
今天的Apache Spark可能是分析大容量数据的最受欢迎的平台。 通过在Python下使用它的可能性,为它的流行做出了巨大贡献。 同时,每个人都同意,在标准API的框架内,Python和Scala / Java代码的性能是可比的,但是对于用户定义函数(用户定义函数,UDF)没有统一的观点。 让我们尝试使用检查SNA Hackathon 2019解决方案的任务示例来弄清楚这种情况下的间接成本如何增加。
作为竞赛的一部分,参与者可以解决对社交网络的新闻提要进行排序的问题,并以一组排序列表的形式上载解决方案。 为了检查获得的溶液的质量,首先,对于每个已加载列表,计算ROC AUC ,然后显示平均值。 请注意,您不需要计算一个通用的ROC AUC,而是为每个用户计算一个个性化的ROC-没有解决该问题的现成设计,因此您将必须编写专门的函数。 在实践中比较这两种方法的充分理由。
作为比较平台,我们将使用具有四个内核的云容器,并在本地模式下启动Spark,并将通过Apache Zeppelin使用它。 为了比较功能,我们将在PySpark和Scala Spark中镜像相同的代码 。 [这里]让我们开始加载数据。
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
当使用标准API时,代码的几乎完整的标识是值得注意的,直到val关键字为止。 操作时间没有显着差异。 现在,让我们尝试确定所需的UDF。
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
当实现特定功能时,很明显Python更简洁,这主要是因为能够使用内置的scikit-learn函数。 但是,有一些不愉快的时刻-您必须明确指定返回值的类型,而在Scala中,它是自动确定的。 让我们执行操作:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
该代码看起来几乎相同,但结果令人沮丧。

在PySpark上的实现花费了一个半分钟而不是在Scala上花费了两秒钟,也就是说, Python的速度慢了45倍 。 运行时,顶部显示了4个正在全速运行的活动Python进程,这表明Global Interpreter Lock不会在此处产生问题。 但是! 也许问题出在内部的scikit-learn实现中-让我们尝试按原样重现Python代码,而不求助于标准库。
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

实验显示出有趣的结果。 一方面,通过这种方法,生产力得以提高,但另一方面,简洁主义消失了。 获得的结果可能表明,在使用其他C ++模块的Python中工作时,在上下文之间进行切换会产生大量开销。 当然,在Java / Scala中使用JNI时也有类似的开销,但是,使用它们时,我不必处理45次降级示例。
为了进行更详细的分析,我们将进行两个附加的实验:使用不带Spark的纯Python来测量程序包调用的贡献,并使用Spark中增加的数据大小来摊销开销并获得更准确的比较。
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
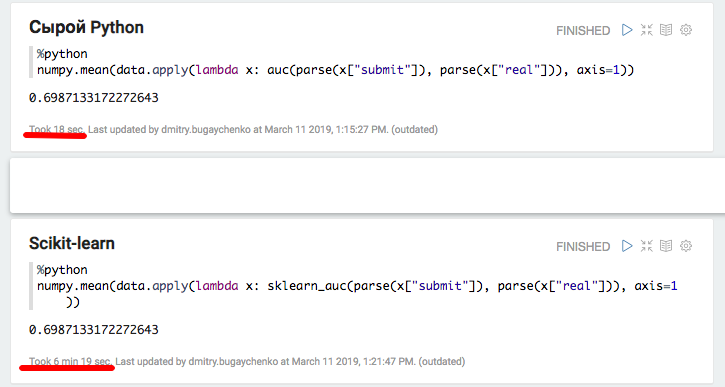
使用本地Python和Pandas进行的实验证实了使用其他软件包时会产生大量开销的假设-使用scikit-learn时,速度降低了20倍以上。 但是,20不是45-让我们尝试“填充”数据并再次比较Spark性能。
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

新的比较显示了Scala实现相对于Python的速度优势是7-8倍-7秒对比55秒。最后,让我们尝试“ Python中最快的速度” -numpy计算数组的总和:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
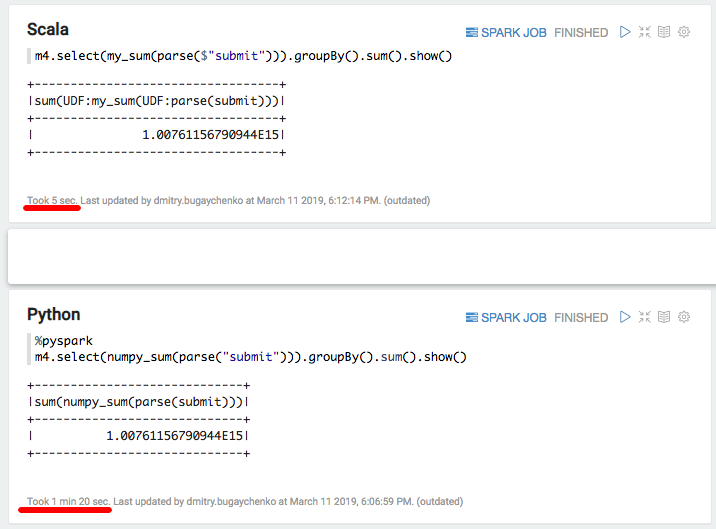
再次大幅下降-Scala为5秒,而Python为80秒。 总结起来,我们可以得出以下结论:
- 虽然PySpark在标准API的框架内运行,但其速度确实可以与Scala媲美。
- 当特定逻辑以用户定义函数的形式出现时,PySpark的性能将明显下降。 有了足够的信息,当数据块的处理时间超过几秒钟时,由于需要在进程之间移动数据并浪费解释Python的资源,因此Python的实现要慢5-10倍。
- 如果出现使用在C ++模块中实现的其他功能的情况,则会产生额外的调用成本,并且Python和Scala之间的差异将增加10至50倍。
因此,尽管拥有Python的全部魅力,但将它与Spark结合使用并不总是合理的。 如果没有太多数据可以使Python开销很大,那么您应该考虑这里是否需要Spark? 如果数据很多,但是处理是在标准Spark SQL API的框架内进行的,那么这里需要Python吗?
如果有大量数据,并且经常不得不处理超出SQL API限制的任务,那么为了在使用PySpark时执行相同数量的工作,您有时必须增加集群。 例如,对于Odnoklassniki,Spark集群的资本支出成本将增加数亿卢布。 而且,如果您尝试利用Python生态系统库的高级功能,那么,放慢速度的风险不仅是有时的,而且是一个数量级。
使用矢量化功能的相对较新的功能可以获得一些加速。 在这种情况下,不是将单行馈送到UDF输入,而是以Pandas数据帧的形式将多行数据包提供给UDF输入。 但是,此功能的开发尚未完成 ,即使在这种情况下,差异也将非常明显 。
另一种选择是维持一支庞大的数据工程师团队,从而能够通过附加功能快速满足数据科学家的需求。 或让自己沉浸在Scala世界中,因为它并不那么困难:已经存在许多必要的工具,因此培训计划超越了PySpark。