引言
Netcracker是一家国际公司,是集成IT解决方案的开发人员,其中包括用于客户端设备的放置和支持服务以及为电信运营商托管已创建的IT系统的服务。
这些主要是与电信运营商的业务活动组织有关的决定。 可以在
这里找到更多详细信息。
正在开发的解决方案的持续可用性非常重要。 如果电信运营商停止工作至少一个小时,这将对运营商和软件提供商造成巨大的财务和声誉损失。 因此,该解决方案的关键要求之一是
可用性参数,其值从99.995%到99.95%不等,具体取决于解决方案的类型。
该解决方案本身是一套复杂的中央整体IT系统,包括位于公共云中的复杂电信设备和服务软件,以及与中央核心集成的许多微服务。
因此,对于支持团队来说,监视集成到单个解决方案中的所有硬件和软件系统非常重要。 大多数情况下,公司使用传统监控。 这个过程是建立良好的:我们可以从头开始构建类似的监视系统,并且我们知道如何正确组织事件响应过程。 但是,从项目到项目,我们在这种方法中面临一些困难。
- 监控什么
当前哪个指标很重要,将来哪个指标很重要? 这里没有确切的答案,因此我们尝试监视所有内容 。 难度第一-指标数量。 存在性能问题,操作仪表板越来越类似于航天器控制面板。
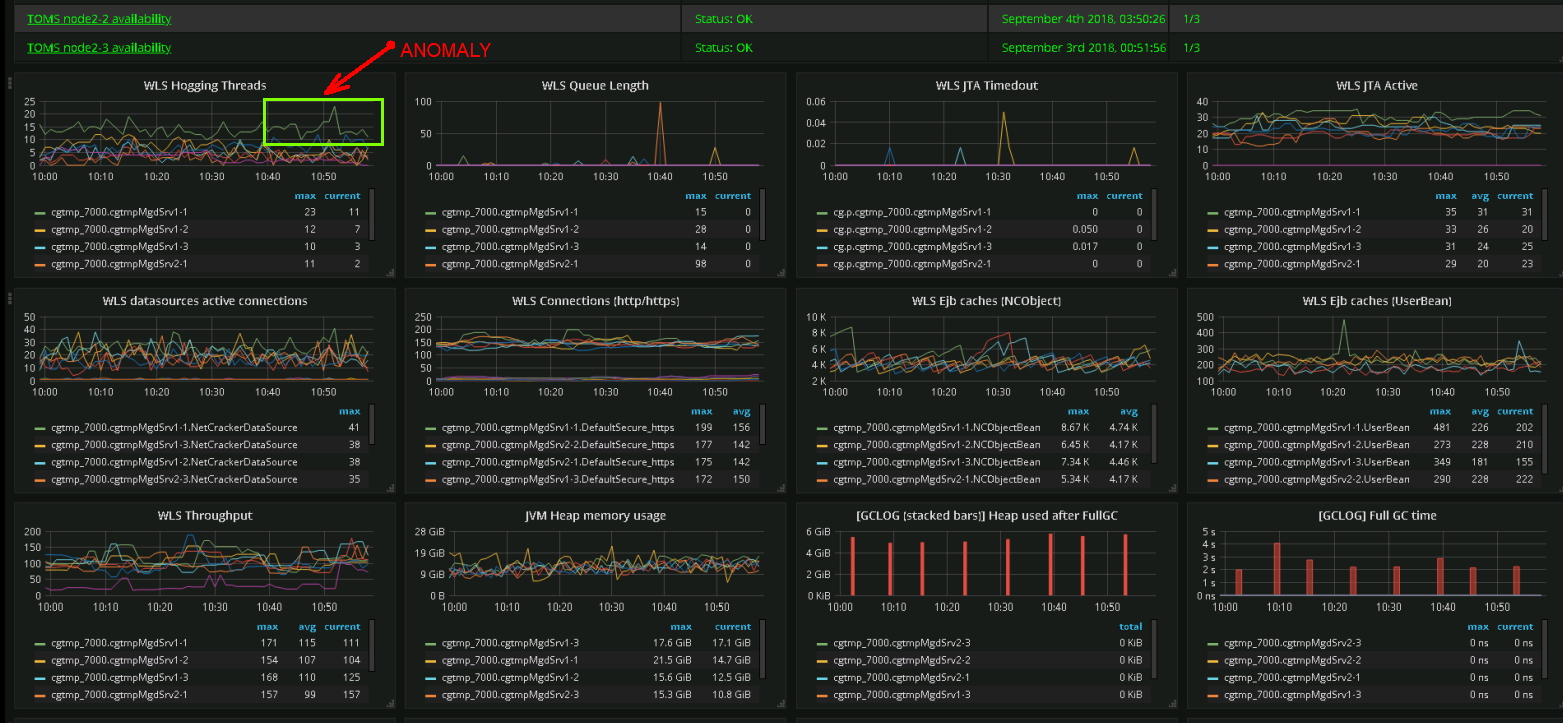
真实仪表板的屏幕截图。 支持团队工程师可以根据其图形表示来识别系统行为中的异常
- 警报/阈值
尽管我们有操作许多大型系统的经验,但是由于所用设备的详细信息和各个供应商的软件版本,监视它们仍然是一项艰巨的任务。 经验和现成的规则通常不能完全从一种解决方案转移到另一种解决方案。 有一些基本设置,其改进是迭代进行的,例如分析由解决方案操作引起的事件。
第二个困难是缺乏明确的定制规则。 - 结果解释
发生事件时,快速定位它非常重要。 这在很大程度上取决于支持团队的经验,因为在有关失败的第二条消息的指导下,您无法注意到问题的根本原因,并且无法快速响应。 这是复杂性三。
在适当组织的流程的帮助下,团队可以解决上述难题,但是,现代的要求做出被动响应的决策(当从想法到实施的时间以天为单位进行测量时)使任务变得非常复杂。 需要持续的团队培训。 不断的变化导致以下事实,即某些规则和因果关系失去了意义,结果,未能及时解决的事件可能会变成事故。
机器学习如何帮助我们
硬件和软件系统故障的预测已成为预防或响应事件的非常普遍的功能。 我们的母公司
NEC Corporation在开发监控方案方面投入了大量资金。 这项投资的结果是获得专利的
系统不变分析技术(SIAT) 。
SIAT是一种机器学习技术,在以时间序列表示的传感器或度量数据集中,使用ML算法查找恒定的功能关系并建立通用模型-这些关系的图表。 详细信息可以在
这里找到。
该图说明了在物理对象的传感器之间发现的关系
此想法最初是为IT系统开发的,目前仅在监视工厂,工厂,核电厂等物理设施时传播。 例如,
洛克希德·马丁公司在其空间部门中
实施了这些技术。 在2018年,
Netcracker与
NEC一起重新考虑了这个想法,并创建了一种适合监视IT系统的产品,作为其他分析的工具。
重要提示 :这只是监视系统的补充,而不是其替代。
SIAT用于IT系统的应用
物理复合体和软件之间有什么区别? 在软件系统中,使用物理指标,即传感器。 由于物理传感器始终物有所值,并且仅放置在有意义的位置,因此使用了更多度量。 如果适当地组织软件度量标准,则不会花费任何费用。 另外,信息系统的数据度量要正确地内插到系统状态要困难得多。 人们更容易理解与物理世界有关的传感器,而软件指标的特定值仅与特定的硬件,配置和负载有关才有意义。
该模型中的
功能互连还假设,如果我们更换硬件或软件版本(例如OS补丁程序),并且所有操作都变得同样快或慢,则由于我们没有进行更改,因此不会导致关于事故的错误消息
门槛 。 如果度量标准不再相互关联,则意味着与系统行为规范不符。 此外,
SIAT技术甚至可以检测到实时行为中的微小偏差,包括所谓的
静默故障 -没有任何错误消息的故障。 如果这种偏差只是更大失败的预兆,我们就有时间做出正确反应。
我们通过在负载下模拟小型Apache Web Server并使用
Linux上的
Fault Injection机制模拟内部错误来验证此语句。
结果以数值度量“
异常得分”的形式表示,其值与此模型相关。 值越大,失败越严重:度量标准异常行为越多。 限制值为100%的指标异常,系统无法正常工作。 此外,结果表明那些指标,其当前行为可被视为异常。 这极大地加快了对原因的分析并确定了当前行为模型中当前出现故障的子系统。
通常,
SIAT甚至可以使
您对行为的微小变化做出响应,而使用传统或基准监视几乎无法检测到。
该图说明了传感器之间关系的干扰
SIAT的另一个优点是用于构建行为模型的算法,该行为模型不需要指示度量的任何业务意义。 该算法自动选择行为相互关联的所有度量,并且此关系是恒定的。 其余孤立的度量标准要么是不影响IT解决方案的点子系统,要么是目前对解决方案状态不重要的度量标准。 如果有意义,则在基于
阈值警报的传统方法的框架中实施对此类指标的监视。
建立模型需要与系统正常运行相关的数据,
这一点非常重要 ,这比进行事故训练时
要简单得多。
如果行为已更改或我们向模型添加了新的指标,则会进一步完善和重建模型。
由于系统的正常行为是可变的特性(取决于一天中的时间和其他业务状况),为了获得更准确的响应,有必要创建几个描述某些情况下系统行为的模型。
该过程是什么样的
监视组织过程如下。
- 我们开始传统的监控。 正确选择度量名称非常重要。 事实是,结果中包含行为异常的度量标准名称,这意味着度量标准越准确地描述位置和含义,就可以更快地获得结果。 例如,一个名为ncp的指标。 erp_netcracker _com.apps.erp。 clust4.wls .jdbc。 LMSDataSource 。 ActiveConnectionsCurrentCount指示在Netcracker ERP系统中 ,名为ActiveConnectionsCurrentCount的度量标准在LMSDataSource的第四个Weblogic群集上失败 。 对于专家而言,这样的信息足以准确定位异常。
- 接下来,我们与指标数据存储系统(在本例中为ClickHouse)集成 ,并获得解决方案正常行为在特定时期内所有指标的数据:最佳模型基于30天的监视结果构建。 为了获得更准确的模型,我们每分钟使用指标数据而没有任何汇总。
- 我们基于来自监控系统的数据使用SIAT建立模型。 在构造模型的框架内,我们根据相似度过滤功能关系。 简而言之,这是行为与给定行为的偏离程度,以百分比表示。
- 我们根据前几天的数据检查该模型,该数据是使用传统的监视和支持团队检测到故障的。
- 我们开始在线监视:每10分钟,所有指标的数据都会传输到一个或多个模型中。 我们得到结果-异常分数,如果结果不为零,那么我们还会获得当前行为异常的指标列表。
- 结果被发送到通用监视系统,在该系统中它成为通用仪表板和其他传统监视工具的一部分。
测验
未经验证,不会发生任何单一实现。 作为经过测试的系统,我们选择了自己的
ERP (整体式,
Weblogic ,
Oracle ,4500个指标)和整个监控系统的路由系统,每分钟700万个指标,-
碳 -
碳中继 (1200个指标)。
将所有指标的转储用作输入,还指出了记录故障的日期。 为了评估结果,我们引入了以下概念:
- 第二种错误的数量是当传统的监视系统或支持团队发现故障时,而SIAT却没有。
- 正确检测的次数-传统监测和SIAT都检测到问题时。
- 第一种错误的数量-当SIAT检测到行为偏差,但支持团队未找到它时。
对于两个测试的系统,我们都没有发现第二种错误。 正确检测的次数
-SIAT发现的故障总数的85%,并且在设备故障的情况下-数据库上的RAID阵列
发生故障-SIAT在到达前七个小时检测到行为降级,并准确指示了与数据库相关的指标在监控系统中设置阈值。
所指示的
SIAT失败中剩余的15%是第一类错误-支持团队无法解释的异常行为。 这可能是由于以下事实:在构建模型时,会自动包含具有功能含义的那些指标,但不会对系统的总体行为产生明显影响。 在几次误报之后,IT专家可以事先将这些指标标记为不重要,并将其从模型中删除,然后再与
SME达成一致。
结果表明,该产品完全自动化了检测故障(包括隐藏故障),及时定位事件并评估其规模的过程。
接下来是什么
现在,我们正在积累用于各种类型的硬件和软件系统的产品操作经验,以便分析此方法对各种系统的适用性:网络设备,
IoT设备,云微服务等。
目前,重建模型的任务是瓶颈。 这需要大量的计算能力,但是幸运的是,可以在隔离的计算机上执行重新计票,将结果导出为最终模型。 实时监视本身不需要大量资源,并且与传统监视在同一设备上并行执行。
结论
总结一下,我想指出的是,结合使用传统的监视技术和机器学习算法,您可以构建一个简单的模型,该模型可以帮助您及时做出响应,找出问题的根源,并使系统保持正常运转。
除了有希望的
SIAT技术之外,我们还在分析使用另一种
NEC技术的可能性-
下一代Log Analytics 。 该技术允许使用机器学习算法和系统日志来确定与产品内部状态相关的异常,这些异常不会影响系统的整体性能。
您使用什么分析来监视IT系统?