
我将分享一个有关小项目的故事:如何在评论中查找作者的答案而又不知道帖子的作者是谁。
我从对机器学习的知识很少的时候就开始了我的项目,我认为这里的专家没有什么新鲜的。 从某种意义上说,该材料是不同文章的汇总,在其中,我将告诉您它是如何完成任务的,在代码中,您可以找到一些有用的自然语言处理小知识和技巧。
我的原始数据如下:一个包含250万个媒体资料和3950万个评论的数据库。 对于一百万个帖子,无论是哪种方式,材料的作者都是已知的(该信息或者存在于数据库中,或者通过间接分析数据获得)。 在此基础上,从标记的215K条记录创建
了一个数据集。
最初,我使用了自然智能发出的基于启发式的方法,并通过全文搜索或正则表达式将其转换为sql查询。 最简单的文本示例为:“谢谢您的评论”或“谢谢您的好评”,这是99.99%的案例中的作者,以及“谢谢您的工作”或“谢谢!” 通过邮件发送材料。 谢谢! -普通审查。 通过这种方法,只有明显的巧合可以被滤除,除了平庸的错别字或作者与评论员对话时。 因此,决定使用神经网络,这个想法并非没有朋友的帮助。
一个典型的评论序列,作者是哪个?
确定文本音调的方法作为基础,对于我们来说,任务很简单,分为两类:作者和作者。 为了训练模型,我使用了Google的一项
服务 ,该
服务为虚拟机提供了GPU和Jupiter笔记本界面。
在Internet上找到的网络示例:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
在清除html标签和特殊字符的行上,它们给出了大约65-74%的准确度,与扔硬币没有太大区别。
有趣的一点是,通过
pad_sequences(x_train, maxlen=max_len, padding='pre')的输入序列的比对在结果上产生了显着差异。 就我而言,最好的结果是padding ='post'。
下一步是使用lemmatization,它立即使准确性提高了80%,并且可以进一步进行处理。 现在主要的问题是正确清除文本。 例如,单词“谢谢”中的错别字被转换(打字频率是按使用频率选择的)成这样的正则表达式(这种表达式已经积累了一半到两打)。
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
在此,我要特别感谢那些礼貌的人,他们认为有必要在每个句子中加上这个词。
减少错别字的比例是必要的,因为 在lemmatizer的出口处,他们说了奇怪的话,我们失去了有用的信息。
但是有一线希望,我厌倦了拼写错误,处理了复杂的文本清理,我使用了单词的矢量表示-word2vec。 该方法允许将所有错别字,错别字和同义词翻译成紧密间隔的向量。

单词及其在向量空间中的关系。
清理规则得到了显着简化(啊哈,讲故事的人),所有消息,用户名都被分为句子并上传到文件中。 重要的一点:由于我们的评论者的简短,为了构建高质量的矢量,需要更多的上下文信息,例如来自论坛和Wikipedia的信息。 在生成的文件上训练了三种模型:经典word2vec,Glove和FastText。 经过多次实验,他最终选择了FastText,因为在我的案例中,FastText是质量上最明显的词簇。
所有这些更改带来了84-85%的稳定精度。
型号范例 def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
和
代码中的另外6个模型。 有些模型是从网络中获取的,有些是独立发明的。
注意到在不同的模型上有不同的注释,这促使该想法使用模型集合。 首先,我手动组装整体,选择最佳模型对,然后制造一个发电机。 为了优化穷举搜索,我以格雷码为基础。
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
随着合奏,“生活变得更加有趣”,当前模型准确性的百分比保持在86-87%,这主要与数据集中某些作者的劣质分类有关。

我遇到的问题:
- 不平衡的数据集。 作者的评论数量明显少于其他评论者。
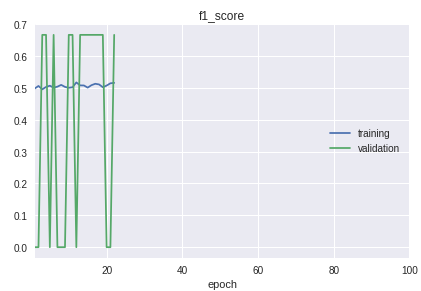
- 样本中的类按严格顺序排列。 最重要的是,分类的质量在开始,中间和结束方面有显着差异。 在学习过程中按f1小节的时间表可以清楚地看到这一点。
对于该解决方案,制造了一辆自行车,用于将其分为训练样本和验证样本。 尽管实际上在大多数情况下,来自sklearn库的train_test_split过程就足够了。
当前工作模型图:

结果,我从简短的评论中得到了一个对作者充满自信的定义的模型。 进一步的改进将与清理并将真实数据的分类结果转移到训练数据集中有关。
所有带有附加说明的代码都在
存储库中 。
附言:如果您需要对大量文本进行分类,请查看“非常深的卷积神经网络”
VDCNN模型 (在keras上
实现 ),这是ResNet的文本类似物。
所用材料:
•
机器学习课程概述•
使用卷积进行卷积分析•
NLP中的卷积网络•
机器学习指标https://ld86.imtqy.com/ml-slides/unbalanced.html•
外观模型