我是
Fabien Sanglard所做的一切的
忠实拥护者 ,我喜欢他的博客,并且阅读
了他的两
本书封面(在最近的
Hansleminutes播客中对此进行了介绍)。
Fabien最近写了一篇很棒的文章,他
解密了一个微型射线追踪器,对代码进行了模糊处理,并以奇妙的方式很好地解释了数学。 我真的建议您花时间阅读本文!
但这使我怀疑
是否可以将C ++代码移植到C# ? 由于最近我在
主要工作中写了很多C ++,所以我认为我可以尝试。
但更重要的是,我想更好地了解
C#是否为低级语言 ?
一个稍有不同但相关的问题:C#适合“系统编程”多少? 关于这个主题,我真的推荐
Joe Duffy从2013年开始的出色文章 。
线路端口
我首先简单地将经过
混淆的C ++代码逐行移植到C#。 这非常简单:似乎仍然在说C#是C ++++!
该示例显示了主要数据结构-'vector',这是一个比较,左侧为C ++,右侧为C#:

因此,在语法上有一些区别,但是由于.NET允许您定义
自己的值类型 ,因此我能够获得相同的功能。 这很重要,因为将“向量”视为一种结构意味着我们可以获得更好的“数据局部性”,并且我们不需要涉及.NET垃圾收集器,因为数据将被压入堆栈(是的,我知道这是一个实现细节)。
有关.NET中的
structs或“值类型”的更多信息,请参见此处:
特别是,在埃里克·利珀特(Eric Lippert)的上一篇文章中,我们找到了这样一个有用的报价,它使“值类型”的真正含义清楚:
当然,关于值的类型的最重要的事实不是实现细节, 如何分配它们 ,而是“值的类型”的原始语义 , 即,它总是“按值”复制 。 如果分配信息很重要,我们将其称为“堆类型”和“堆栈类型”。 但在大多数情况下,这并不重要。 大多数时候,复制和标识的语义是相关的。
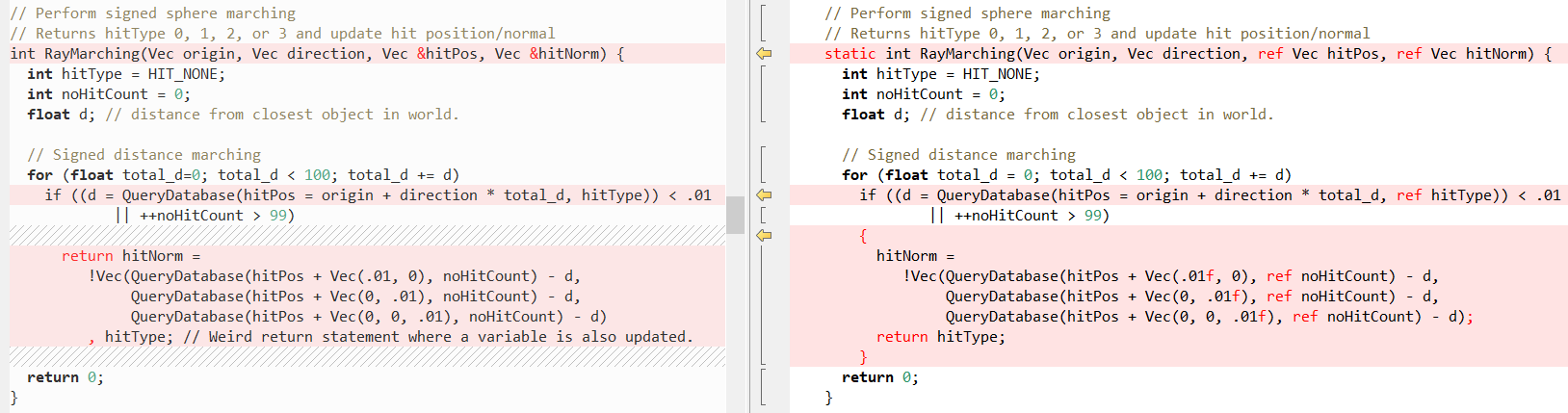
现在,让我们看一下比较中的其他一些方法(再次是C ++,左边是C#),首先是
RayTracing(..) :
然后
QueryDatabase (..) :
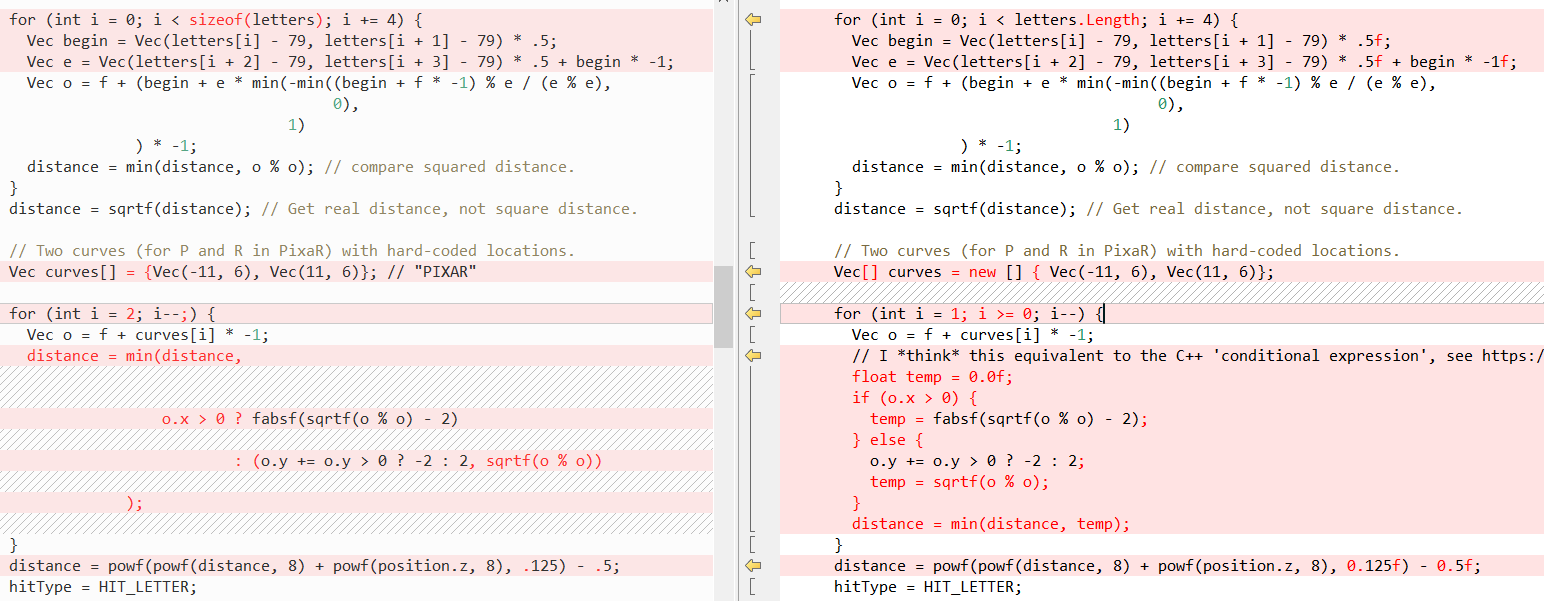
(有关这两个功能的解释,请参见
Fabian的帖子 )
但是,事实再次是,C#使编写C ++代码变得非常容易! 在这种情况下,
ref关键字对我们的帮助最大,这使我们可以通过
reference传递
值 。 我们已经在方法调用中使用
ref了很长一段时间,但是最近,我们努力在其他地方解析
ref :
现在
有时使用
ref可以提高性能,因为不需要复制该结构,有关更多信息,请参见
Adam Stinix在
帖子中的基准测试和
“ Performance traps ref locals and ref return in C#” 。
但是最重要的是,这样的脚本为我们的C#端口提供了与C ++源代码相同的行为。 尽管我想指出的是,所谓的“托管链接”与“指针”并不完全相同,特别是,您无法对其进行算术运算,请参见此处:
性能表现
因此,代码移植得很好,但是性能也很重要。 特别是在光线跟踪器中,它可以计算几分钟的帧。 C ++代码包含变量
sampleCount ,它控制最终的图像质量,其中
sampleCount = 2如下:

显然不是很现实!
但是,当您达到
sampleCount = 2048 ,一切看起来
会好得多:

但是从
sampleCount = 2048开始
非常耗时,因此所有其他运行都以
2值执行,至少需要一分钟。 更改
sampleCount仅影响最外层代码循环的迭代次数,有关说明,请参见此
要点 。
“天真”线路端口后的结果
为了实质性地比较C ++和C#,我使用了
time-windows工具,这是
time unix命令的端口。 初始结果如下所示:
| C ++(VS 2017) | .NET Framework(4.7.2) | .NET Core(2.2) |
|---|
| 时间(秒) | 47.40 | 80.14 | 78.02 |
| 核心(秒) | 0.14(0.3%) | 0.72(0.9%) | 0.63(0.8%) |
| 在用户空间(秒) | 43.86(92.5%) | 73.06(91.2%) | 70.66(90.6%) |
| 页面错误错误数 | 1143 | 4818 | 5945 |
| 工作集(KB) | 4232 | 13624 | 17052 |
| 扩展内存(KB) | 95 | 172 | 154 |
| 非抢先内存 | 7 | 14 | 16 |
| 交换文件(KB) | 1460 | 10936 | 11024 |
最初,我们看到C#代码比C ++版本稍慢一些,但是越来越好(见下文)。
但是,让我们首先看看.NET JIT甚至通过这个“天真”的逐行端口对我们的作用。 首先,它很好地嵌入了较小的辅助方法。 这可以在出色的
Inlining分析器工具的输出中看到(绿色=内置):
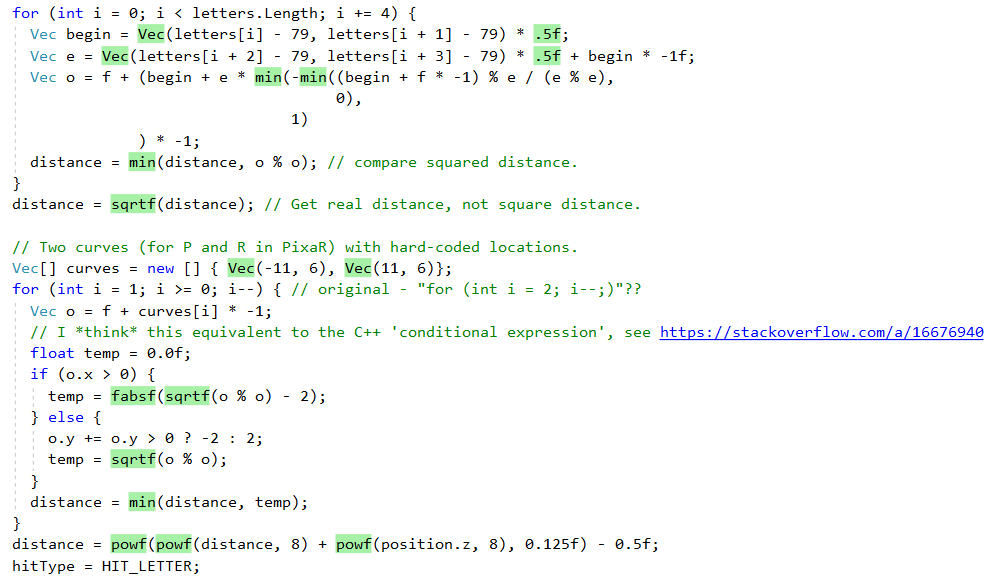
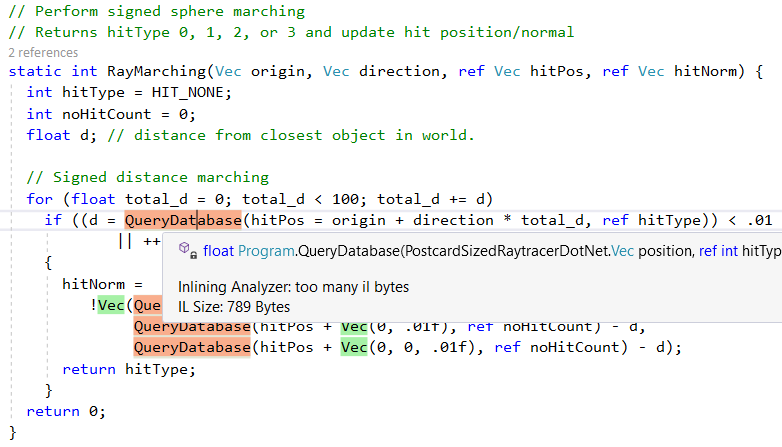
但是,它不会嵌入所有方法,例如,由于复杂性,
QueryDatabase(..)跳过
QueryDatabase(..) :
.NET即时(JIT)编译器的另一个功能是将特定的方法调用转换为相应的CPU指令。 我们可以在
sqrt shell函数中看到这一点,这里是C#源代码(请注意对
Math.Sqrt的调用):
这是.NET JIT生成的汇编代码:没有对
Math.Sqrt调用,而使用了处理器指令
vsqrtsd :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(要获取此问题,请遵循
以下说明 ,使用
“ Disasmo” VS2019附加组件或查看
SharpLab.io )
这些替换也称为
内在函数 ,在下面的代码中,我们可以看到JIT如何生成它们。 该代码段仅显示了
AMD64的映射,但是JIT还针对
X86 ,
ARM和
ARM64 (
此处的完整方法)。
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
如您所见,实现了一些方法,例如
Sqrt和
Abs ,而其他方法则使用C ++运行时函数,例如
powf 。
“如何在.NET Framework中实现Math.Pow()?”一文中对整个过程进行了很好的解释。 ,也可以在CoreCLR源代码中看到:
简单的性能改进后的结果
我想知道您是否可以立即改进朴素的逐端口端口。 经过一些分析后,我进行了两项重大更改:
- 删除内联数组初始化
- 用
Math.XXX(..)的类似物代替Math.XXX(..)的功能
这些更改将在下面更详细地说明。
删除内联数组初始化
有关为什么需
要这样做的更多信息,请参见
Andrei Akinshin提供的 出色的Stack Overflow答案以及基准和汇编代码。 他得出以下结论:
结论
- .NET是否缓存硬编码的本地数组? 就像将Roslyn编译器放入元数据的代码一样。
- 在这种情况下,会有开销吗? 不幸的是,是的:对于每次调用,JIT都会从元数据中复制数组的内容,与静态数组相比,这会花费额外的时间。 运行时还选择对象并在内存中创建流量。
- 有什么需要担心的吗? 可能吧 如果这是一个热门方法,并且您想要实现良好的性能水平,则需要使用静态数组。 如果这是不影响应用程序性能的冷方法,则可能需要编写“良好”源代码并将该数组放置在方法区域中。
您可以看到在
此diff中所做的更改。
使用MathF函数代替数学
其次,也是最重要的是,通过进行以下更改,我显着提高了性能:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
从.NET Standard 2.1开始,存在
float通用数学函数的具体实现。 它们位于
System.MathF类中。 有关此API及其实现的更多信息,请参见此处:
经过这些更改后,C#和C ++代码性能的差异减少到大约10%:
| C ++(VS C ++ 2017) | .NET Framework(4.7.2) | .NET Core(2.2)TC关闭 | .NET Core(2.2)TC开 |
|---|
| 时间(秒) | 41.38 | 58.89 | 46.04 | 44.33 |
| 核心(秒) | 0.05(0.1%) | 0.06(0.1%) | 0.14(0.3%) | 0.13(0.3%) |
| 在用户空间(秒) | 41.19(99.5%) | 58.34(99.1%) | 44.72(97.1%) | 44.03(99.3%) |
| 页面错误错误数 | 1119 | 4749 | 5776 | 5661 |
| 工作集(KB) | 4136 | 13,440 | 16,788 | 16,652 |
| 扩展内存(KB) | 89 | 172 | 150 | 150 |
| 非抢先内存 | 7 | 13 | 16 | 16 |
| 交换文件(KB) | 1428 | 10 904 | 10960 | 11044 |
TC多级编译,
分层编译 (
我想默认它将在.NET Core 3.0中启用)
为了完整起见,以下是几次运行的结果:
| 跑 | C ++(VS C ++ 2017) | .NET Framework(4.7.2) | .NET Core(2.2)TC关闭 | .NET Core(2.2)TC开 |
|---|
| TestRun-01 | 41.38 | 58.89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57.65 | 46.23 | 45.96 |
| TestRun-03 | 42.17 | 62.64 | 46.22 | 48.73 |
注意 :.NET Core和.NET Framework之间的差异是由于.NET Framework 4.7.2中缺少MathF API,有关更多信息,请参阅
支持票证.Net Framework(4.8?)对于netstandard 2.1 。
进一步提高生产力
我确信代码仍可以改进!
如果您有兴趣解决性能差异,那么
这里是C#代码 。 为了进行比较,您可以从出色的
Compiler Explorer服务中观看C ++汇编程序代码。
最后,如果有帮助,这是带有“热路径”显示的Visual Studio探查器输出(在上述性能改进之后):
C#是低级语言吗?
或更具体地说:
C#/ F#/ VB.NET或BCL /运行时功能的哪些语言功能意味着“低级” *编程?
*是的,我知道“低级”是一个主观术语。
注意:每个C#开发人员都有自己的“低级”概念,这些功能将被C ++或Rust程序员视为理所当然。
这是我列出的清单:
- ref返回和ref当地人
- “通过引用返回并避免复制大型结构。 安全的类型和内存甚至比不安全的还快 !”
- .NET中不安全的代码
- “在前几章中定义的核心C#语言与C和C ++有很大不同,因为它缺少指针作为数据类型。 相反,C#提供了链接,并提供了创建由垃圾收集器控制的对象的功能。 这种设计与其他功能的结合,使C#语言比C或C ++安全得多。”
- .NET中的托管指针
- “ CLR中还有另一种类型的指针-托管指针。 可以将其定义为一种更通用的链接类型,它可以指向其他位置,而不仅仅是指向对象的开头。”
- C#7系列,第10部分:跨度<T>和通用内存管理
- “ System.Span <T>只是包装所有内存访问模式的堆栈类型(
ref struct );它是用于通用连续内存访问的类型。 我们可以想象一个Span实现,它具有一个虚拟引用,并且其长度可以接受所有三种类型的内存访问。”
- 兼容性(“ C#编程指南”)
- “ .NET Framework通过平台调用服务,
System.Runtime.InteropServices ,C ++兼容性和COM(COM互操作性)兼容性,提供了与非托管代码的互操作性。”
我还在Twitter上大喊一声,并获得了更多加入列表的选项:
- Ben Adams :“用于平台的内置工具(CPU指令)”
- 马克·格雷韦尔 ( Mark Gravell) :“通过Vector进行SIMD(与Span配合得很好)*很低*; .NET Core应该(很快吗?)提供直接的CPU嵌入式工具,以便更明确地使用特定的CPU指令”
- Mark Gravell :“强大的JIT:诸如数组/间隔上的范围省略之类的东西,以及使用按结构T的规则删除JIT知道的大段代码,以确保它们不适用于该T或您的特定对象CPU(BitConverter.IsLittleEndian,Vector.IsHardwareAccelerated等)“
- 凯文·琼斯 :“我特别要提到
MemoryMarshal和Unsafe类,以及System.Runtime.CompilerServices中的其他一些东西,”
- Theodoros Chatsigiannakis :“您还可以包括
__makeref和其余的内容”
- Damageboy :“能够动态生成与预期输入完全匹配的代码的功能,假设后者只能在运行时知道并且可能会定期更改?”
- 罗伯特·哈肯(Robert Hacken) :“ IL的动态排放”
- Victor Baybekov :“未提及Stackalloc。 也可以编写纯IL(不是动态的,因此将其保存在函数调用中),例如,使用缓存的
ldftn并通过calli对其进行调用。 VS2017中有一个proj模板,可通过重写方法extern + MethodImplOptions.ForwardRef + ilasm.ex来简化此工作»
- Victor Baybekov :“ MethodImplOptions.AggressiveInlining也“激活了低级编程”,因为它允许您使用许多小的方法编写高级代码,并且仍然控制JIT的行为以获得最佳结果。 否则,将复制粘贴数百种LOC方法...”
- Ben Adams :“使用与基本平台相同的调用约定(ABI),并且p /调用进行交互吗?”
- Victor Baibekov :“此外,由于您提到了#fsharp-它具有一个
inline ,该inline在IL级别直到JIT都有效,因此在语言级别上被认为很重要。 C#到目前为止,对于lambda来说,这还远远不够,因为lambda始终是虚拟调用,解决方法通常很奇怪(有限的泛型)”
- Alexandre Mutel :“新的嵌入式SIMD,对Unsafe Utility类/ IL(例如,自定义,Fody等)进行后处理。 对于C#8.0,即将发布的函数指针...
- Alexandre Mutel :“例如,关于IL,F#直接支持某种语言的IL”
- OmariO :“ BinaryPrimitives 。 级别低,但很安全”
- 松井晃司 :“您自己的内置汇编程序怎么样? 这对工具包和运行时都非常困难,但是它可以替代当前的p / invoke解决方案并实现嵌入式代码(如果有的话)
- 弗兰克·A·克鲁格(Frank A. Kruger) :“ Ldobj,stobj,initobj,initblk,cpyblk”
- 康拉德·椰子(Conrad Coconut) :“也许可以流式传输本地存储? 固定大小的缓冲区? 您可能应该提到非托管约束和可绑定类型:)”
- Sebastiano Mandala :“只说了几句话:简单的事情(例如安排结构)以及填充和对齐内存以及字段顺序如何影响缓存性能? 这是我自己必须探索的东西。”
- Nino Floris :“通过readspanspan,stackalloc,finalizers,WeakReference,开放委托,MethodImplOptions,MemoryBarriers,TypedReference,varargs,SIMD,Unsafe.AsRef嵌入的常量可以完全根据布局(用于TaskAwaiter及其版本)设置结构的类型”
因此,最后,我要说的是,C#当然允许您编写类似于C ++的代码,并且结合运行时库和基类库提供了许多底层函数。进一步阅读
Unity Burst编译器: