
迄今为止,任何学习过神经网络课程的学生都可以识别朝鲜语字符。 给他一个样品和一台带视频卡的计算机,过一会儿,他将带给您一个可以识别几乎没有错误的韩文字符的网络。
但是这样的解决方案将具有以下缺点:
首先 ,大量必要的计算会影响运行时间或所需的能量(这对于移动设备非常重要)。 确实,如果我们要识别至少3000个字符,则这将是网络最后一层的大小。 如果该层的输入至少为512,那么我们得到512 * 3000的乘法。 太多了
其次 ,大小。 与上一个示例相同的最后一层将重512 * 3001 * 4字节,即约6兆字节。 这仅是一层,整个网络将重达数十兆字节。 显然,这对于台式计算机来说不是什么大问题,但是并不是每个人都愿意在智能手机上存储如此多的数据以识别一种语言。
第三 ,这样的网络将在非韩文字符但仍用于韩文文本的图像上产生不可预测的结果。 在实验室条件下,这并不困难,但是对于技术的实际应用而言,必须以某种方式解决该问题。
第四 ,问题在于字符数:3000很可能足以区分餐厅菜单中的牛排和海参,但有时文字更复杂。 训练大量字符的网络将很困难:不仅速度较慢,而且训练样本的收集也将存在问题,因为字符的频率大约呈指数下降。 当然,您可以从字体中获取图像并对其进行扩充,但这不足以训练一个好的网络。
今天,我将告诉您我们如何解决这些问题。
韩文写作如何运作?
韩国文字韩文是中国文字和欧洲文字之间的交叉。 从表面上看,这些是类似于象形文字的方形字符,在文本的一页上,您可以算出一百多个独特的字符。 另一方面,它是语音记录,即基于声音的记录。 有一个包含24个字母的字母(此外,您还可以计算diffraphs和diphthongs)。 但是,与拉丁字母或西里尔字母不同,声音不是成行书写,而是组合在一起。 例如,如果我们以相同的方式编写,则短语“ Hello,Habr”可以用以下三个代码块编写:
每个块可以包含两个,三个或四个字母。 在这种情况下,辅音总是先出现,然后是一个或两个元音,最后可能是另一个辅音。 有几种不同的方法可以将字母组合成块,例如,在不同的块中,第二个字母将位于不同的位置。
下图显示了两个块,它们一起构成单词“ Hangul”。 每个块的第一个字母用红色表示,元音用蓝色突出显示,最后辅音用绿色突出显示。
图片来源:Wikipedia。修改韩文区块
也就是说,事实证明可以用以下公式描述一个韩文块:Ci V [V] [Cf],其中Ci是初始辅音(可能是双音),V是元音,Cf是最终辅音(也可以是双音)。 这样的表示方式不便于识别,因此我们对其进行了更改。
首先,组合两个元音。 我们得到公式Ci V'[Cf],其中V'-考虑到第二个字母的缺失,用于组合字母的所有可能选项。 由于该语言中有10个元音,因此可以期望得到10 *(10 + 1)个选项,但实际上并非所有选项都可行,因此只能获得21个。
此外,最后一个字母可能不是。 在结尾处添加许多空字母。 然后,我们得到公式Ci V'Cf *。 因此,事实证明,现在的韩国符号始终由三个“字母”组成。 您可以学习网格。
我们建立一个网络
这个想法是,我们不会识别整个字符,而是会识别其中的各个字母。 因此,我们得到了三个较小的softmax,而不是最后一个巨大的softmax,每个大约几十个大小。 它们对应于音节中的第一,第二和第三“字母”。 结果,我们得到了以下架构:
可点击的图片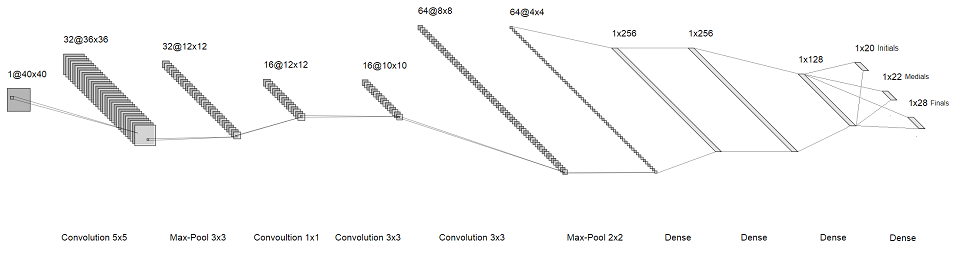
我们训练并在单独的样本上运行。 质量好,网格速度快,重量轻。 让我们尝试将其从实验室带到现实世界。
我们解决问题
我们马上就会遇到第一个问题:有时输入的字符根本不是韩文,并且它们上的网络的行为极其无法预测。 当然,您可以训练另一个网络,该网络将朝鲜街区与其他地区区分开来,但我们将使其变得更容易。
让我们做与处理第三组字母相同的操作:添加缺少字母的输出。 然后,符号公式将如下所示:Ci * V'* Cf *。 在训练集中,我们将添加各种垃圾-汉字,不正确切割的字符,欧洲字母,并且我们将指导网络在其上标记三个空字母。
我们训练,测试。 它有效,但问题仍然存在。 事实证明,例如,此类图像经常掉入网格中:
这是正确的单引号韩国语块。 很明显,在它们上,网络可以完美地找到该块所组成的所有三个字母。 那只是图像不正确,我们需要发出信号。 在图像中返回空字母是错误的。 让我们尝试应用已经证明是好的方法:再添加两个输出以识别此类粘性标点。 当图像中没有多余的内容时,它们中的每一个都会有一个额外的输出,但是除此之外,有必要为情况“有一个标点符号,但它未被识别,可能是垃圾”增加一个输出。
训练有素 在这样的网格上,识别标点符号很不好:它可以将逗号和方括号区分开来,但是从点上来说已经很困难了。 您可以增加网格的复杂性,但不想这样做。 稍后我们将处理对标点符号的识别,但是现在我们将简单地指出是否存在标点符号。 这个网格学得很好。
我们找出了粘连的标点符号,但是相反,如果图像中缺少部分键怎么办? 原来有两个字符,但是我们错误地将其切成字符:
这里的网络没有任何问题,决定了中心字母。 如果我们的任务是仅识别一部分字符,这将是非常有用的品质,但是在现实世界中,这将是有害的:当我们错误地将字符串切成字符时,我们必须在上面传递此信息,因为否则,剩下的部分会被识别为某种标点符号,结果文本中将有一个额外的字符。
为了解决这个问题,我们将使用许多年前一些旧实验的结果。 通过字母识别朝鲜语字符的想法是很久以前出现的,甚至在神经网络时代之前就进行了首次尝试,但是它们并未得到实际应用。 但是从那以后,有趣的事情仍然存在:
- 标记出每个块都有字母的位置。
- 高质量(尽管快速)从符号中切出这些字母。
清除灰尘后,借助这种产品,我们将生成足够数量的此类有问题的图像,而无需包含字母之一,并且我们将特别地教导网络以回答它们是空字母。
仅此而已,识别韩文字符再也没有问题,但是生活再次陷入困境。
事实是,除韩文字符外,韩语文本还包含大量其他字符:标点符号,欧洲字符(至少为数字)和汉字。 但是它们自然发生的频率要少得多。 我们将它们分为两组:象形文字和其他所有内容,我们将为它们中的每一个训练网格。 我们将创建一个简单的分类器,根据用于识别韩文字符和其他某些符号(首先是几何符号)的网络结果,将回答是否至少需要启动其中一个,如果需要,则回答哪个。 您需要识别一些欧洲字符,因此网格会很小,但是对于象形文字来说……它可以节省它们在文本中很少发现的位置,因此让我们扭转分类器的位置,使其很少建议识别它们。
通常,使用这两个网格,在不是训练她的符号的图像中会出现适当答案的问题,但是我们将再次讨论如何解决此问题。
进行实验
第一个 。 有两个图像库,我们称它们为“真实”和“合成”。 实数由从扫描文档获得的实像和合成-由字体获得的图像组成。 在第一个库中,有2374个块的图像(其余图像很少见),从字体中我们得到了所有可能的11172个字符。 让我们尝试在Real上的块上训练网络(我们将从两个库中获取图像),并在仅Synthetic上的块上进行测试。 结果:

也就是说,在大约60%的情况下,网络能够识别出那些块,这些块在训练过程中根本看不到。 如果不是因为一个问题,质量本来可以更高:最后一个字母中有非常少的字母,并且在训练过程中,网络中几乎看不到其中的块图像。 这解释了最后一栏中的低质量。 如果有可能以不同的方式选择我们要研究的2374个块,那么质量很可能会明显更高。
第二个 。 将我们的网络与一个“正常”网络进行比较,“正常”网络的末尾具有softmax。 我想将其尺寸设置为11172,但是对于稀有块我们找不到足够数量的真实图像,因此我们将自身限制为2374。 该网络的质量和速度取决于隐藏层的大小。 我们只会在Real上授课,在Real上进行测试(当然,在另一部分上)。

也就是说,即使我们将自己限制为仅识别2374个块,我们的网络也更快且质量处于同一水平。
第三 。 假设我们能够在11172个韩国街区中找到一个庞大的基地。 如果我们训练一个带有softmax的网络,它将按时工作多长时间? 进行所有实验都很昂贵,因此我们只考虑具有256个隐藏层大小的网络:

我们得到结果
没有他们,什么也不会发生
我对这个想法的原始作者我的同事朱拉·朱利宁(Jura Chulinin)表示感谢。 它在俄罗斯
获得了专利 ,此外,美国专利局(USPTO)也
提出了类似的申请。 非常感谢开发人员Misha Zatsepin实施了所有这些步骤并进行了所有实验。
尤里·瓦特林
复杂脚本小组负责人