切入点是有关机器学习领域如何出现在渡渡鸟中的故事。 剧透:我启动了它。 核心技术细节不会在这里,请确保为他们撰写单独的文章。 今天更多地是关于同事的动力和支持。

准备工作
我碰到过三次机器学习的话题,直到产生了一些有价值的东西。
俄语学校
我第一次在HSE遇到机器学习-当我在Dodo工作时,我获得了大数据系统方向的第二座塔。 在切线上经历了这个巨大的炒作话题之后,我完全不明白为什么我一生都花了三年时间。 甚至更多,所以我没有想到这对公司有什么用处。 那时我还没有为命运的挑战做好准备。
捷克航行
在微软封闭式机器学习黑客马拉松大会上,我第二次在布拉格遇到这个话题。 我们与其他公司的人员一起,致力于在假期和高峰期预测渡渡鸟的需求。 我返回了一个可以预测需求的现成模型。 正是在这次黑客马拉松之后,我才想到可以将所学知识应用到公司中。 在那里。
好吧,您在Jupyter中有模型吗? 如何使用? 向企业解释这一点的所有尝试都面临着严酷的现实:因此很明显,在假期和高峰时段会有很多订单。 成年的比萨店能够根据去年的数据预测销售额,而没有比萨店的新比萨店会遇到问题。 我们推迟了开发机器学习的尝试。 但是,我们可以利用数据做更多事情的想法已经牢牢地牢牢扎在我的脑海,不想离开那里。 现在我已经准备好迎接挑战,但公司却没有。
美国梦
第三次会议变得很重要。 我们的团队完成了一项艰巨而有趣的任务:为美国开发定制的比萨饼模块。 这是您可以订购包含任何成分的披萨,创建自己的食谱的时候。 项目中需要完成的所有工作:从数据库体系结构的更改到站点上的客户端代码。 我们抓住了任务,开发了我认为是真正的胜利的产品。 我们的美国首席执行官艾琳娜(Alena)对主要评估结果assessment之以鼻。

我们做了模块,但是我看到了扩展问题。 如果该功能不在一个州的一两个比萨店中出现,而是在大型网络中出现,该怎么办? 如何管理这样的产品,计划库存? 我认为这种情况可以证明在Dodo中开发机器学习的必要性。 我觉得这次我和公司都准备好向新的方向发展。
汽车一对一
在此背景下,我开始分析美国定制披萨的销售情况。 使用聚类算法,可以证明用户创建的所有食谱都基于六种基本成分以及一些随机成分。 即使基于此算法的简单报表也可以进行半手动的预测销售和计划库存。 由于缺乏官僚主义和随时随地进行重建的能力,我们已获准开始朝这个方向努力。
我和技术总监不止一次地理解和讨论,我需要离开当前的团队并开始制定新的方向,以表明我们需要它。 我需要快速进入一个新领域。 我知道,如果无法解决问题,有两种方法。 首先是在另一个渡渡鸟团队中恢复发展。 第二个是更新您的HH简历并寻找新工作。 我不想要任何一个。 我处于这种状态大约三个月,直到迷上了其他销售模块。
第一个项目
另一个破坏者:事实证明,运行ML不需要遇到任何复杂的事情。 显然不是吗? 但是,在旅程开始时很难理解。
建议向订单添加其他产品的模块不受任何人直接控制。 那意味着我可以和他一起做任何我想做的事。 蛋糕上的樱桃-通过更多个性化商品提供增加销售的机会。 以前,该模块的工作原理很简单:如果在订单中添加了比萨饼,那么饮料的类别会显示在附加销售中,如果是比萨饼和饮料,那么还会显示甜点等。
大量人的冷漠再次表明,我在一家公司中工作,每个人都可以提供支持。 我花了数小时与营销同事一起处理数据和其他报价。 我们设法根据他们的喜好和忠诚度对所有用户进行聚类,为每个组基于聚类中的顶级产品提供静态商品。
数字和证明
我搞砸了更多产品的日志记录,并为200万用户提供了新的优惠。
用户样本仅占销售额的一小部分。 有必要转向未经授权的客户和新客户。 我已经为合作过滤和足够的用户提供了足够多的文章和文献。 根据购物篮中的产品提出建议的想法赢得了。 基于项目的建议和余弦收敛度量构成了一个新的尽管简单但已经有效的模型的基础。
12月,我们启动了基于项目的建议模块。 统计数据表明,买家可能确实对完全不同的产品感兴趣,而不仅仅是饮料。 也许就是在此之后,渡渡鸟相信数据和机器学习的发展将使它们能够在未来超负荷的市场中竞争。
一些统计。
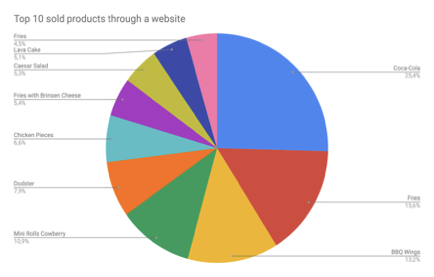
网站上10种最畅销的产品

10种最畅销的移动应用程序产品

每周销售增长
技术预告片
以下是有关为什么该模型基于相似度的余弦量度的一些技术细节。 这是文章的预览,将在几个月后发布。 如果您不喜欢数学,请随时跳到最后一部分。
下表显示了每个用户购买的商品的订单数量。 我们可以确定一个用户与另一个用户的购买相似度-为此,我们需要计算用户向量之间的距离。
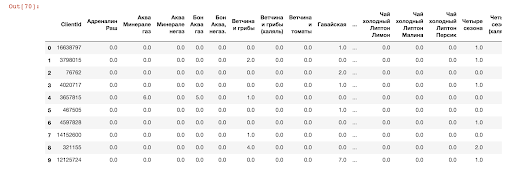
客户销售表
距离将取决于所选度量。 欧几里得空间的计算包括向量的权重和大小:

其中a和b是表中两个不同的客户向量。 让我们看看这个距离在一个抽象示例中的外观。
假设我们查看三个客户的历史-a,b和c。 让我们建立他们购买的矩阵。

计算出客户之间的欧几里得距离后,我们得到以下值:
d(a,b)= 16.22;
d(b,c)= 13.38;
d(a,c)= 13.64。
这些值表示客户端b和c彼此最接近。 但是,如果您查看源数据,则情况恰恰相反。 客户a和b更喜欢订购更多意大利辣香肠和其他产品,而客户c更喜欢Supreme Pizza。 我们可以得出结论,向量的大小对计算客户之间的距离有负面影响。 相似度的余弦度量仅考虑了向量之间的角度,而忽略了向量幅度的重要性:

使用此公式计算距离,我们得到:
d(a,b)= 0.9183;
d(b,c)= 0.5848;
d(a,c)= 0.7947;
我们看到客户a和b彼此靠近。 他们偏爱一套商品,而没有考虑所下订单数量的差异。 此逻辑与我们的专家意见一致,并暗示客户a和b的偏好彼此最接近。
这是一部预告片,两个月内会详细介绍。
搜索您的
现在,我们处于组建团队的阶段,该团队将由专家来组织数据存储,开发机器学习模型并将其投入生产。 但最重要的是,我们现在更好地理解了为什么需要所有这些。 从组织智能物流系统和库存计划到使用Computer Vision技术自动化比萨店的出色创意,我们可以自由地做一些非常酷的事情。
即使结果看不到,也要相信自己和自己的优点。 我想以其他人的思想作为结尾:马克斯·韦伯(Max Weber)在他给慕尼黑大学学生的报告中引述的一句话:“你不能带着悲伤和期望做任何事情,而你需要采取不同的行动-你需要转向工作并满足作为人类的“当今的需求”,如此专业。 如果每个人都找到自己的恶魔并服从这个恶魔,编织自己的生命线,那么这一要求将变得简单明了。” 找到你的。