亚历山大·鲁宾(Alexander Rubin)在Percona工作,并在
HighLoad ++上进行了
不止一次的演奏,参与者是MySQL的专家。 合理地假设,今天我们将讨论与MySQL相关的内容。 之所以如此,只是部分原因是因为我们还将讨论
物联网 。 这个故事将是有趣的一半,尤其是在第一部分中,我们将看看亚历山大创造的用来收获杏子的装置。 这就是真正的工程师的天性-如果您想要水果,就需要付费。

背景知识
一切始于一个简单的愿望,即在该地区种一棵果树。 这样做似乎很简单-您来商店买苗。 但是在美国,卖家要问的第一个问题是树会收到多少阳光。 对于亚历山大来说,这是一个巨大的谜团-完全未知该站点上有多少阳光。
为了找出答案,学生每天可以到院子里看阳光多少,然后写在笔记本上。 但是事实并非如此-一切都需要配备设备和自动化。
在演示过程中,运行并播放了许多示例。 要获得比文字更完整的图片,请切换到观看视频。因此,为了不在笔记本上记录天气观测,有大量用于Internet的设备-Raspberry Pi,新的Raspberry Pi和Arduino-数千种不同的平台。 但是我为此项目选择了一种名为“
粒子光子”的设备。 它非常易于使用,在官方网站上售价19美元。
关于粒子光子的好处是:
- 100%云解决方案;
- 任何传感器都适用于例如Arduino。 它们的价格都不到一美元。
我制作了这样的设备,并将其放在现场的草地上。 它具有粒子设备云和控制台。 该设备通过Wi-Fi热点连接并发送数据:光线,温度和湿度。 测试仪在一块小的电池上可以持续24小时,这是相当不错的。
此外,我不仅需要测量照明等等,然后将它们传输到手机(这确实很好-我可以实时看到我拥有哪种照明),还
需要存储数据 。 为此,我自然选择了MySQL作为MySQL的资深人士。
我们如何在MySQL中写入数据
我选择了一个相当复杂的方案:
- 我从粒子控制台获取数据;
- 我使用Node.js将它们写入MySQL。
我使用的是Particle JS API,可以从Particle网站下载。 我建立与MySQL的连接并进行写操作,也就是说,我只是执行INSERT INTO值。 这样的管道。
因此,设备位于院子中,通过Wi-Fi连接到家庭路由器,并使用MQTT协议将数据传输到Particle。 然后就是这个方案:Node.js上的程序在虚拟机上运行,该虚拟机从Particle接收数据并将其写入MySQL。
首先,我从R中的原始数据构建了图表。图表显示,温度和光照在白天升高,在夜间下降,湿度升高-这是自然的。 但是图表上也有噪声,这是物联网设备的典型现象。 例如,当错误爬到设备上并将其关闭时,传感器可以传输完全不相关的数据。 这对于进一步考虑很重要。
现在,我们来讨论MySQL和JSON,它们在使用JSON的过程中已经从MySQL 5.7更改为MySQL8。然后,我将展示一个使用MySQL 8的演示(在报告该版本尚未准备好生产时,已经发布了稳定版本)。
MySQL数据存储
当我们尝试存储从传感器接收的数据时,我们的第一个想法是
在MySQL中创建一个表 :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
在这里,对于每个传感器和每种数据类型,都有一列:光,温度,湿度。
这是合乎逻辑的,但是
存在一个问题-它不灵活 。 假设我们要添加另一个传感器并测量其他东西。 例如,有些人测量小桶中剩余的啤酒。 在这种情况下该怎么办?
alter table sensor_wide add water level double ...;
如何变态以便向表中添加内容? 您需要制作一个alter table,但是如果您在MySQL中做了一个alter table,那么您知道我在说什么-这是完全困难的。 MySQL 8和MariaDB中的Alter表要简单得多,但是从历史上看这是一个大问题。 因此,如果我们需要添加例如啤酒名称的列,那么事情就不会那么简单了。
同样,传感器出现,消失,我们该如何处理旧数据? 例如,我们停止接收有关照明的信息。 还是我们要创建一个新列-如何存储以前不存在的内容? 标准方法是空的,但是对于分析它不是很方便。
另一个选择是键/值存储。
MySQL数据存储:键/值
这将
更加灵活 :在键/值中将有一个名称,例如温度和相应的数据。
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
在这种情况下,会出现
另一个问题-没有类型 。 我们不知道我们在“数据”字段中存储了什么。 我们将不得不将其声明为文本字段。 创建物联网设备时,我知道有哪种传感器以及相应的传感器类型,但是如果您需要将其他人的数据存储在同一张表中,则我将不知道要收集什么数据。
您可以存储许多表,但是为每个传感器创建一个全新的表并不是很好。
该怎么办? -使用JSON。
MySQL数据存储:JSON
好消息是,在MySQL 5.7中,您可以将JSON存储为字段。
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
在MySQL 5.7出现之前,人们还存储JSON,但存储为文本字段。 MySQL中的JSON字段可让您最有效地存储JSON本身。 此外,基于JSON,您可以基于它们创建虚拟列和索引。
唯一的小问题是
表在存储过程中会增大 。 但是,我们得到了更大的灵活性。
JSON字段比文本字段更适合存储JSON,因为:
- 提供自动文档验证 。 也就是说,如果我们尝试在此处写入无效的内容,则会发生错误。
- 这是一种优化的存储格式 。 JSON以二进制格式存储,这使您可以从一个JSON文档切换到另一个JSON文档(称为跳过)。
要以JSON格式存储数据,我们可以简单地使用SQL:制作一个INSERT,在其中放置“数据”并从设备中获取数据。
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
演示版
为了演示(
在视频中开始),该示例使用了其中包含SQL的虚拟机。

下面是该程序的一部分。
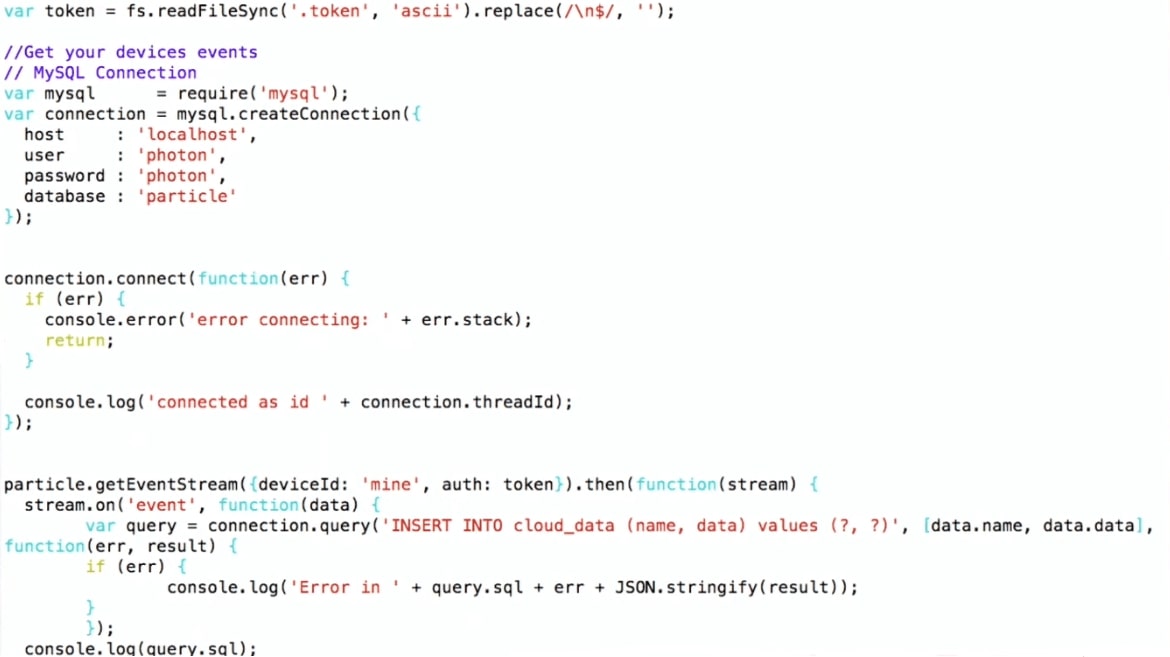
我执行
INSERT INTO cloud_data (name, data) ,我已经获得了JSON格式的数据,并且可以直接将其直接写入MySQL,而无需考虑内部内容。
事实证明,使用此云,您不仅可以访问我的设备的数据,而且还可以访问此粒子使用的
所有数据 。 到目前为止,它似乎仍然有效。 全世界使用粒子光子的人们都在发送一些数据:车库的门是开着的,或者啤酒的其余部分是这样的或其他。 这些设备位于何处尚不清楚,但可以获取此类数据。 唯一的区别是,当我获取数据时,我会写类似:
deviceId: 'mine' 。
运行代码时,我们从正在做某事的其他人的设备中获取一些数据流。
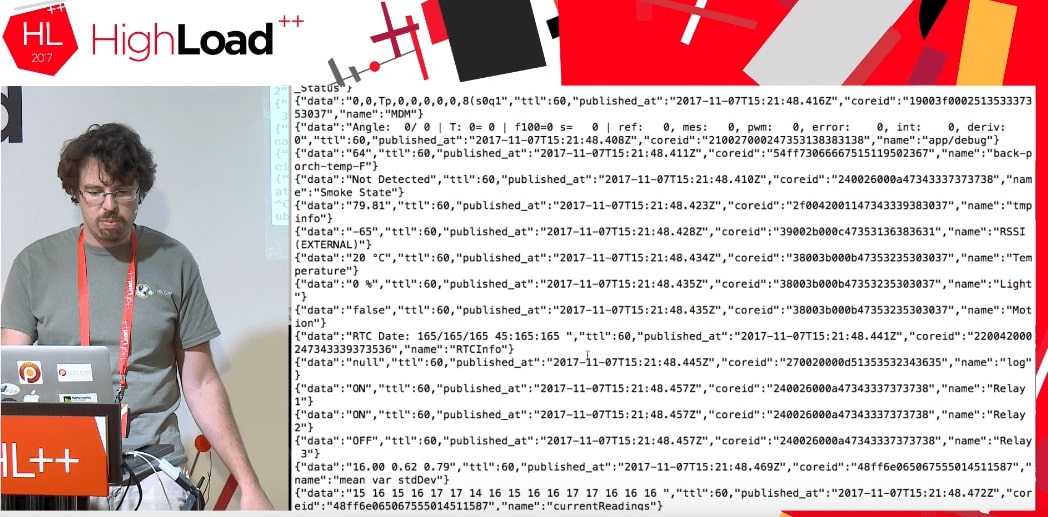
我们根本不知道这些数据是什么:TTL,published_at,coreid,门状态(门打开),继电器打开。
这是一个很好的例子。 假设我尝试将其放在MySQL中的常规数据结构中。 我应该知道那里的门,为什么打开的门以及可以使用的一般参数。 如果我有JSON,则将其作为JSON字段直接写入MySQL。
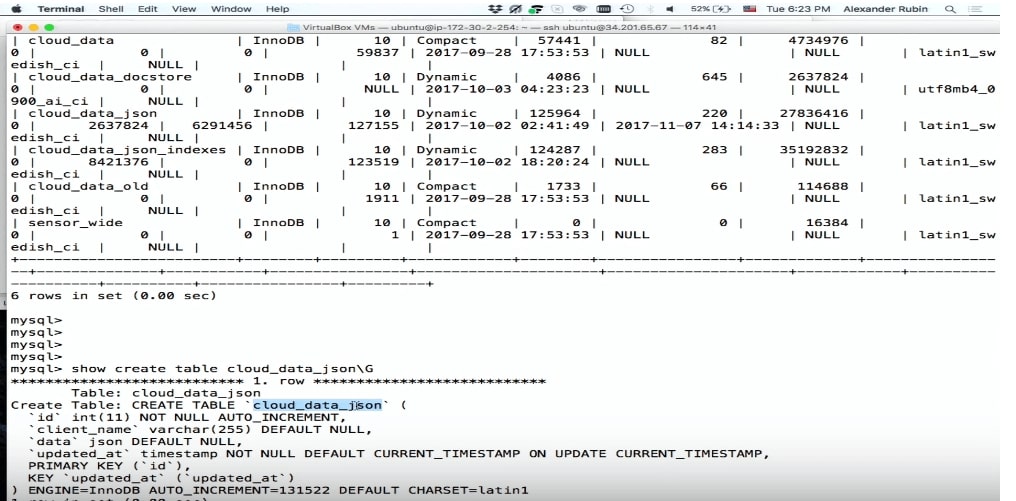
拜托,一切都被记录了。
文件存储
文档存储是MySQL中为JSON存储的一种尝试。 我非常喜欢SQL,非常熟悉SQL,可以进行任何SQL查询,等等。 但是由于种种原因,许多人不喜欢SQL,因此文档存储可以为他们提供解决方案,因为有了它,您可以从SQL中抽象,连接到MySQL并直接在其中编写JSON。

MySQL 5.7中出现了另一种可能性:使用不同的协议,不同的端口,并且还需要另一个驱动程序。 对于Node.js(实际上,对于任何编程语言-PHP,Java等),我们使用不同的协议连接到MySQL,并且可以JSON格式传输数据。 再说一次,我不知道这个JSON中有什么-有关门或其他东西的信息,我只是将数据转储到MySQL中,然后我们将其找出来。
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
如果要尝试此操作,则可以配置MySQL 5.7,以便它理解并侦听相应端口的Document Store或X DevAPI。 我使用了connector-nodejs。
这是我在这里写下的例子:啤酒等。我绝对不知道那里有什么。 现在我们将其写下来,然后进行分析。

我们程序的下一点是如何查看其中的内容?
MySQL数据存储:JSON +索引
JSON和MySQL 5.7中有一个很棒的功能,可以将字段拉出JSON。 这是JSON_EXTRACT函数上的这种语法糖。 我觉得这很方便。
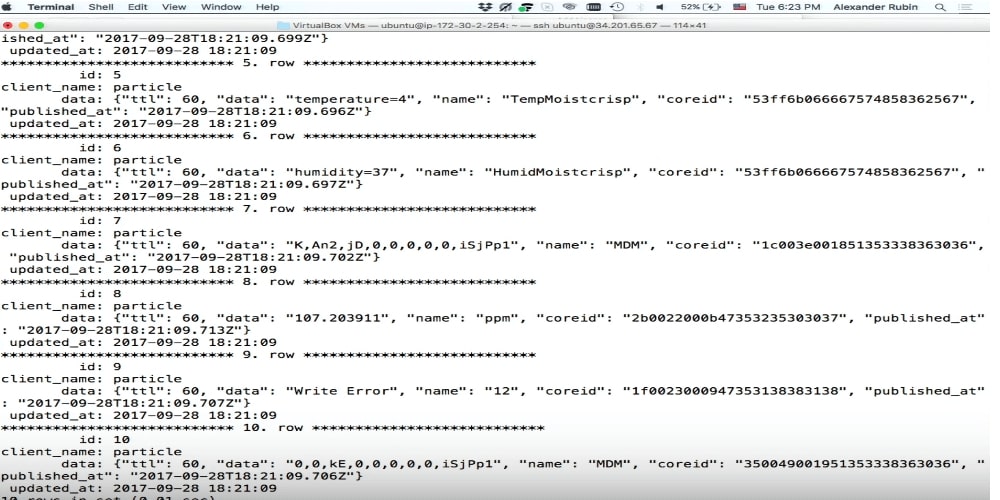
在我们的案例中,数据是存储JSON的列的名称,而name是我们的字段。 名称,数据,published_at-这就是我们可以通过这种方式提取的全部内容。
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
在这个例子中,我想看看我写到MySQL表的内容以及最后10条记录。 我提出了这样的请求,并尝试执行它。 不幸的是,
这将持续很长时间 。
从逻辑上讲,在这种情况下,MySQL将不使用任何索引。 我们从JSON中提取数据,并尝试应用某种过滤器和排序。 在这种情况下,我们获得使用文件排序。
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
使用filesort非常不好,它是一种外部排序。
好消息是您可以采取2个步骤来加快速度。
步骤1.创建一个虚拟列
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
我执行EXTRACT,也就是说,我从JSON中提取数据,并基于它创建一个虚拟列。 虚拟列未存储在MySQL 5.7和MySQL 8中-只是创建单独列的能力。
您问这是怎么回事,您说过ALTER TABLE这么长的操作。 但这还不错。
创建虚拟列很快 。 那里有很多,但实际上在MySQL中,所有DDL操作都有锁。 ALTER TABLE是一个相当快的操作,它不会重建整个表。
我们在这里创建了一个虚拟列。 我必须转换日期,因为在JSON中它以iso格式存储,但是在这里MySQL使用了完全不同的格式。 为了创建一个列,我给它命名,给它一个类型,并说我要在那里记录。
要优化原始查询,您需要提取published_at和name。 Published_at已经存在,名称更容易-只需创建一个虚拟列即可。
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
步骤2.创建索引
在下面的代码中,我在published_at上创建索引并执行查询:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
您可以看到MySQL实际上使用了索引。 这是按顺序进行的优化。 在此示例中,数据和名称未编制索引。 MySQL使用按数据排序,并且由于我们在published_at上有一个索引,因此它使用它。
此外,我可以使用相同的语法糖
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")而不是按顺序)。 MySQL仍然会理解在此列上有一个索引并开始使用它。
实际上,这有一个小问题。 假设我不仅要按published_at排序数据,还要按名称排序。
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
如果您的设备每秒处理数万个事件,由于存在重复项,published_at不会给出很好的排序。 因此,我们添加了另一个按data_name排序。 这不仅是物联网的典型查询:给我最后10个事件,然后按日期对它们进行排序,然后再按例如人的姓氏升序进行排序。 为此,在上面的示例中,有两个字段并指定了两个排序键:降序和升序。
首先,在这种情况下,MySQL将不使用索引。 在这种特殊情况下,MySQL决定全表扫描比使用索引更有利可图,并且再次使用非常慢的文件排序操作。
MySQL 8.0的新功能
下降/上升
在MySQL 5.7中,仅以其他事情为代价,无法优化此类查询。 在MySQL 8中,确实有机会为每个字段指定排序。
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
最有趣的是,索引名称后的降序/升序键早已在SQL中使用。 即使在MySQL 3.23的第一个版本中,您也可以指定Published_at降序或Published_at升序。 MySQL接受了这一点,
但是什么也没做 ,也就是说,它总是沿一个方向排序。
在MySQL 8中,此问题已修复,现在有了这样的功能。 您可以按降序创建字段并使用默认排序。
让我们回头再看一下第2步中的示例。
为什么有效,否则无效? 之所以可行,是因为在MySQL索引中,它是一个B树,并且B树索引可以从头到尾读取。 在这种情况下,MySQL从末尾读取索引,一切正常。 但是,如果我们进行下降和上升,那么您将无法阅读。 您可以按相同的顺序阅读,但
不能将两种分类结合使用 -您需要重新分类。
由于我们正在优化一个非常特殊的情况,因此我们可以为其创建索引并指定特定的排序:此处的published_at为降序,data_name为升序。 MySQL使用此索引,一切都会很快。
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
这是MySQL 8的一项功能,在发布时,该功能现已可用并可以在生产中使用。
输出结果
我还想展示两个有趣的东西:
1.漂亮的打印,即漂亮的数据输出到屏幕。 使用普通的SELECT,将不会格式化JSON。
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2.我们可以说MySQL将以JSON数组或JSON对象的形式输出结果,指定字段,然后将输出格式化为JSON。
JSON文档中的全文本搜索
如果我们使用灵活的存储系统并且不知道JSON内含什么内容,那么使用全文搜索将是合乎逻辑的。
不幸的是,
全文搜索有其局限性 。 我尝试的第一件事就是创建一个全文本密钥。 我试图做这样的事情:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
不幸的是,这不起作用。 不幸的是,即使在MySQL 8中,仅通过JSON字段创建全文索引也是不可能的。 当然,我想拥有这样的功能-至少可以通过JSON键进行搜索的功能将非常有用。
但是,如果这还不可能,我们创建一个虚拟列。 在我们的例子中,有一个数据字段,让我们看看里面有什么有趣。
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
不幸的是,这也不起作用-
您不能在virtual column上创建全文索引 。
如果是这样,让我们创建一个存储列。 MySQL 5.7允许您将列声明为存储字段。
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
在前面的示例中,我们创建了未存储的虚拟列,但是创建并存储了索引。 在这种情况下,我必须告诉MySQL这是一个STORED列,即它将被创建并将数据复制到该列。 之后,MySQL创建了全文索引,为此,我们不得不重新创建表。 但这实际上是InnoDB和InnoDB全文搜索的限制:您必须重新创建表以添加特殊的全文搜索标识符。
有趣的是,在MySQL 8中,有一个
用于表情符号的
新 UTF8 MB4 编码 。 当然,这对他们而言并不完全,但是因为在UTF8MB3中俄语,中文,日语和其他语言存在一些问题。
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
因此,MySQL 8应该将JSON数据存储在UTF8MB4中。 但是,无论是由于Node.js连接到Device Cloud并在其中错误写入内容还是Beta版本的错误,都没有发生。 因此,我必须先转换数据,然后再将其写入存储的列。
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
之后,我能够在两个字段上创建全文搜索:JSON名称和JSON数据。
不仅是物联网
JSON不仅是物联网。 它可以用于其他有趣的事情:
使用灵活的数据存储方案可以更方便地实现某些事情。 Oracle OpenWorld提供了一个很好的例子:电影院预订。 在关系模型中很难实现这一点-您将获得许多依赖表,联接等。 另一方面,我们可以将整个房间分别存储为JSON结构,将其在MySQL中写入其他表并以通常的方式使用:基于JSON创建索引,等等。
复杂的结构以JSON格式方便地存储。
这是一棵成功栽种的树。 不幸的是,几年后,鹿吃了它,但这是一个完全不同的故事。
该报告是一个很好的示例,说明了整个部分如何在大型会议上脱离一个主题,然后又脱离一个单独的事件。 在物联网方面,我们获得了InoThings ++ -面向物联网市场专业人士的会议,该会议将于4月4日第二次举行。
会议的中心事件似乎将是“我们需要物联网国家标准吗?” 圆桌会议 ,有机地将由全面的应用报告加以补充。 如果您的重载系统正在正确地转移到IIoT,请来。