们很相似。 即使没有用户一起听两个音轨,以SVD形式进行的协作过滤也使我们能够做到这一点。 他们使我们能够对其进行很好的评估。 这是第一个优点。
这给了我们什么? 有了跟踪向量,我们可以将其推荐给更广泛的人群,并推荐不太受欢迎的跟踪。 最重要的是,我们仍然可以获得轨迹的矢量表示,使用它非常方便,您可以使用它快速搜索相似的轨迹。
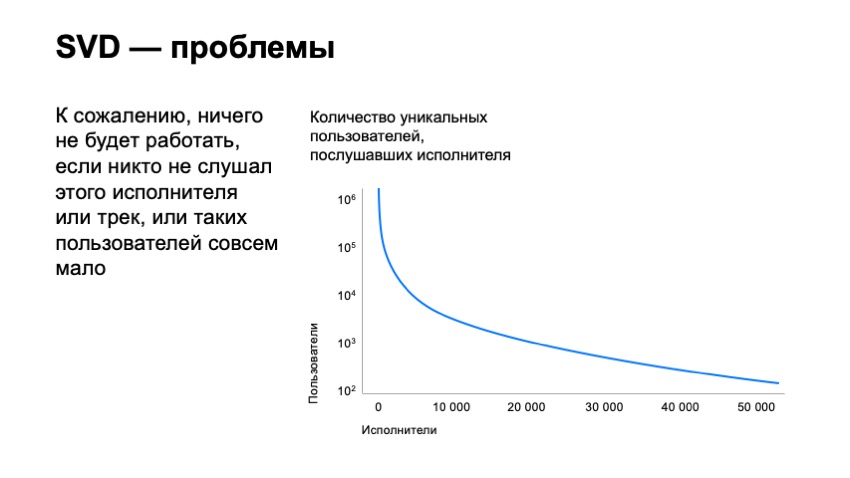
但是,这不能解决我们所有的问题。 我们只稍微移动了我们可以推荐的曲目数量栏。 如果我们建立一个收听表演者的用户数量的图表,实际上按照表演者的受欢迎程度对表演者进行排序,我们将看到数以百万计的用户正在收听我们服务中表现最好的表演者。 如果我们已经看过这些艺术家的千分之一的位置,那么将只有一千个用户。 如果我们什至只看第50,000位艺术家,将只有一百个用户。 显然,他的曲目只有几十个听过他的用户,因此实际上不可能推荐他们,因为此类曲目的SVD矢量将极其不稳定并且无法正常工作。
我们如何解决这个问题? 我们想要什么?
我们想采用一条我们不了解的罕见的新曲目,例如,来自以色列的罕见曲目,并且我们想要为其获取某种矢量表示,这与我们的SVD矢量非常相似,使用起来非常方便并提出建议。
我们唯一没有考虑的是该音轨本身的音频。 多亏了音频,我们可以推荐曲目。 我们如何使用音轨获得SVD向量。 我们要做的第一件事是小的转换。
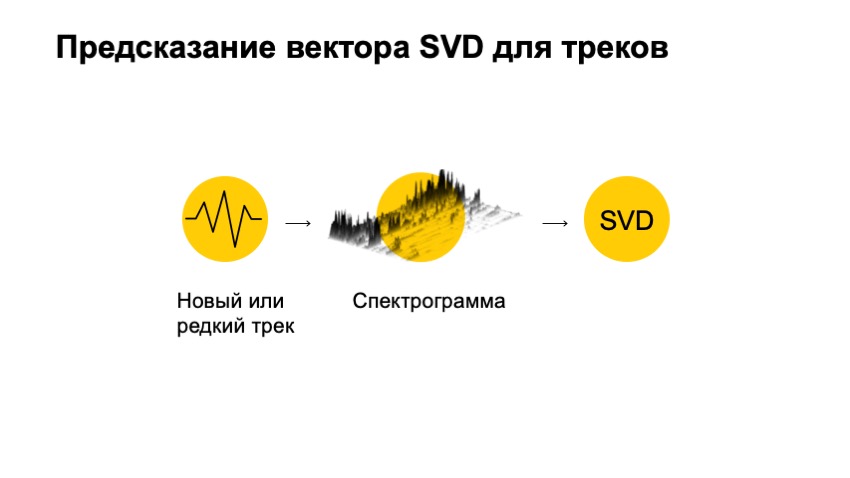
本质上是音频? 您可以想象一个电压图。 无论如何,这是一维数字集,使用起来非常不便,它既大又长,本身就没有意义。 但是我们可以检查他的频谱,非常简短地对他进行傅立叶变换,以了解他看起来像一种特定的正弦曲线。 他看起来像什么正弦曲线。 并查看此图中有多少正弦曲线,并对每个频率进行相同的操作。
当然,如果我们对整个曲目进行此操作,我们将获得一些信息,但是很少,它会说的很少,因为例如,曲目的各个部分之间的过渡对于音乐非常重要,而在频谱中,我们会在非常大的频率变化中具有间接形式,该变化应与秒,分钟相关,这非常不便,并且频谱形式的表示也很差。
