
与数据库有关的任何进程迟早都会遇到对该数据库的查询性能问题。
Rostelecom的数据仓库建立在Greenplum上,大多数计算(转换)由sql查询执行,这些查询启动(或生成并运行)ETL机制。 DBMS有其自身的细微差别,会严重影响性能。 本文旨在强调在性能和共享经验方面与Greenplum合作的最关键方面。
简而言之GreenplumGreenplum-
MPP数据库服务器,其核心基于PostgreSql。
表示PostgreSql流程的几个不同实例(实例)。 其中一个是客户端的入口点,称为主实例(master)(其他实例),所有其他实例均称为Segment实例(segment,Independent实例,每个实例都有自己的数据)。 每个服务器(段主机)可以从一个服务运行到多个服务(段)。 这样做是为了更好地利用服务器资源,主要是处理器。 该向导存储元数据,负责与客户端进行数据通信,还可以在段之间分配工作。
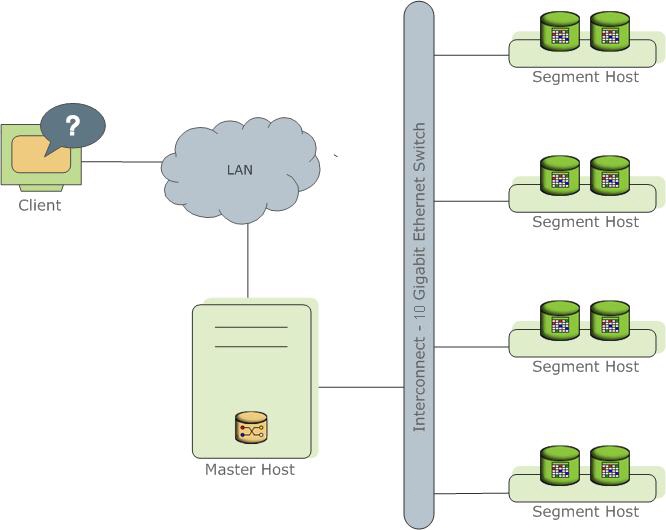
在
官方文档中阅读更多
内容 。
在本文的进一步内容中,将有许多对请求计划的引用。 有关Greenplum的信息,请
点击此处 。
如何在Greenplum上编写好的查询(很好,或者至少不太难过)
由于我们正在处理分布式数据库,因此不仅重要的是如何编写sql查询,而且如何存储数据也很重要。
1.发行
数据实际存储在不同的段中。 您可以按段随机划分数据,也可以按一个字段或一组字段的哈希函数值分隔数据。
语法(创建表时):
DISTRIBUTED BY (some_field)
大概:
DISTRIBUTED RANDOMLY
分配字段应具有良好的选择性,并且不应具有空值(或具有最小值),因为具有此类字段的记录将分布在一个段上,这可能导致数据失真。
字段类型最好是整数。 该字段用于联接表。 哈希联接是联接表的最佳方法之一(就查询执行而言),最适合此数据类型。
对于分发,建议选择不超过两个字段,当然,一个字段胜于两个字段。 分发键中的其他字段首先需要额外的哈希时间,其次,(在大多数情况下)执行连接时需要在段之间传输数据。
如果您无法选择一个或两个合适的字段以及小的标签,则可以使用随机分布。 但是我们必须考虑到这样的分布最适合海量数据插入,而不是一条记录。 GreenPlum根据
循环算法分配数据,并从第一段开始为每个插入操作启动一个新的周期,该段在频繁插入的情况下会导致偏斜(数据偏斜)。
使用精心选择的分布字段,所有计算将在该段上执行,而无需将数据发送到其他段。 另外,为实现表的最佳联接(联接),应将相同的值放在同一段上。
在所有表中,联接中使用的字段类型必须相同。
重要提示:请勿将用于过滤查询的位置用作分发字段,因为在这种情况下,查询期间的负载也不会平均分配。
2.分区
通过分区 ,您可以将大型表(例如
事实 )划分为逻辑上分开的部分。 Greenplum在物理上将您的表分为几个单独的表,每个表都根据第1页中的设置分为几个部分。
表应在逻辑上划分为多个部分,为此,请选择where块中经常使用的字段。 实际上这就是表。 因此,通过正确访问查询中的表,您将只处理整个大表的一部分。
通常,分区是一个相当知名的主题,我想强调一下,您不应为分区和分发选择相同的字段。 这将导致以下事实:该请求将完全在一个段上执行。
实际上,是时候处理这些请求了。 该请求将根据特定
计划按段执行:
3.优化器
Greenplum有两个优化器,内置的遗留优化器和第三方Orca优化器:GPORCA-Orca-关键查询优化器。
根据要求启用GPORCA:
set optimizer = on;
通常 ,GPORCA优化器要优于内置优化器。 它更适合与子查询和
CTE配合使用 (更多详细信息请参见
此处 )。
使用最大的数据过滤功能(不要忘记分区修剪)和显式指定的字段列表对CTE中的大型表进行了调用-效果很好。
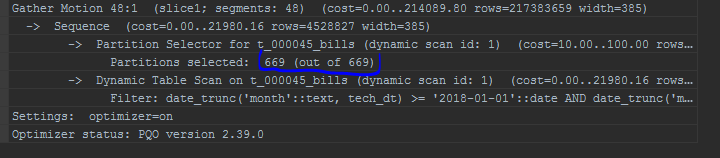
例如,它会稍微修改查询计划,否则显示扫描的分区:
标准优化程序: 逆戟鲸:
逆戟鲸:
GPORCA还允许更新分区/分发字段。 尽管在某些情况下内置优化器的性能更好。 第三方优化器对统计信息的要求很高,重要的是不要忘记
分析 。
无论优化器多么出色,编写不当的查询都不会拉伸Orca:
4.使用where块或联接条件中的字段进行操作
重要的是要记住,应用于过滤器字段的函数或联接条件应用于
每个记录。
对于分区字段(例如,分区字段的date_trunc-date),即使GPORCA在这种情况下也无法正常工作,因此
剪切分区将不起作用。
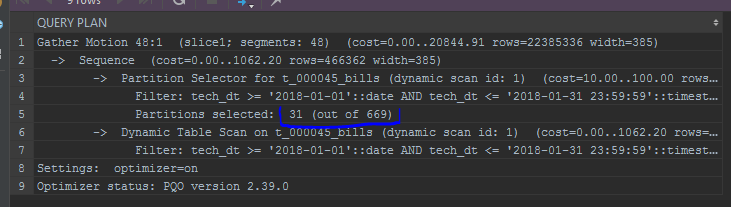 我还提请注意分区的显示。 内置的优化器将在列表中显示分区:
我还提请注意分区的显示。 内置的优化器将在列表中显示分区:
仔细将函数应用于相同分区过滤器中的常量。 一个示例是相同的date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCA将完全应付这样的麻烦,并且将正常工作,标准优化器将不再应付。 但是,通过进行显式类型转换,可以使其工作:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

如果一切都做错了?
5.动作
在
查询计划中可以观察到的另一种操作类型是运动。 因此,段之间的数据移动明显:
- 聚集运动 -将在几乎所有计划中显示,这意味着将来自所有段的查询执行结果组合到一个流(通常是到主流)中。
由一个键分布的两个表(用于联接)对段执行所有操作,而无需移动数据。 否则,将发生广播动作或重新分发动作: - 广播运动 -每个段将其数据副本发送到其他段。 在理想情况下,仅对小表进行广播。
- 重新分布运动 -为了联接分布在不同键上的大型表,执行重新分布以在本地建立连接。 对于大表,这可能是相当昂贵的操作。
广播和重新分发是非常不利的操作。 它们在每次运行请求时执行。 建议避免使用它们。 在查询计划中看到了这些要点之后,就应该注意分发键。 异类和联合操作也会引起运动。
这份清单并不详尽,主要是基于作者的经验。 一次无法在Internet上立即找到所有内容,这是行不通的。 在这里,我试图找出影响请求性能的最关键因素,并了解为什么以及为什么发生这种情况。
本文由Rostelecom数据管理团队编写