数据可视化和分析当前在电信行业中广泛使用。 特别是,分析高度依赖于地理空间数据的使用。 也许是由于电信网络本身在地理位置上分散。 因此,分析这种分散体可能具有巨大的价值。
资料
为了说明k均值聚类算法,我们将使用纽约的免费公共WiFi地理数据库。 该数据集可在纽约市开放数据处获得。 具体而言,k均值聚类算法用于基于纬度和经度数据形成WiFi使用集群。
使用编程语言R从数据集本身提取纬度和经度数据:
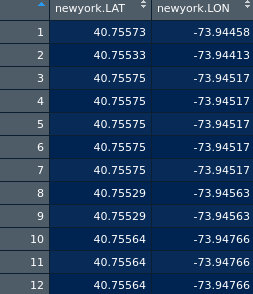
这是一条数据:
我们确定簇数
接下来,我们使用下面的代码确定簇的数量,该代码在图形中显示。
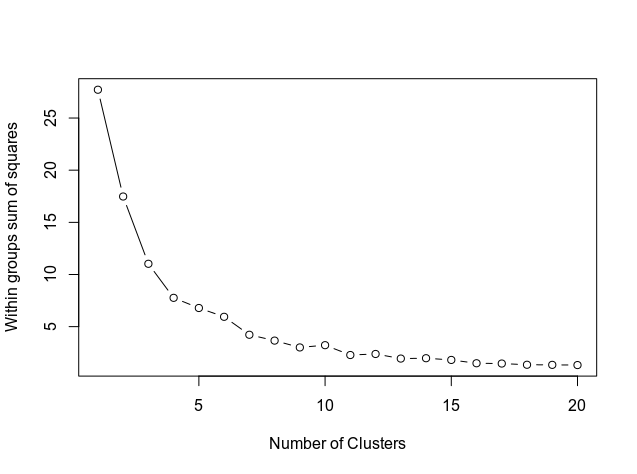
该图显示了曲线如何在11点附近对齐。因此,这是将在k均值模型中使用的簇数。
K均值分析
K-均值的分析如下:
newyorkdf数据集包含有关纬度,经度和聚类标签的信息:
> newyorkdf
newyork.lat newyork.lon fit.cluster
1 40.75573 -73.94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
...
80 40.84832 -73.82075 11
这是一个清晰的例子:
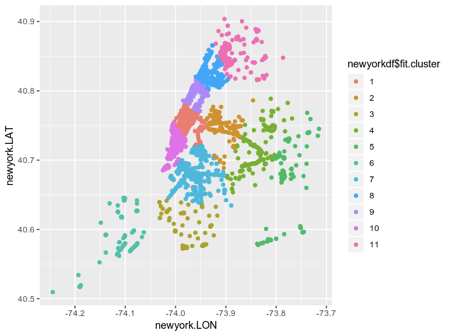
该插图很有用,但是如果将其覆盖在纽约地图上,则其渲染将更有价值。

这种类型的群集为城市中的WiFi网络的结构提供了一个很好的主意。 这表明群集1标记的地理区域显示了大量的WiFi流量。 另一方面,群集6中较少的连接可能表示WiFi流量较低。
仅凭K-Means群集无法告诉我们特定群集的流量为何偏高或偏低。 例如,当群集6的人口密度较高,但互联网速度较低时,连接数将减少。
但是,此聚类算法为进一步分析提供了极好的起点,并有助于收集其他信息。 例如,以该地图为例,您可以建立有关单个地理集群的假设。 原始文章在
这里 。