
在生产中使用Kubernetes的多年来,我们积累了许多有趣的故事,因为各种系统组件中的错误导致影响容器和吊舱操作的令人不愉快和/或难以理解的后果。 在本文中,我们选择了一些最常用或最有趣的选项。 即使您从来没有幸运地遇到过这种情况,阅读有关这类简短的侦探的信息(尤其是第一手资料)总是很有趣,不是吗?
历史1.超cronic和冻结Docker
在其中一个集群上,我们定期收到一个“冻结”的Docker,它干扰了集群的正常运行。 同时,在Docker日志中观察到以下内容
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
在此错误中,我们对以下消息最感兴趣:
pthread_create failed: No space left on device 。 对
文档的快速研究表明,Docker无法分叉该进程,这导致其定期“冻结”。
在监视发生的情况时,下图对应:

在其他节点上也观察到类似情况:


在相同的节点上,我们看到:
root@kube-node-1 ~
事实证明,此行为是
超cronic的
pod工作的
结果 (我们用来在pod中运行cron任务的Go实用程序):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
问题是这样的:当任务以超cronic形式启动时,它所生成的过程
无法正确完成 ,变成了
僵尸 。
注意 :更精确地说,进程是由cron任务生成的,但是supercronic并不是一个init系统,因此不能“采用”其子级产生的进程。 当发生SIGHUP或SIGTERM信号时,它们不会传输到生成的进程,因此子进程不会终止,仍然处于僵尸状态。 例如,您可以在此类文章中阅读有关所有这些内容的更多信息。有两种解决问题的方法:
- 作为暂时的解决方法-在单个时间点增加系统中PID的数量:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- 或者,不是直接在超级crocronic中启动任务,而是借助相同的tini来启动任务,它可以正确终止进程而不产生僵尸。
历史记录2.删除cgroup时出现“僵尸”
Kubelet开始消耗大量CPU:
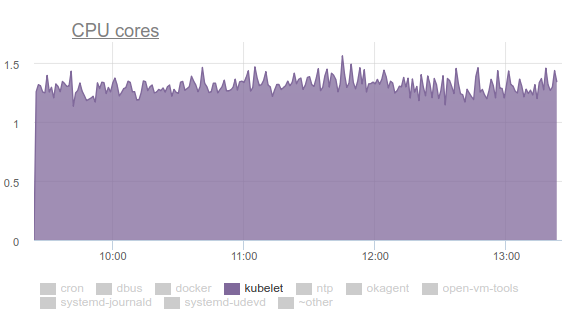
没有人喜欢这样,所以我们用性能武装自己,开始解决这个问题。 调查结果如下:
- Kubelet花了超过三分之一的CPU时间从所有cgroup中提取内存数据:

- 在内核开发人员邮件列表中,您可以找到有关该问题的讨论 。 简而言之,最重要的是,删除cgroup时, 不同的tmpfs文件和其他类似内容不会从系统中完全删除-剩下所谓的memcg zombie 。 迟早它们仍将从页面缓存中删除,但是服务器上的内存很大,内核看不到浪费时间的问题。 因此,他们继续积累。 为什么会这样呢? 这是一台具有cron作业的服务器,该服务器不断创建新作业,并为其创建新的pod。 因此,将为其中的容器创建新的cgroup,并将很快将其删除。
- 为什么kubelet中的cAdvisor花这么多时间? 通过
time cat /sys/fs/cgroup/memory/memory.stat的最简单执行,很容易看出这一点。 如果在正常运行的机器上操作需要0.01秒,那么在有问题的cron02上需要1.2秒。 问题是cAdvisor会非常缓慢地从sysfs读取数据,它也会尝试考虑僵尸cgroup中已使用的内存。 - 为了强制删除僵尸,我们尝试按照LKML中的建议清除缓存
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches ,但是内核却变得更加复杂并挂起了计算机。
怎么办 通过将Linux内核更新为版本4.16,可以解决此问题(
commit和其描述,请参见
发行消息 )。
历史3. Systemd及其安装
同样,kubelet在某些节点上消耗了太多的资源,但是这次已经是内存了:

事实证明,在Ubuntu 16.04中使用的systemd中存在问题,并且在控制为从ConfigMaps或密钥连接子
subPath而创建的安装时,会发生此问题。 Pod完成后,
systemd服务及其服务安装将保留在系统上。 随着时间的推移,它们积累了大量。 关于此主题甚至还有一些问题:
- 鲤鱼#5916 ;
- kubernetes#57345 。
...最后一个参考systemd中的PR:
#7811 (systemd中的问题为
#7798 )。
问题在Ubuntu 18.04中不再存在,但是如果您想继续使用Ubuntu 16.04,则有关此主题的解决方法可能会派上用场。
因此,我们制作了以下DaemonSet:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
...,它使用以下脚本:
...它每5分钟从已经提到的超cronic开始。 他的Dockerfile看起来像这样:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
历史4.规划吊舱的竞争
需要注意的是:如果一个pod放置在我们的节点上并且其图像被抽出了很长时间,那么“到达”同一节点的另一个pod根本
不会开始提取新pod的图像 。 相反,他等待上一个吊舱的图像被拉出。 结果,已经计划好并且可以在短短一分钟内下载图像的Pod将长期处于
containerCreating状态。
在事件中,将出现以下内容:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
事实证明,
慢速注册表中
的单个映像可能会阻止部署到节点。
不幸的是,没有太多方法可以解决这种情况:
- 尝试直接在集群中或直接在集群中使用Docker Registry(例如,GitLab Registry,Nexus等);
- 使用kraken之类的实用程序。
历史记录5.挂起内存不足的节点
在各种应用程序的运行过程中,我们还收到一种情况,该节点完全无法访问:SSH不响应,所有监视守护程序都掉线,然后日志中没有异常(或几乎没有异常)。
我将在MongoDB发挥作用的一个节点示例中的图片中告诉您。
这是崩溃
前的样子:

等等-事故发生后:

在监视中,节点也将无法访问,这是一个急剧的跳跃:
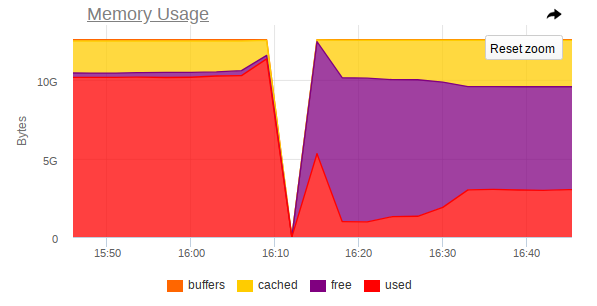
因此,屏幕截图显示:
- 机器上的RAM快用完了;
- 观察到RAM消耗急剧增加,此后,将严重禁止访问整个计算机。
- 一项艰巨的任务到达了Mongo,这迫使DBMS进程使用更多的内存并主动从磁盘读取数据。
事实证明,如果Linux用完了可用内存(发生内存压力)并且没有交换,那么
在 OOM杀手er到来
之前 ,在将页面缓存到页面缓存并将它们写回到磁盘之间可能会出现平衡。 这是由kswapd完成的,它会勇敢地释放尽可能多的内存页以供以后分发。
不幸的是,由于I / O负载很大,再加上少量的可用内存,
kswapd成为整个系统的瓶颈 ,因为系统中内存页面的
所有页面错误都与之相关。 如果进程不再使用内存,而是固定在OOM杀手级深渊的边缘,则此过程可能会持续很长时间。
逻辑上的问题是:为什么OOM杀手来得这么晚? 在当前的OOM迭代中,杀手非常愚蠢:仅当分配内存页的尝试失败时,杀手才会杀死进程。 如果页面错误失败。 这不会发生很长时间,因为kswapd通过将页面缓存(实际上是系统中的所有磁盘I / O)刷新回磁盘来勇敢地释放内存页面。 更详细地讲解消除内核中此类问题所需的步骤,可以
在此处阅读。
在Linux 4.6+内核中,此行为
应有所改善 。
故事六。豆荚正在等待
在确实有很多Pod的某些集群中,我们开始注意到,尽管Docker容器本身已经在节点上运行,并且您可以手动使用它们,但它们中的大多数悬挂在
Pending状态的时间很长。
describe没有错:
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
深入研究之后,我们假设kubelet只是没有时间向API服务器发送有关Pod状态,活动性/就绪性示例的所有信息。
通过研究帮助,我们发现了以下参数:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
如您所见,
默认值很小 ,
只有 90%的
默认值可以满足所有需求……但是,在我们的情况下,这还不够。 因此,我们设置以下值:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
...并重新启动kubelet,之后他们在访问API服务器的图表中看到以下图片:

……是的,一切开始飞起来!
聚苯乙烯
对于收集错误和准备文章的帮助,我对公司的众多工程师,尤其是我们研发团队(
zuzzas )的同事Andrei Klimentyev表示深深的谢意。
PPS
另请参阅我们的博客: