我们已经讨论了PostgreSQL
索引引擎和
访问方法的接口 ,以及访问方法之一的
哈希索引 。 现在,我们将考虑B树,这是最传统且使用最广泛的索引。 这篇文章很大,请耐心等待。
Btree
结构形式
B树索引类型,实现为“ btree”访问方法,适用于可以排序的数据。 换句话说,必须为数据类型定义“更大”,“更大或相等”,“小于”,“小于或等于”和“等于”运算符。 请注意,有时可以对不同的数据进行不同的排序,这
使我们回到了操作员族的概念。
与往常一样,B树的索引行打包到页面中。 在叶页中,这些行包含要建立索引的数据(键)和对表行的引用(TID)。 在内部页面中,每一行都引用索引的子页面,并在该页面中包含最小值。
B树具有一些重要特征:
- B树是平衡的,也就是说,每个叶页面与根都由相同数量的内部页面分隔开。 因此,搜索任何值都需要花费相同的时间。
- B树是多分支的,即每个页面(通常8 KB)包含很多(数百个)TID。 结果,B树的深度很小,对于非常大的表,实际上高达4–5。
- 索引中的数据以不降序排序(在页面之间和每个页面内部),并且同一级别的页面通过双向列表相互连接。 因此,我们可以仅通过列表的一个方向或另一个方向获得有序数据集,而不必每次都返回到根。
下面是一个使用整数键的字段索引的简化示例。
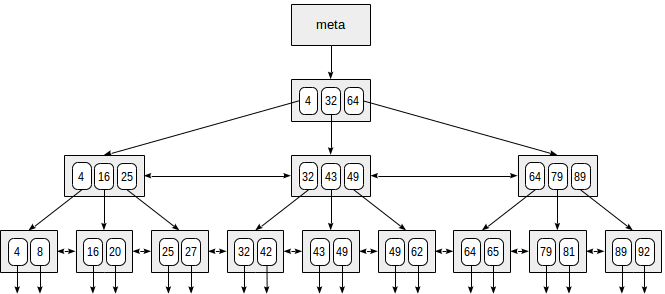
索引的第一页是一个元页,它引用索引根。 内部节点位于根下方,叶子页位于最底行。 向下箭头表示从叶节点到表行(TID)的引用。
平等搜索
让我们考虑通过条件“
indexed-field =
expression ”在树中搜索值。 假设我们对49键很感兴趣。

搜索从根节点开始,我们需要确定要降到哪个子节点。 由于知道根节点(4、32、64)中的键,因此我们找出了子节点中的值范围。 由于32≤49 <64,因此我们需要下降到第二个子节点。 接下来,递归重复相同的过程,直到我们到达一个叶节点,可以从该叶节点获得所需的TID。
实际上,许多细节使这一看似简单的过程变得复杂。 例如,索引可以包含非唯一键,并且可能有太多相等的值以至于它们不适合一页。 回到我们的示例,似乎我们应该从内部节点下降到参考值49。但是,从图中可以清楚地看出,通过这种方式,我们将跳过上一页中的“ 49”键之一。 因此,一旦我们在内部页面中找到一个完全相等的键,就必须向左下移一个位置,然后从左到右浏览基础层的索引行以寻找所需的键。
(另一个复杂之处在于,在搜索过程中,其他进程可以更改数据:可以重建树,可以将页面拆分为两个,依此类推。所有算法都针对这些并发操作而设计,不会互相干扰,也不会引起额外的锁定只要有可能,但我们会避免对此进行扩展。)
按不平等搜索
当通过条件“
indexed-field =
expression ”(或“
indexed- field≥expression”)进行搜索时,我们首先通过相等条件“
indexed-field =
expression ”在索引中找到一个值(如果有),然后逐步遍历沿正确方向将页末尾。
该图说明了n≤35时的此过程:

除了必须删除最初找到的值以外,以类似的方式支持“更大”和“更少”运算符。
按范围搜索
当按范围“
表达式 1≤
索引字段 ≤expression2”搜索时,我们根据条件“
索引字段 =
表达式1 ”找到一个值,然后在满足条件“
索引字段 ≤expression2”的情况下继续遍历叶页; 反之亦然:从第二个表达式开始,然后朝相反的方向走,直到到达第一个表达式。
该图显示了条件23≤n≤64时的此过程:

例子
让我们看一下查询计划的示例。 像往常一样,我们使用演示数据库,这一次我们将考虑飞机表。 它只包含9行,规划者会选择不使用索引,因为整个表都适合一页。 但是,出于说明目的,此表对我们来说很有趣。
demo=# select * from aircrafts;
aircraft_code | model | range ---------------+---------------------+------- 773 | Boeing 777-300 | 11100 763 | Boeing 767-300 | 7900 SU9 | Sukhoi SuperJet-100 | 3000 320 | Airbus A320-200 | 5700 321 | Airbus A321-200 | 5600 319 | Airbus A319-100 | 6700 733 | Boeing 737-300 | 4200 CN1 | Cessna 208 Caravan | 1200 CR2 | Bombardier CRJ-200 | 2700 (9 rows)
demo=# create index on aircrafts(range); demo=# set enable_seqscan = off;
(或者明确地说,“使用btree(范围)在飞机上创建索引”,但这是默认情况下构建的B树。)
平等搜索:
demo=# explain(costs off) select * from aircrafts where range = 3000;
QUERY PLAN --------------------------------------------------- Index Scan using aircrafts_range_idx on aircrafts Index Cond: (range = 3000) (2 rows)
按不平等搜索:
demo=# explain(costs off) select * from aircrafts where range < 3000;
QUERY PLAN --------------------------------------------------- Index Scan using aircrafts_range_idx on aircrafts Index Cond: (range < 3000) (2 rows)
并按范围:
demo=# explain(costs off) select * from aircrafts where range between 3000 and 5000;
QUERY PLAN ----------------------------------------------------- Index Scan using aircrafts_range_idx on aircrafts Index Cond: ((range >= 3000) AND (range <= 5000)) (2 rows)
排序
让我们再次强调一点,对于任何类型的扫描(索引,仅索引或位图),“ btree”访问方法都会返回有序数据,我们可以在上图中清楚地看到。
因此,如果表在排序条件上具有索引,那么优化器将考虑以下两个选项:表的索引扫描(该索引扫描很容易返回排序后的数据)以及表的顺序扫描以及结果的后续排序。
排序顺序
创建索引时,我们可以显式指定排序顺序。 例如,我们可以通过这种方式特别按照航班范围创建索引:
demo=# create index on aircrafts(range desc);
在这种情况下,较大的值将出现在左侧的树中,而较小的值将出现在右侧。 如果我们可以双向浏览索引值,为什么需要这样做?
目的是多列索引。 让我们创建一个视图,以显示按常规分为短程,中程和远程飞行器的飞机模型:
demo=# create view aircrafts_v as select model, case when range < 4000 then 1 when range < 10000 then 2 else 3 end as class from aircrafts; demo=# select * from aircrafts_v;
model | class ---------------------+------- Boeing 777-300 | 3 Boeing 767-300 | 2 Sukhoi SuperJet-100 | 1 Airbus A320-200 | 2 Airbus A321-200 | 2 Airbus A319-100 | 2 Boeing 737-300 | 2 Cessna 208 Caravan | 1 Bombardier CRJ-200 | 1 (9 rows)
让我们创建一个索引(使用表达式):
demo=# create index on aircrafts( (case when range < 4000 then 1 when range < 10000 then 2 else 3 end), model);
现在,我们可以使用该索引来获取按升序按两列排序的数据:
demo=# select class, model from aircrafts_v order by class, model;
class | model -------+--------------------- 1 | Bombardier CRJ-200 1 | Cessna 208 Caravan 1 | Sukhoi SuperJet-100 2 | Airbus A319-100 2 | Airbus A320-200 2 | Airbus A321-200 2 | Boeing 737-300 2 | Boeing 767-300 3 | Boeing 777-300 (9 rows)
demo=# explain(costs off) select class, model from aircrafts_v order by class, model;
QUERY PLAN -------------------------------------------------------- Index Scan using aircrafts_case_model_idx on aircrafts (1 row)
同样,我们可以执行查询以对数据进行降序排序:
demo=# select class, model from aircrafts_v order by class desc, model desc;
class | model -------+--------------------- 3 | Boeing 777-300 2 | Boeing 767-300 2 | Boeing 737-300 2 | Airbus A321-200 2 | Airbus A320-200 2 | Airbus A319-100 1 | Sukhoi SuperJet-100 1 | Cessna 208 Caravan 1 | Bombardier CRJ-200 (9 rows)
demo=# explain(costs off) select class, model from aircrafts_v order by class desc, model desc;
QUERY PLAN ----------------------------------------------------------------- Index Scan BACKWARD using aircrafts_case_model_idx on aircrafts (1 row)
但是,我们不能使用此索引来获取数据按降序按一列排序,而按升序按另一列排序。 这将需要单独排序:
demo=# explain(costs off) select class, model from aircrafts_v order by class ASC, model DESC;
QUERY PLAN ------------------------------------------------- Sort Sort Key: (CASE ... END), aircrafts.model DESC -> Seq Scan on aircrafts (3 rows)
(请注意,作为最后的选择,计划者选择了顺序扫描,而不考虑先前进行的“ enable_seqscan = off”设置。这是因为实际上此设置并不禁止表扫描,而只是设置其天文成本-请通过以下方式查看计划“费用”。)
为了使该查询使用索引,必须使用所需的排序方向来构建后者:
demo=# create index aircrafts_case_asc_model_desc_idx on aircrafts( (case when range < 4000 then 1 when range < 10000 then 2 else 3 end) ASC, model DESC); demo=# explain(costs off) select class, model from aircrafts_v order by class ASC, model DESC;
QUERY PLAN ----------------------------------------------------------------- Index Scan using aircrafts_case_asc_model_desc_idx on aircrafts (1 row)
列顺序
使用多列索引时出现的另一个问题是索引中列的排列顺序。 对于B树,此顺序非常重要:页面内的数据将按第一个字段排序,然后按第二个字段排序,依此类推。
我们可以用以下符号方式表示建立在范围间隔和模型上的索引:

实际上,这么小的索引肯定会适合一个根页面。 为了清楚起见,在图中故意将其分布在几页中。
从此图表中可以清楚地看出,按谓词进行搜索,例如“ class = 3”(仅按第一个字段进行搜索)或“ class = 3 and model ='Boeing 777-300'”(按两个字段进行搜索)将有效。
但是,通过谓词“ model ='Boeing 777-300'”进行搜索将效率较低:从根开始,我们无法确定要降落到哪个子节点,因此,我们必须降落到所有子节点。 这并不意味着永远不能使用这样的索引-它的效率是有问题的。 例如,如果我们有三类飞机,每一类中有很多型号,那么我们将不得不仔细检查一下索引的三分之一,这可能比全表扫描更有效……或者没有。
但是,如果我们创建这样的索引:
demo=# create index on aircrafts( model, (case when range < 4000 then 1 when range < 10000 then 2 else 3 end));
字段的顺序将更改:

使用此索引,通过谓词“ model ='Boeing 777-300'”进行的搜索将有效地进行,但通过谓词“ class = 3”进行的搜索将无法进行。
空值
“ Btree”访问方法索引NULL,并支持按条件IS NULL和IS NOT NULL进行搜索。
让我们考虑航班表,其中出现NULL:
demo=# create index on flights(actual_arrival); demo=# explain(costs off) select * from flights where actual_arrival is null;
QUERY PLAN ------------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (actual_arrival IS NULL) -> Bitmap Index Scan on flights_actual_arrival_idx Index Cond: (actual_arrival IS NULL) (4 rows)
NULL位于叶节点的另一端或另一端,具体取决于创建索引的方式(NULLS FIRST或NULLS LAST)。 如果查询包括排序,则这一点很重要:如果SELECT命令在其ORDER BY子句中指定的NULL顺序与为构建索引指定的顺序相同(NULLS FIRST或NULLS LAST),则可以使用索引。
在以下示例中,这些顺序相同,因此,我们可以使用索引:
demo=# explain(costs off) select * from flights order by actual_arrival NULLS LAST;
QUERY PLAN -------------------------------------------------------- Index Scan using flights_actual_arrival_idx on flights (1 row)
这里的顺序是不同的,优化器选择顺序扫描和后续排序:
demo=# explain(costs off) select * from flights order by actual_arrival NULLS FIRST;
QUERY PLAN ---------------------------------------- Sort Sort Key: actual_arrival NULLS FIRST -> Seq Scan on flights (3 rows)
要使用索引,必须使用开头的NULL创建索引:
demo=# create index flights_nulls_first_idx on flights(actual_arrival NULLS FIRST); demo=# explain(costs off) select * from flights order by actual_arrival NULLS FIRST;
QUERY PLAN ----------------------------------------------------- Index Scan using flights_nulls_first_idx on flights (1 row)
诸如此类的问题肯定是由于NULL无法排序引起的,也就是说,NULL与其他任何值的比较结果均未定义:
demo=# \pset null NULL demo=# select null < 42;
?column? ---------- NULL (1 row)
这与B树的概念背道而驰,不适合一般模式。 但是,NULL在数据库中起着非常重要的作用,因此我们总是必须为它们设置例外。
由于可以为NULL编制索引,因此即使对表没有任何条件,也可以使用索引(因为索引肯定包含所有表行的信息)。 如果查询需要数据排序并且索引确保了所需的顺序,则这可能很有意义。 在这种情况下,计划者可以选择索引访问来保存单独的排序。
物产
让我们看一下“ btree”访问方法的属性(
已经提供了查询)。
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t
如我们所见,B树可以排序数据并支持唯一性-这是唯一为我们提供此类属性的访问方法。 也允许使用多列索引,但是其他访问方法(尽管不是全部)也可以支持此类索引。 下次,我们将讨论EXCLUDE约束的支持,并非毫无道理。
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t
“ Btree”访问方法支持两种获取值的技术:索引扫描和位图扫描。 正如我们所看到的,访问方法既可以“向前”又可以“向后”遍历树。
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t
该层的前四个属性说明特定列的值如何精确排序。 在此示例中,值以升序排序(“ asc”),最后提供NULL(“ nulls_last”)。 但是正如我们已经看到的,其他组合也是可能的。
“ Search_array”属性通过索引指示对这样的表达式的支持:
demo=# explain(costs off) select * from aircrafts where aircraft_code in ('733','763','773');
QUERY PLAN ----------------------------------------------------------------- Index Scan using aircrafts_pkey on aircrafts Index Cond: (aircraft_code = ANY ('{733,763,773}'::bpchar[])) (2 rows)
“可返回”属性表示支持仅索引扫描,这是合理的,因为索引的行本身存储索引值(例如,与哈希索引不同)。 在这里说几句关于覆盖基于B树的索引是有意义的。
具有其他行的唯一索引
如前所述 ,覆盖索引是存储查询所需的所有值的索引,无需(几乎)访问表本身。 唯一索引可以专门覆盖。
但是,假设我们要向唯一索引添加查询所需的额外列。 但是,此类复合值的唯一性不能保证键的唯一性,因此将需要在同一列上使用两个索引:一个唯一以支持完整性约束,另一个则用作覆盖。 这肯定是低效的。
在我们的公司Anastasiya Lubennikova
lubennikovaav中,我们改进了“ btree”方法,以便可以在唯一索引中包含其他非唯一列。 我们希望,该补丁将被社区所采用,成为PostgreSQL的一部分,但是这种情况最早要在版本10中才能实现。目前,该补丁在Pro Standard 9.5+中可用,这就是它的样子。喜欢。
实际上,此补丁已提交给PostgreSQL 11。
让我们考虑预订表:
demo=# \d bookings
Table "bookings.bookings" Column | Type | Modifiers --------------+--------------------------+----------- book_ref | character(6) | not null book_date | timestamp with time zone | not null total_amount | numeric(10,2) | not null Indexes: "bookings_pkey" PRIMARY KEY, btree (book_ref) Referenced by: TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
在此表中,主键(book_ref,预订代码)由常规的“ btree”索引提供。 让我们用附加的列创建一个新的唯一索引:
demo=# create unique index bookings_pkey2 on bookings(book_ref) INCLUDE (book_date);
现在,我们用新索引替换现有索引(在事务中,以同时应用所有更改):
demo=# begin; demo=# alter table bookings drop constraint bookings_pkey cascade; demo=# alter table bookings add primary key using index bookings_pkey2; demo=# alter table tickets add foreign key (book_ref) references bookings (book_ref); demo=# commit;
这是我们得到的:
demo=# \d bookings
Table "bookings.bookings" Column | Type | Modifiers --------------+--------------------------+----------- book_ref | character(6) | not null book_date | timestamp with time zone | not null total_amount | numeric(10,2) | not null Indexes: "bookings_pkey2" PRIMARY KEY, btree (book_ref) INCLUDE (book_date) Referenced by: TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
现在,一个和相同的索引可以作为唯一索引,并充当此查询的覆盖索引,例如:
demo=# explain(costs off) select book_ref, book_date from bookings where book_ref = '059FC4';
QUERY PLAN -------------------------------------------------- Index Only Scan using bookings_pkey2 on bookings Index Cond: (book_ref = '059FC4'::bpchar) (2 rows)
创建索引
众所周知,但同样重要的是,对于大型表,最好在没有索引的情况下加载数据,然后再创建所需的索引。 这不仅更快,而且很可能索引的大小更小。
事实是,“ btree”索引的创建比将值按行插入树中使用的过程更有效。 大致上,表中所有可用的数据都被排序,并创建这些数据的叶页。 然后将内部页面“建立”在此基础之上,直到整个金字塔收敛到根为止。
此过程的速度取决于可用RAM的大小,这受“ maintenance_work_mem”参数限制。 因此,增加参数值可以加快处理过程。 对于唯一索引,除“ maintenance_work_mem”外还分配了大小为“ work_mem”的内存。
比较语义
上次我们提到PostgreSQL需要知道哪个哈希函数来调用不同类型的值,并且该关联存储在“哈希”访问方法中。 同样,系统必须弄清楚如何对值进行排序。 这对于排序,分组(有时),合并联接等是必需的。 PostgreSQL不会将自己绑定到运算符名称(例如>,<,=),因为用户可以定义自己的数据类型并为相应的运算符赋予不同的名称。 “ btree”访问方法使用的运算符系列将定义运算符名称。
例如,这些比较运算符在“ bool_ops”运算符系列中使用:
postgres=# select amop.amopopr::regoperator as opfamily_operator, amop.amopstrategy from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'btree' and opf.opfname = 'bool_ops' order by amopstrategy;
opfamily_operator | amopstrategy ---------------------+-------------- <(boolean,boolean) | 1 <=(boolean,boolean) | 2 =(boolean,boolean) | 3 >=(boolean,boolean) | 4 >(boolean,boolean) | 5 (5 rows)
在这里我们可以看到五个比较运算符,但是正如已经提到的,我们不应该依赖它们的名称。 为了弄清楚每个操作员进行的比较,引入了策略概念。 定义了五种策略来描述操作员语义:
- 1-少
- 2-小于或等于
- 3-相等
- 4-大于或等于
- 5-更大
一些运营商家族可以包含多个实施一项策略的运营商。 例如,“ integer_ops”运算符家族包含以下策略1运算符:
postgres=# select amop.amopopr::regoperator as opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'btree' and opf.opfname = 'integer_ops' and amop.amopstrategy = 1 order by opfamily_operator;
opfamily_operator ---------------------- <(integer,bigint) <(smallint,smallint) <(integer,integer) <(bigint,bigint) <(bigint,integer) <(smallint,integer) <(integer,smallint) <(smallint,bigint) <(bigint,smallint) (9 rows)
因此,当比较一个运算符系列中包含的不同类型的值时,优化器可以避免类型转换。
对新数据类型的索引支持
该文档提供
了创建用于复数的新数据类型以及用于对该类型的值进行排序的运算符类
的示例 。 本示例使用C语言,当速度至关重要时,这是绝对合理的。 但是,没有什么妨碍我们为了尝试更好地理解比较语义而将纯SQL用于同一实验。
让我们用两个字段创建一个新的复合类型:实部和虚部。
postgres=# create type complex as (re float, im float);
我们可以创建一个具有新类型字段的表,并向该表中添加一些值:
postgres=# create table numbers(x complex); postgres=# insert into numbers values ((0.0, 10.0)), ((1.0, 3.0)), ((1.0, 1.0));
现在出现一个问题:如果在数学意义上没有定义复数关系,该如何对复数进行排序?
事实证明,已经为我们定义了比较运算符:
postgres=# select * from numbers order by x;
x -------- (0,10) (1,1) (1,3) (3 rows)
默认情况下,对于复合类型,排序是按组件进行的:比较第一个字段,然后比较第二个字段,依此类推,与逐个字符比较文本字符串的方式大致相同。 但是我们可以定义不同的顺序。 例如,复数可被视为向量,并按模量(长度)排序,该模量被计算为坐标平方和的平方根(毕达哥拉斯定理)。 为了定义这样的顺序,让我们创建一个辅助函数来计算模量:
postgres=# create function modulus(a complex) returns float as $$ select sqrt(a.re*a.re + a.im*a.im); $$ immutable language sql;
现在,我们将使用此辅助函数为所有五个比较运算符系统地定义函数:
postgres=# create function complex_lt(a complex, b complex) returns boolean as $$ select modulus(a) < modulus(b); $$ immutable language sql; postgres=# create function complex_le(a complex, b complex) returns boolean as $$ select modulus(a) <= modulus(b); $$ immutable language sql; postgres=# create function complex_eq(a complex, b complex) returns boolean as $$ select modulus(a) = modulus(b); $$ immutable language sql; postgres=# create function complex_ge(a complex, b complex) returns boolean as $$ select modulus(a) >= modulus(b); $$ immutable language sql; postgres=# create function complex_gt(a complex, b complex) returns boolean as $$ select modulus(a) > modulus(b); $$ immutable language sql;
我们将创建相应的运算符。 为了说明它们不必被称为“>”,“ <”等,我们给它们起“怪异”的名字。
postgres=# create operator #<#(leftarg=complex, rightarg=complex, procedure=complex_lt); postgres=# create operator #<=#(leftarg=complex, rightarg=complex, procedure=complex_le); postgres=# create operator #=#(leftarg=complex, rightarg=complex, procedure=complex_eq); postgres=# create operator #>=#(leftarg=complex, rightarg=complex, procedure=complex_ge); postgres=# create operator #>#(leftarg=complex, rightarg=complex, procedure=complex_gt);
在这一点上,我们可以比较数字:
postgres=# select (1.0,1.0)::complex #<# (1.0,3.0)::complex;
?column? ---------- t (1 row)
除五种运算符外,“ btree”访问方法还需要定义一个功能(过多但方便):如果第一个值小于,等于或大于第二个值,则它必须返回-1、0或1。一。 此辅助功能称为支持。 其他访问方法可能需要定义其他支持功能。
postgres=# create function complex_cmp(a complex, b complex) returns integer as $$ select case when modulus(a) < modulus(b) then -1 when modulus(a) > modulus(b) then 1 else 0 end; $$ language sql;
现在我们准备创建一个操作符类(并且将自动创建同名操作符族):
postgres=# create operator class complex_ops default for type complex using btree as operator 1 #<#, operator 2 #<=#, operator 3 #=#, operator 4 #>=#, operator 5 #>#, function 1 complex_cmp(complex,complex);
现在可以按需要进行排序:
postgres=# select * from numbers order by x;
x -------- (1,1) (1,3) (0,10) (3 rows)
并且肯定会得到“ btree”索引的支持。
要完成图片,您可以使用以下查询获得支持功能:
postgres=# select amp.amprocnum, amp.amproc, amp.amproclefttype::regtype, amp.amprocrighttype::regtype from pg_opfamily opf, pg_am am, pg_amproc amp where opf.opfname = 'complex_ops' and opf.opfmethod = am.oid and am.amname = 'btree' and amp.amprocfamily = opf.oid;
amprocnum | amproc | amproclefttype | amprocrighttype -----------+-------------+----------------+----------------- 1 | complex_cmp | complex | complex (1 row)
内部构造
我们可以使用“ pageinspect”扩展来探索B树的内部结构。
demo=# create extension pageinspect;
索引元页:
demo=# select * from bt_metap('ticket_flights_pkey');
magic | version | root | level | fastroot | fastlevel --------+---------+------+-------+----------+----------- 340322 | 2 | 164 | 2 | 164 | 2 (1 row)
这里最有趣的是索引级别:一百万行的表在两列上的索引需要最少2个级别(不包括根)。
关于块164的统计信息(根):
demo=# select type, live_items, dead_items, avg_item_size, page_size, free_size from bt_page_stats('ticket_flights_pkey',164);
type | live_items | dead_items | avg_item_size | page_size | free_size ------+------------+------------+---------------+-----------+----------- r | 33 | 0 | 31 | 8192 | 6984 (1 row)
块中的数据(此处牺牲为屏幕宽度的“数据”字段包含二进制表示形式的索引键的值):
demo=# select itemoffset, ctid, itemlen, left(data,56) as data from bt_page_items('ticket_flights_pkey',164) limit 5;
itemoffset | ctid | itemlen | data ------------+---------+---------+---------------------------------------------------------- 1 | (3,1) | 8 | 2 | (163,1) | 32 | 1d 30 30 30 35 34 33 32 33 30 35 37 37 31 00 00 ff 5f 00 3 | (323,1) | 32 | 1d 30 30 30 35 34 33 32 34 32 33 36 36 32 00 00 4f 78 00 4 | (482,1) | 32 | 1d 30 30 30 35 34 33 32 35 33 30 38 39 33 00 00 4d 1e 00 5 | (641,1) | 32 | 1d 30 30 30 35 34 33 32 36 35 35 37 38 35 00 00 2b 09 00 (5 rows)
第一个元素与技术有关,并指定块中所有元素的上限(我们未讨论的实现细节),而数据本身以第二个元素开头。 显然,最左边的子节点是块163,然后是块323,依此类推。 反过来,可以使用相同的功能进行探索。
现在,遵循良好的传统,阅读文档,
README和源代码就变得很有意义。
还有一个可能有用的扩展是“
amcheck ”,它将被合并到PostgreSQL 10中,对于较低的版本,您可以从
github获得它。 此扩展检查B树中数据的逻辑一致性,并使我们能够提前发现故障。
没错,“ amcheck”是PostgreSQL从版本10开始的一部分。
继续阅读 。