哈Ha
在发布
2017年和
2018年文章的排名之后,下一个想法很明显-收集所有年份的通用排名。 但是仅收集链接将是陈旧的(尽管也很有用),因此决定扩展数据处理并收集一些更有用的信息。

额定值,统计信息和一些源代码在Python的帮助下。
资料处理
那些对结果立即感兴趣的人可以跳过本章。 同时,我们将了解其工作原理。
作为源数据,有一个大致为以下类型的csv文件:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
此表格中所有文章的索引占用42 MB,并且收集它花了大约10天的时间才能在Raspberry Pi上运行脚本(下载以暂停的方式进入一个流,以免服务器超载)。 现在,让我们看看可以从所有这些数据中提取什么数据。
现场观众
让我们从一个相对简单的例子开始-我们将评估这些年来网站的受众群体。 粗略估计,您可以使用文章评论的数量。 下载数据并显示评论数的图表。
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
数据看起来像这样:

结果很有趣-事实证明,自2009年以来,该网站的活跃观众(对文章发表评论的人)几乎没有增长。 尽管也许所有IT员工都在这里?
由于我们是在谈论受众,因此回想一下Habr的最新创新-添加网站的英文版很有趣。 列出链接中带有“ / en /”的文章。
df = df[df['link'].str.contains("/en/")]
结果也很有趣(垂直比例尺特别保持不变):