因此,我们走得更远,将赛道切成小块。 在每件作品中,我们都进行了这样的转换。 结果,我们得到了这样一张图片,我以三维形式绘制了它,这样就更清楚地看到我们在某个时间和高度上在一个平面上展开了频率-当时的能量。 他们得到了所谓的频谱图。
我们如何使用这个频谱图来获得SVD向量? 在我们这个时代,答案是平庸的:让我们采用一个神经网络并对其进行训练,以预测SVD向量。
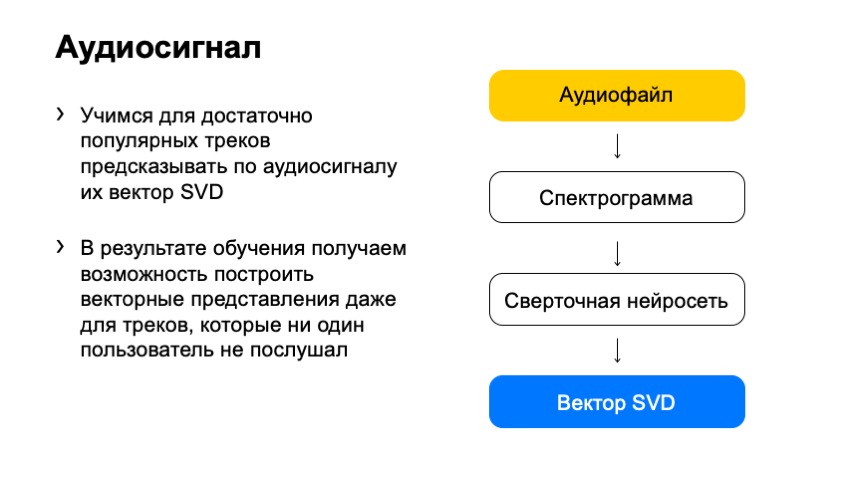
我们做到了。 我们选择了什么作为培训? 那些SVD跟踪我们确定的向量。 我们特别选择了受欢迎的曲目,它们的反馈足够大,因此SVD矢量已经完全安静了,我们可以清楚地对其进行计算。 并且-他们训练了神经网络来预测这些向量。
我们到底得到了什么? 可以追踪并预测其SVD向量的网络。 我们有一个非常简单的解决方案,效果很好。
我想展示一个我们拔出的音轨的例子。 这些轨道之一很受欢迎,并且可以非常准确地识别其SVD向量,而第二个则非常不受欢迎。 我想建议您猜测这些曲目中哪个更不受欢迎,哪个更受欢迎。
第一轨:
第二轨:
答案
第一首曲目更受欢迎。 如果您查看了解此曲目并可以在没有建议的帮助下自己找到的听众数量,那么第一曲目可以被超过1000个用户找到,第二曲目-仅10个用户。而且我们如何应用我们的技术,我们无法甚至尝试推荐这首单曲,因为没有什么值得推荐。 我们只能将其提供给这10个用户。
当我们将其应用到生产中时,我们得到了很多好评。 在我们能够应用这项技术之后,其中之一的播放列表“ Deja Vu”已得到显着改善,其中我们必须在其中嵌入用户未收听的曲目,为用户组织发现。
当然,我们在进入新国家时应用了此方法,并获得了许多积极的评价。 他们指出,播放列表知道如何个性化。 此外,以色列的编辑很惊讶俄罗斯在以色列的演出并不大量推荐俄罗斯艺术家,而是推荐本地音乐和国际音乐。

关于我们设法实现的数字。 最重要的是,我们希望在音频流中实现为用户提供新产品的数量,从而使其变得更加多样化。 , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . 谢谢您的关注。