在本文中,我将讨论埋设在地雷下的地雷,以及地雷的探测(最好是在爆炸前)和处置。
什么是地雷?
让我们从任何知识的源头开始-具有定义。 古人说,正确命名意味着正确理解。 我认为最好通过对比一个明显的错误来表述表现良好的地雷,例如:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
即使是新手开发人员也知道这些行是不可变的,并且将它们粘合成一个循环并不意味着将数据添加到现有行的尾部,而是每次通过都会创建一条新行。 如果您弄错了,请不要气--“想法”会立即警告您危险,而“声纳”肯定会淹没您的组件。
但是此代码将吸引较少的关注,并且Idea( 2018.2之前的版本 )将保持沉默:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
这里的问题是相同的:简单类型的包装器是不可变的,这意味着在对象编号中添加5个单位意味着创建一个新包装器并将6写入其中。
这里的笑话是在Java中存在两种表示某些类型的数据的表示形式-简单和对象,以及它们通过语言本身的自动转换。 因此,许多新手开发人员都会这样思考:“好吧,执行以某种方式将它们本身转化为一个数字。”
实际上,并非一切都那么简单。 进行基准测试并尝试以指定的方式添加数字:
突然,它变得非常非常便宜(以下是JDK 11,除非另有明确说明) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
与简单类型进行比较:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
从这里我们可以得出性能欠佳的地雷的定义之一-该代码无法吸引眼球,也无法被静态分析器检测到(至少在您遇到它时),但是在某些用途中它会减慢速度。 在我们的示例中,从缓存中获取的对象总数不超过127,而Long仅比long慢4倍。 但是,对于大小为100的数组,速度几乎要低10倍。
大件小事
有时,在几乎没有改变执行含义的情况下进行小的更改,在某些情况下会成为一个重大障碍。
假设我们有一个代码:
方法逻辑是什么样的?
不要急着间谍,想想这是ConcurrentHashMap::computeIfAbsent !
我们拥有“八”字,我们可以轻松地改进代码:用1替换6行,使代码更短,更易于理解。 顺便说一下,多线程专家们可能会指出ConcurrentHashMap::computeIfAbsent带来的另一项改进,但ConcurrentHashMap::computeIfAbsent会有所改进;)
让我们实现一个伟大的想法:
聚集,开始,哭泣要查看完整尺寸,请右键单击图片,然后选择“在新标签页中打开图像”
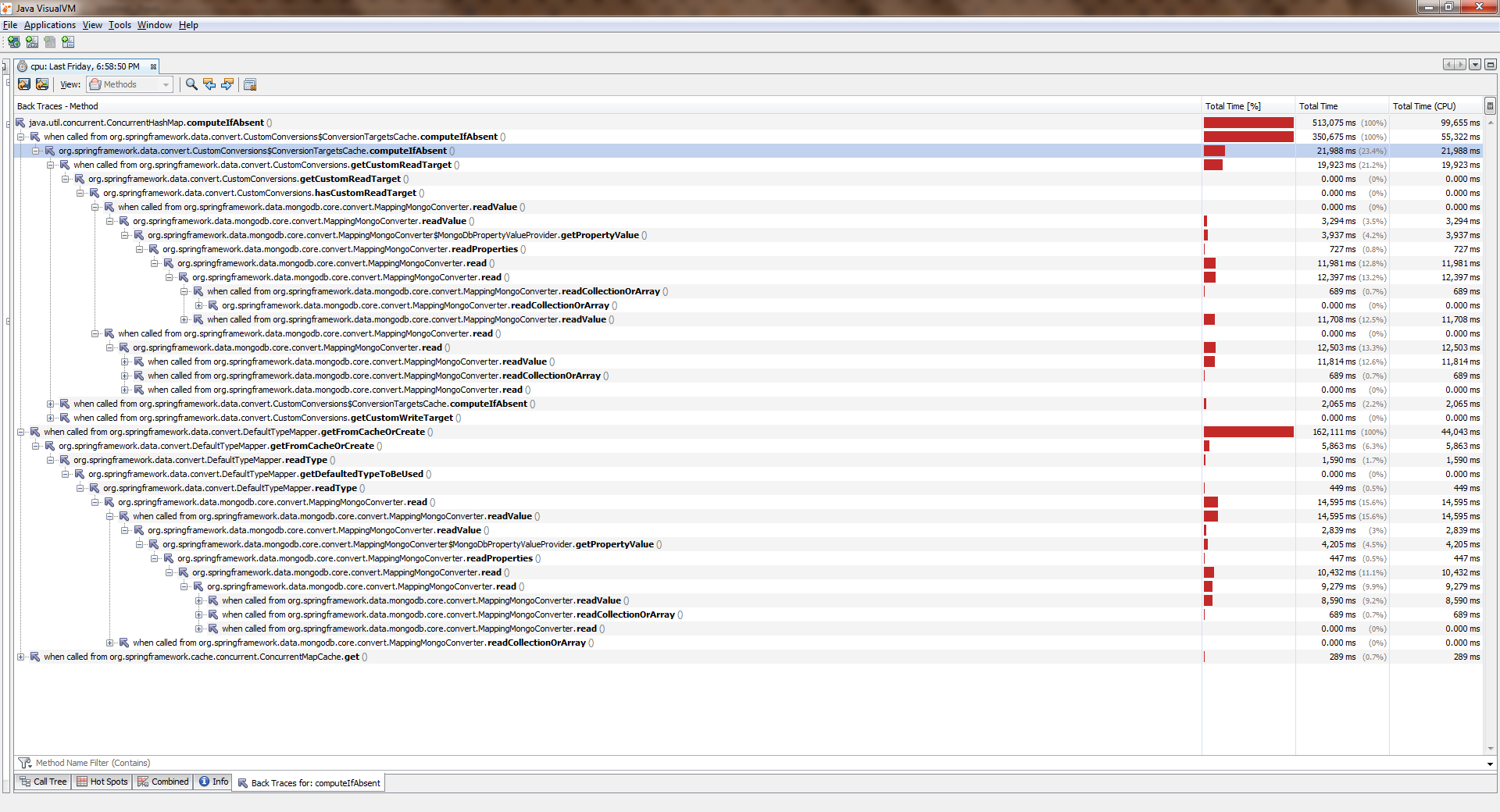
当应用程序使用一个线程时,一切都差不多。 流变得越来越多,变得越来越差。 ConcurrentHashMap::computeIfAbsent证明, 即使已将密钥添加到字典中 , ConcurrentHashMap::computeIfAbsent被阻止。 这就是Spring Date Mongo中出现大量错误的原因。
您可以通过简单的测量 (“八”)进行验证。 这是他的结论:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
开发人员可以明确地认为这是一个错误吗? 以我的拙见,不,不。 该文件说:
在计算进行期间,可能会阻止其他线程在此映射上进行的某些尝试的更新操作,因此计算应简短而简单,并且不得尝试更新此映射的任何其他映射
换句话说, ConcurrentHashMap::computeIfAbsent关闭包含来自外界的键的单元格(与ConcurrentHashMap::get不同),这通常是正确的,因为当尚未添加键时,它允许您从不同的线程调用方法时躲避竞争。
另一方面,在最常见的操作模式中,值的计算及其与键的绑定仅在第一次调用时发生,而所有后续调用仅返回先前计算的值。 因此,有意义的是更改逻辑,以便仅在更改时设置锁定。 它是在这里做的 。
在较新的版本(> 8)中, ConcurrentHashMap::computeIfAbsent变得ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
请注意此示例的阴险之处:语义内容并没有太大变化,因为乍一看我们只是使用了更高级的语法。 同时,当应用程序在一个线程中运行时,用户几乎感觉不到差异! 这看似无害的变化 猪 我的表现。
为什么我写“几乎不变”ConcurrentHashMap::computeIfAbsent并不总是可以与getAndPut表达式互换,因为ConcurrentHashMap::computeIfAbsent是原子操作。 用相同的代码
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
由于缺乏外部同步,种族出现了 。 如果传递给给定键的ConcurrentHashMap::computeIfAbsent函数始终返回相同的值,则这是一个“安全”的竞争,我们面临的最大ConcurrentHashMap::computeIfAbsent是两次或更多次计算相同的值。 如果没有这样的保证,那么机械更换将困扰着应用的崩溃。 小心点!
这些手什么都没变
也有可能代码根本没有改变,但是突然它开始变慢了。
想象一下,我们面临着将数组元素转移到集合中的任务。 最合乎逻辑的方法是使用现成的Collection::addAll ,但这很不幸-它接受该集合:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
最简单的方法是将数组包装在Arrays::asList 。 结果会是
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
在校对期间,注重性能的同事可能会告诉我们,此代码同时存在两个问题:
- 将数组包装在列表中(额外对象)
- 创建一个迭代器(另一个额外的对象)并传递给它
实际上,在Collection::addAll的参考实现中,我们将看到以下内容:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
因此,这里创建了一个迭代器,并使用它对元素进行了排序。 因此,有经验的同志提供他们的解决方案:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
在代码内部, 看起来似乎更有生产力:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
首先,不创建迭代器。 其次,该过程按通常的计数周期进行,此外,数组非常适合高速缓存,其元素顺序位于内存中(这意味着几乎没有高速缓存未命中),并且通过索引访问它们非常快。 好了,也不创建包装列表。 听起来不错。
最后,同事们引用了最后通行比例规定:文件。 那里,白色的灰色(或黑色的绿色)表示:
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
也就是说,开发人员自己(如果不是,他们应该相信谁?)写道,对于大多数实现而言,实用程序方法的运行速度要快得多。 而且他真的更快。 有时候
我们将在G8上针对HashSet推出的基准测试将有助于HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
看来更有经验的同志是对的。 差不多了
在更高版本中(例如,在11中),实用程序方法的辉煌将逐渐消失:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
可以看出,我们没有在谈论任何“快得多”的问题。 而且,如果我们对ArrayList -a重复该实验,那么结果发现实用程序方法开始损失很多(越强大):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
这里没有什么意外的, ArrayList围绕数组构建的,因此开发人员具有远见地重新定义了Collection::addAll :
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
现在回到我们的地雷。 假设我们仍然接受了校对中提出的解决方案,并保留了以下代码:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
暂时一切都很好,但是在添加了新功能之后,该方法有时会变得很热并且开始变慢。 我们开放源代码-代码未更改。 数据量是相同的。 而且性能下降了很多。 这是我的另一种类型。
发现调试器并找到漂亮的:

请注意:我们没有改变算法,处理的数据量没有改变,但是它们的性质改变了,并且在我们的代码中出现了性能问题:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
在大型数组上, Collections::addAll和Collection::addAll之间的Collection::addAll只有500倍。 事实是, COWList不仅会扩展现有数组,还会在每次添加元素时创建一个新数组:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
谁该怪?
这里的主要问题是Collections::addAll接受一个接口,而addAll方法没有主体。 没有内容-没有业务,因此,文档基于AbstractCollection::addAll存在的实现AbstractCollection::addAll ,这是适用于所有集合的通用算法。 这意味着处于较低抽象级别的数据结构的更具体的实现可以更改此行为。
现在人类 Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
有关抽象的更多信息
由于我们在谈论抽象的层次,因此我将向您介绍生活中的一个例子。
让我们比较一下这两种在数据库中保存第n个实体的方式:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
乍一看,这两种方法的性能不应有很大差异,因为
- 在两种情况下,相同数量的实体将存储在数据库中
- 如果密钥是从序列中获取的,则通话次数将相同
- 传输的数据量相同
SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
这里的黑点是flush()方法。 为什么傻呢? 在我看来,它在JpaRepository接口中的公开是开发人员的错误。 我会尽力证明我的想法。 通常,开发人员根本不会使用此方法,因为对EntityManager::flush的调用与Spring控制的事务的完成相关:
请注意: EntityManager是在Hibernate中作为会话实现的JPA规范的一部分(分别为Session接口和SessionImpl类)。 Spring Date是一个在ORM(在本例中为Hibernate)之上运行的框架。 事实证明,尽管框架的任务是隐藏低级细节(该情况与JDK中的不安全故事类似),但JpaRepository::saveAndFlush使我们可以访问API的低级。
在我们的例子中,当使用JpaRepository::saveAndFlush我们进入了应用程序的较低层,从而破坏了某些内容。
花些时间偷看,自己考虑一下Hibernate批量发送数据的功能已被破坏,它是application.yml指定的jdbc.batch_size设置的倍数:
spring: jpa: properties: hibernate: jdbc.batch_size: 500
Hibernate的工作基于事件,因此当您保存1000个这样的实体时
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
调用repository.save(e)不会立即保存。 而是创建一个排队的事件。 事务完成后,将使用EntityManager::flush合并数据,该数据将插入/更新分成jdbc.batch_size倍数束,并jdbc.batch_size创建请求。 在我们的例子中, jdbc.batch_size: 500 ,因此实际上保存1000个实体仅意味着2个请求。
但是,在周期的每个阶段都要手动执行会话
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
队列已清除,保存1000个实体意味着1000个查询。
因此,干扰应用程序的较低层很容易成为地雷,而不仅仅是生产力地雷(请参阅不安全及其不受控制的使用)。
它减慢了多少? 以最好的情况(对我们而言)-数据库与应用程序位于同一主机上。 我的测量结果如下图所示:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
显然,如果数据库位于远程主机上,则数据传输的成本将随着数据量的增长而逐渐降低性能。
因此,以错误的抽象级别进行工作很容易制造定时炸弹。 顺便说一下,在我以前的一篇文章中,我谈到了一种改进StringBuilder -a的奇怪尝试:在尝试进入更抽象的代码级别时,我没有成功。
雷区边界
让我们扮演一个工兵吗? 查找我的:
评论家大声说道:“你在开玩笑吗?但是只有两行胶合吗?在血腥的E.中意味着什么?” 让我引起您的注意的是,我不仅强调了字符串的粘合,而且还强调了类的名称和方法的名称。 确实,胶合字符串的危险不是胶合自身,而是在创建用于缓存的键的方法中发生的事情,即在某些情况下,我们将对该方法有很多访问权限,这意味着很多垃圾回收行。
因此, 仅当实际抛出此错误时才应创建错误消息:
因此,雷区具有边界-这是数据量,使用该方法的频率等定量指标,一旦达到或超过此范围,轻微的缺陷就会在统计上变得显着。
另一方面,这是一个特性,相对而言,代码的复杂性并不能带来明显的(可衡量的)改进。
这是对开发人员的另一个结论:在大多数情况下,欺骗是邪恶的,从而导致代码毫无意义的复杂化。 在100个案例中有99个案例,我们一无所获。
应该记住,总有
一百例
这是Nitzan Wakart在他的文章volatile读取中给出的代码:
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
建立经验后,我们将发现两种遍历数组的方式之间的惊人差异:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
在这里,没有经验的开发人员可以得出这样一个显而易见的基准结论:使用新语法传递数组比计数周期更快。 这是错误的结论,因为值得goodOldLoop更改一下goodOldLoop方法:
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
其性能可与“更快”的sweetLoop方法相媲美:
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .