当
HighLoad ++参与者来到
Alexander Krasheninnikov的报告时,他们希望听到每秒处理1,600,000个事件的信息。 期望没有实现。因为在准备性能期间,这个数字飞涨到了
180万 -因此,在HighLoad ++上,现实超出了期望。
3年前,亚历山大(Alexander)告诉他们如何在Badoo建立可扩展的近实时事件处理系统。 从那时起,它不断发展,过程中数量不断增长,有必要解决缩放和容错问题,并且在某些时候需要采取根本措施-
技术堆栈的
变化 。

从解密中,您将学习在Badoo中如何用ClickHouse替换Spark + Hadoop捆绑软件,如何
节省3倍的硬件并增加6倍的负载 ,为什么以及通过什么方式收集项目中的统计信息以及如何处理这些数据。
关于演讲者: Alexander Krasheninnikov(
alexkrash )
-Badoo数据工程主管。 他从事BI基础架构,扩展工作负载,并管理构建数据处理基础架构的团队。 他喜欢分布式的所有内容:Hadoop,Spark,ClickHouse。 我确信可以从OpenSource准备出色的分布式系统。
统计资料收集
如果我们没有数据,那么我们将是盲目的,无法管理我们的项目。 这就是为什么我们需要统计信息-
监视项目的可行性。 作为工程师,我们应该努力改进我们的产品,如果
您要改进,请对其进行评估。 这是我工作的座右铭。 首先,我们的目标是业务收益。 统计数据
提供业务问题的答案 。 技术指标是技术指标,但是企业也对指标感兴趣,因此也需要考虑它们。
统计生命周期
我将统计数据的生命周期定义为4点,我们将分别讨论每点。
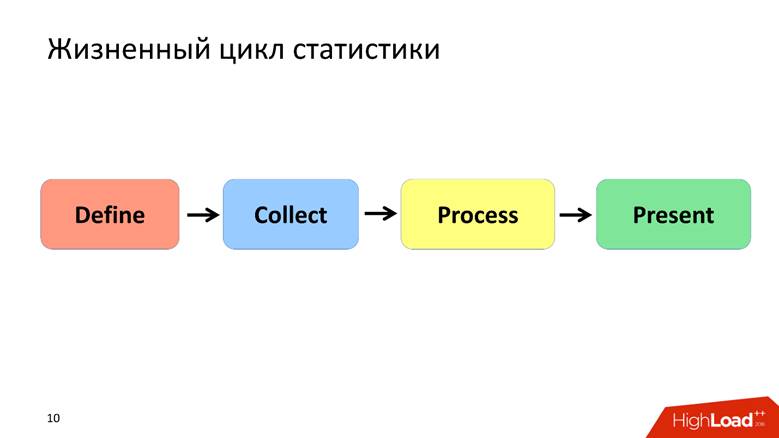
定义阶段-形式化
在应用程序中,我们收集了几个指标。 首先,这些是
业务指标 。 例如,如果您有照片服务,您想知道每天,每小时,每秒上传多少张照片。 以下指标是
“半技术性的” :移动应用程序或站点的响应速度,API操作,用户与站点交互的速度,应用程序安装,UX。
跟踪用户行为是第三个重要指标。 这些系统类似于Google Analytics(分析)和Yandex.Metrics。 我们有自己的很酷的跟踪系统,我们在其中进行了大量投资。
在处理统计信息的过程中,涉及到许多用户-这些是开发人员和业务分析人员。 每个人都说相同的语言很重要,因此您需要同意。
可以进行口头谈判,但是正式进行时(在清晰的事件结构中)会更好。
正式的商业事件结构是当开发人员说出我们拥有多少注册时,分析师了解到,不仅为他提供了有关注册总数的信息,而且还提供了有关国家,性别和其他参数的信息。 所有这些信息都是正式的
,对公司的所有用户都是公开的 。 该事件具有类型化的结构和形式描述。 例如,我们以
协议缓冲区格式存储此信息。
事件“注册”的描述:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
注册事件包含有关
用户,字段,事件
时间和用户注册
国家/地区的信息 。 这些信息可供分析人员使用,并且将来,企业将了解我们收集的信息。
为什么需要正式说明?
