
数据科学领域的传统工具是R和Python之类的语言-宽松的语法以及大量用于机器学习和数据处理的库,可让您快速获得一些可行的解决方案。 但是,在某些情况下,这些工具的局限性成为一个重大障碍-首先,如果您需要在处理速度和/或使用非常大的数据集方面实现高性能。 在这种情况下,专家必须无奈地求助于“阴暗面”的帮助,并以“工业”编程语言( Scala , Java和C ++)连接工具。
但是这面那么黑吗? 经过多年的发展,“工业”数据科学的工具已经走了很长一段路,今天,它们与2-3年前的版本大不相同。 让我们尝试使用SNA Hackathon 2019任务的示例来弄清楚Scala + Spark生态系统可以对应Python Data Science多少。
在SNA Hackathon 2019的框架内,参与者解决了以下三种“学科”之一中对社交网络用户的新闻提要进行排序的问题:使用文本,图像或功能日志中的数据。 在本出版物中,我们将研究在Spark中如何使用经典的机器学习工具基于符号对数来解决问题。
在解决问题时,我们将遵循任何数据分析专家在开发模型时所遵循的标准路径:
- 我们将进行研究数据分析,绘制图表。
- 我们分析数据中符号的统计特性,查看它们在训练集和测试集之间的差异。
- 我们将根据统计属性对特征进行初步选择。
- 我们计算符号与目标变量之间的相关性,以及符号之间的互相关性。
- 我们将形成最后一组功能,训练模型并检查其质量。
- 让我们分析模型的内部结构以识别增长点。
在我们的“旅途”中,我们将熟悉Zeppelin交互式笔记本, Spark ML机器学习库及其扩展PravdaML , GraphX 图形包, Vegas可视化库,当然还有Apache Spark等所有工具: ) 所有代码和实验结果都可以在Zepl协作笔记本平台上获得 。
资料载入
在SNA Hackathon 2019上展示的数据的独特之处在于可以使用Python直接对其进行处理,但是这很困难:由于Apache Parquet列格式的功能,原始数据得到了非常有效的打包,并且当``按额头''读入内存时,它被解压缩为数十GB。 使用Apache Spark时,不需要将数据完全加载到内存中,Spark体系结构旨在处理分段数据,并根据需要从磁盘加载。
因此,第一步是使用盒装工具轻松执行按天检查数据分布的操作:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
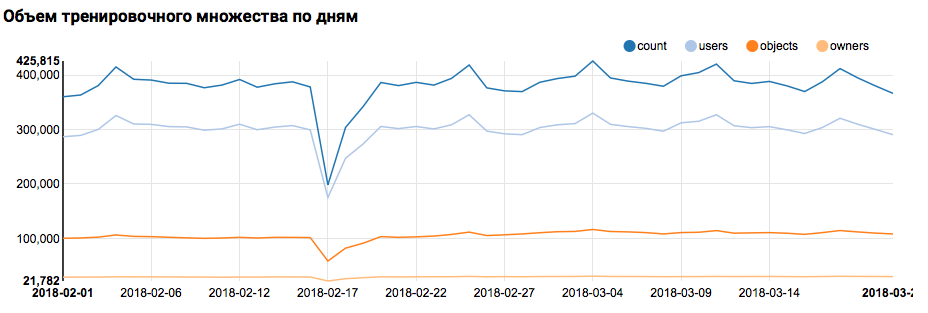
相应的图形将在Zeppelin中显示什么:
我必须说Scala语法非常灵活,例如,相同的代码可能看起来像这样:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
这里应该发出一个重要的警告:当在一个大型团队中工作时,每个人都从自己的品味角度着手编写Scala代码,而交流则要困难得多。 因此,最好开发出统一的代码风格概念。
但是回到我们的任务。 每天进行的简单分析显示,在2月17日和18日出现了异常点; 可能这几天收集的数据不完整,性状的分布可能有偏差。 在进一步分析中应考虑到这一点。 此外,令人惊讶的是,唯一身份用户数与对象数非常接近,因此研究具有不同对象数的用户分布是有意义的:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
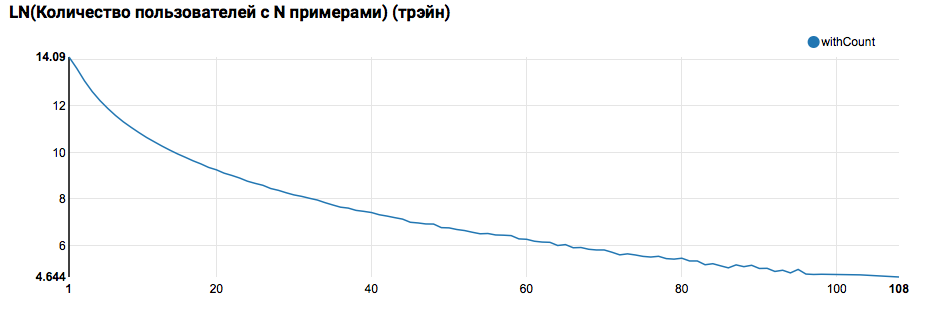
预计将看到接近指数分布,尾巴很长。 通常,在此类任务中,可以通过细分具有不同活动级别的用户的模型来提高工作质量。 为了检查是否值得这样做,请比较用户在测试集中的对象数量分布:
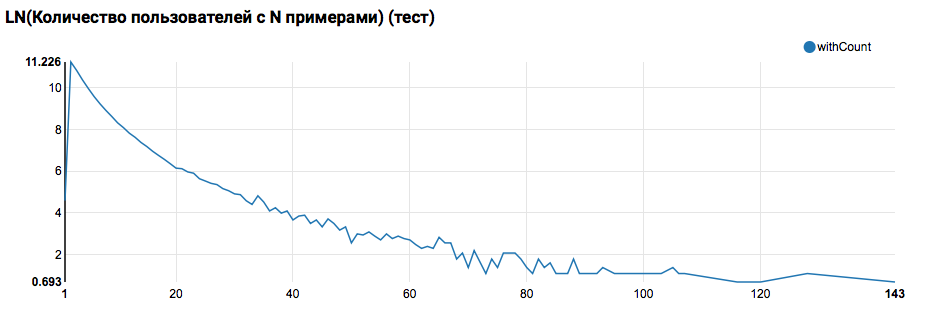
与测试的比较表明,测试用户的日志中至少有两个对象(由于在黑客马拉松上解决了排名问题,这是评估质量的必要条件)。 将来,我建议您仔细查看培训集中的用户,为此我们使用过滤器声明“用户定义的函数”:
在这里还应该指出一个重要的观点:从定义UDF的角度来看,Scala / Java和Python下对Spark的使用截然不同。 虽然PySpark代码使用基本功能,但一切工作几乎都一样快,但是当出现被覆盖的功能时,PySpark的性能将降低一个数量级。
第一条ML管道
在下一步中,我们将尝试计算有关操作和属性的基本统计信息。 但是为此,我们需要SparkML的功能,因此首先我们来看一下其一般架构:

SparkML是基于以下概念构建的:
- 变压器-将数据集作为输入并返回修改后的集(变换)。 通常,它用于实现预处理和后处理算法,特征提取,还可以表示生成的ML模型。
- 估计器-将数据集作为输入,并返回Transformer(拟合)。 自然,估计器可以表示ML算法。
- 管道是估算器的一种特例,它由一系列变压器和估算器组成。 调用该方法时,fit通过链,如果它看到一个转换器,则将其应用于数据,如果它看到一个估计器,则对其进行训练,将其应用于数据,然后继续。
- PipelineModel-Pipeline的结果在内部也包含一个链,但仅由变压器组成。 因此,PipelineModel本身也是一个转换器。
这种形成ML算法的方法有助于实现清晰的模块化结构和良好的可重复性-可以节省模型和管线。
首先,我们将建立一个简单的管道,通过该管道我们可以计算出训练集中用户的动作分布(反馈字段)的统计信息:
val feedbackAggregator = new Pipeline().setStages(Array(
在此管道中,将积极使用PravdaML的功能-具有扩展的SparkML有用块的库,即:
- MultinominalExtractor用于根据“一键通”原理将“字符串数组”类型的字符编码为矢量。 这是管道中的唯一估算器(要构建编码,必须从数据集中收集唯一的行)。
- VectorStatCollector用于计算向量统计信息。
- VectorExplode用于将结果转换为便于可视化的格式。
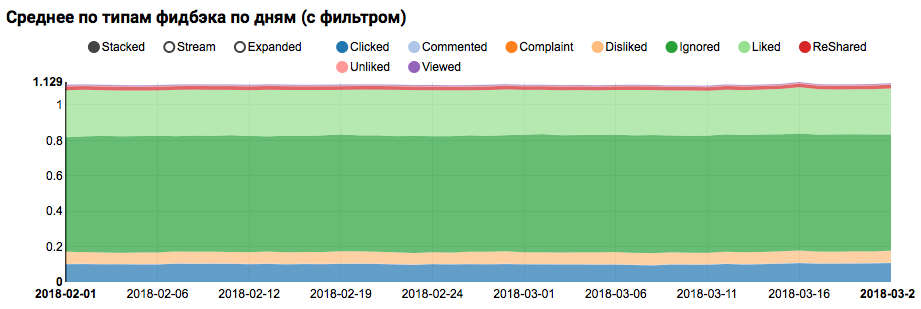
工作的结果将是一张图表,显示数据集中的类不平衡,但是目标Liked类的不平衡不是极端的:

对与测试用户相似的用户之间相似分布的分析(日志中同时具有“正”和“负”)表明,它偏向正类别:
标志的统计分析
在下一阶段,我们将对属性的统计属性进行详细分析。 这次我们需要更大的输送机:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
从现在开始,我们不需要使用单独的字段,而是要同时处理所有属性,我们将使用两个更有用的PravdaML实用程序:
- NullToDefaultReplacer允许您将数据中缺少的元素替换为其默认值(0表示数字,false表示逻辑变量,等等)。 如果不执行此转换,则NaN值将出现在结果向量中,这对许多算法来说都是致命的(尽管例如XGBoost可以幸免于此)。 NaNToMeanReplacerEstimator中实现了用零替代的替代方法是用平均值替代。
- AutoAssembler是一个非常强大的实用程序,可以分析表布局,并为每列选择与列类型匹配的矢量化方案。
使用生成的管道,我们计算三组统计信息(培训,用户过滤器培训和测试)并将其保存在单独的文件中:
接收了三个具有属性统计信息的数据集后,我们分析了以下内容:
- 我们是否有排放量大的标志?
-应该限制这种迹象,或者应该过滤掉异常记录。 - 相对于中位数,我们的平均偏差是否大?
-这种偏移通常发生在配电的情况下,对数这些符号是合理的。 - 训练和测试集之间的平均分布是否有变化。
- 如何紧密填充我们的特征矩阵。
为了澄清这些方面,这样的请求将帮助我们:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
在此阶段,可视化问题迫在眉睫:使用常规的Zeppelin工具很难立即显示所有方面,并且由于DOM膨胀,带有大量图形的笔记本开始显着放慢速度。 Scala上的Vegas -DSL库用于构建vega-lite规范可以解决此问题。 Vegas不仅提供了更丰富的可视化功能(与matplotlib相当),而且还可以在Canvas上绘制它们而不会膨胀DOM :)。
我们感兴趣的图表规格将如下所示:
vegas.Vegas(width = 1024, height = 648)
下图应如下所示:
- X轴显示测试和训练集之间分布中心的移动(越接近0,符号越稳定)。
- 沿Y轴绘制非零元素的百分比(数值越高,表示属性的点数越多,数据越多)。
- 大小显示平均值相对于中位数的位移(点越大,幂定律分布的可能性越大)。
- 颜色表示排放(越红,排放越多)。
- 好吧,这种形式的区别在于比较模式:训练集中有用户过滤器或没有过滤器。
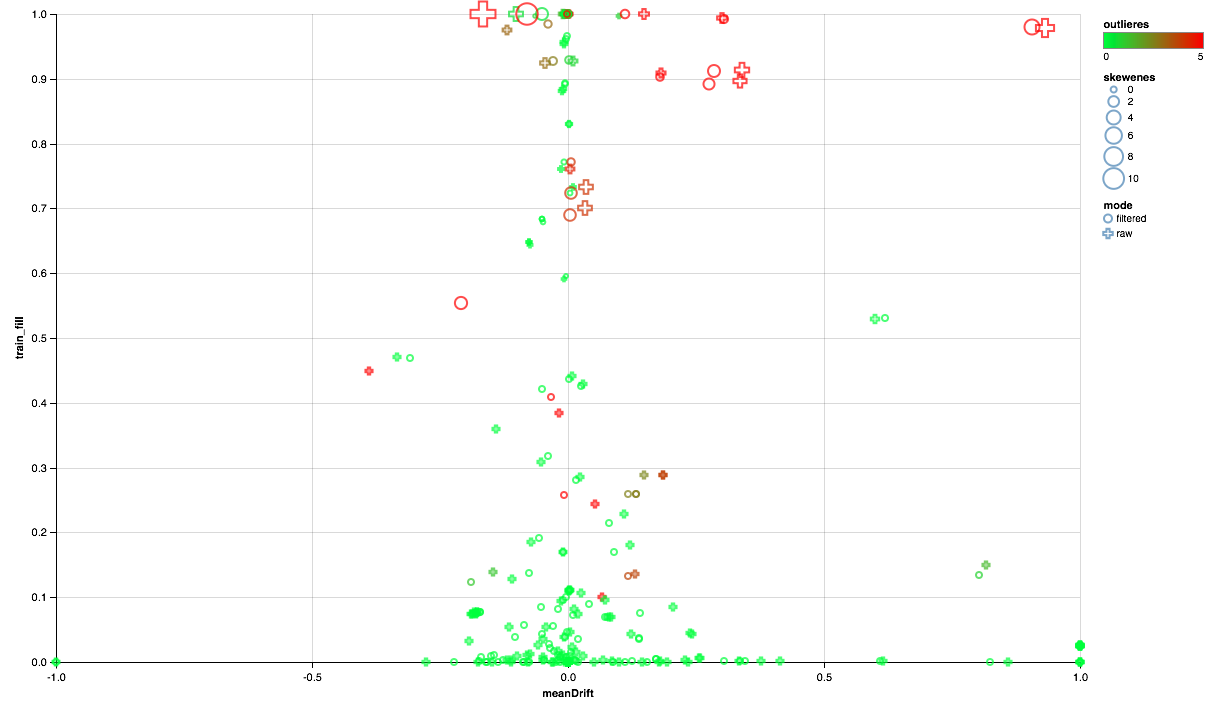
因此,我们可以得出以下结论:
- 有些标志需要发射过滤器-我们将限制90%的最大值。
- 一些迹象表明分布接近指数-我们将采用对数。
- 测试中未提供某些功能-我们将其排除在培训范围之外。
相关分析
在大致了解属性如何分布以及它们在训练集和测试集之间的关系之后,让我们尝试分析相关性。 为此,请根据以前的观察结果配置特征提取器:
在此管道中的新机器中,SQLTransformer实用程序引起了人们的注意,它允许对输入表进行任意SQL转换。
在分析相关性时,重要的是要滤除由一个热点特征的自然相关性产生的噪声。 为此,我想了解向量的哪些元素对应于哪些源列。 Spark中的此任务使用列元数据(与数据一起存储)和属性组完成。 以下代码块用于过滤来自同一字符串类型的同一列的属性名称对:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
拥有一个带有向量列的数据集,使用Spark计算互相关非常简单,但是结果是一个矩阵,要部署该矩阵,您将需要一点点成对地进行操作:
val pearsonCorrelation =
当然,还有可视化:我们将再次需要Vegas的帮助来绘制热图:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
结果最好在Zepl-e中查看。 大致了解:
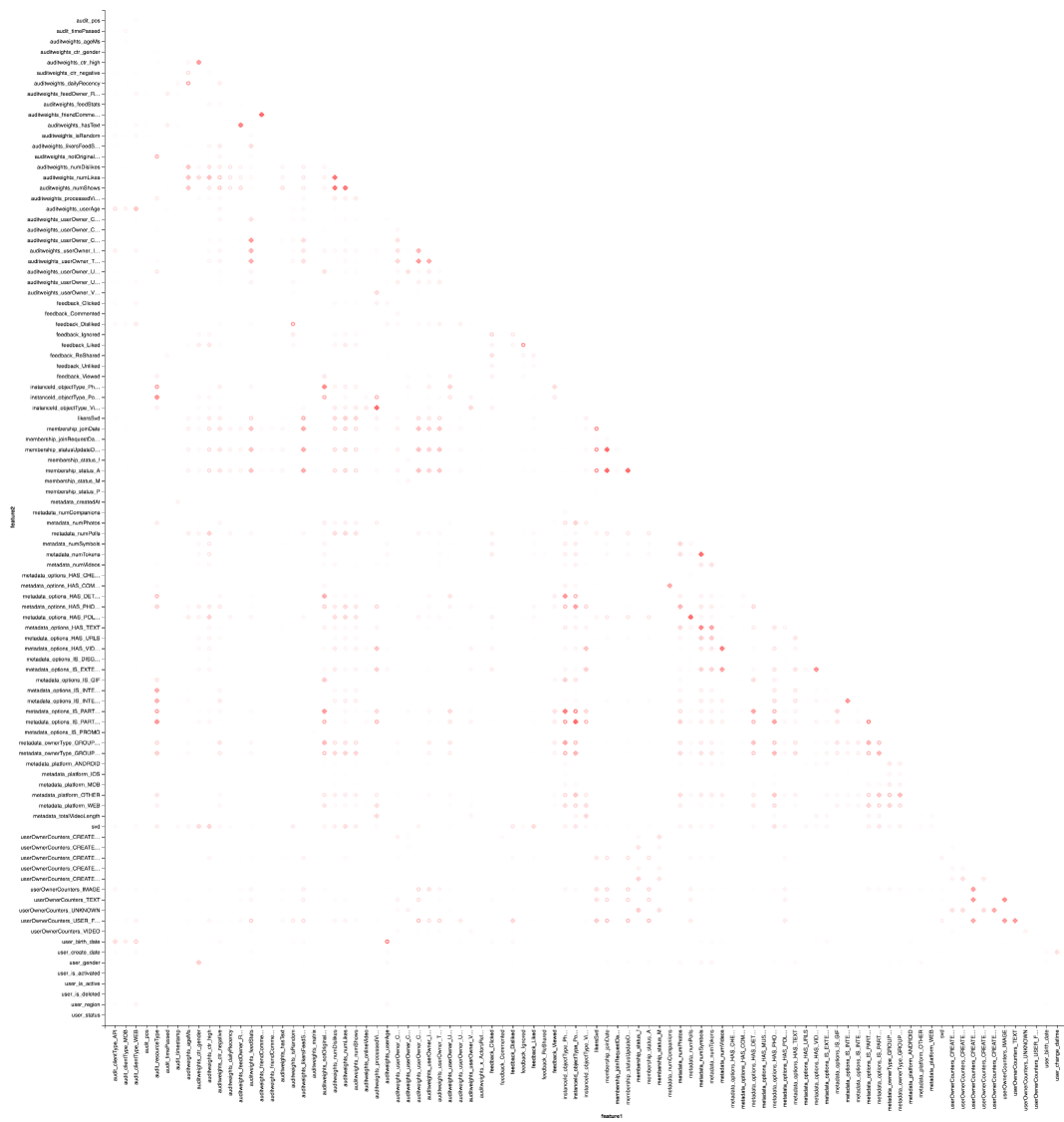
热图显示一些相关性显然存在。 让我们尝试选择具有最强相关性的功能块,为此我们使用GraphX库:将相关性矩阵转换为图形,按权重过滤边缘,然后找到连接的组件并仅保留未退化的组件(来自多个元素)。 这样的过程本质上类似于DBSCAN算法的应用,如下所示:
结果以表格形式显示:
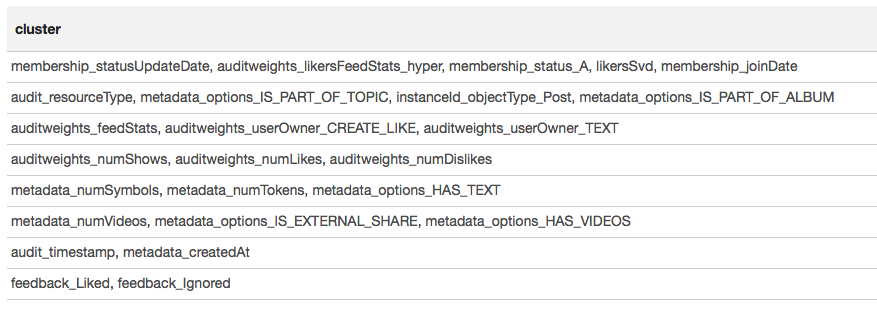
根据聚类的结果,我们可以得出结论,最相关的组围绕与该组中的用户成员身份相关的符号(membership_status_A)以及对象类型(instanceId_objectType)形成。 为了对符号交互进行最佳建模,有必要应用模型细分-为不同类型的对象训练不同的模型,分别针对用户所在或不在的组进行训练。
机器学习
我们采用最有趣的方法-机器学习。 使用SparkML和PravdaML扩展来训练最简单的模型(逻辑回归)的管道如下:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
在这里,我们不仅看到许多熟悉的元素,而且还看到了几个新元素:
- LogisticRegressionLBFSG是对Logistic回归进行分布式训练的估计器。
- 为了从分布式ML算法中获得最大性能。 数据应最佳地分布在分区之间。 UnwrappedStage.repartition实用程序将对此有所帮助,将重新分区操作添加到管道中,使其仅在训练阶段使用(毕竟,在构建预测时,不再需要)。
- 这样线性模型可以给出很好的结果。 必须缩放数据,由Scaler.scale实用程序负责。 但是,两个连续的线性变换(按比例缩放和乘以回归权重)的存在会导致不必要的开销,并且希望折叠这些运算。 使用PravdaML时,输出将是带有一个转换的纯净模型:)。
- 好吧,当然,对于此类模型,您需要一个免费成员,我们使用Interceptor.intercept操作将其添加。
应用于所有数据的结果管道将为每个用户提供AUC 0.6889(验证代码可在Zepl上获得 )。 现在仍然可以应用我们的所有研究:过滤数据,变换特征和分段模型。 最终的管道如下所示:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
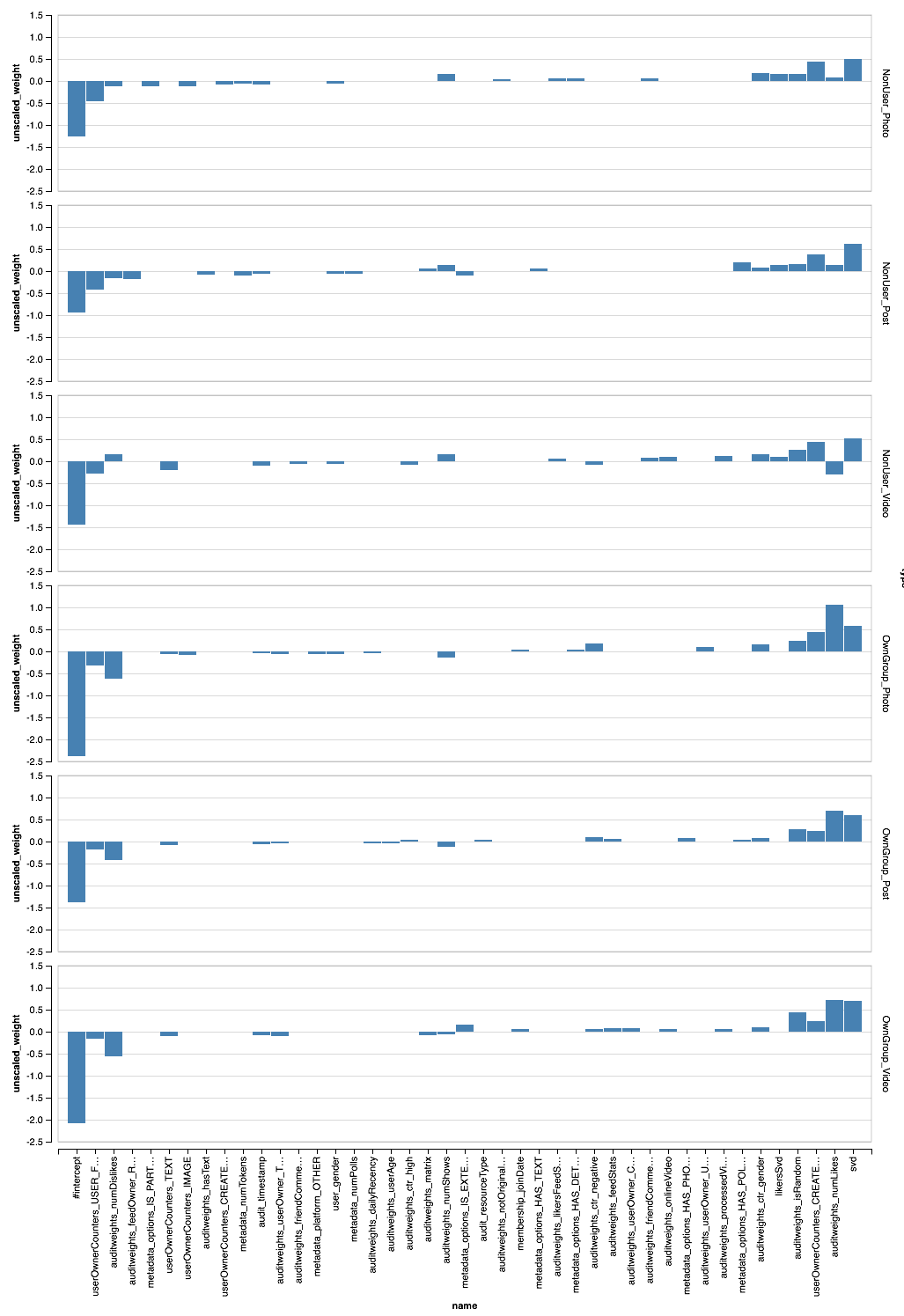
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
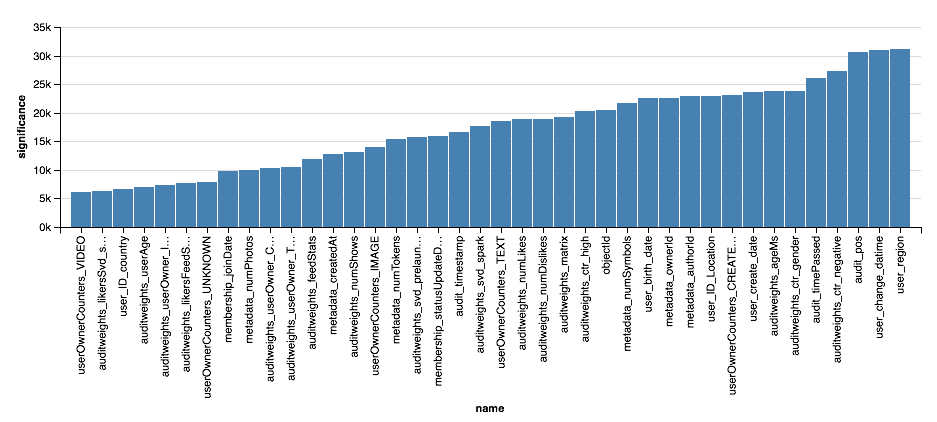
, , XGBoost, , . . , XGBoost , , .
结论
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .