大家好! 春天来了,这意味着
距离Python开发人员课程开始还剩不到一个月的时间。 我们今天的出版物就是致力于这一过程的。

 任务:
任务:-了解Python的内部结构;
-了解构造抽象语法树(AST)的原理;
-在时间和内存上编写更有效的代码。
初步建议:-对解释器的基本了解(AST,令牌等)。
-Python知识。
-C的基本知识。
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
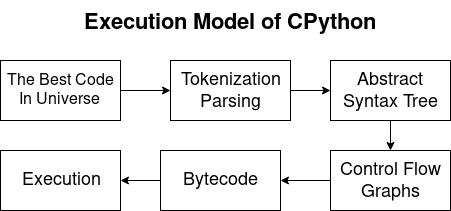
CPython执行模型Python是一种编译和解释语言。 因此,Python编译器生成字节码,然后解释器执行它们。 在本文中,我们将考虑以下问题:
- 解析和标记化:
- AST转型;
- 控制流程图(CFG);
- 字节码
- 在CPython虚拟机上运行。
解析和标记化。
语法语法定义了Python语言的语义。 在指示解析器解释语言的方式时也很有用。 Python语法使用类似于扩展Backus-Naur形式的语法。 对于来自源语言的翻译器,它具有自己的语法。 您可以在目录“ cpython / Grammar / Grammar”中找到语法文件。
以下是语法示例,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
简单表达式包含小表达式和方括号,命令以换行结尾。 小表达式看起来像导入...的表达式列表
其他一些表达方式:)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
标记化(Lexing)令牌化是获取文本数据流并将其拆分为具有重要元数据(对于解释器)的令牌以及其他元数据的过程(例如,令牌的开始和结束位置以及此令牌的字符串值是多少)。
代币令牌是包含所有令牌定义的头文件。 Python中有59种令牌类型(Include / token.h)。
以下是其中一些示例,
如果将一些Python代码分解为令牌,则会看到它们。
使用CLI的标记化这是tests.py文件
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
然后,我们使用python -m tokenize命令将其标记化,并输出以下内容:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
这里的数字(例如1.4-1.13)显示令牌的开始位置和结束位置。 编码令牌始终是我们收到的第一个令牌。 它提供有关源文件编码的信息,如果存在任何问题,解释器将引发异常。
使用tokenize.tokenize进行标记化如果需要从代码中标记文件,则可以使用
stdlib中的
标记模块。
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
令牌的类型是其在
token.h头文件中的
ID。 字符串是令牌的值。 “开始”和“结束”分别显示令牌的开始和结束位置。
在其他语言中,块用方括号或begin / end语句表示,但Python使用缩进和不同级别。 INDENT和DEDENT标记并表示缩进。 这些标记是构建关系解析树和/或抽象语法树所必需的。
解析器生成解析器生成-根据给定语法生成解析器的过程。 解析器生成器称为PGen。 Cpython有两个解析器生成器。 一种是原始的(
Parser/pgen ),另一种是用python(
/Lib/lib2to3/pgen2 )重写的。
“原始生成器是我为Python编写的第一个代码”
-圭多从上面的引用中可以明显看出,
pgen在编程语言中是最重要的。 当您调用pgen(在
Parser / pgen中 )时,它将生成一个头文件和一个C文件(解析器本身)。 如果查看生成的C代码,它似乎毫无意义,因为它有意义的外观是可选的。 它包含许多静态数据和结构。 接下来,我们将尝试解释其主要组成部分。
DFA(定义状态机)解析器为每个非终端定义一个DFA。 每个DFA被定义为状态数组。
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
对于每个DFA,都有一个入门工具包,用于显示特殊的非终端可以使用哪些令牌。
条件每个状态由过渡/边(弧)数组定义。
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
过渡(弧)每个过渡数组都有两个数字。 第一个数字是转换的名称(弧形标签),它表示符号编号。 第二个数字是目的地。
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
名称(标签)这是一个特殊的表,它将字符的ID映射到转换的名称。
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
数字1对应于所有标识符。 因此,即使它们都具有相同的字符ID,它们每个都将获得不同的过渡名称。
一个简单的例子:假设我们有一个代码,如果1-true,则输出“ Hi”:
if 1: print('Hi')
解析器将此代码视为single_input。
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
然后,我们的解析树从一次性输入的根节点开始。

DFA的值(single_input)为0。
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
它看起来像这样:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
在这里,
arc_0_0由三个元素组成。 第一个是
NEWLINE ,第二个是
simple_stmt ,最后一个是
compound_stmt 。
给定初始的
simple_stmt集
simple_stmt我们可以得出结论,
simple_stmt不能以
if开头。 但是,即使不是新行,
compound_stmt仍可以以
if开头。 因此,我们从最后一个
arc ({4;2}) ,将
compound_stmt节点添加到解析树中,然后移至数字2,然后切换到新的DFA。 我们得到一个更新的解析树:

新的DFA解析复合语句。
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
我们得到以下信息:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
只有第一个跳转才能从
if开始。 我们得到一个更新的解析树。
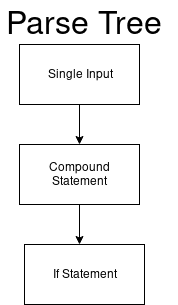
然后,我们再次更改DFA和下一个DFA ifs。
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
结果,我们获得了唯一的标记为97的过渡。它与
if标记重合。
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
当我们切换到保留在同一DFA中的下一个状态时,下一个arcs_41_1也只有一个过渡。 对于测试终端,这是正确的。 它必须以数字开头(例如1)。
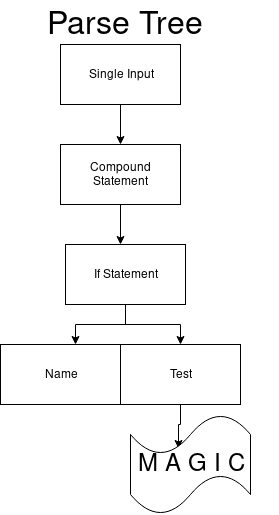
arc_41_2中只有一个转换可获取冒号(:)。

因此,我们得到了一个可以从打印值开始的集合。 最后,转到arcs_41_4。 集合中的第一个过渡是elif表达式,第二个过渡是else,第三个过渡到最后一个状态。 然后,我们得到了解析树的最终视图。
 解析器的Python接口。
解析器的Python接口。
Python允许您使用称为解析器的模块来编辑表达式的解析树。
>>> import parser >>> code = "if 1: print('Hi')"
您可以使用parser.suite生成特定的语法树(具体语法树,CST)。
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
输出值将是一个嵌套列表。 结构中的每个列表都有2个元素。 第一个是字符的ID(0-256-终端,256+-非终端),第二个是终端的令牌字符串。
抽象语法树实际上,抽象语法树(AST)是树形式的源代码结构表示,其中每个顶点表示不同类型的语言构造(表达式,变量,运算符等)。
什么是树?树是一种以根顶点为起点的数据结构。 根顶点通过分支(过渡)降低到其他顶点。 除根以外,每个顶点都有一个唯一的父顶点。
抽象语法树和解析树之间有一定的区别。
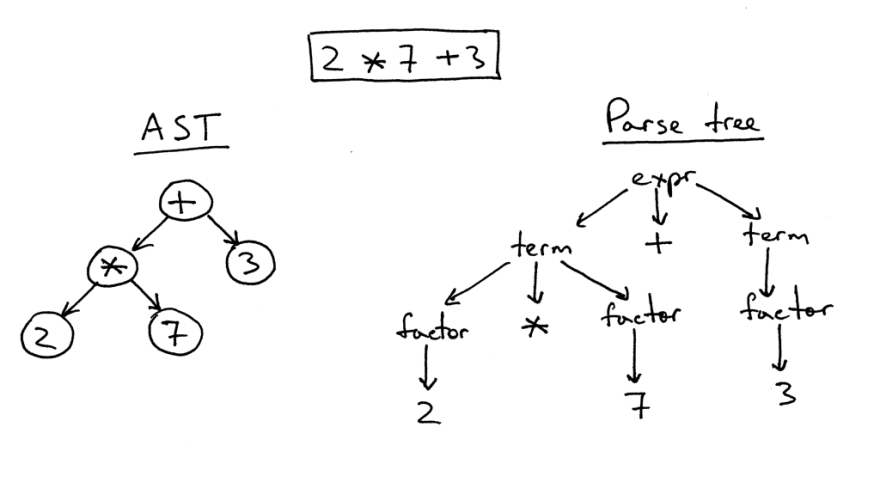
右侧是表达式2 * 7 + 3的解析树。 这实际上是树形式的一对一源图像。 所有表达式,术语和值都可见。 但是,这样的图像对于简单的一段代码来说太复杂了,因此我们可以简单地删除必须在代码中为计算而定义的所有语法表达式。
这样的简化树称为抽象语法树(AST)。 在图的左侧,准确显示了相同的代码。 为了简化理解,所有语法表达式都已被丢弃,但是请记住,某些信息已经丢失。
例子
Python提供了用于AST的内置AST模块。 要从AST树生成代码,可以使用第三方模块,例如
Astor 。
例如,考虑与以前相同的代码。
>>> import ast >>> code = "if 1: print('Hi')"
要获取AST,我们使用ast.parse方法。
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
尝试使用
ast.dump方法来获取更具可读性的抽象语法树。
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
通常认为AST比解析树更直观和易于理解。
控制流梯度(CFG)控制流程图是有向图,它们使用包含中间表示的基本块对程序的流程进行建模。
通常,CFG是获取输出代码值之前的上一步。 从顶部开始,使用CFG中的向后深度搜索直接从基本块生成代码。
字节码Python字节码是在Python虚拟机中工作的中间指令集。 运行源代码时,Python将创建一个名为__pycache__的目录。 它存储已编译的代码,以便在重新启动编译时节省时间。
考虑func.py中的一个简单的Python函数。
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
say_hello对象
say_hello是一个函数。
>>> type(say_hello) <class 'function'>
它具有
__code__属性。
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
代码对象代码对象是不可变的数据结构,其中包含执行代码所需的指令或元数据。 简而言之,这些是Python代码的表示。 您还可以通过使用
compile方法编译抽象语法树来获取代码对象。
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
每个代码对象的属性都包含某些信息(前缀为co_)。 在这里,我们仅提及其中的一些。
co_name首先-一个名字。 如果存在一个函数,则它必须分别具有一个名称,该名称将是该函数的名称,与类的情况类似。 在AST示例中,我们使用模块,我们可以准确地告诉编译器我们要为其命名的名称。 让他们只是一个
module 。
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnames这是一个包含所有局部变量(包括参数)的元组。
>>> say_hello.__code__.co_varnames ('name',)
co_conts一个元组,其中包含我们在函数主体中访问的所有文字和常量值。 值得注意的是值None。 我们没有在函数的主体中包括None,但是,Python指出了这一点,因为如果函数开始执行然后在没有收到任何返回值的情况下结束,它将返回None。
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
字节码(co_code)以下是我们函数的字节码。
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
这不是字符串,这是一个字节对象,即字节序列。
>>> type(bytecode) <class 'bytes'>
打印的第一个字符是“ t”。 如果我们要求它的数值,我们得到以下结果。
>>> ord('t') 116
116与字节码[0]相同。
>>> assert bytecode[0] == ord('t')
对我们而言,值116毫无意义。 幸运的是,Python提供了一个名为dis(来自反汇编)的标准库。 使用opname列表时,此功能很有用。 这是所有字节码指令的列表,其中每个索引都是指令的名称。
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
让我们创建另一个更复杂的函数。
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
我们找到字节码中的第一条指令。
>>> dis.opname[bytecode[0]] 'LOAD_FAST
LOAD_FAST语句由两个元素组成。
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
Loadfast 0指令恰好在元组中搜索变量名,并将索引为零的元素压入执行堆栈中的元组。
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
我们的代码可以使用dis.dis进行反汇编,并将字节码转换为熟悉的视图。 这里的数字(2,3,4)是行号。 Python中的每一行代码都被扩展为一组指令。
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
交货时间CPython是面向堆栈的虚拟机,而不是寄存器的集合。 这意味着Python代码是为具有堆栈体系结构的虚拟机编译的。
调用函数时,Python会同时使用两个堆栈。 第一个是执行堆栈,第二个是块堆栈。 大多数调用都在执行堆栈上进行; 块堆栈跟踪当前有多少个块处于活动状态,以及与块和范围相关的其他参数。
我们期待您对材料的评论,并邀请您参加主题为“发布:发布可靠软件的实际方面”
的公开网络研讨会 ,该
研讨会将由我们的老师,
Stanislav Stupnikov的 Mail.Ru广告系统程序员来进行。