哈Ha!
我叫Anton Markelov,我是United Traders的操作工程师。 我们以一种或另一种方式从事与投资,交易和其他财务事项有关的项目。 我们不是一个很大的公司,大约有30名开发工程师,规模合适-不到一百台服务器。 在基础架构的数量和质量增长期间,经典的解决方案“我们将应用程序及其数据库都保存在同一服务器上”在可靠性和速度方面都不再适合我们。 分析师方面,需要创建跨数据库查询,操作部门已经厌倦了搞乱备份和监视大量数据库服务器。 最重要的是,将状态与应用程序本身存储在同一台计算机上大大降低了资源计划的灵活性和基础架构的弹性。
过渡到当前体系结构的过程是不断发展的,已经测试了各种解决方案,既为开发人员和分析人员提供了方便的界面,又提高了整个经济体系的可靠性和可管理性。 我想谈谈我们的DBMS现代化的主要阶段,我们遇到的困难以及做出的决定,因此,一个容错的独立环境为操作工程师,开发人员和分析人员提供了便捷的交互方式。 我希望我们的经验对我们规模的公司的工程师有用。
本文是我在UPTIMEDAY会议上的
报告的摘要,也许视频格式对某人来说会更舒适,尽管作家用我的双手比说一些说话的人要好一些。
KDPV的“雪花人”是从马克西姆·多罗费耶夫(Maxim Dorofeev)的无耻
借来的 。
生长疾病
我们有一个微服务架构,服务主要使用Spring框架以Java或Kotlin编写。 每个微服务旁边都有一个PostgreSQL基础,上面的所有内容都由nginx覆盖以提供访问权限。 典型的微服务是Spring Boot上的一个应用程序,该应用程序将其数据写入PostgreSQL(同时是部分应用程序和ClickHouse),通过Kafka与邻居进行通信,并具有一些REST或GraphQL端点与外界进行通信。
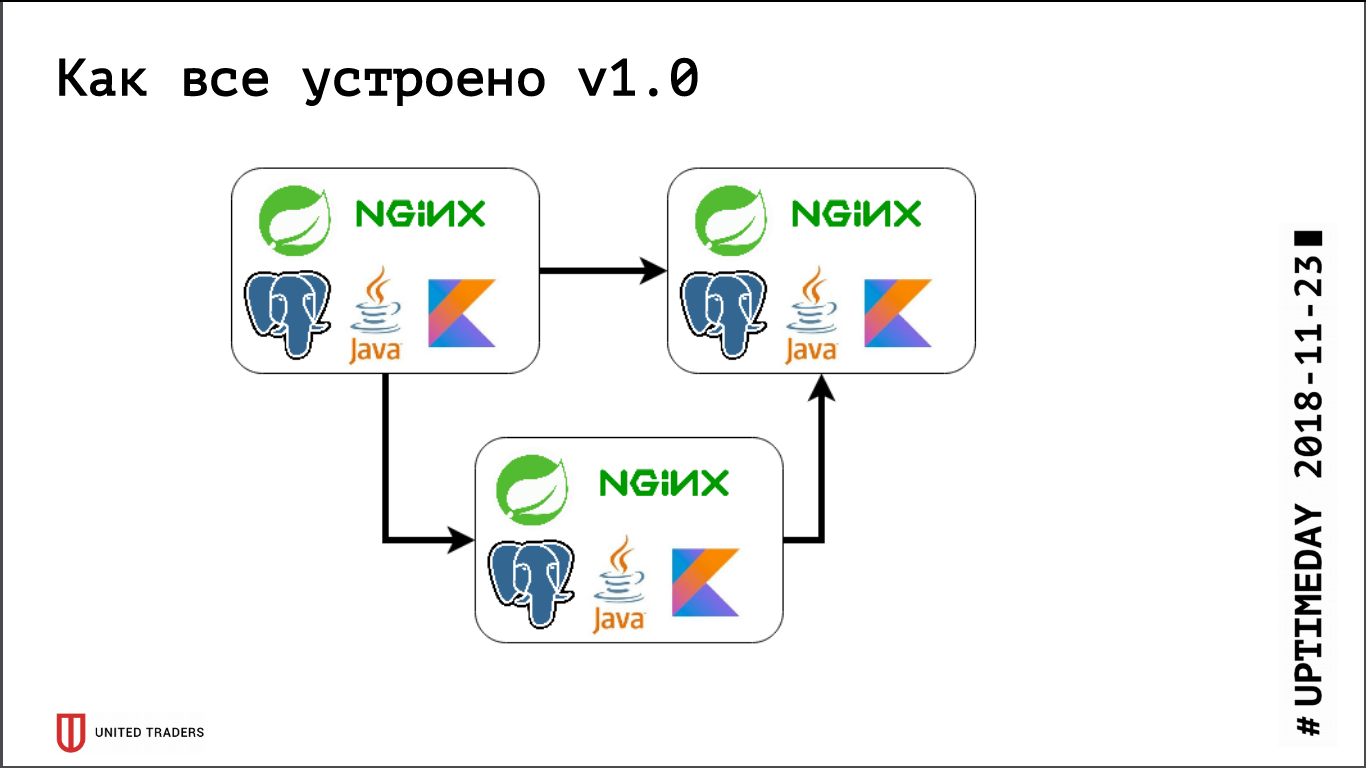
以前,当我们很小的时候,我们只是在DigitalOcean中保留了几台服务器,而Kafka还不在那里,所有通信都是通过REST进行的。 也就是说,我们花了一个小滴,在那里安装了Java,PostgreSQL,nginx,并在那里启动了Zabbix,以便它可以监视服务器资源和服务端点的可用性。 他们在Ansible的帮助下部署了所有内容,我们获得了标准化的剧本,整个服务推出了四到五个角色。 相对而言,只要我们有6台服务器在生产中,有3台在测试中-您就可以以某种方式使用它。
然后开始活跃的开发阶段,应用程序的数量增加,十个微服务变成了四十个,它们的功能开始改变,并且出现了与外部系统(例如CRM,客户站点等)的集成。 我们第一个痛苦。 一些应用程序开始消耗更多的资源,停止进入现有服务器,我们遇到了小故障,来回拖动应用程序,花了很多力气。 它的伤害非常严重-没有人喜欢愚蠢的机械工作,-我想迅速做出决定。 因此,我们进行了正面讨论-我们只使用了3个大型专用服务器,而不是10个云滴。 这解决了一段时间,但是很明显,是时候为某种编排和服务器重新平衡制定解决方案了。 我们开始密切关注DC / OS和Kubernetes等解决方案,并逐渐增加我们在该领域的专业知识。
大约在同一时间,我们有一个分析部门,该部门需要定期提出困难的要求,准备报告,使用漂亮的仪表板,这给我们带来了第二个痛苦。 首先,分析人员负担很重的基础,其次,他们需要跨数据库查询,因为 每个微服务保留一个相当狭窄的数据片。 我们测试了几个系统,起初我们尝试通过表级复制来解决所有问题(它是在第九个PostgreSQL中提供的,没有开箱即用的逻辑复制),但是基于pgologic,Presto,Slony-I和Bucardo的技术并没有完全实现。安排。 例如,pgologic不支持迁移-推出了新版本的微服务,数据库的结构发生了变化,Java本身使用Flyway更改了结构,并且在pgologic中的副本上需要手动更改所有内容。 否则,要么缺少某些东西,要么太难了。
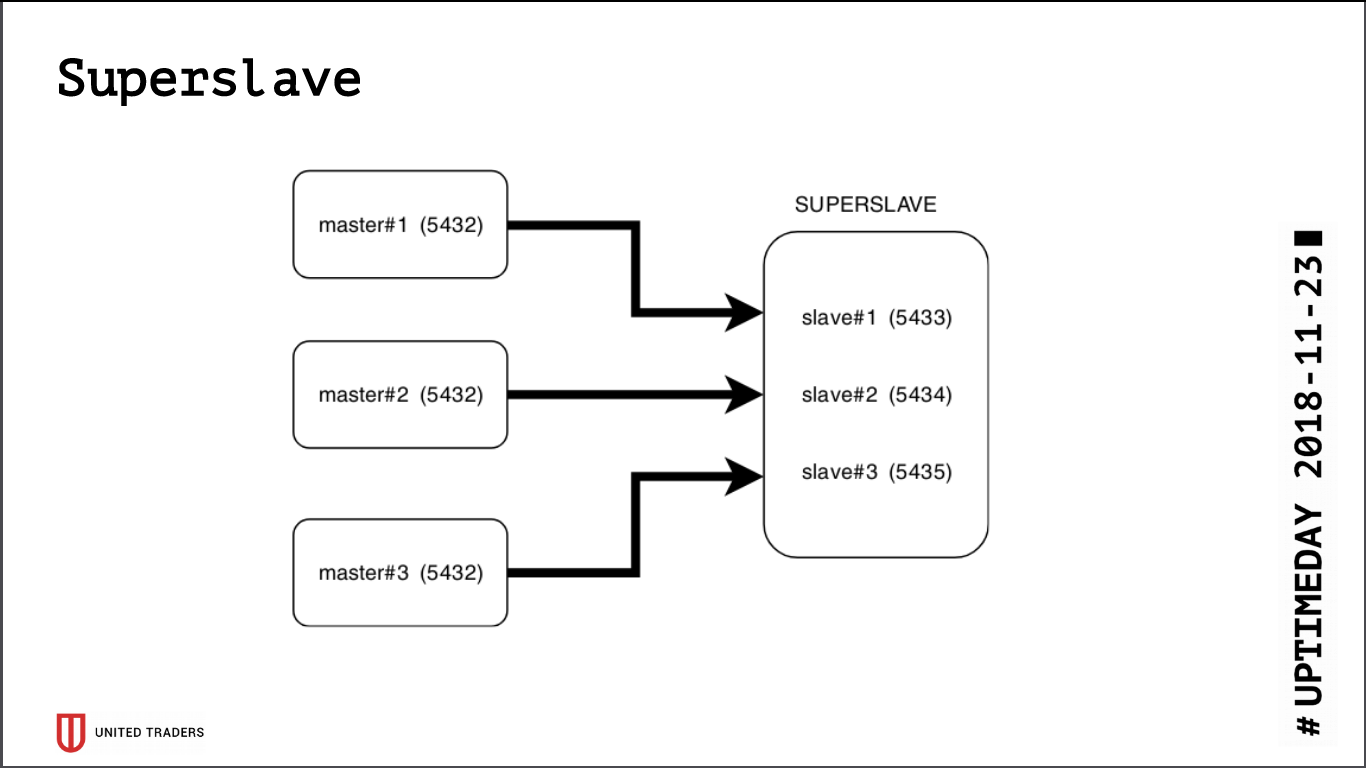
超级奴隶
研究的结果是诞生了一个简单而残酷的解决方案,称为Superslave:我们采用了一个单独的服务器,在其上为每个生产服务器在不同端口上配置一个从属服务器,并创建了一个虚拟数据库,该虚拟数据库通过postgres_fdw(外部数据包装器)合并了来自该从属服务器的数据库。 也就是说,所有这些都是通过postgres的标准方法实现的,而没有简单而可靠地引入其他实体的情况:只需一个请求,便可以从多个数据库中获取数据。 我们将此虚拟跨库提供给了分析师。 另一个优点是,即使具有访问权限错误,只读副本也无法在其中写入任何内容。
我们使用
Redash进行可视化,它知道如何绘制图表,按计划执行请求(例如每天一次),并且拥有足够的权限系统,因此我们让分析师和开发人员可以使用它。

同时,持续增长,Kafka作为总线和ClickHouse出现在基础架构中,用于分析存储。 他们很容易地被打包成盒子,我们超级奴隶在他们的背景下看起来像笨拙的化石。 另外,事实上,PostgreSQL仍然是应用程序之后唯一需要拖拽的状态(如果仍然必须将其转移到另一台服务器上),我们真的想获得一个无状态的应用程序来与Kubernetes和他紧密地进行实验。类似的平台。
我们开始寻找满足以下要求的解决方案:
- 容错能力:当N台服务器出现故障时,群集将继续工作;
- 对于应用程序,所有内容都应保持不变,而无需更改代码;
- 易于部署和管理;
- 与常规PostgreSQL相比,抽象层更少;
- 理想情况下,进行负载平衡,以使并非所有请求都发送到一台服务器;
- 理想情况下,它是用熟悉的语言编写的。
候选人不多:
- 标准流复制(repmgr,Patroni,Stolon);
- 基于触发器的复制(Londiste,Slony);
- 中间层查询复制(pgpool-II);
- 与多个核心服务器(Bucardo)进行同步复制。
在很大的程度上,我们在横梁的建造过程中已经经历了糟糕的经历,因此Patroni和Stolon留下了。 Patroni是用Python编写的,Stolon是Go编写的,我们在两种语言方面都有足够的专业知识。 而且,它们具有相似的体系结构和功能,因此选择是出于主观原因:Patroni由Zalando开发,并且我们曾经尝试与他们的Nakadi项目(用于Kafka的REST API)一起工作,在那里我们遇到了严重缺乏文档的情况。
