“有了经验,就会出现一种标准的科学方法来计算正确的纸叠大小:取一个随机数,并希望获得最佳。”
-Jack Ganssle,“嵌入式系统设计的艺术”哈Ha!
看起来很奇怪,在我特别看到的绝大多数“ STM32入门”以及一般的微控制器中,内存分配,堆栈放置以及最重要的是防止内存溢出等问题都没有,因为一个区域会磨损另一区域,并且一切都会崩溃,通常具有迷人的效果。
这部分是由于使用相对较油腻的微控制器在调试板上进行的培训项目的简单性,在这种情况下很难通过闪烁LED来陷入内存不足的问题-但是,最近,即使对于初学者,也越来越多地引用STM32F030F4P6类型的控制器。 ,易于安装,值得一分钱,而且还带有千字节的存储单元。
这样的控制器可以让您自己做很认真的事情(例如,在这里,我们在STM32F042K6T6上为我们做了一个非常
合适的测量 ,它具有6 KB的RAM,其中剩余100多个字节可用),但是在处理内存时,您需要一定数量的内存整洁。
我想谈谈这种准确性。 本文将简短,专业人士将不会学习任何新知识-但对于初学者,强烈建议您学习这些知识。
在基于Cortex-M内核的微控制器的典型项目中,RAM有条件地分为四个部分:
- 数据-由特定值初始化的数据
- bss-数据初始化为零
- 堆-堆(使用malloc从中显式分配内存的动态区域)
- stack-堆栈(编译器隐式从中分配内存的动态区域)
noinit区域也可能偶尔出现(未初始化的变量-它们很方便,因为它们在重新启动之间保留了值),甚至为某些分配给特定任务的其他区域也很少出现。
它们以相当特定的方式位于物理内存中-实际上,ARM内核上的微控制器堆栈从上到下增长。 因此,它与其余存储块分开位于RAM的末尾:
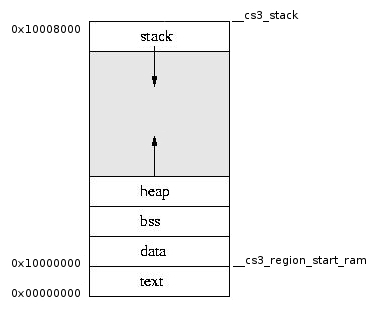
默认情况下,它的地址通常等于最新的RAM地址,并且随着它的增长它从那里开始递减-并且堆栈的一个极其不愉快的功能也逐渐消失了:它可以到达bss并重写其顶部,并且您不会以任何明确的方式知道它。
静态和动态存储区
所有内存分为两类-静态分配,即 内存,其总量从程序文本中是显而易见的,并且不取决于其执行顺序,而是动态分配的,其动态分配量取决于程序的进度。
后者包括一个堆(使用malloc从中取出大块,然后使用free返回)和一个自身增长和收缩的堆栈。
一般来说,
强烈建议不要在微控制器上使用malloc,除非您确切地知道自己在做什么。 它们带来的主要问题是内存碎片-如果您分配10个10字节,然后每秒释放一次,那么您将不会获得50个字节。 您将获得5个免费的片段,每个片段10个字节。
此外,在编译程序的阶段,编译器将无法自动确定malloc所需的内存(尤其是考虑到碎片化,这不仅取决于请求片段的大小,还取决于它们分配和释放的顺序),因此将无法警告您如果最后没有足够的内存。
有一些方法可以解决此问题-特殊的malloc实现在静态分配的区域(而不是整个RAM)中运行,谨慎使用malloc并考虑程序逻辑级别可能的碎片等。 -但通常
最好不要触摸malloc 。
具有边界和地址的所有存储区都以.LD扩展名注册到文件中,链接器在构建项目时将以该文件为准。
静态分配的内存
因此,从静态分配的内存中,我们有两个区域-bss和数据,它们仅在形式上有所不同。 初始化系统后,将从闪存中复制数据块,并为其存储必要的初始化值,然后简单地将bss块填充为零(至少将其填充为零被认为是一种很好的形式)。
两者-从闪存复制和填充零-都
以显式形式在程序代码
中完成,但不是以main()进行,而是在首先执行的单独文件中进行一次编写,然后只需将其从一个项目拖到另一个项目即可。
但是,这不是我们现在感兴趣的-而是我们将如何了解我们的数据是否适合控制器的RAM。
它可以很容易地被识别-通过具有单个参数的arm-none-eabi-size实用程序-我们程序的编译后的ELF文件(由于方便,通常将其调用插入在Makefile的末尾):

这里的text是闪存中的程序数据量,而bss和data是我们在RAM中静态分配的区域。 最后两列不打扰我们-这是前三列的总和,没有实际意义。
总计,静态地在RAM中,我们需要bss +数据字节,在这种情况下为5324字节。 控制器有6144个字节的RAM,我们不使用malloc,剩下820个字节。
这对我们来说应该足够了。
但是够了吗? 因为如果不这样做,我们的堆栈将增长为我们自己的数据,然后首先将覆盖数据,然后数据将覆盖它,然后所有崩溃。 此外,在第一点和第二点之间,程序可以继续工作,而无需意识到它处理的数据中存在垃圾。 在最坏的情况下,它将是您在堆栈中的所有部分都按顺序排列时写下的数据,而现在您只是读取了(例如某个传感器的校准参数),然后您就没有任何明显的方式来了解它们的所有不良情况,该程序将继续运行,好像什么都没发生一样,使您在输出端出现垃圾。
动态分配的内存
在这里,最有趣的部分开始了-如果将故事简化为一个短语,那么
几乎不可能预先确定堆栈的大小 。
从理论上讲 ,您可以要求编译器提供每个函数使用的堆栈大小,然后要求编译器生成程序的执行树,并针对其中的每个分支计算该树中存在的所有函数的堆栈之和。 仅此一个复杂的程序就将花费您大量的时间。
然后,您记住,随时可能发生中断,其处理器也需要内存。
然后-可能发生两个或三个嵌套的中断,其中的处理程序...
一般来说,您了解。 尝试计算特定程序的堆栈是一项激动人心且通常有用的活动,但通常您不会这样做。
因此,在实践中,使用了一种技术,即至少可以某种方式了解我们生活中的一切是否发展良好的技术-所谓的“内存绘画”(memory painting)。
此方法的便利之处在于它不依赖于您使用的调试工具,并且如果系统至少具有某种输出信息的方式,则可以完全不用调试工具来执行操作。
其本质是在程序执行的最早期阶段,从bss的末尾到栈顶的整个数组,都用相同的值填充。
此外,检查该值在哪个地址已经消失,我们了解堆栈在哪里下降。 由于一旦删除的颜色本身将无法恢复,因此可以偶尔进行检查-它会显示达到的最大堆栈大小。
定义油漆的颜色-特定的值无关紧要,在下面,我仅用左手的两个手指轻击。 最主要的是不要选择0和FF:
#define STACK_CANARY_WORD (0xCACACACAUL)
- , -, :
volatile unsigned *top, *start;
__asm__ volatile ("mov %[top], sp" : [top] "=r" (top) : : );
start = &_ebss;
while (start < top) {
*(start++) = STACK_CANARY_WORD;
}
? top , — ; start — bss (, ,
*.ld — libopencm3). bss .
:
unsigned check_stack_size(void) {
/* top of data section */
unsigned *addr = &_ebss;
/* look for the canary word till the end of RAM */
while ((addr < &_stack) && (*addr == STACK_CANARY_WORD)) {
addr++;
}
return ((unsigned)&_stack - (unsigned)addr);
}
_ebss , _stack —
, , , , .
.
— - check_stack_size() , , , .
.
712 — 6 108 .
Word of caution
— , , 100-% . ,
, , , , . , , -, 10-20 %, 108 .
, , , .
P.S. RTOS — MSP, , PSP. , — .