哈Ha! 我提请您注意鲁迪·吉尔曼(Rudy Gilman)和凯瑟琳·王(Katherine Wang)的《 直觉RL:优势-演员-批评(A2C)简介》的翻译 。

强化学习专家(RL)编写了许多出色的教程。 但是,大多数人用数学方程式和抽象图来描述RL。 我们喜欢从不同的角度来考虑这个问题。 RL本身受到动物学习方式的启发,所以为什么不将潜在的RL机制转换回拟模拟的自然现象呢? 人们通过故事学习得最好。
这就是演员优势评论家(A2C)模型的故事。 主题批评模型是Policy Gradient模型的一种流行形式,它本身就是传统的RL算法。 如果您了解A2C,就会了解深入的RL。
对A2C有了直观的了解后,请检查:
插图@embermarke
在RL中,特工Klyukovka狐狸穿越行动所包围的州,试图在旅途中获得最大的回报。
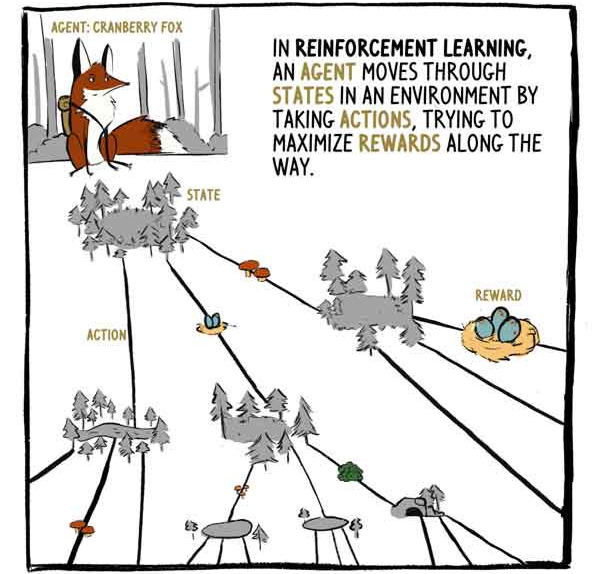
A2C接收状态输入-在Klukovka的情况下为传感器输入-并生成两个输出:
1)从当前状态开始,评估将获得多少报酬,但当前(现有)报酬除外。
2)关于采取何种措施(政策)的建议。
评论家:哇,多么美妙的山谷! 觅食将是丰硕的一天! 我敢打赌,今天我会在日落之前收集20分。
“主题”:这些花看起来很美,我渴望“ A”。

深度RL模型是输入-输出映射机,就像其他任何分类或回归模型一样。 深度RL模型不是将图像或文本分类,而是将状态带入操作和/或将状态带入状态值。 A2C两者都做。


这组状态-行动-奖励是一个观察。 她会将这行数据写到日记中,但是现在还没有考虑。 当她停止思考时,她会填满它。
一些作者将奖励1与时间步骤1相关联,另一些作者则将其与步骤2相关联,但是所有人都记住相同的概念:奖励与状态相关,并且动作紧随其后。

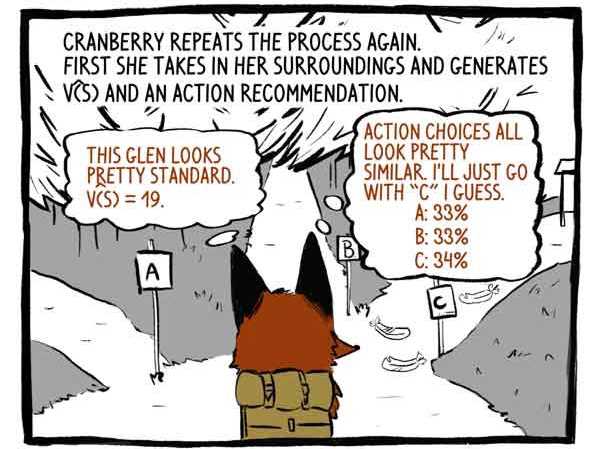
挂钩再次重复该过程。 首先,她感知周围环境,并开发出函数V(S)和行动建议。
评论家:这个山谷看起来很标准。 V(S)= 19。
主题:采取的行动选项非常相似。 我想我会走在“ C”轨道上。
然后它起作用。

获得+20的奖励! 并记录观察结果。

她再次重复该过程。

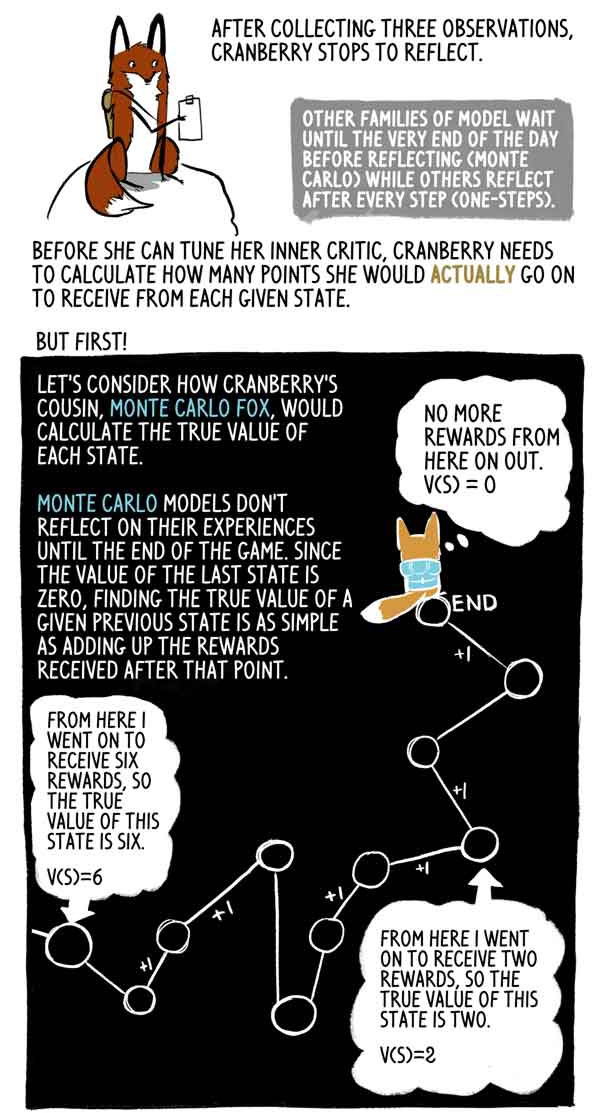
收集了三个观察结果后,克里尤科夫卡停止思考。
其他模特家族一直等到一天结束(蒙特卡洛),而其他模特家族则一步一步地思考。
在设置内部评论者之前,Klukovka需要计算在每个给定状态下她实际上将获得多少积分。
但是首先!
让我们看一下克鲁科夫卡的堂兄Lis Monte Carlo如何计算每个州的真实含义。
蒙特卡洛模型直到比赛结束才反映出他们的经验,并且由于最后一个状态的值为零,因此很容易找到此先前状态的真实值作为此刻之后获得的奖励总和。
实际上,这只是一个高分散样本V(S)。 代理可以轻松地遵循与同一状态不同的轨迹,从而获得不同的合计奖励。
但是克里尤科夫卡走了,停了下来,反省了好多次,直到一天结束。 她想知道从每个州到比赛结束她将实际获得多少积分,因为到比赛结束还剩几个小时。
那是她做些真正聪明的事的地方-狐狸Klyukovka估计她将获得该组最后一个状态的分数。 幸运的是,她对自己的病情有了正确的评估-她的批评家。
通过此评估,Klyukovka可以像蒙特卡洛狐狸一样准确地计算先前状态的“正确”值。
利斯·蒙特卡洛(Lis Monte Carlo)评估目标标记,部署轨迹并增加各州的奖励。 A2C削减了这一轨迹,并通过对其批评者的评估来代替它。 这种初始负载减小了得分的差异,并且允许A2C连续运行,尽管引入了较小的偏差。

酬金通常会减少,以反映这样一个事实:现在的薪酬比将来的要好。 为简单起见,Klukovka不会减少其回报。

现在,Klukovka可以遍历数据的每一行,并将其状态值的估计值与实际值进行比较。 她利用这些数字之间的差来完善自己的预测技能。 在一天中的每三个步骤中,Klyukovka收集了值得考虑的宝贵经验。
“我对州1和州2的评价很差。我做错了什么? 是的 下次我看到这样的羽毛时,我将增加V(S)。
Klukovka能够使用她的V(S)等级作为与其他预测进行比较的基础,这似乎很疯狂。 但是动物(包括我们)一直在这样做! 如果您感觉事情进展顺利,则无需重新培训使您进入此状态的操作。

通过修整计算的输出并将其替换为初始负载估算,我们用较小的偏差替换了较大的蒙特卡洛方差。 RL模型通常会遭受高度分散(代表所有可能的路径)的困扰,因此通常值得这样做。
克鲁科夫卡整天重复这一过程,收集了三项关于国家行为奖励的观察结果并进行了反思。
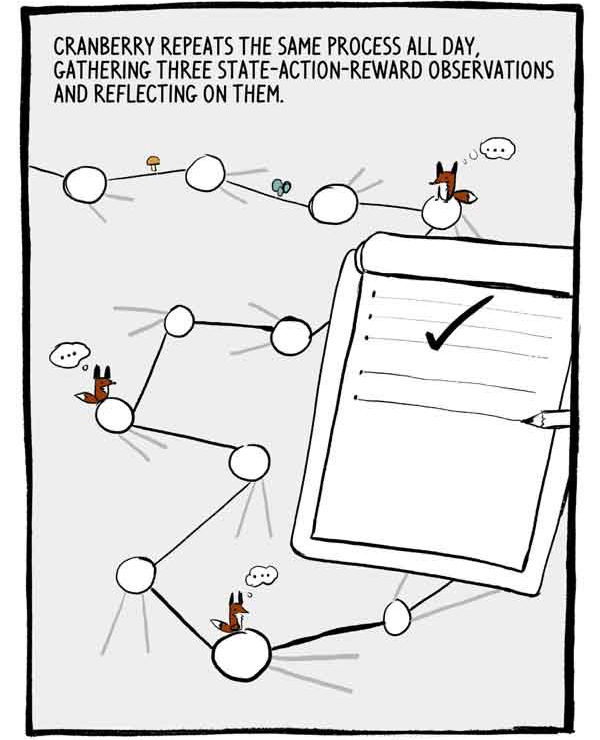
每组三个观察值是一系列小的,自相关的标记训练数据。 为了减少这种自相关,许多A2C并行地训练了许多代理,在将其经验发送到公共神经网络之前将其经验加在一起。

一天终于结束了。 仅剩两步了。
正如我们之前所说,克鲁维卡行动的建议以对其能力的信心百分比表示。 克鲁维卡不仅选择最可靠的选择,还从这种行动分配中进行选择。 这确保了她并不总是同意安全但潜在的平庸行为。
我可能会后悔,但是...有时候,探索未知的事物,您可能会发现令人兴奋的新发现...

为了进一步鼓励研究,从损失函数中减去一个称为熵的值。 熵是行动分布的“范围”。
-看来游戏已经成功了!

还是不行
有时,代理人处于所有行动都会导致负面结果的状态。 但是,A2C可以很好地应对恶劣的情况。


太阳下山时,克柳科夫卡(Klyukovka)思考了最后一套解决方案。

我们谈到了克柳科夫卡是如何建立他内心的批评家的。 但是她如何微调自己内在的“主体”? 她如何学习做出如此精妙的选择?
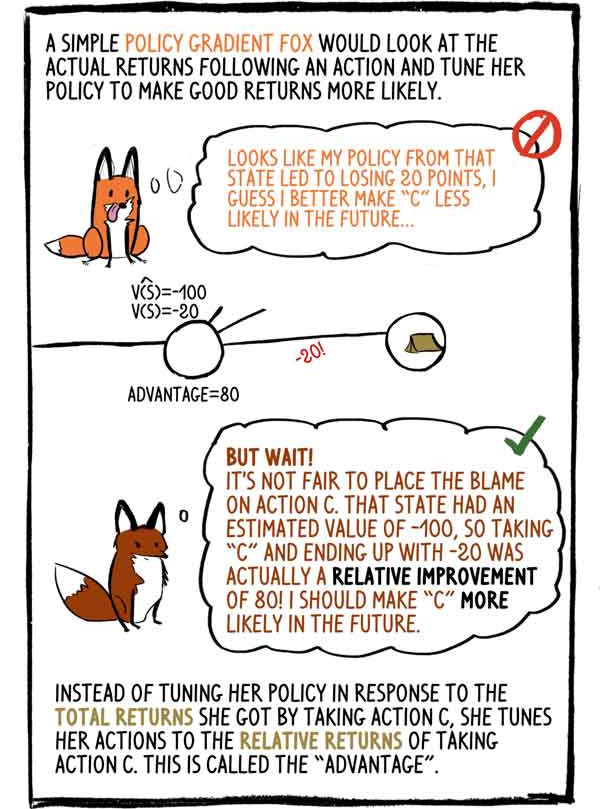
笨拙的狐狸梯度政策会在行动后查看实际收入,并调整其政策以使获得较高收入的可能性更大:-看来我在这种状态下的政策导致损失了20点,我认为将来最好做“ C”可能性较小。
-等一下! 责怪行动“ C”是不公平的。 该状态的估计值为-100,因此选择“ C”并以-20结尾实际上是80的相对改善! 将来我必须提高“ C”的可能性。
它没有根据选择操作C收到的总收入来调整其策略,而是将其操作调整为来自操作C的相对收入。这被称为“优势”。
我们所谓的优势仅仅是一个错误。 作为一项优势,Klukovka使用它来使出乎意料的好活动变得更有可能。 作为一个错误,她使用相同的金额来推动内部批评者改善对状态价值的评估。
主题利用:
-“哇,效果比我想象的要好,动作C必须是个好主意。”
评论者使用以下错误:
“但是我为什么感到惊讶? 我可能不应该如此否定地评估这种情况。”
现在我们可以展示如何计算总损失-我们最小化此函数以改进模型。
“总损失=行动损失+价值损失-熵”
请注意,要计算三种在质量上不同的类型的梯度,我们取值“一”。 这是有效的,但会使收敛更加困难。

像所有动物一样,随着克留夫科夫(Klyukovka)的长大,他将磨练预测国家价值的能力,对自己的行为有更多的信心,对奖项的惊奇也越来越少。
RL代理(例如Klukovka)不仅可以生成所有必要的数据,只需与环境进行交互即可,而且还可以自己评估目标标签。 没错,RL模型会更新以前的成绩,以更好地匹配新的和改进的成绩。
正如Google Deepmind RL小组负责人David Silver博士所说:AI = DL + RL。 当像Klyukovka这样的特工可以设定自己的智慧时,可能性无穷无尽...