斯托隆
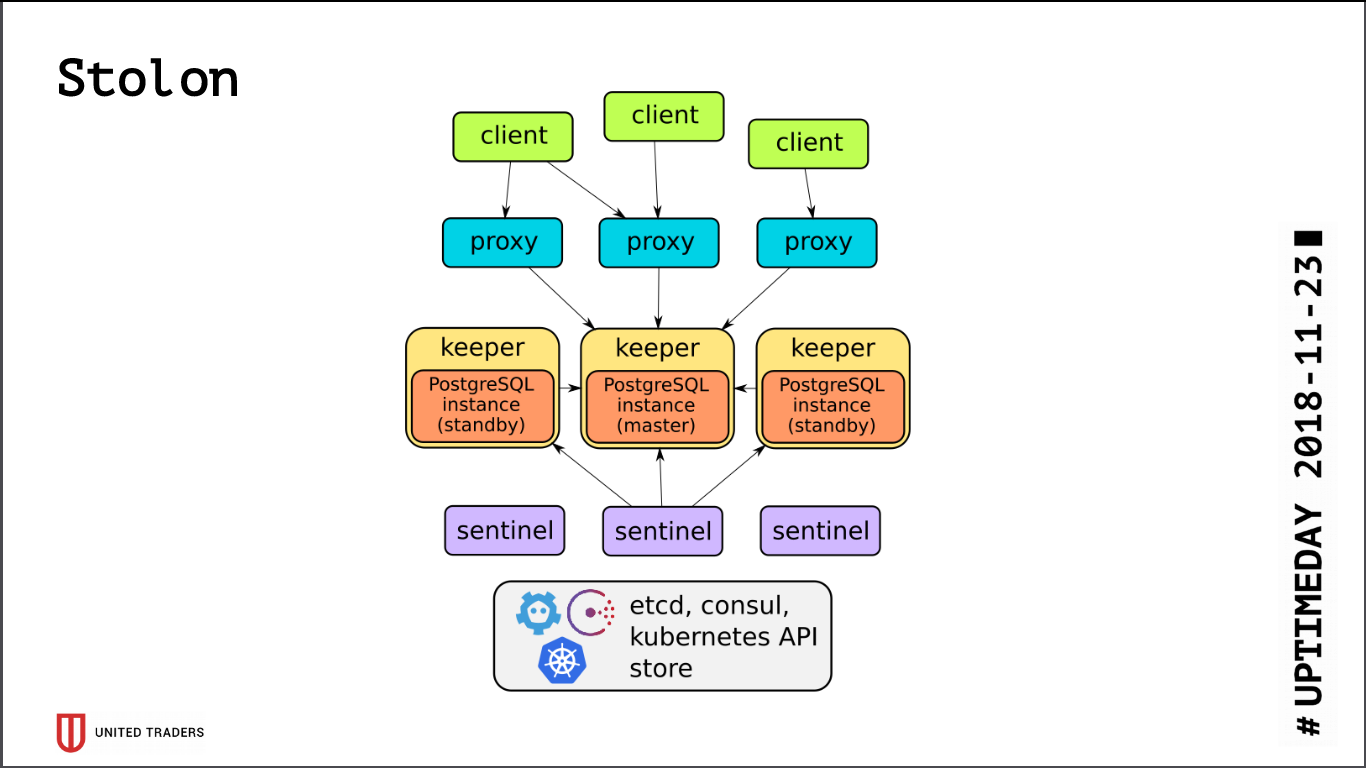
Stolon的体系结构非常简单:有N台服务器,使用etcd / consul选择领导者,以向导模式启动PostgreSQL并将其复制到其他服务器。 然后,stolon代理将转到该PostgreSQL主机,假装是具有普通postgres的应用程序,而客户端将转至这些代理。 如果主人失踪,将进行改选,其他人将成为主人,其余人将成为待命者。 抽象层很少,PostgreSQL照常安装,唯一的警告是PostgreSQL配置存储在etcd中,并且其配置有所不同。
在测试集群时,我们发现了很多问题:
- Stolon不知道如何在ZooKeeper之上工作,只知道领事或etcd。
- etcd对IO非常敏感。 如果将PostgreSQL和etcd保留在同一服务器上,则肯定需要快速的SSD。
- 即使在SSD上,也必须配置etcd超时,否则一切都会在负载下中断-群集会认为主机已断开并不断断开连接;
- 默认情况下,PostgreSQL上的max_connections很小(200),您需要根据需要增加它。
- 一个由三个etcd组成的集群将仅能保留一台服务器,而理想情况下,您需要进行配置,例如5 etcd + 3 Stolon;
- 开箱即用,所有连接都转到主站,从站无法访问该连接。
由于所有与PostgreSQL的连接都进入向导,因此我们再次遇到了繁重的分析请求问题。 etcd有时会对主机上的高负载做出痛苦的反应并进行切换。 切换向导总是会断开连接。 该请求已重新启动,全部重新开始。 为了解决此问题,编写
了一个Python脚本 ,
该脚本请求活动从属的stolonctl地址,并生成HAProxy的配置,将请求重定向到它们。
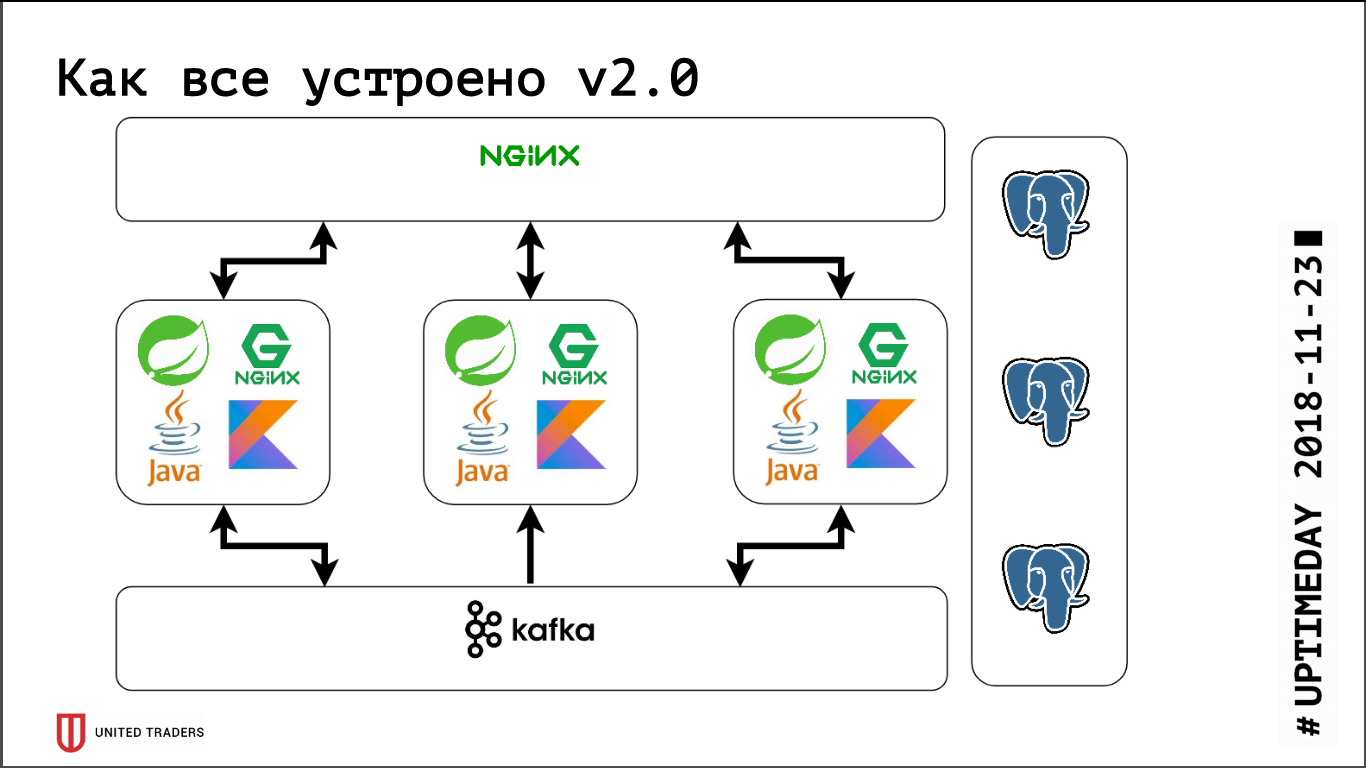
如下图所示:来自应用程序的请求转到stolon-proxy端口,该端口将它们重定向到主服务器,而来自分析程序的请求(它们始终是只读的)进入HAProxy端口,该端口将它们发送给某个从属服务器。
同样,从字面上讲,今天,Stolon采用了PR,它允许将有关Stolon实例的信息发送给第三方服务发现。
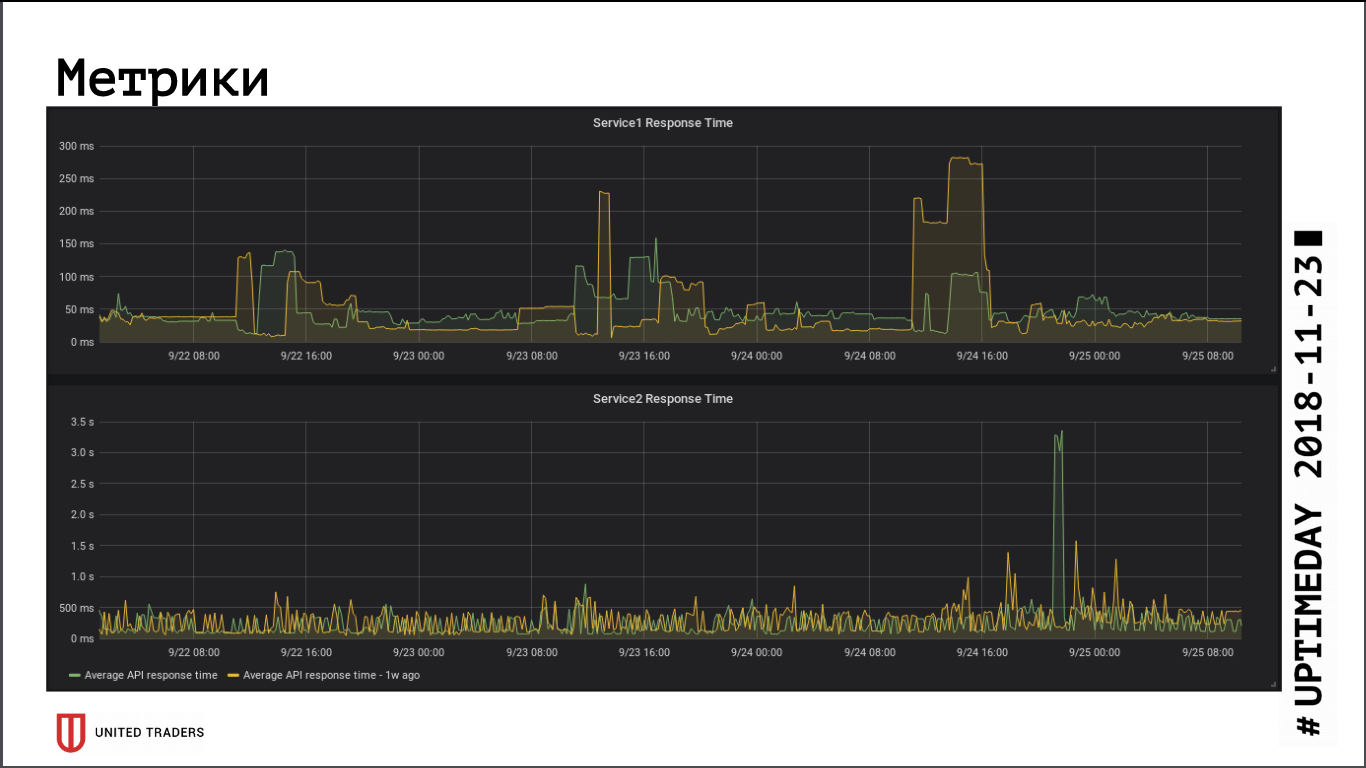
从应用程序响应速度指标来看,向远程集群的过渡对性能没有重大影响,平均响应时间没有变化。 由于数据库现在位于专用服务器上,因此可以弥补由此产生的网络延迟。
当服务器正常运行时,没有问题的Stolon可以在向导崩溃(服务器丢失,网络丢失,磁盘丢失)中生存下来-它会自动重置副本。 Stolon中最薄弱的地方是etcd,其中的故障使群集成为可能。 我们发生了一次典型的事故:一个由三个节点etcd组成的集群,其中两个被削减。 一切都中断了仲裁,etcd进入了不正常状态,Stolon群集不接受任何连接,包括来自stolonctl的请求。 恢复方案:将尚存的服务器上的etcd转换为单节点群集,然后将成员添加回去。 结论:为了在两台服务器死亡的情况下生存,您必须至少有5个实例etcd。
监控和发现错误
随着基础架构的增长和微服务的复杂性,我想收集有关应用程序和Java机器内部正在发生的事情的更多信息。 我们无法使Zabbix适应新环境:在基础架构不断变化的情况下,这非常不便。 我不得不通过它的API磨拐杖,或者用手爬进去,这甚至更糟。 它的数据库很难适应繁重的工作,通常将所有这些信息放到关系数据库中非常不便。
结果,我们选择了Prometheus进行监视。 他为Spring应用程序提供了一个开箱即用的执行器来提供指标,对于Kafka,他们拧紧了JMX Exporter,后者还以舒适的方式提供了指标。 那些未在“盒子里”找到的出口商,我们用Python编写,大约有十个。 我们可视化Grafana,使用Graylog收集日志(因为他现在支持Beats)。
我们使用
Sentry收集错误。 他以结构化形式编写所有内容,绘制图表,显示发生的频率更高,频率更低的事件。 通常,开发人员在部署后会立即前往Sentry,查看是否有高峰,或者迫切需要回滚。 事实证明,可以快速捕获错误,而无需选择日志。
仅此而已,如果文章的格式适合读者,我们将继续讨论我们的基础架构,但仍然有很多乐趣:Kafka和通过它的事件的分析解决方案,用于Windows应用程序的CI / CD频道以及Openshift冒险。