
第1/3部分
第3/3部分
您好,欢迎回来! 这是在裸机上建立Kubernetes集群的文章的第二部分。 之前我们使用外部etcd,master-master和负载平衡来配置Kubernetes HA集群。 好了,现在是时候设置一个额外的环境和实用程序,以使群集更有用并尽可能接近工作状态了。
在本文的这一部分中,我们将重点介绍配置群集服务的内部负载平衡器-这就是MetalLB。 我们还将在工作节点之间安装和配置分布式文件存储。 我们将对Kubernetes中可用的持久卷使用GlusterFS。
完成所有步骤后,我们的集群图将如下所示:
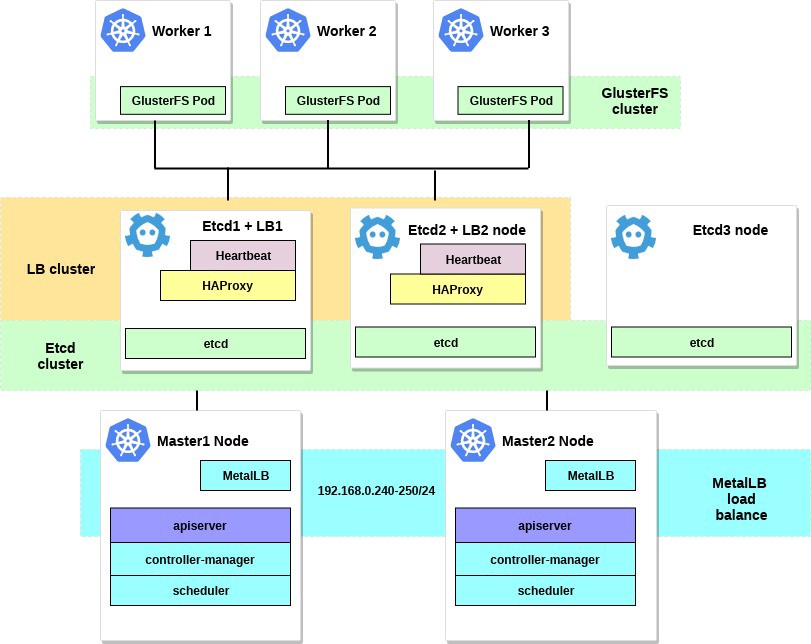
关于MetalLB的几句话,直接来自文档页面:
MetalLB是使用标准路由协议的Kubernetes裸机集群的负载均衡器实现。
Kubernetes不提供用于裸机的网络负载平衡器( 服务类型LoadBalancer )的实现。 Kubernetes随附的所有Network LB实施选项都是中间件,它可以访问各种IaaS平台(GCP,AWS,Azure等)。 如果您不在IaaS支持的平台(GCP,AWS,Azure等)上工作,则LoadBalancer在创建后将无限期保持“待机”状态。
BM服务器运营商有两个效率较低的工具,即NodePort和externalIPs服务,用于将用户流量输入其集群。 这两种选择在生产上都有明显的缺陷,这使BM群成为Kubernetes生态系统中的二等公民。
MetalLB试图通过提供与标准网络设备集成的Network LB实施来纠正这种不平衡,因此BM群集上的外部服务也可以以最快的速度“正常工作”。
因此,使用此工具,我们使用负载平衡器在Kubernetes集群中启动服务,这要归功于MetalLB团队。 设置过程确实非常简单明了。
在示例的前面,我们为群集的需要选择了192.168.0.0/24子网。 现在,将其中一些子网用于将来的负载均衡器。
我们使用配置的kubectl实用程序进入机器系统并运行:
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
这将在metallb-system中的群集中部署MetalLB。 确保所有MetalLB组件均正常运行:
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
现在使用configmap配置MetalLB。 在此示例中,我们使用第2层自定义,有关其他自定义选项的信息,请参见MetalLB文档。
在集群的子网的选定IP范围内的任何目录中创建metallb-config.yaml文件 :
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
并应用以下设置:
control# kubectl apply -f metallb-config.yaml
如有必要,稍后检查并修改configmap:
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
现在我们有了自己配置的本地负载均衡器。 我们以Nginx服务为例,看看它是如何工作的。
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
然后创建一个测试部署和Nginx服务:
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
现在-检查结果:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
如之前部署中所述,创建了3个Nginx Pod。 Nginx服务将根据循环平衡方案将流量定向到所有这些Pod。 您还可以看到从我们的MetalLB负载平衡器收到的外部IP。
现在尝试汇总到IP地址192.168.0.240,您将看到Nginx index.html页面。 切记删除测试部署和Nginx服务。
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
好吧,这就是MetalLB的全部内容,让我们继续-我们将为Kubernetes卷配置GlusterFS。
2.在工作节点上使用Heketi配置GlusterFS。
实际上,没有内部卷就无法使用Kubernetes集群。 如您所知,炉膛是短暂的,即 可以随时创建和删除它们。 其中的所有数据都将丢失。 因此,在实际集群中,需要分布式存储以确保节点和内部应用程序之间的设置和数据交换。
在Kubernetes中,可以通过多种方式使用卷;选择所需的卷。 在此示例中,我将演示如何为任何内部应用程序创建GlusterFS存储,就像持久卷一样。 之前,我为此在所有Kubernetes工作节点上都使用了GlusterFS的“系统”安装,然后在GlusterFS目录中简单地创建了hostPath卷。
现在我们有了一个新的便捷的Heketi工具。
Heketi文档中的几句话:
用于GlusterFS的RESTful卷管理基础结构。
Heketi提供了一个RESTful管理界面,可用于管理GlusterFS卷的生命周期。 感谢Heketi,诸如OpenStack Manila,Kubernetes和OpenShift之类的云服务可以动态地为GlusterFS卷提供支持的任何类型的可靠性。 Heketi自动确定集群中块的位置,提供块及其副本在不同故障区域的位置。 Heketi还支持任意数量的GlusterFS群集,从而使云服务能够提供在线文件存储,而不仅仅是单个GlusterFS群集。
听起来不错,此外,此工具还将使我们的VM集群更接近Kubernetes大型云集群。 最后,您将能够创建PersistentVolumeClaims ,它将自动生成等等。
您可以使用其他系统硬盘驱动器来配置GlusterFS,也可以仅创建一些虚拟块设备。 在此示例中,我将使用第二种方法。
在所有三个工作节点上创建虚拟块设备:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
您将获得一个大约10 GB的文件。 然后使用Lostup-将其添加到这些节点,作为回送设备:
worker1-3# losetup /dev/loop0 /home/gluster/image
请注意:如果您已经有某种回送设备0,那么您将需要选择任何其他号码。
我花了时间,找出了为什么赫凯蒂不想正常工作。 因此,为防止将来的配置出现任何问题,请首先确保我们已加载dm_thin_pool内核模块并在所有工作节点上安装了glusterfs-client软件包。
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
好了,现在您需要在所有工作节点上都存在文件/ home / gluster / image和设备/ dev / loop0 。 请记住要创建一个systemd服务,该服务将在每次这些服务器启动时自动启动Lostup和Modprobe 。
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
并打开它:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
准备工作已经完成,我们准备将GlusterFS和Heketi部署到我们的集群中。 为此,我将使用这个很酷的指南 。 大多数命令是从外部控制计算机启动的,很小的命令是从群集内的任何主节点启动的。
首先,复制存储库并创建DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
现在,让我们为GlusterFS标记三个工作节点; 标记它们后,将创建GlusterFS容器:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
现在创建一个Heketi服务帐户:
control# kubectl create -f heketi-service-account.json
我们为此服务帐户提供了管理Gluster Pod的功能。 为此,请为我们新创建的服务帐户创建所需的集群功能:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
现在让我们创建一个Kubernetes秘密密钥来阻止我们的Heketi实例的配置:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
在Heketi下创建第一个源,我们将其用于第一个设置操作,然后删除:
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
创建并启动Bootstrap Heketi服务后,由于外部控制节点不在集群内部,因此我们将需要切换到主节点之一,在此我们将运行多个命令,因此我们无法访问工作Pod和集群的内部网络。
首先,让我们下载heketi-client实用程序并将其复制到bin系统文件夹中:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
现在找到heketi pod的IP地址,并将其导出为系统变量:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
现在,让我们为Heketi提供应管理的有关GlusterFS集群的信息。 我们通过拓扑文件提供它。 拓扑是JSON清单,其中包含GlusterFS使用的所有节点,磁盘和群集的列表。
注意 确保hostnames/manage指示确切的名称(如kubectl get node部分中所述),并且hostnames/storage是存储节点的IP地址。
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
然后下载此文件:
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
接下来,我们使用Heketi提供用于存储数据库的卷。 团队名称有点奇怪,但是一切都井井有条。 还创建一个heketi存储库:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
这些都是您需要从主节点运行的所有命令。 让我们回到控制节点并从那里继续。 首先,请确保最后一个正在运行的命令已成功执行:
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
heketi-storage-copy-job工作已经完成。
如果当前在您的工作节点上未安装任何已安装的glusterfs-client软件包,则会发生错误。
现在是时候删除Heketi Bootstrap安装文件并进行一些清理了:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
在最后阶段,我们需要创建Heketi的长期副本:
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
如果当前在您的工作节点上未安装任何已安装的glusterfs-client软件包,则会发生错误。 差不多完成了,现在Heketi数据库存储在GlusterFS卷中,并且每次重新启动Heketi炉床时都不会重置。
要开始使用具有动态资源分配功能的GlusterFS集群,我们需要创建一个StorageClass。
首先,让我们找到Gluster存储端点,它将作为参数(heketi-storage-endpoints)传递给StorageClass:
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
现在创建一些文件:
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
使用以下文件创建类和pvc:
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
我们还可以查看PV量:
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
现在,我们有了一个与PersistentVolumeClaim关联的动态创建的GlusterFS卷,并且可以在任何子图中使用此语句。
在Nginx下创建一个简单的文件并进行测试:
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
在下面浏览(等待几分钟,如果该图像尚不存在,则可能需要下载该图像):
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
现在进入容器并创建index.html文件:
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
您将需要找到炉床的内部IP地址,并从任何主节点上将其卷曲:
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
这样,我们只需测试新的持久卷。
签出新GlusterFS群集的一些有用命令是: heketi-cli cluster list和heketi-cli volume list 。 如果安装了heketi-cli,它们可以在您的计算机上运行。 在此示例中,这是节点master1 。
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
在此阶段,我们成功设置了带有文件存储的内部负载平衡器,并且我们的集群现在已接近运行状态。
在本文的下一部分中,我们将专注于创建集群监视系统,并在其中启动一个测试项目以使用我们配置的所有资源。
保持联系,万事如意!