出版物数量激增始于2019年1月15日,那时
Hello world的发布! 但是,
还是英文的Habr,这3篇文章已经出版了几个月了:
1,2和
3 。 可能是Beta测试?
标识符
在前面的部分中我们没有涉及的下一个有趣的点是文章标识符和发布日期的比较。 每篇文章的链接类型
均为habr.com/en/post/N ,文章编号是横切的,第一篇文章的标识符为1,而您正在阅读的标识符为441740。看来一切都很简单。 但事实并非如此。 检查日期和标识符的对应关系。
将文件上传到Pandas Dataframe,选择日期和ID,然后绘制它们:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
结果是令人惊讶的-标识符并非总是排成一排,如最初所假设的那样,存在明显的“异常值”。
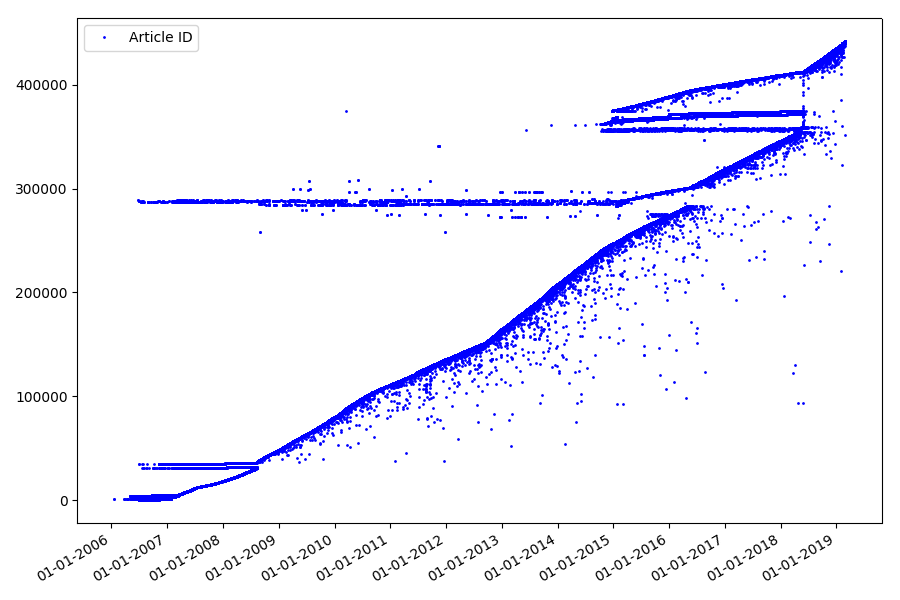
部分由于这些原因,观众对2017年和2018年的收视率有疑问-解析器未考虑ID为“错误”的此类文章。 为什么这么难说,却没有那么重要。
有关标识符的有趣之处是什么? 有一个假设我无法正式证明,但这似乎很明显。 在撰写本文草案时会分配一个标识符,而发布日期显然会晚些。 有人在同一天发布文章,后来有人发表材料。 为什么要这样? 让我们将标识符放在X轴上,并将日期垂直放置,然后更详细地查看图表的一部分:
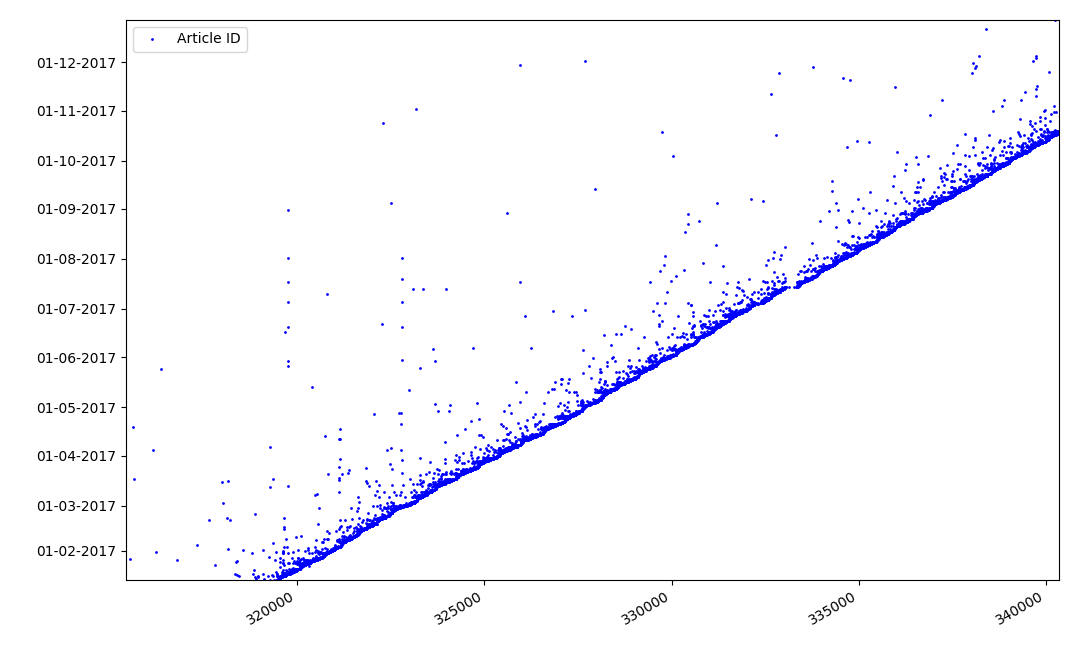
结果-我们在实线上方看到了点云,这向我们显示
了文章创建期间的时间分布。 如您所见,最大间隔为1-2周。 几乎所有文章的撰写都在不超过一个月的时间内完成,尽管有些文章是在草稿创建后的几个月发布的(当然,这不能保证作者每天都要写几个月的文章,但是结果仍然很有趣)。
出版日期和时间
一个有趣的,尽管直观的观点是文章发表的时间。
输出工作日统计信息:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
工作日文章数量与发布时间的依赖关系:
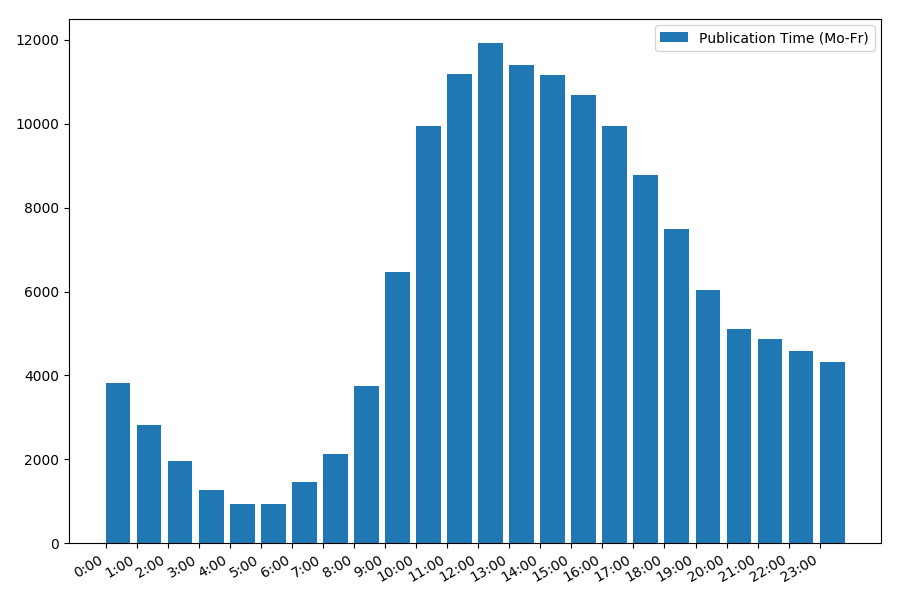
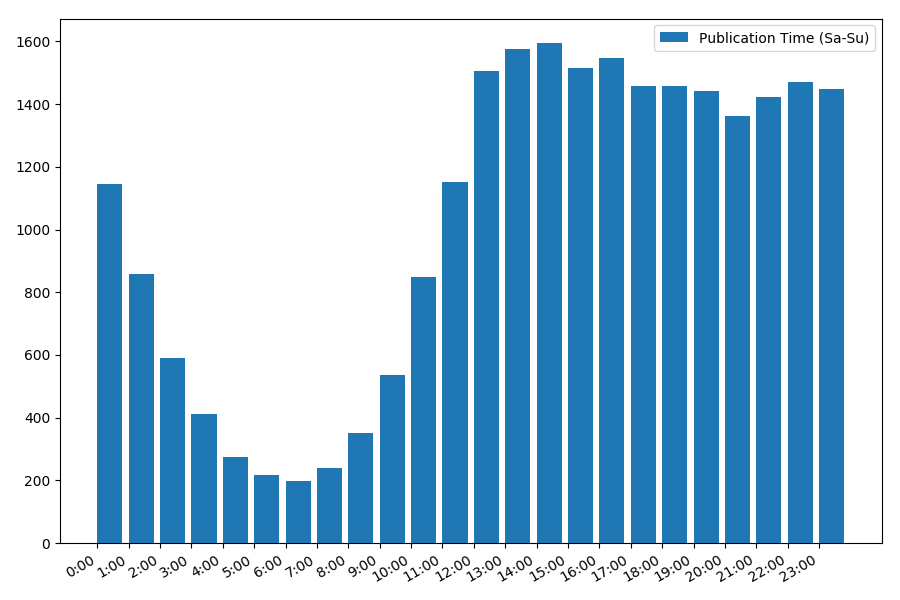
图片很有趣,大多数出版物都在工作时间上。 仍然很有趣,对于大多数撰写文章的作者来说,这是主要的工作,还是只是在工作时间做文章? ;)但是周末的分发时间表却有所不同:
由于我们在谈论日期和时间,因此让我们按星期几查看平均观看次数和文章数。
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
结果很有趣:
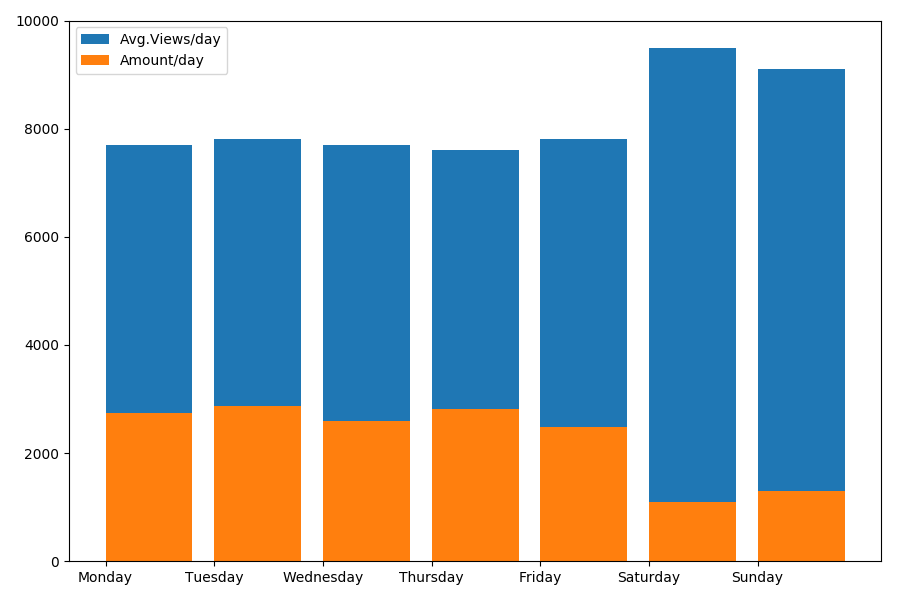
如您所见,周末发表的文章明显减少。 但是,每篇文章都有更多的观点,因此在周末发布文章似乎非常可取(正如在
第一部分中发现的那样,文章的有效期不超过3-4天,因此前两天非常关键)。
这篇文章可能太长了。
第二部分结尾。