哈Ha! 我提请您注意Deb Haldar撰写的文章
“ Top 20 C ++多线程错误以及如何避免这些错误” 。
”中的场景") 电影《时间的循环》(2012)中的场景
电影《时间的循环》(2012)中的场景多线程是编程中最困难的领域之一,尤其是在C ++中。 经过多年的发展,我犯了很多错误。 幸运的是,它们中的大多数是通过审查代码和测试确定的。 但是,由于某种原因,生产效率下降了,我们不得不编辑操作系统,这总是很昂贵的。
在本文中,我尝试使用可能的解决方案对我知道的所有错误进行分类。 如果您知道其他任何陷阱,或者对解决所描述的错误有建议,请在本文下方保留您的评论。
错误#1:在退出应用程序之前,请勿使用join()等待后台线程
如果您忘记在程序终止之前加入流(
join() )或取消固定它(
detach() )(使其不可连接),则将导致崩溃。 (虽然这并不完全正确,但是翻译将包含在
join()上下文中的
join和在
detach()上下文中的
detach 。实际上,
join()是一个执行线程等待另一个线程完成的地方,并且不会发生线程的合并或合并[评论翻译])。
在下面的示例中,我们忘记了在主线程中执行线程t1的
join() :
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
//t1.join(); // join-
return 0 ;
}为什么程序崩溃? 因为在
main()函数的末尾,变量t1超出范围,所以调用了线程析构函数。 析构函数检查线程t1是否
可连接 。 如果线程尚未分离,则该线程是
可连接的 。 在这种情况下,将在其析构函数中调用
std :: terminate 。 例如,这就是MSVC ++编译器所做的。
~thread ( ) _NOEXCEPT
{ // clean up
if ( joinable ( ) )
XSTD terminate ( ) ;
}
有两种方法可以解决此问题,具体取决于任务:
1.在主线程中调用线程t1的
join() :
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. join ( ) ; // join t1,
return 0 ;
}
2.从主流分离流t1,使其继续作为“妖魔化”流工作:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ; // t1
return 0 ;
}错误2:尝试附加先前分离的线程
如果程序在某个时候有
分离流,则无法将其附加回主流。 这是一个非常明显的错误。 问题是您可以取消固定流,然后编写几百行代码并尝试重新附加它。 毕竟,谁记得他写了300行,对吗?
问题在于这不会导致编译错误,相反,程序将在启动时崩溃。 例如:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
t1. join ( ) ; // CRASH !!!
return 0 ;
}
解决方案是在尝试将线程附加到调用线程之前,始终检查该线程是否存在
joinable() 。
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
if ( t1. joinable ( ) )
{
t1. join ( ) ;
}
return 0 ;
}
错误3:误解std :: thread :: join()阻止了执行的调用线程
在实际应用中,您经常需要分离出处理网络I / O的“长时间播放”操作或等待用户单击按钮等。 对于此类工作流(例如,UI渲染线程)的
join()调用可能会导致用户界面挂起。 有更多合适的实现方法。
例如,在GUI应用程序中,工作线程可以在完成后将消息发送到UI线程。 UI流具有其自己的事件处理循环,例如:移动鼠标,按下键等。 此循环还可以接收来自工作线程的消息并对其进行响应,而不必调用阻塞的
join()方法。
因此,Microsoft的
WinRT平台中几乎所有用户交互都是异步的,并且没有同步替代方法。 做出这些决定是为了确保开发人员将使用可提供最佳最终用户体验的API。 您可以参考“
Modern C ++和Windows Store Apps ”手册,以获取有关此主题的更多信息。
错误4:假设默认情况下通过引用传递流函数参数
默认情况下,流函数的参数按值传递。 如果需要更改所传递的参数,则必须使用
std :: ref()函数通过引用将其传递。
在剧透之下,来自另
一篇C ++ 11文章“通过Q&A进行多线程教程-线程管理基础知识(Deb Haldar) ”的示例,说明了传递参数的过程。 译者]。
更多详细信息:执行代码时:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, targetCity ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
它将显示在终端中:
Changing The Target City To Metropolis
Current Target City is Star City
如您所见,流中通过引用调用的函数接收到的targetCity变量的值未更改。
使用std :: ref()重写代码以传递参数:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, std :: ref ( targetCity ) ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
它将输出:
Changing The Target City To Metropolis
Current Target City is Metropolis
在新线程中所做的更改将影响在主函数中声明和初始化的targetCity变量的值。
错误5:请勿使用关键部分(例如互斥锁)保护共享数据和资源
在多线程环境中,通常会有多个线程竞争资源和共享数据。 通常,这会导致资源和数据的状态不确定,除非通过某种机制保护对它们的访问,该机制仅允许一个执行线程在任何时间对其执行操作。
在下面的示例中,
std :: cout是一个共享资源,可以使用6个线程(t1-t5 + main)。
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex mu ;
void CallHome ( string message )
{
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
}
int main ( )
{
thread t1 ( CallHome, "Hello from Jupiter" ) ;
thread t2 ( CallHome, "Hello from Pluto" ) ;
thread t3 ( CallHome, "Hello from Moon" ) ;
CallHome ( "Hello from Main/Earth" ) ;
thread t4 ( CallHome, "Hello from Uranus" ) ;
thread t5 ( CallHome, "Hello from Neptune" ) ;
t1. join ( ) ;
t2. join ( ) ;
t3. join ( ) ;
t4. join ( ) ;
t5. join ( ) ;
return 0 ;
}
如果执行此程序,我们将得出结论:
Thread 0x1000fb5c0 says Hello from Main/Earth
Thread Thread Thread 0x700005bd20000x700005b4f000 says says Thread Thread Hello from Pluto0x700005c55000Hello from Jupiter says 0x700005d5b000Hello from Moon
0x700005cd8000 says says Hello from Uranus
Hello from Neptune
这是因为五个线程正在以随机顺序同时访问输出流。 为了使结论更具体,必须使用
std :: mutex保护对共享资源的访问。 只需更改
CallHome()函数,以便它在使用
std :: cout之前捕获互斥量,并在之后释放它。
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
mu. unlock ( ) ;
}错误#6:退出关键部分后忘记释放锁
在上一段中,您了解了如何使用互斥锁保护关键部分。 但是,不建议直接在互斥
锁上调用
lock()和
unlock()方法,因为您可能会忘记赋予保留的锁。 接下来会发生什么? 等待资源释放的所有其他线程将被无限阻止,程序可能会挂起。
在我们的综合示例中,如果您忘记了在
CallHome()函数调用中解锁互斥锁,则来自流t1的第一条消息将输出到标准流,并且程序将崩溃。 这是由于以下事实:线程t1接收了互斥锁,而其余线程等待此锁被释放。
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
//mu.unlock();
}以下是此代码的输出-程序崩溃,在终端中显示唯一的消息,但没有结束:
Thread 0x700005986000 says Hello from Pluto
经常会发生此类错误,这就是不希望直接从互斥锁使用
lock()/ unlock()方法的原因。 而是使用
std :: lock_guard模板类,该模板类使用
RAII惯用语来控制锁的生存期。 创建
lock_guard对象时,它将尝试接管互斥锁。 当程序离开
lock_guard对象的范围时,将调用析构函数,从而释放互斥量。
我们使用
std :: lock_guard对象重写
CallHome()函数:
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; //
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard错误7:使关键部分的尺寸大于必要的尺寸
当一个线程在关键部分内执行时,所有其他试图进入该线程的线程都会被阻塞。 在关键部分中,我们应该保留尽可能少的说明。 为了说明这一点,给出了一个带有较大临界区的错误代码示例:
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
ReadFifyThousandRecords ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muReadFifyThousandRecords()方法不会修改数据。 没有理由在锁定状态下执行它。 如果执行此方法10秒钟,从数据库中读取5万行,则在此整个周期内,所有其他线程都将被不必要地阻塞。 这会严重影响程序性能。
正确的解决方案是仅在关键部分中使用
std :: cout 。
void CallHome ( string message )
{
ReadFifyThousandRecords ( ) ; // ..
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard mu错误8:以不同的顺序获取多个锁
这是
死锁的最常见原因之一,在这种情况下,由于等待访问其他线程阻塞的资源而导致线程被无限阻塞。 考虑一个例子:
| 流1 | 流2 |
|---|
| 锁A | 锁B |
| // ...一些操作 | // ...一些操作 |
| 锁B | 锁A |
| // ...其他一些操作 | // ...其他一些操作 |
| 解锁B | 解锁A |
| 解锁A | 解锁B |
由于线程2已经捕获了锁B,因此线程1将尝试捕获锁B并被阻塞的情况可能会出现。 同时,第二个线程正在尝试捕获锁A,但不能执行此操作,因为它是第一个线程捕获的。 线程1直到锁住B等后才能释放锁A。 换句话说,程序冻结。
此代码示例将帮助您重现
死锁 :
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex muA ;
std :: mutex muB ;
void CallHome_Th1 ( string message )
{
muA. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muB. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muB. unlock ( ) ;
muA. unlock ( ) ;
}
void CallHome_Th2 ( string message )
{
muB. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muA. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muA. unlock ( ) ;
muB. unlock ( ) ;
}
int main ( )
{
thread t1 ( CallHome_Th1, "Hello from Jupiter" ) ;
thread t2 ( CallHome_Th2, "Hello from Pluto" ) ;
t1. join ( ) ;
t2. join ( ) ;
return 0 ;
}如果运行此代码,它将崩溃。 如果您在线程窗口中深入调试器,则会看到第一个线程(从
CallHome_Th1()调用)试图获取互斥锁B,而线程2(从
CallHome_Th2()调用)试图阻止互斥锁A。无法成功,这将导致僵局!
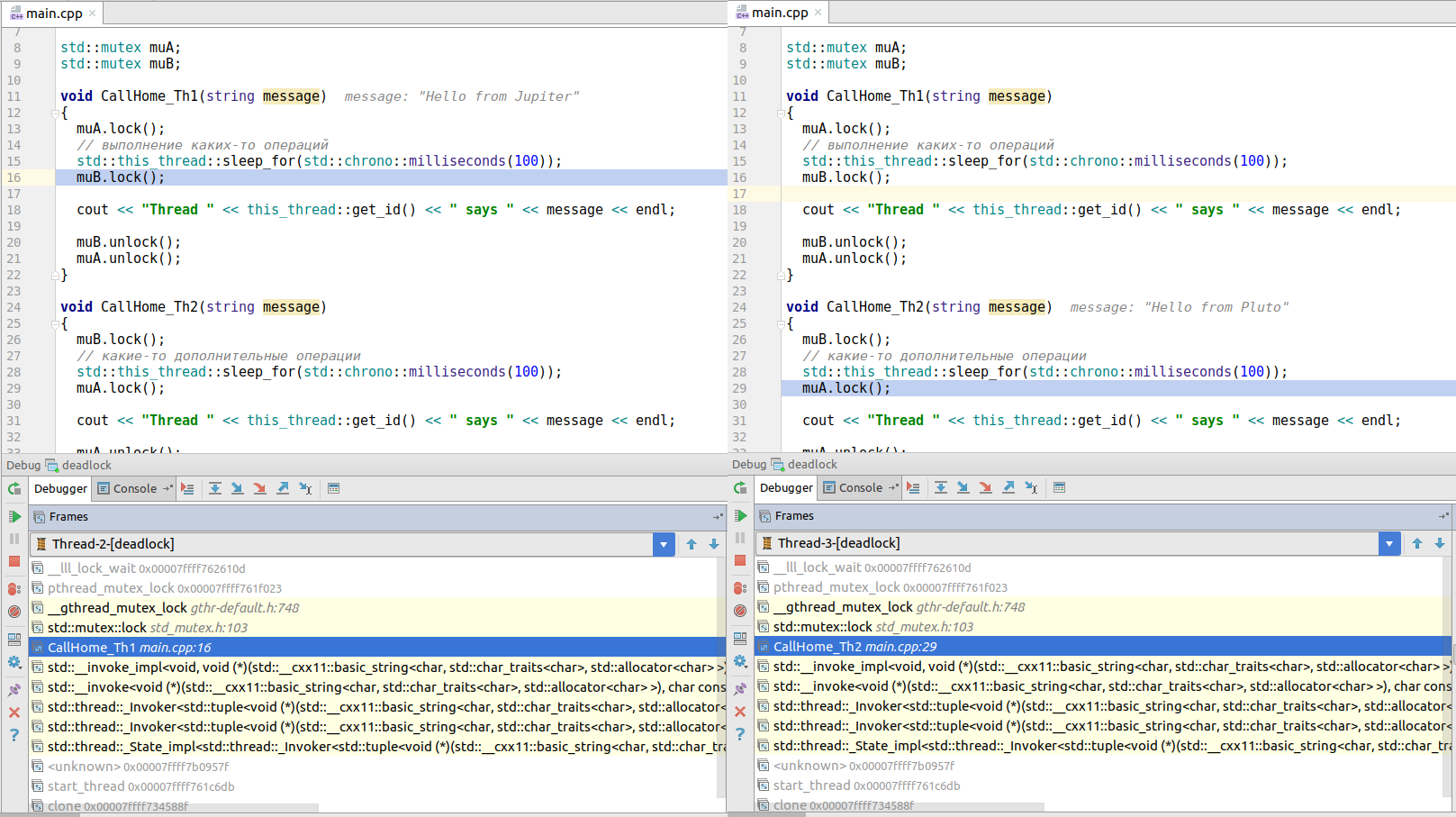
(图片可点击)
你能做什么呢? 最好的解决方案是重组代码,以便每次锁定锁的顺序相同。
根据情况,您可以使用其他策略:
1.使用包装器
类std :: scoped_lock共同捕获多个锁:
std :: scoped_lock lock { muA, muB } ;2.使用
std :: timed_mutex类 ,您可以在其中指定一个超时,如果资源不可用,将在该超时后释放锁。
std :: timed_mutex m ;
void DoSome ( ) {
std :: chrono :: milliseconds timeout ( 100 ) ;
while ( true ) {
if ( m. try_lock_for ( timeout ) ) {
std :: cout << std :: this_thread :: get_id ( ) << ": acquire mutex successfully" << std :: endl ;
m. unlock ( ) ;
} else {
std :: cout << std :: this_thread :: get_id ( ) << ": can't acquire mutex, do something else" << std :: endl ;
}
}
}错误9:尝试两次捕获std ::互斥锁
尝试两次锁定该锁将导致未定义的行为。 在大多数调试实现中,这将崩溃。 例如,在下面的代码中,
LaunchRocket()将锁定互斥锁,然后调用
StartThruster() 。 令人好奇的是,在上面的代码中,您在程序正常运行期间不会遇到此问题,仅当引发异常(伴随着未定义的行为或程序异常终止)时才会出现此问题。
#include "stdafx.h"
#include <iostream>
#include <thread>
#include <mutex>
std :: mutex mu ;
static int counter = 0 ;
void StartThruster ( )
{
try
{
// -
}
catch ( ... )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
std :: cout << "Launching rocket" << std :: endl ;
}
}
void LaunchRocket ( )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
counter ++ ;
StartThruster ( ) ;
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
return 0 ;
}
若要解决此问题,您必须以防止重新检索以前收到的锁的方式更正代码。 您可以将
std :: recursive_mutex用作拐杖解决方案,但是这样的解决方案几乎总是表明程序的体系结构不佳。
错误10:在std ::原子类型足够时使用互斥
当您需要更改简单数据类型(例如布尔值或整数计数器)时,使用
std:atomic通常会比使用互斥锁提供更好的性能。
例如,代替使用以下构造:
int counter ;
...
mu. lock ( ) ;
counter ++ ;
mu. unlock ( ) ;
最好将变量声明为
std :: atomic :
std :: atomic < int > counter ;
...
counter ++ ;有关互斥锁和原子锁的详细比较,请参阅《
比较:C ++ 11与C ++中的原子无
锁编程》。 互斥锁和读写锁»错误11:直接创建和销毁大量线程,而不是使用空闲线程池
就处理器时间而言,创建和销毁线程是一项昂贵的操作。 想象一下在系统执行计算密集型操作(例如渲染图形或计算游戏物理)时创建流的尝试。 通常用于此类任务的方法是创建一个预分配线程池,该池可以处理例行任务,例如在整个过程的整个生命周期中写入磁盘或通过网络发送数据。
与您自己生成和销毁线程相比,线程池的另一个优点是您不必担心
线程超额订购 (这种情况下,线程数超过了可用核心数,并且处理器的大部分时间都花在切换上下文上[大约。翻译]]。 这可能会影响系统性能。
另外,池的使用使我们免于管理线程生命周期的烦恼,最终使它转化为具有更少错误的更紧凑代码。
实现线程池的两个最受欢迎的库是
Intel线程构建块(TBB)和
Microsoft并行模式库(PPL) 。
错误编号12:不处理后台线程中发生的异常
在一个线程中引发的异常无法在另一个线程中处理。 假设我们有一个引发异常的函数。 如果我们在与执行主线程分开的单独线程中执行此函数,并且期望我们将捕获从附加线程抛出的任何异常,那么它将无法正常工作。 考虑一个例子:
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr teptr = nullptr ;
void LaunchRocket ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
int main ( )
{
try
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
return 0 ;
}
当执行此程序时,它将崩溃,但是,main()函数中的catch块将不执行,并且将无法处理线程t1中引发的异常。
解决此问题的方法是使用C ++ 11中的功能:
std :: exception_ptr用于处理在后台线程中引发的异常。 这是您需要采取的步骤:
通过引用调用异常不会在创建它的线程中发生,因此此功能非常适合处理不同线程中的异常。
在下面的代码中,您可以安全地处理在后台线程中引发的异常。
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr globalExceptionPtr = nullptr ;
void LaunchRocket ( )
{
try
{
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
catch ( ... )
{
//
globalExceptionPtr = std :: current_exception ( ) ;
}
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
if ( globalExceptionPtr )
{
try
{
std :: rethrow_exception ( globalExceptionPtr ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
}
return 0 ;
}
错误13:使用线程模拟异步操作,而不是使用std :: async
如果您需要代码以异步方式执行,即 在不阻塞执行主线程的情况下,最好的选择是使用
std :: async() 。 这等效于创建流并通过指向lambda函数形式的函数或参数的指针传递在该流中执行的必要代码。 但是,在后一种情况下,您需要监视此线程的创建,连接/分离以及对该线程中可能发生的所有异常的处理。 如果使用
std :: async() ,则可以减轻这些问题的负担,并大大减少
陷入僵局的机会。
使用
std :: async的另一个重要优点是能够使用
std :: future对象将异步操作的结果返回给调用线程。 假设我们有一个
ConjureMagic()函数,它返回一个int值。 我们可以启动一个异步操作,该异步操作将在任务完成时将将来的值设置为
将来的对象,并且可以在调用该操作的执行流中从该对象中提取执行结果。
// future
std :: future asyncResult2 = std :: async ( & ConjureMagic ) ;
//... - future
// future
int v = asyncResult2. get ( ) ;将结果从正在运行的线程返回给调用者比较麻烦。 两种方法是可能的:
- 将对输出变量的引用传递到将保存结果的流中。
- 将结果存储在工作流对象的字段变量中,线程完成执行后即可读取。
Kurt Guntheroth发现,就性能而言,创建流的开销是使用
async的开销的14倍。
底线:默认情况下使用
std :: async() ,直到找到有利于直接使用
std :: thread的强大参数为止。
错误编号14:如果需要异步,请不要使用std :: launch :: async
std :: async()函数的名称不太正确,因为默认情况下它可能不会异步运行!
有两种
std :: async运行时策略:
- std :: launch :: async :传递的函数开始在单独的线程中立即执行
- std :: launch :: deferred :传递的函数不会立即启动,在对std :: future对象进行get()或wait()调用之前,它的启动会延迟,这将从std :: async调用返回。 代替调用这些方法,该函数将同步执行。
当我们使用默认参数调用
std :: async()时,它以这两个参数的组合开头,实际上会导致不可预测的行为。 使用
std还存在许多其他困难
:默认启动策略使用
async() :
- 无法预测对局部流量变量的正确访问
- 由于在程序执行期间可能不会调用get()和wait()方法,因此异步任务可能根本不会启动
- 当在退出条件期望std :: future对象准备就绪的循环中使用时,这些循环可能永远不会结束,因为调用std :: async返回的std :: future可能开始于延迟状态。
为避免所有这些困难,请
始终使用
std :: launch :: async启动策略调用
std :: async 。
不要这样做:
// myFunction std::async
auto myFuture = std :: async ( myFunction ) ;相反,请执行以下操作:
// myFunction
auto myFuture = std :: async ( std :: launch :: async , myFunction ) ;Scott Meyers在书中“ Effective and Modern C ++”对这一点进行了更详细的考虑。
错误15:在执行时间很关键的代码块中调用std :: future对象的get()方法
下面的代码处理从异步操作的
std :: future对象获得的结果。 但是,
while循环将被锁定,直到异步操作完成(在这种情况下为10秒)。 如果要使用此循环在屏幕上显示信息,则可能导致渲染用户界面时出现令人不快的延迟。
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
int val = myFuture. get ( ) ; // 10
// - Val
}
return 0 ;
}
注意 :上面代码的另一个问题是,它尝试第二次访问
std :: future对象,尽管
std :: future对象的状态是在循环的第一次迭代中获取的,但无法获取。
正确的解决方案是在调用
get()方法之前检查
std :: future对象的有效性。 因此,我们不会阻止异步任务的完成,也不会尝试询问已经提取的
std :: future对象。
此代码段可实现以下目的:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
if ( myFuture. valid ( ) )
{
int val = myFuture. get ( ) ; // 10
// - Val
}
}
return 0 ;
}
№16: , , , std::future::get()
假设我们有以下代码片段,您认为调用std :: future :: get()的结果是什么?如果您认为程序将崩溃-绝对正确!仅当在std :: future对象上调用get()方法时,才会引发异步操作中引发的异常。如果未调用get()方法,则当std :: future对象超出范围时,将忽略并引发异常。如果您的异步操作可能引发异常,则应始终将对std :: future :: get()的调用包装在try / catch块中。有关此示例的示例:#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
int result = myFuture. get ( ) ;
}
return 0 ;
}
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
try
{
int result = myFuture. get ( ) ;
}
catch ( const std :: runtime_error & e )
{
std :: cout << "Async task threw exception: " << e. what ( ) << std :: endl ;
}
}
return 0 ;
}
№17: std::async,
尽管在大多数情况下std :: async()就足够了,但在某些情况下,您可能需要仔细控制流中代码的执行。例如,如果您要将特定线程绑定到多处理器系统(例如Xbox)中的特定处理器核心。给定的代码片段建立了线程与系统中第5个处理器内核的绑定。这要归功于std :: thread对象的native_handle()方法,并将其传递给Win32 API流函数。通过流Win32 API提供的许多其他功能在std :: thread或std :: async()中不可用。通过工作时#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
DWORD result = :: SetThreadIdealProcessor ( t1. native_handle ( ) , 5 ) ;
t1. join ( ) ;
return 0 ;
}
std :: async(),这些基本平台功能不可用,这使此方法不适用于更复杂的任务。另一种方法是创建std :: packaged_task,然后在设置线程的属性后将其移动到所需的执行线程。错误#18:创建的“正在运行”的线程比可用的内核多得多
从体系结构的角度来看,流可以分为两类:“正在运行”和“正在等待”。正在运行的线程占用了正在运行的内核的处理器时间的100%。当一个内核分配多个运行线程时,CPU利用率降低。如果在一个处理器内核上执行多个运行线程,则不会获得性能提升-实际上,由于附加的上下文切换,性能会下降。等待线程仅使用几个时钟周期,在等待系统事件或网络I / O等时执行。在这种情况下,内核的大部分可用处理器时间仍未使用。一个等待线程可以处理数据,而另一个等待线程正在等待事件触发,这就是为什么将多个等待线程分配到一个内核是有利的。每个内核调度多个未决线程可以提供更高的程序性能。那么,如何理解系统支持多少个正在运行的线程呢?使用std :: thread :: hardware_concurrency()方法。此函数通常返回处理器核心的数量,但是由于以下原因,它会考虑充当两个或多个逻辑核心的核心:超踩踏。您必须使用获得的目标平台值来计划程序同时运行的最大线程数。您还可以为所有挂起的线程分配一个核心,并使用剩余的核心数来运行线程。例如,在四核系统中,对所有挂起的线程使用一个核,对于其余三个核,使用三个运行线程。根据线程调度程序的效率,某些可执行线程可能会切换上下文(由于页面访问失败等),从而使内核处于非活动状态一段时间。如果在分析过程中观察到这种情况,则应创建比内核数量稍多的已执行线程,并为系统配置该值。错误19:使用volatile关键字进行同步
在指定变量类型之前,volatile关键字不会使对该变量进行原子或线程安全的操作。您可能想要的是std :: atomic。有关更多详细信息,请参见关于stackoverflow的讨论。错误20:除非绝对必要,否则请使用无锁架构
-, . , (lock free), , , , . . , C ++, , , , ( , !).
C ++ , , , 10 .
, :
总之,对于正常的应用程序开发,请仅在用尽所有其他替代方法后才考虑非锁定编程。另一种看待这种情况的方式是,如果您仍在犯上述19个错误中的某些错误,则可能应避免编程而不会阻塞。[从。译者:非常感谢vovo4K帮助我准备了本文。