前言
世界上有一个如此简单且非常有用的实用程序
-BDelta ,它恰好在我们的生产过程中扎根了很长时间(尽管无法安装其版本,但肯定不是最后一个可用的版本)。 我们将其用于预期目的-二进制补丁的构建。 如果您查看存储库中的内容,它会变得有点可悲:实际上,它很久以前就被废弃了,很多东西在那儿已经过时了(我的前同事曾经在那里做了几次更正,但那是很久以前了)。 总的来说,我决定恢复这项业务:我分叉了,扔掉了我不打算使用的东西,在
cmake上超过了项目,内联了“热门”微功能,从堆栈中删除了大数组(以及坦率地说是“炸弹”的可变长度数组)。 ,再次驱动探查器-发现大约40%的时间都花在了
fwrite上 ...
那么fwrite怎么了?
在此代码中,fwrite(在我的特定测试用例中:在接近300 MB的文件之间构建补丁,输入数据完全在内存中)用一个小缓冲区调用了数百万次。 显然,这件事会放慢脚步,因此我想以某种方式影响这种耻辱。 不想实现任何类型的数据源,异步输入输出,我想找到一个更简单的解决方案。 首先想到的是增加缓冲区的大小
setvbuf(file, nullptr, _IOFBF, 64* 1024)
但是我的结果没有得到明显的改善(现在fwrite占了大约37%的时间)-这意味着问题仍然不在频繁将数据记录到磁盘上。 看起来是“内幕”,您可以看到锁/解锁文件结构像这样发生在内部(伪代码,所有分析都在Visual Studio 2017下完成):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); } return retval; }
根据探查器,_fwrite_nolock仅占6%的时间,其余为开销。 在我的特定情况下,线程安全性显然是多余的,我会通过用
_fwrite_nolock替换fwrite调用来牺牲它,即使使用我不需要
聪明的参数也是如此。 总计:这种简单的操作有时会减少记录结果的成本,而在原始版本中,这几乎是时间成本的一半。 顺便说一下,在POSIX世界中,有一个类似的功能
-fwrite_unlocked 。 一般来说,恐惧也是一样。 因此,在#define对的帮助下,如果不需要不必要的锁(这种情况经常发生),您可以得到一个跨平台的解决方案,而无需不必要的锁。
fwrite,_fwrite_nolock,setvbuf
让我们从原始项目中抽象出来,并开始测试一个特定的案例:以极小的部分(1个字节)记录一个大文件(512 MB)。 测试系统:AMD Ryzen 7 1700、16 GB RAM,3.5“ HDD 3.5”,7200 rpm 64 MB高速缓存,Windows 10 1809,binar内置32位,包含优化功能,库是静态链接的。
实验样本:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
变量将为TEST_BUFFER_SIZE,在某些情况下,我们将fwrite_unlocked替换为fwrite。 让我们从fwrite的情况开始,而无需显式设置缓冲区大小(注释setvbuf和相关代码):时间27048906μs,写入速度-18.93 Mb / s。 现在将缓冲区大小设置为64 Kb:时间-25037111μs,速度-20.44 Mb / s。 现在我们无需调用setvbuf就测试_fwrite_nolock的操作:7262221 ms,速度为70.5 Mb / s!
接下来,尝试使用缓冲区(setvbuf)的大小:
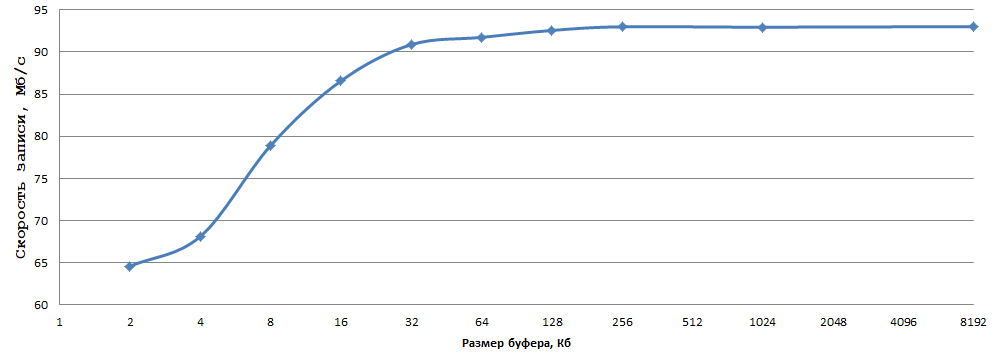
数据是通过平均5个实验获得的;我懒得考虑这些错误。 对于我来说,将1个字节写入常规HDD时的93 MB / s是一个很好的结果,只需选择最佳的缓冲区大小(在我的情况下为256 KB-恰好),然后将fwrite替换为_fwrite_nolock / fwrite_unlocked(在当然,如果不需要线程安全)。
与类似条件下的恐惧感相似。 现在让我们看看Linux上的情况如何,测试配置如下:AMD Ryzen 7 1700X,16 GB RAM,HDD 3.5“ 7200 rpm 64 MB缓存,OpenSUSE 15 OS,GCC 8.3.1,我们将测试x86-64二进制文件系统ext4测试部分在此测试中未明确设置缓冲区大小的fwrite结果为67.6 Mb / s,将缓冲区设置为256 Kb时速度提高至69.7 Mb / s。现在我们将对fwrite_unlocked进行类似的测量-结果分别为93.5 Mb / s和94.6 Mb / s。将缓冲区大小从1 KB更改为8 MB可以得出以下结论:增加缓冲区可以提高写入速度, 但是我的情况只有3 Mb / s的差异,我根本没有注意到64 Kb和8 Mb缓冲区之间的速度差异,从这台Linux机器上收到的数据中,我们可以得出以下结论:
- fwrite_unlocked比fwrite快,但是写入速度的差异不如Windows上的大。
- 通过fwrite / fwrite_unlocked,Linux上的缓冲区大小对写入速度的影响不如Windows上大。
总体而言,所提出的方法在Windows上和Linux上均有效(尽管程度要小得多)。
后记
本文的目的是描述在许多情况下的一种简单有效的技术(我之前并没有遇到过_fwrite_nolock / fwrite_unlocked函数,它们不是很流行-徒然)。 我不假装不是新手,但希望本文对社区有用。