对开发人员,分析师和产品部门而言,正式的描述是
统一的。 然后,此信息会渗透到应用程序业务逻辑的描述中。 例如,我们有一个用于描述业务流程的内部系统,并且在其中有一个新功能的屏幕。
在
产品需求文档中,有一节包含说明,当用户以这种方式与应用程序交互时,我们必须发送具有完全相同参数的事件。 随后,我们将能够验证我们的功能运行状况以及对它们的正确测量。 正式的描述使我们可以进一步了解如何将这些数据保存在数据库中:NoSQL,SQL或其他。 我们有
一个数据模式 ,这很酷。
在某些作为服务提供的分析系统中,秘密存储中只有10-15个事件。 在我们国家,这个数字已经增长到1000多个,而且不会停止-
没有一个登记册就无法生存 。
定义阶段摘要
我们认为
统计-这很重要,并
描述了某个主题领域 -很好,您可以继续。
收集阶段-数据收集
我们决定构建该系统,以便在发生业务事件(例如注册,发送消息)时,在保存此信息的同时,我们分别发送特定的统计事件。
在代码中,统计信息与业务事件同时发送。
由于
数据流通过单独的处理管道 ,因此完全独立于应用程序在其中运行的数据存储进行
处理。通过EDL描述:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
我们对注册事件进行了描述。 API是自动生成的,开发人员可以从代码中访问它,该代码只需4行即可发送统计信息。
基于EDL的API:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
活动交付
这是我们的外部系统。 我们之所以这样做,是因为我们拥有令人难以置信的服务,它们提供了用于处理照片数据以及其他内容的API。 它们都将数据存储在很棒的新型数据库中,例如Aerospike和CockroachDB。
当您需要建立某种类型的报告时,您不必战斗:“伙计,您有多少,有多少?” -所有数据以单独的流发送。 加工输送机-外部系统。 从应用程序上下文中,我们从业务逻辑存储库中解开所有数据,并将其进一步发送到单独的管道。
收集阶段假定应用程序服务器可用。 我们有这个PHP。
交通运输
这是一个子系统,它使我们可以将在应用程序上下文中执行的操作发送到另一个管道。 仅根据您的需求选择运输,具体取决于项目的情况。
运输具有特点,首先是
交货保证。 传输的特征:至少一次,完全一次,您可以根据这些数据的重要性来选择任务的统计信息。 例如,对于计费系统,统计信息显示的交易数量超过了实际数量,这是不可接受的-这就是金钱,这是不可能的。
第二个参数是
编程语言的绑定。 我们必须以某种方式与运输交互,因此要根据编写项目的语言选择运输。
第三个参数是
可伸缩性。 由于我们正在谈论每秒数百万个事件,因此牢记未来的可伸缩性将是一件很不错的事情。
有许多传输选项:RDBMS应用程序,Flume,Kafka或LSD。 我们使用
LSD-这是我们的特殊方式。
直播流守护程序
LSD与禁用物质无关。 这是一个
活泼,非常快速的流式守护进程 ,它不提供任何代理来写入该
守护进程 。 我们可以调整它,并
与其他系统集成 :HDFS,Kafka-我们可以重新排列发送的数据。 LSD在INSERT上没有网络调用,您可以在其中控制网络拓扑。
