在短期内,仅知道一种网络抓取方法可以解决该问题,但是所有方法都有其优点和缺点。 意识到这一点可以节省时间并有助于更有效地解决问题。

许多资源都在谈论从网页检索数据的唯一真正方法。 但是实际情况是,您可以使用多种解决方案和工具。
- 以编程方式从网页检索数据有哪些选项?
- 每种方法的利弊?
- 如何利用云资源来提高自动化程度?
本文将有助于获得这些问题的答案。
我假设您已经知道什么是
HTTP请求,
DOM (文档对象模型),
HTML ,
CSS选择器和
异步JavaScript 。
如果没有,我建议您深入研究理论,然后返回本文。
静态内容
HTML来源让我们从最简单的方法开始。
如果您打算剪贴网页,这是第一件事。 它将需要很少的计算机电源和最少的时间。
但是,这仅在HTML源代码包含您要定位的数据时才有效。 要在Chrome浏览器中对此进行测试,请右键单击页面,然后选择查看页面代码。 现在,您应该看到HTML源代码。
找到数据后,编写属于包装元素的
CSS选择器 ,以便以后有一个链接。
为了实现,您可以将HTTP GET请求发送到页面的URL并获取HTML源代码。
在
Node中,您可以使用
CheerioJS工具
解析原始HTML并使用选择器检索数据。 该代码将如下所示:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
动态内容
在许多情况下,您无法从原始HTML代码访问信息,因为DOM是由在后台运行的JavaScript控制的。 一个典型的示例是SPA(单页应用程序),其中HTML文档包含的信息最少,而JavaScript在运行时填充该信息。
在这种情况下,解决方案是创建DOM并执行HTML源代码中的脚本,就像浏览器一样。 之后,可以使用选择器从该对象中提取数据。
无头浏览器无头浏览器与普通浏览器相同,只是没有用户界面。 它在后台运行,您可以通过编程方式控制它,而无需从键盘上单击和键入。
Puppeteer是最流行的无头浏览器之一。 这是一个易于使用的Node库,提供了用于离线管理Chrome的高级API。 可以将其配置为不带头文件运行,这在开发过程中非常方便。 以下代码与以前的功能相同,但可用于动态页面:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
当然,您可以使用Puppeteer做更多有趣的事情,因此请查阅
文档 。 这是一段导航URL,截屏并保存的代码段:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
与发送简单的GET请求和分析响应相比,浏览器需要更多的计算能力。 因此,执行相对较慢。 不仅如此,而且将浏览器添加为依赖项会使程序包变得庞大。
另一方面,此方法非常灵活。 您可以使用它来导航页面,模拟单击,鼠标移动并使用键盘,填写表格,创建屏幕快照或创建PDF页面,在控制台中执行命令,选择项以提取文本内容。 基本上,所有可以在浏览器中手动完成的操作。
建立一个DOM您将认为不必为了创建DOM而模拟整个浏览器。 实际上,至少在某些情况下确实如此。
Jsdom是一个Node库,它像浏览器一样解析正在传输的HTML。 但是,这不是浏览器,而是
用于从给定HTML源代码构建DOM以及在此HTML中执行JavaScript代码的工具。
由于有了这种抽象,Jsdom的运行速度比无头浏览器要快。 如果速度更快,为什么不一直使用它而不是无头浏览器呢?
从文档引用 :
人们在使用jsdom时异步加载脚本时经常遇到问题。 许多页面异步加载脚本,但是无法确定何时发生,因此无法确定何时运行代码并检查生成的DOM结构。 这是一个基本限制。
该解决方案如示例所示。 每100毫秒检查一次元素是否出现或是否发生超时(2秒后)。
当Jsdom没有在页面上实现某些浏览器功能时,它通常还会给出错误消息,例如:“
错误:未实现:window.alert ...”或“错误:未实现:window.scrollTo ... ”。 也可以通过一些解决方法(
虚拟控制台 )解决此问题。
与Puppeteer相比,这通常是一个较低级别的API,因此您需要自己实现一些功能。
从示例中可以看出,这使使用变得有些复杂。
Jsdom为同一工作提供了快速的解决方案。
让我们看同一示例,但使用
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
逆向工程Jsdom是一种快速简便的解决方案,但您可以使其变得更加简单。
我们需要对DOM建模吗?
您要剪贴的网页包含相同的HTML和JavaScript,以及您已经知道的相同技术。 因此,
如果找到一段从中获取目标数据的代码,则可以重复相同的操作以获得相同的结果 。
为简化起见,您要查找的数据可能是:
- HTML源代码的一部分(从本文的第一部分可以看出),
- HTML文档中引用的静态文件的一部分(例如javascript文件中的一行),
- 对网络请求的响应(例如,一些JavaScript代码将AJAX请求发送到了以JSON字符串作为响应的服务器)。
可以使用网络查询访问这些数据源 。 网页是否使用HTTP,WebSocket或任何其他通信协议都没关系,因为它们在理论上都是可复制的。
找到包含数据的资源后,您可以将与原始页面相似的网络请求发送到同一服务器。 结果,您将获得包含目标数据的答案,可以使用正则表达式,字符串方法,JSON.parse等轻松提取目标数据。
简而言之,您可以利用数据所在的资源,而不是处理和加载所有材料。 因此,可以通过单个HTTP请求而不是控制浏览器或复杂的JavaScript对象来解决前面示例中显示的问题。
从理论上讲,此解决方案似乎很简单,但是在大多数情况下,这可能很耗时,并且需要使用网页和服务器的经验。
首先监视网络流量。
Chrome DevTools中的
网络标签是一个很好的工具。 您将看到所有带有答案的传出请求(包括静态文件,AJAX请求等),以对它们进行迭代并搜索数据。
如果在屏幕上显示答案之前已用任何代码对其进行了更改,则过程会较慢。 在这种情况下,您必须找到代码的这一部分并了解发生了什么。
如您所见,这种方法可能比上述方法需要更多的工作。 另一方面,它提供了最佳性能。
该图显示了与Jsdom和Puppeteer相比所需的运行时和数据包大小:
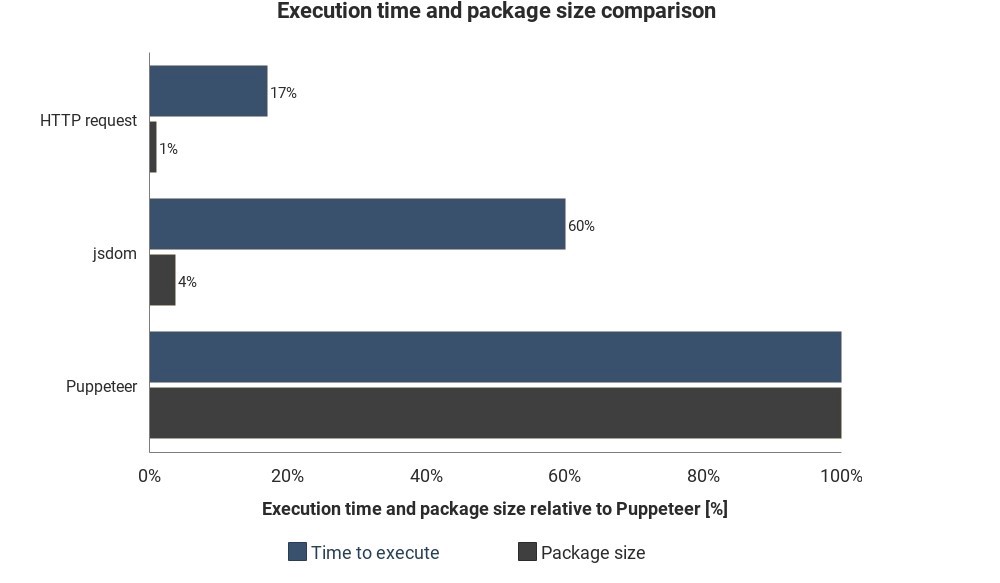
结果并非基于准确的测量结果,并且可能会有所不同,但是在这些方法之间显示出良好的近似差异。
云服务集成
假设您已经实现了这些解决方案之一。 一种执行脚本的方法是打开计算机,打开终端,然后手动启动它。
但是它将变得烦人且效率低下,因此最好将脚本上载到服务器,并根据设置定期执行代码,这样会更好。
这可以通过启动实际服务器并设置执行脚本的时间来完成。 在其他情况下,云功能是一种更简单的方法。
云功能是用于在事件发生时执行下载的代码的存储。 这意味着您不需要管理服务器,这是由您的云提供商自动完成的。
触发器可以是时间表,网络请求和许多其他事件。 您可以将收集的数据保存在数据库中,将其写入
Google表格或通过
电子邮件发送 。 这完全取决于您的想象力。
流行的云提供商
-Amazon Web Services (AWS),
Google Cloud Platform (GCP)和
Microsoft Azure :
您可以免费使用这些服务,但不能长期使用。
如果您使用Puppeteer,则
Google Cloud
功能是最简单的解决方案。 无头Chrome格式的程序包大小(〜130 MB)超出了AWS Lambda中允许的最大存档大小(50 MB)。 有多种方法可以使其与Lambda一起使用,但是GCP功能默认情况下
支持不带标头的Chrome ,您只需在
package.json中将Puppeteer作为依赖项包括在内即可。
如果您想进一步了解有关云功能的更多信息,请查看无服务器架构信息。 关于此主题已经编写了许多很好的教程,并且大多数提供程序都具有易于理解的文档。