推荐算法,事件预测或风险评估算法是银行,保险公司和许多其他业务部门的趋势解决方案。 例如,这些程序基于数据分析来帮助建议客户何时退还银行贷款,零售的需求是什么,发生保险事件或电信客户流失的可能性等等。 对于企业而言,这是优化他们的费用,提高工作速度并总体上改善服务的宝贵机会。
但是,传统方法(例如分类和回归)不适用于构建此类程序。 以这个问题为例,该案例可预测医疗事件:我们分析数据性质的细微差别以及可能的建模方法,建立模型并分析其质量。
预测医疗事件的挑战
情节的预测是基于对历史数据的分析。 在这种情况下,数据集由两部分组成。 首先是先前提供给患者的服务数据。 数据集的这一部分包括有关患者的社会人口统计学数据,例如年龄和性别,以及在不同时间以ICD10-CM编码[1]和执行的HCPCS程序对患者进行的诊断[2]。 这些数据按时间顺序排列,使您可以在感兴趣的时间了解患者的状况。 对于培训模型以及生产中的工作,个性化数据就足够了。
数据集的第二部分是针对患者发生的发作的列表。 对于每个情节,我们都指出其发生的类型和日期以及时间段,包括服务和其他信息。 根据这些数据,生成用于预测的目标变量。
时间方面对于解决问题很重要:我们只对不久的将来可能发生的事件感兴趣。 另一方面,我们使用的数据集是在有限的时间内收集的,超过该时间没有数据。 因此,我们无法说出发作是否在观察期之外发生,它们是什么发作,在什么确切的时间出现。 这种情况称为权限检查。
同样,也会进行左审查:对于某些患者,发作可能比我们的观察结果更早开始发作。 对我们来说,这看起来像是没有任何背景的情节。
数据审查还有另一种类型-观察中断(如果观察期未完成且事件尚未发生)。 例如,由于患者移动,数据收集系统出现故障等。
在图。 图1示意性地示出了不同类型的数据审查。 所有这些都扭曲了统计数据,使建立模型变得困难。
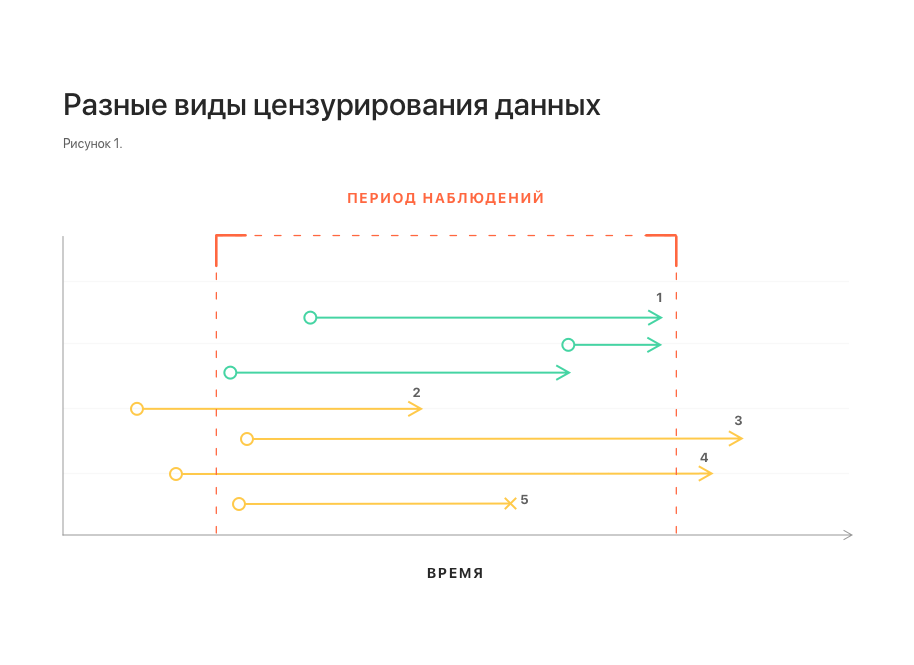 注:1-未经审查的观察; 2、3-分别为左,右审查制度; 4-同时进行左右审查;
注:1-未经审查的观察; 2、3-分别为左,右审查制度; 4-同时进行左右审查;
5-观察中断。数据集的另一个重要特征与现实生活中数据流的性质有关。 一些数据可能会延迟到达,在这种情况下,在预测时它们将不可用。 要考虑此功能,有必要通过从每个序列的尾部抛出几个元素来补充数据集。
分类与回归
自然,首先想到的是将问题简化为众所周知的分类和回归。 但是,这些方法遇到严重的困难。
为什么回归不适合我们,从考虑到的左右审查制度现象可以清楚地看出:事件发生时间在数据集中的分布可以改变。 此外,无法使用数据集本身来确定此偏差的大小和存在的事实。 构建的模型可以通过任何验证方法显示出任意良好的结果,但这很可能与它对生产数据进行预测的适用性无关。
乍一看,更有希望的尝试是将问题简化为分类:设置一定的时间段并确定该时间段内将发生的事件。 这里的主要困难是我们感兴趣的时间间隔的绑定。 仅可以将其可靠地链接到患者历史记录的最新更新时刻。 同时,预测情节的请求与时间完全没有关系,并且可以在任何时间出现,既可以在此期间内(然后缩短感兴趣的有效期),也可以完全在其之外-然后预测通常会失去意义(见图。 2)。 这自然会引起关注期间的增加,但最终无论如何都会降低预测的价值。
 注意:1-更新患者的病史; 2-最新更新及其相关的时间跨度; 3、4-在此期间收到的情节预测请求。 可以看出,它们的有效预测间隔更短。 5-在间隔之外收到请求。 对他来说,预测是不可能的。
注意:1-更新患者的病史; 2-最新更新及其相关的时间跨度; 3、4-在此期间收到的情节预测请求。 可以看出,它们的有效预测间隔更短。 5-在间隔之外收到请求。 对他来说,预测是不可能的。生存分析
作为替代方案,我们可以考虑在俄罗斯文献中将这种方法称为生存分析(survival analysis,或事件发生时间分析)[3]。 这是专门为处理审查数据而设计的一系列模型。 它基于风险函数(风险函数,事件发生的强度)的近似值,该函数估计事件随时间变化的概率分布。 这种方法使您可以正确考虑存在不同类型的审查制度。
对于要解决的问题,此方法还允许将问题的两个方面组合到一个模型中:确定事件的类型并预测事件的发生时间。 为此,为每种类型的情节建立一个单独的模型就足够了,类似于分类中的“一对多”方法。 然后,非目标情节的发生可以解释为从观察到的样本中排除了一个对象而没有发生事件,这是数据审查的另一种类型,并且模型也已正确考虑了该事件。 从业务逻辑的角度来看,这种解释是正确的:如果患者进行了白内障手术,这并不排除将来会发生其他发作。
在用于生存分析的模型系列中,可以区分两种:分析和回归。 分析模型仅是描述性的,它们是针对整个人口构建的,没有考虑其单个成员的特征,因此只能预测某些典型成员的事件发生。 与分析不同,回归模型是在考虑人口个体成员的特征的基础上构建的,并且可以考虑到个体成员的特征对个体成员进行预测。 在此问题中,正是使用了这种变化,或更确切地说,使用了Cox的比例危害模型(以下简称CoxPH)。
生存回归和白内障手术
最简单的方法将类似于常规回归:将事件发生时间的数学期望作为输出。 由于CoxPH在输入端将数据作为数字矢量接收,并且实际上我们的数据集是一系列诊断代码和过程(分类数据),因此需要进行初步的数据转换:
- 使用先前训练的GloVe模型将代码转换为嵌入式表示[4];
- 将患者病史的最后一个阶段中可用的所有代码汇总到一个向量中;
- 一键编码患者的性别和年龄比例。
我们将获得的特征向量用于模型训练及其验证。 结果模型展示了以下一致性指数(c-index或c-statistic)值[5]:
这可与此类模型通常的0.6-0.7水平相比较[6]。
但是,如果查看事件发生的预计预期时间与实际事件之间的平均绝对误差,则该误差为5天。 发生如此大错误的原因是,对c-index的优化只能保证正确的值顺序:如果一个事件应该比另一个事件更早发生,那么预期事件发生时间的预测值将分别比另一个事件小。 而且,没有关于预测值本身的陈述。
该模型的输出值的另一个可能的变体是风险函数在不同时间点的值表。 该选项具有更复杂的结构,比上一个更难以解释,但同时它提供了更多信息。
更改输出格式需要使用不同的方法来评估模型的质量:我们需要确保对于阳性样本(发生事件时),其风险水平要高于阴性样本(当发生事件时)的风险水平。 为此,对于延迟样本中风险函数的每个预测分布,我们将从值表移至一个值-最大值。 计算了正例和负例的中位数后,我们将看到它们确实可靠地不同:分别为0.13和0.04。
接下来,我们使用这些值来构建ROC曲线并计算其下的面积-ROC AUC为0.92,这对于要解决的问题是可以接受的。
结论
因此,我们认为生存分析是考虑到问题的所有细微差别和可用数据,是解决预测医学事件的最佳方法。 但是,其应用意味着模型输出数据的格式不同,并且评估质量的方法也不同。
将CoxPH模型用于预测白内障手术的发作,使我们能够获得可接受的模型质量指标。 可以将类似的方法应用于其他类型的情节,但是只能在建模过程中直接评估模型的特定质量指标。
文学作品
[1] ICD-10临床修改
en.wikipedia.org/wiki/ICD-10_Clinical_Modification[2]医疗保健通用程序编码系统
en.wikipedia.org/wiki/Healthcare_Common_Procedure_Coding_System[3]生存分析
en.wikipedia.org/wiki/Survival_analysis[4] GloVe:单词表示的全局向量
nlp.stanford.edu/projects/glove[5] C-Statistic:定义,示例,权重和意义
www.statisticshowto.datasciencecentral.com/c-statistic[6] VC Raykar等。 关于生存分析的排名:一致性索引上的
限制papers.nips.cc/paper/3375-on-ranking-in-survival-analysis-bounds-on-the-concordance-index.pdf