最重要的是,这是
Badoo的OpenSource-没有理由不信任该软件。
如果这是一个完美的恶魔,那么我们将在每次会议上讨论LSD,而不是Kafka,但是每一个LSD都有美中不足。 我们有适合自己的局限性:我们
在LSD中没有复制支持,并且
至少有一次交付保证。 另外,对于货币交易而言,这不是最合适的传输方式,但是您通常需要专门通过支持
ACID的 “酸性”数据库与货币进行通信。
收集阶段摘要
基于上一个系列的结果,我们收到了
对数据的
正式描述 ,并从中
为事件调度程序生成了一个出色,便捷的
API ,并弄清楚了如何
将这些数据
从应用程序上下文 传输 到单独的管道 。 已经不错,我们正在进入下一阶段。
阶段处理-数据处理
我们从注册,上传的照片,民意调查中收集数据-怎么做? 从这些数据中,我们希望获得具有悠久历史和
原始数据的 图表 。 图表可以理解所有内容-您无需成为开发人员即可从曲线上了解公司的收入正在增长。 我们将原始数据用于在线报告和临时。 对于更复杂的情况,我们的分析师希望对此数据执行分析查询。 该功能和该功能对于我们都是必需的。
图表
图表有多种形式。
或者,例如,具有历史记录的图表显示10年的数据。
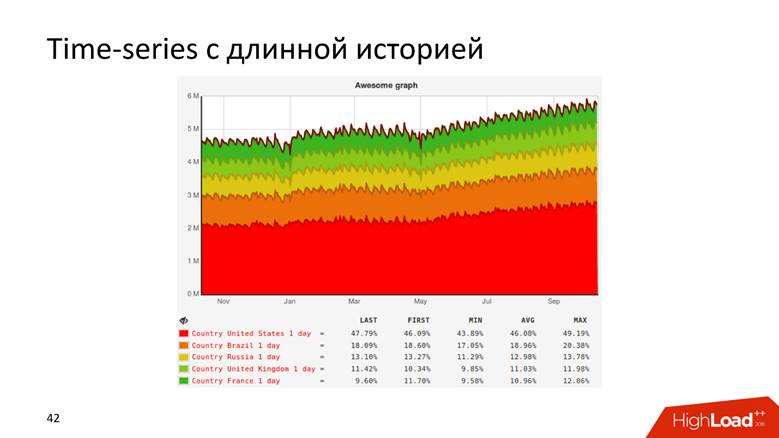
图表甚至是这样。
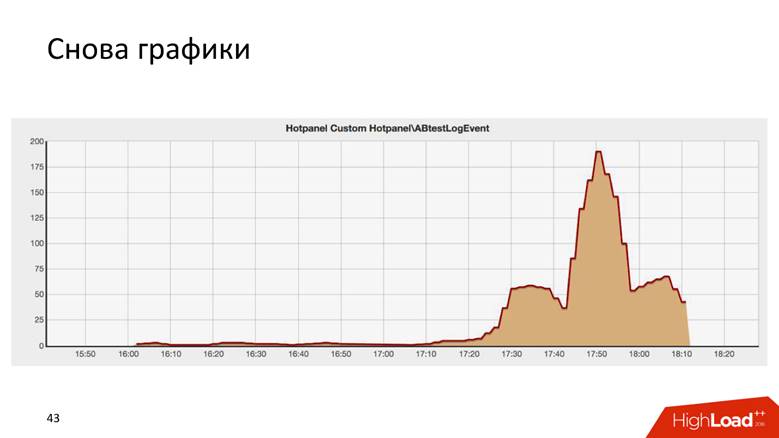
这是一些AB测试的结果,令人惊讶地类似于纽约的克莱斯勒大楼。
绘制图形有两种方法:
查询原始数据和
时间序列 。 两种方法都有缺点和优点,我们将不对其进行详细介绍。 我们使用一种
混合方法 :从原始数据中获取简短信息用于运营报告,从时间序列中获取长期存储信息。 第二个是从第一个开始计算的。
我们如何发展到每秒180万个事件
这是一个漫长的故事-一天不会发生数百万个RPS。 Badoo是一家拥有十年历史的公司,可以说数据处理系统随着公司的发展而发展。
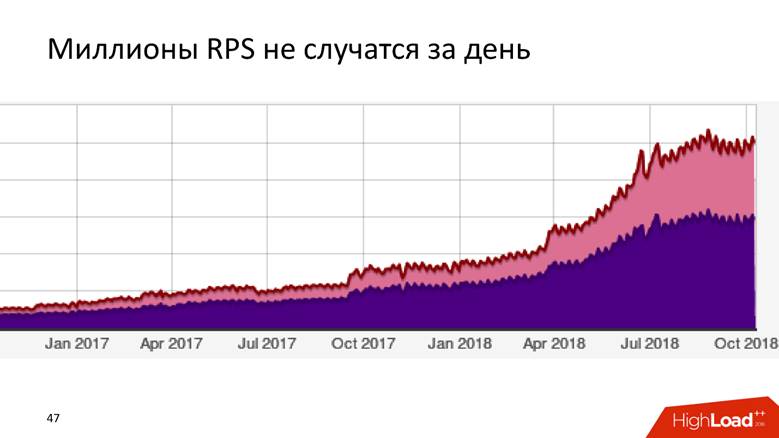
起初我们什么都没有。 我们开始收集数据-
每秒发现
5,000个事件。 一台MySQL主机,别无其他! 任何关系型DBMS都可以完成此任务,并且对它很满意:您将具有事务性-放置数据,接收来自它的请求-一切工作都很好。 所以我们住了一段时间。
在某个时候,功能分片发生了:注册数据-在这里,关于照片-在那儿。 因此,我们
每秒最多可以处理
200,000个事件,并开始使用各种组合方法:不存储原始数据,而是存储
聚合数据,但到目前为止存储在关系数据库中。 我们存储计数器,但是大多数关系数据库的本质是无法对数据执行
DISTINCT查询 -计数器的代数模型不允许计算DISTINCT。
在Badoo,我们的座右铭是
“不可阻挡的力量” 。 我们不会停下来并进一步发展。 当我们超过
每秒200,000个事件的阈值时,我们决定创建一个正式的描述,我在上面已经谈到过。 在此之前,这里有些混乱,现在我们有了一个结构化的事件记录器:我们开始扩展系统,
连接Hadoop ,所有数据都放入
Hive表中。Hadoop是一个巨大的软件包,文件系统。 对于分布式计算,Hadoop说:“将数据放在此处,我将让您对它们执行分析查询。” 因此,我们做到了-
为所有图表编写了
常规计算 -结果很好。 但是,图表在快速更新时很有价值-每天一次,观看图表更新并不是那么有趣。 如果我们推出的产品导致生产中出现致命错误,我们希望图表立即下降,而不是隔天下降。 因此,一段时间后,整个系统开始降级。 但是,我们意识到,在此阶段,您可以坚持使用选定的技术堆栈。
对我们来说,Java是新的,我们喜欢它,并且我们理解可以采取不同的方法。
在
每秒 400,000到
800,000个事件的阶段,我们以最纯粹的形式替换了Hadoop,而Hive作为
Spark查询上的分析查询的执行者,编写了
通用的map / reduce和增量计算指标。 3年前,我
告诉我们如何做到的。 然后在我们看来,Spark将会永远存在,但是生命却以其他方式降低-我们遇到了Hadoop的局限性。 也许如果我们有其他条件,我们将继续使用Hadoop。
除了在Hadoop上计算图形外,另一个问题是由分析人员驱动的令人难以置信的四层SQL查询,并且图形没有快速更新。 事实是,操作数据处理工作相当棘手,因此它是实时,快速和酷炫的。
Badoo由位于大西洋两侧的两个数据中心提供服务,分别位于欧洲和北美。 要建立统一的报告,您需要将数据从美国发送到欧洲。 我们保留所有统计数据统计信息在欧洲数据中心中,因为它具有更大的计算能力。 数据中心之间
的往返时间约为
200毫秒 -网络非常精密-向另一个DC发出请求与前往下一个机架并不相同。
当我们开始正式化事件并开发人员,并且产品经理参与其中时,每个人都喜欢一切-
事件爆炸性增长 。 现在是时候在集群中购买铁了,但是我们并不是真的想要这样做。
当我们超过了
每秒800,000个事件的峰值时,我们发现了Yandex上传到OpenSource
ClickHouse的内容 ,并决定尝试一下。 当他们尝试做某事时,
他们装满了圆锥形的火车,结果,当一切正常的时候,他们举办了一次小型自助招待会,招待了前100万场活动。 ClickHouse可能已经完成了报告。
只需使用ClickHouse并与其一起生活。
但这并不有趣,因此我们将继续谈论数据处理。
Clickhouse
ClickHouse是最近两年的一次大肆宣传,无需介绍:仅在2018年的HighLoad ++上,我记得
有关该报告的五份报告以及研讨会和会议。
该工具旨在准确解决我们为自己设置的那些任务。 我们一次从Hadoop接收
实时更新和芯片:复制,分片。 没有理由不尝试ClickHouse,因为他们知道通过Hadoop实施,我们已经触底。 该工具很棒,文档通常都很火爆-我自己写在那里,我真的很喜欢一切,而且一切都很棒。 但是我们必须解决许多问题。
如何在ClickHouse中转移事件的整个流程? 如何合并来自两个数据中心的数据? 从我们来到管理员那里说:“伙计们,让我们安装ClickHouse”的事实来看,他们不会使网络厚两倍,而延迟却是原来的一半。 不,网络仍然像第一笔薪金一样薄。
如何存储结果 ? 在Hadoop,我们了解如何绘制图形-但是如何在神奇的ClickHouse上进行绘制? 不包括魔术棒。
如何将结果传递到时间序列存储?
正如我在该研究所的讲师所说的那样,请考虑3种数据方案:战略,逻辑和物理方案。
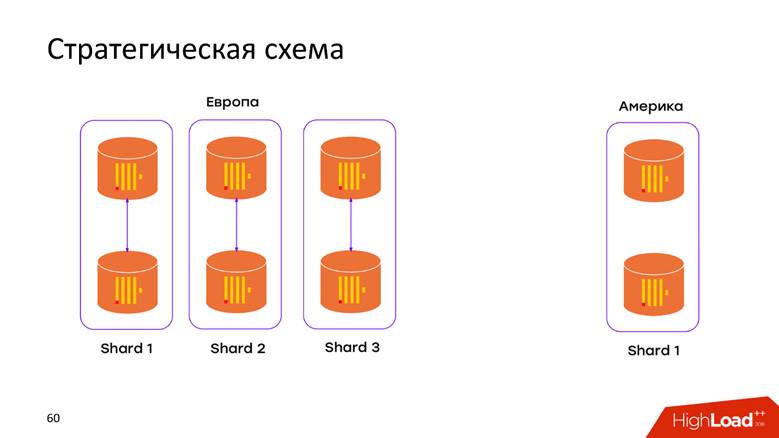
战略存储方案
我们有
2个数据中心 。 我们了解到ClickHouse对DC一无所知,我们只是在每个DC中弹出集群。 现在,
数据不再通过跨大西洋电缆移动 -DC中发生的所有数据都本地存储在其群集中。 例如,当我们要请求合并的数据时,要找出两个DC中有多少注册,ClickHouse会给我们这个机会。 低延迟和低可用性的请求-只是一个杰作!
物理存储方案
再次提出问题:我们的数据将如何落入ClickHouse关系模型中,应如何做才能避免丢失复制和分片?
ClickHouse文档中对所有内容进行了
详尽的描述 ,如果您拥有多个服务器,则会遇到本文。 因此,我们将不深入研究手册中的内容:对分片上所有数据的复制,分片和查询。
储存逻辑
逻辑图是最有趣的。 在一个管道中,我们处理异构事件。 这意味着我们有
各种各样的事件 :注册,语音,照片上传,技术指标,跟踪用户行为-所有这些事件具有完全
不同的属性 。 例如,我看着手机上的屏幕-我需要一个屏幕ID,我为某人投票-您需要了解该投票是赞成还是反对。 所有这些事件都具有不同的属性,在它们上绘制了不同的图形,但是所有这些事件必须在单个管道中进行处理。 如何将其放入ClickHouse模型中?
方法1-每个事件表。 我们从MySQL的经验中推断出第一种方法-我们
为 ClickHouse中的
每个事件创建了一个
平板电脑 。 听起来很合逻辑,但是我们遇到了许多困难。
我们没有限制,当今天的版本发布时,事件将改变其结构。 任何开发人员都可以完成此补丁。 该方案通常在各个方向上都是可变的。 唯一
必需的字段是
时间戳记事件和事件的名称。 其他所有内容都会随时更改,因此,需要修改这些标牌。 ClickHouse可以
在群集上执行
ALTER的功能 ,但这是一个微妙的微妙过程,很难使其自动化以使其平稳运行。 因此,这是一个负号。
我们有超过一千个不同的事件,这使我们
每台机器的插入率很高 -我们将所有数据不断记录在一千个表中。 对于ClickHouse,这是一种反模式。 如果百事可乐的口号是“大口活”,那么ClickHouse-
“大口活”。 如果不这样做,那么复制将被阻塞,ClickHouse拒绝接受新的插入-令人不快的方案。
方法2-宽桌 。 西伯利亚人试图将电锯滑到轨道上,并应用其他数据模型。 我们创建一个包含
一千列的表 ,其中每个事件都有为其数据保留的列。 我们得到了一个庞大的
稀疏表 -幸运的是,这并没有超出开发环境,因为从最初的插入开始就可以清楚地看出该方案绝对是不好的,我们不会这样做。
但是我仍然想使用这样一个很酷的软件产品,还有一点要完成-这将是您所需要的。
方法3-通用表。 我们有一个巨大的表,其中将数据存储在数组中,因为ClickHouse支持
非标量数据类型 。 也就是说,我们从存储属性名称的列开始,到具有存储属性值的数组的单独列开始。
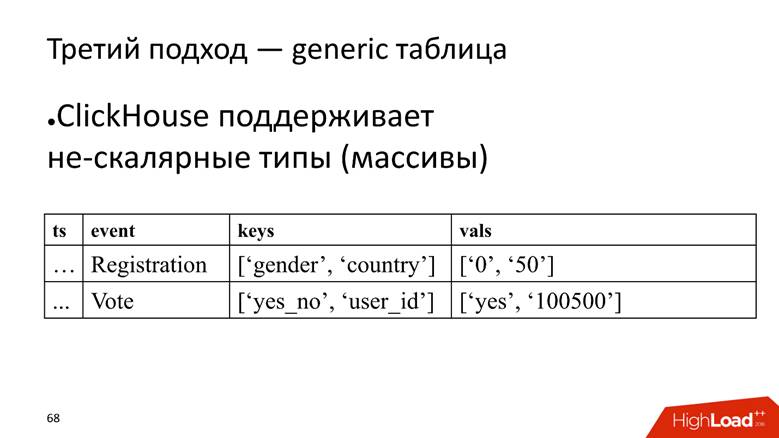
ClickHouse在这里可以很好地执行任务。 如果只需要插入数据,则在当前安装中可能会再挤出10次。
然而,美中不足的是,它也是ClickHouse的反模式-
存储字符串数组 。 这是不好的,因为行阵列
占用更多的磁盘空间 -它们的收缩比简单的列更糟,并且
更难处理 。 但是对于我们的任务,由于优势胜过,我们对此视而不见。
如何从这样的表进行SELECT? 我们的任务是对按性别分组的注册进行计数。 首先,您需要在一个数组中找到对应于性别列的位置,然后使用该索引爬到另一列中并获取数据。
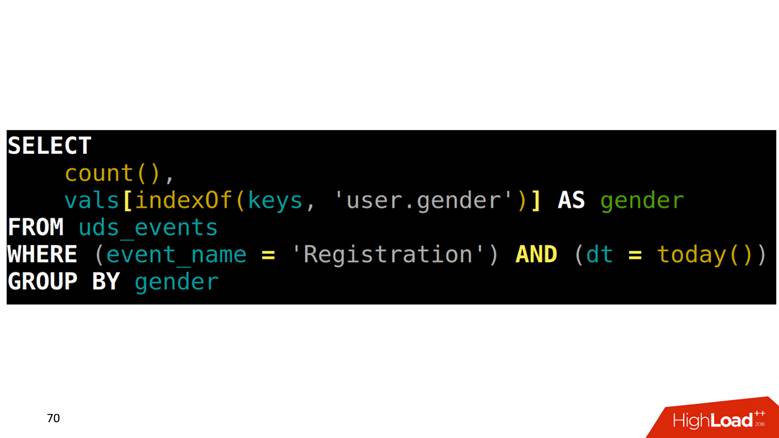
如何在此数据上绘制图形
由于描述了所有事件,因此它们具有严格的结构,我们针对每种事件类型形成一个四层的SQL查询,执行该查询并将结果保存到另一个表中。
问题是要在图形上绘制两个相邻的点,您需要
扫描整个表格 。 示例:我们每天查看一次注册。 此事件是从顶线到倒数第二个。 扫描一次-非常好。 5分钟后,我们想在图表上绘制一个新点-再次,我们扫描与上一次扫描相交的数据范围,依此类推,针对每个事件。 听起来合乎逻辑,但看起来并不好。
另外,当我们走几行时,我们还需要
读取aggregation下的结果 。 例如,有一个事实,就是上帝的仆人在斯堪的那维亚注册并且是一个男人,我们需要计算摘要统计数据:多少个注册,多少个男人,其中有多少人是多少,以及有多少来自挪威。 用分析数据库
ROLLUP,CUBE和
GROUPING SETS来称呼-将一行变成几行。
怎么治疗
幸运的是,ClickHouse有一个工具可以解决此问题,即
聚合函数的
序列化状态 。 这意味着您可以一次扫描一条数据并保存这些结果。 这是一个
杀手级功能 。 3年前,我们正是在Spark和Hadoop上做到了这一点,很酷的是,与我们并行的是,Yandex最好的头脑在ClickHouse中实现了一个模拟。
要求缓慢
我们的要求很慢-要计算今天和昨天的唯一身份用户。
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
在物理平面中,我们可以对昨天的状态进行SELECT,获取其二进制表示形式,并将其保存在某个位置。
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
对于今天,我们只是更改今天的条件:
'yyy' AS ts而
WHERE dt = today()和时间戳,我们将其称为“ xxx”和“ yyy”。 , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
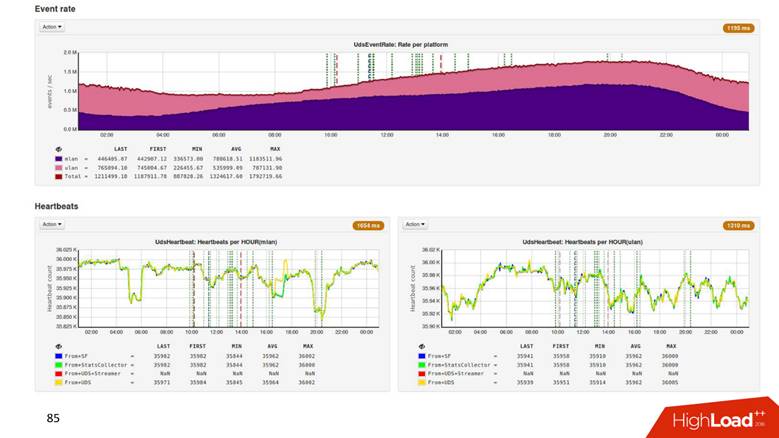
8 ClickHouse , 6 - , 2 : 2 — , .
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
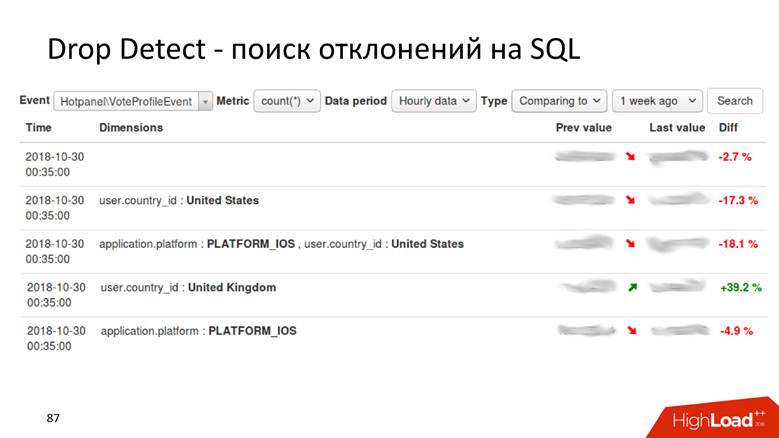
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
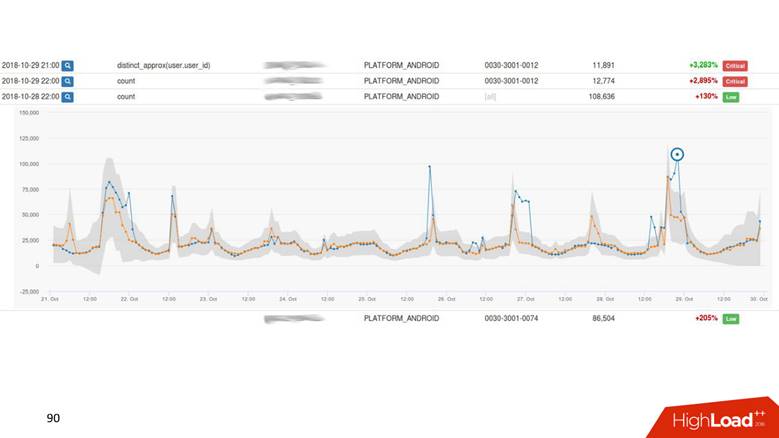
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .