响应于正在运行的应用程序数量和网络设备数量的增加,网络带宽增加,并且数据包传递要求越来越严格。 在对企业至关重要的云关键数据中心规模上,传统的基础架构维护方法不再允许解决典型任务。 因此,AIOps(算法IT运营)的概念诞生了。
根据Gartner的调查,到明年,大约50%的公司将使用AIOps。 我们可以使用网络分析仪Huawei FabricInsight的例子来讨论当今类似工具可以做什么,它是华为CloudFabric数据中心全面解决方案的一部分。
企业的数字化转型提供了新的机会-引入大数据分析,开发机器学习算法-不再只是一种时尚,而是一种有意识的需求,关闭它带来了真正的利润。 但是,新的实现方式会导致基础架构的复杂性成倍增加,这同时在维护方面提出了新的挑战。
如今,维护大型基础架构的主要问题是必须收集和处理的数据量才能获得有关数据中心状态的信息,以及对故障原因给出相关答案的速度。 一方面,受监控参数的数量一直在增长,另一方面,时间在与组织争执,因为任何公司的目标都是在出现问题时尽快恢复其服务的可用性(尤其是考虑到严格的SLA要求)。 崩溃后服务“上升”的速度在很大程度上取决于事件调查的速度。 而这又取决于正在发生的事情的信息的完整性。 但是,如果在数据中心中至少安装了50-100个服务器机架,则标准的监视机制将无法满足对带宽和及时传送数据包的高要求。
SNMP为什么会失败?
标准机制-SNMP和xFlow-仅每5到15分钟收集一次数据,并提供采样信息。 开发它们的初衷是为了对累积数据进行后处理的局限性,而没有实时发现问题的任务。 甚至这种有限的数据收集也会影响网络设备的运行。
考虑到有问题的流量仅为3.65%,根据分析结果,传统方法仅揭示了30%的网络问题,其中70%对于监视系统不可见。
有经验的管理员需要知道什么内容以及在哪里寻找才能从SNMP和xFlow收集的数据中识别问题的根源。 必须通过分析大量日志和多个错误消息来确定问题,然后手动进行配置更改。 但是随着SDN的发展以及物理资源的虚拟化,手动配置已成为过去。 如今,即使是整个系统管理员,也无法再确保基础结构参数不断满足业务需求。
FabricInsight工作方式不同
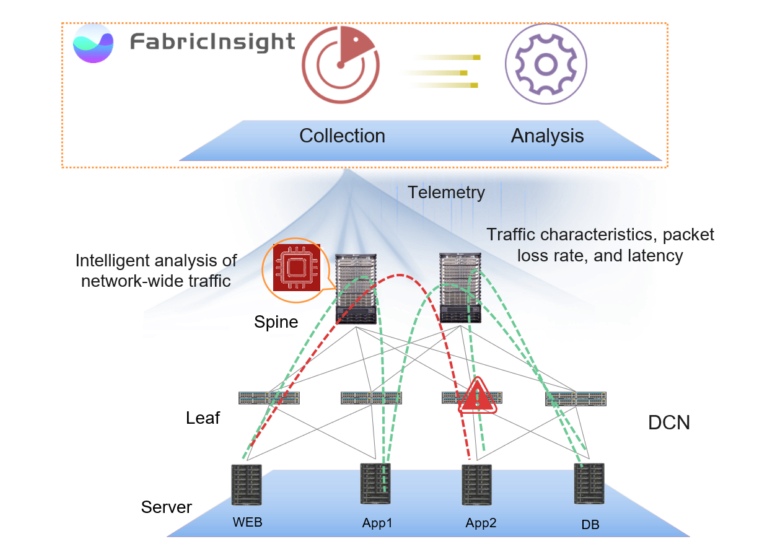
FabricInsight网络分析平台提供了另一种方法,可自动执行网络维护和故障点检测。 FabricInsight分析应用程序的行为,识别应用程序使用的网络路径并跟踪应用程序上的设备状态。

此方法基于两个关键组件-所有可用数据的收集及其自动分析。 与功能可视化和数据开放性策略相辅相成,这种方法使我们能够解决许多以前都是死胡同的问题。
收集所有可用数据。
快速应对这种情况的关键是在网络级别上全面了解数据中心内部发生的情况。 FabricInsight使用推送遥测订阅机制来及时收集所有第二级服务数据,而无需进行采样。 为了全面了解网络,需要收集有关设备操作,应用程序和网络流量(TCP SYN,FIN和RST数据包)传递的数据-支持ERSPAN来镜像数据包,而无需使用设备的CPU和Google的GRPC来报告设备本身的性能。
通过FabricInsight LEAF收集的数据将传输到FabricInsight收集器,后者监视通过网络的数据包的时间参数。 收集器提供带有时间戳的网络流量数据,进行编码并通过HTTP发送到FabricInsight Analyzer。 这种方法使您可以收集有关网络的最大信息,甚至捕获“经典”解决方案无法检测到的短期流量突发。
同时,FabricInsight不查找IP数据包的内部(它不捕获其内容),仅在其工作中使用标头。 因此,它可以用于对业务至关重要的领域,例如,处理个人数据的地方。
实时分析
该系统的第二个组成部分是FabricInsight分析器。 接收到收集到的数据后,它可以识别交通路径并运行算法,从而几乎实时地分析情况。 通常,FabricInsight Analyzer将网络流量与应用程序相关联,使您能够快速识别和修复问题。 由于机器学习的原因,对算法进行了“训练”以识别基础结构的正常和异常行为。
NetworkInsight在其界面中以网络状态图,应用程序交互,单个应用程序的分析等形式实时反映网络分析的结果,并实时更新。 该接口的实现方式以可视方式链接应用程序级别和负责网络可操作性的特定物理设备,从而加快了查找故障的方法和解决方法。
如果在自动模式下检测到任何异常,则将保存初始信息,根据这些信息已识别出问题(存储持续时间是可调的),必要时-FabricInsight警告用户。 此外,初始化了通过图形界面“一键式”纠正情况的过程。 同时,分析各种纠错模式以找到最相关的方法。
案例
为了识别数据中心异常,使用了对应用程序,设备和流量路径操作的相关性分析,因此记录了各种类型的异常-临时的和长期的。

顺便说一下,上面提到的大多数临时异常无法使用经典方法来解决。 这也适用于某些长期异常。 一个相当常见的示例是“弯曲的”软件更新。 假设某个应用程序正在数据中心中运行,并且产生了某些流量。 更新后,此流量的数量发生了巨大变化,例如,应用程序吞吐量下降了,延迟增加了。 FabricInsight将修复此异常。
另一个例子是在故障之前光通信模块的逐渐退化(性能损失)。 降级决定了传输的不稳定性,这在很长一段时间内可能表明需要尽早更换设备。 但是用标准方法来识别这一点非常困难。

为了解决这个问题,FabricInsight界面显示了系统中所有光模块的状态以及它们发生故障的可能性的估计值。

整合性
尽管FabricInsight于今年1月在俄罗斯市场上亮相,但已经在ICBC,中国银联,招商银行,PICC和其他基于华为基础设施的大型数据中心中进行了部署。
到目前为止,该解决方案仅支持我们的交换机(在Broadcom芯片组上),但是在将来,它计划超越一个制造商的生态系统。 另外,在使用FabricInsight时,我们最初专注于开放标准,因此我们可以正常地与第三方工具交朋友。 例如,可以使用Druid从FabricInsight导出数据,通过该数据可以将信息发送到第三方可视化器。 FabricInsight也已经与Grafana的开放渲染工具集成在一起。
通常,诸如FabricInsight之类的AIOps工具是开发基础架构监视和维护工具的逻辑方法。 在我们看来,这是继续遵守SLA服务的唯一途径。