Yandex.Zen服务最重要的是开发和维护一个将读者与作者联系起来的平台。 要成为对优秀作者有吸引力的平台,Zen必须能够找到有关任何主题(包括最狭窄主题)的频道的相关受众。 作者幸福小组的负责人Boris Sharchilev谈到了自动中心排名,该排名为作者选择了最相关的用户。 从报告中,您可以发现这种方法与相关项目的选择有何不同-在推荐系统中更受欢迎。
通过平衡以用户为中心的排名和以自动为中心的排名,我们可以实现用户幸福感和作者幸福感之间的适当平衡。
-同事们,大家好。 我叫Borya。 我处理Zen中的排名质量。 我确信这是最有趣的Yandex服务之一,我们的机器学习非常酷,在接下来的17分钟内,我将尝试使您相信这一点。
什么是禅宗? 如果很简单,Zen就是个人推荐服务。 我们会根据我们对这些用户的兴趣所知向他们推荐相关的内容。 我们的高级目标是让用户花时间在Zen上。 非常重要的是他们这次不要后悔。
我们内容消费的基本形式如下所示。 这是无休止的建议。 显然,我们在原则上正在尝试就非常不同的主题推荐非常材料。 有不同的主题:关于业务,关于幽默,甚至关于幻想的一些话题。 也就是说,在录像带中,您既可以找到教育文章,也可以找到更具娱乐性的文章。 而且,当然是个性化。 每个人的Zen提要看起来都不同-取决于用户的兴趣。 另外,当然还有一些广告。

非常重要的一点。 在最初出现之初,实际上我们是Internet内容的聚合者。 也就是说,我们走访了现有站点,从中获取了内容,并根据兴趣向用户展示了这些内容。 现在情况有所不同。 现在,Zen是一个完整的博客平台,每个人都可以在此平台上创建自己的频道,无论是著名的博客作者还是有话要说的新手作者。 新作者看到了一个非常不错的欢迎屏幕,我们在其中讨论服务-Zen自己将选择一个观众,而他只需要编写优质的材料。
现在,该平台占Zen总流量的一半以上。 而且这个数字只会增长。 我们了解每个人都可以对现有内容进行排名。 当然,我们将尽一切努力。 但是,并非每个人都有独特的内容,我们相信这将是我们的竞争优势。

重要的是要了解Zen已经很大。 根据Yandex.Radar的数据,到去年年底,我们每天的读者约为10-12百万,每天的读者约为3500万,甚至根据Yandex.Radar的一些数据,我们去年他们第一次绕过Yandex.News观众。 这意味着我们正在认真对待互联网,我们有非常艰巨的任务,其中有很多任务,我们非常期待您的帮助。
让我们讨论一下它如何工作的细节,并讨论我们可以用实习生做什么,如何帮助我们的服务。
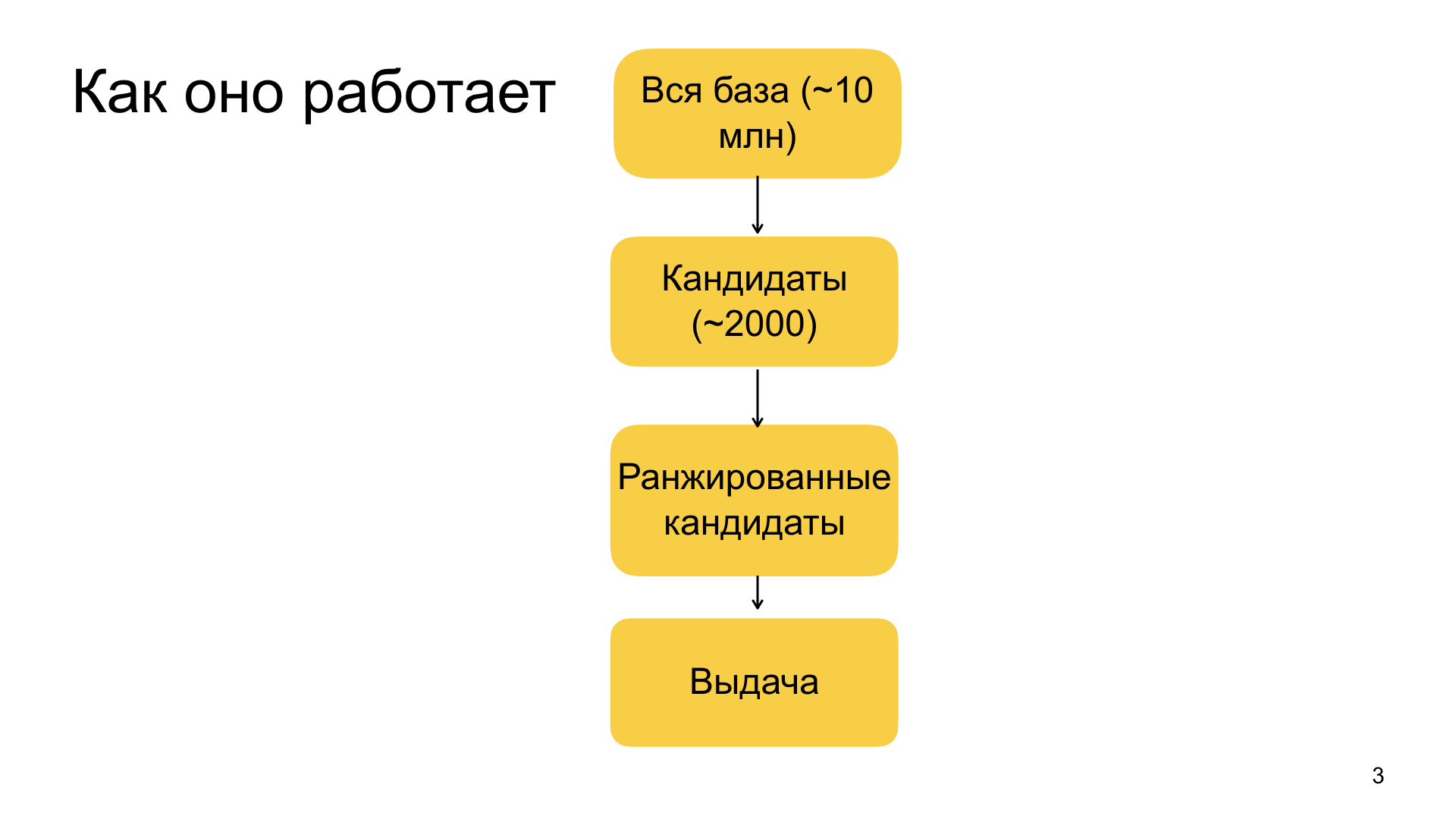
我们提出的建议的总体大纲是这样安排的。 这一切都始于我们庞大的文档数据库,我们从中选择建议材料。 它包含数千万个文档。 此外,该数据库不断得到补充-每天大约有100万个新文档到达。 理想情况下,我们希望将我们的整个机器学习机应用于每个用户的数千万个文档,并为他选择最相关的文档。 但是,不幸的是,这在实践中不可行,因为Zen是一种实时工作的服务。 我们对准备响应的速度有非常严格的保证,因此,出于实际原因,我们被迫在第一阶段将数千万个文档的基础缩小到成千上万个潜在建议,我们已经可以完全根据我们的模型进行排名并选择最相关的建议。 将基数从几千万缩小到几千的阶段称为候选人选择或简易排名。
当我们有了这个工具包时,我们将其应用于复杂的大型机器学习模型,该模型在顶层是梯度增强。 这一切都不足为奇,但是我们有非常多种多样的因素-从一些简单的因素来表征,例如,该域与用户,来源,来源,访问频率,点击,留下反馈,喜欢和不喜欢的相关性。 基于神经网络功能的更复杂因素也是如此。 我们处理文章的文字,处理图片,其他数据源,并且我们也使用这种复合功能。 所有这些方案都非常复杂,我将没有时间详细地告诉您。
在对2000名候选人进行排名之后,我们从他们中选出了最高的候选人。 顶部的大小取决于我们需要推荐多少材料。 它的定义总是不同的。 因此,我们形成了最后的问题。
这就是电路的高电平外观。 现在让我们谈谈我们有兴趣改进整个过程中的哪些组件。

事实证明,我们对几乎所有事情都感兴趣。 有很多任务。 我们希望提高排名的数据传递速度:我们拥有的数据越新,我们提出的建议就越相关。 我想加快服务速度:我们的工作越快,用户体验就越好。 我们希望增加服务的可靠性。
对我们来说,提高排名很重要。 也就是说,我们需要应用新的机器学习模型,并在其他国家/地区改进当前模型。 我们不仅在俄罗斯,而且在世界许多其他国家都推荐我们。
我们还希望考虑到地区性,并向人们推荐与他们所在地区相关的内容。
这非常重要-我们需要开发我们的创作平台。 这是我们的未来,我们需要对其进行投资。 还有很多任务。 特别是,我们需要能够找到并启动高质量的内容。 对我们来说,展示好材料而不是垃圾很重要。 我们需要能够对新的内容格式进行排名。 我们不仅提供文章,还提供短片和用户直接在Feed中观看的帖子。 所有这些格式都必须能够进行排名。
还有一个非常重要的观点,我想在更多的技术细节中更详细地讨论-对于我们而言,重要的是,每个作者都能找到与他相关的受众,即使涉及到非常利基的作者和话题。 让我们更详细地讨论这里存在的问题以及如何解决。
让我们来看一个例子。
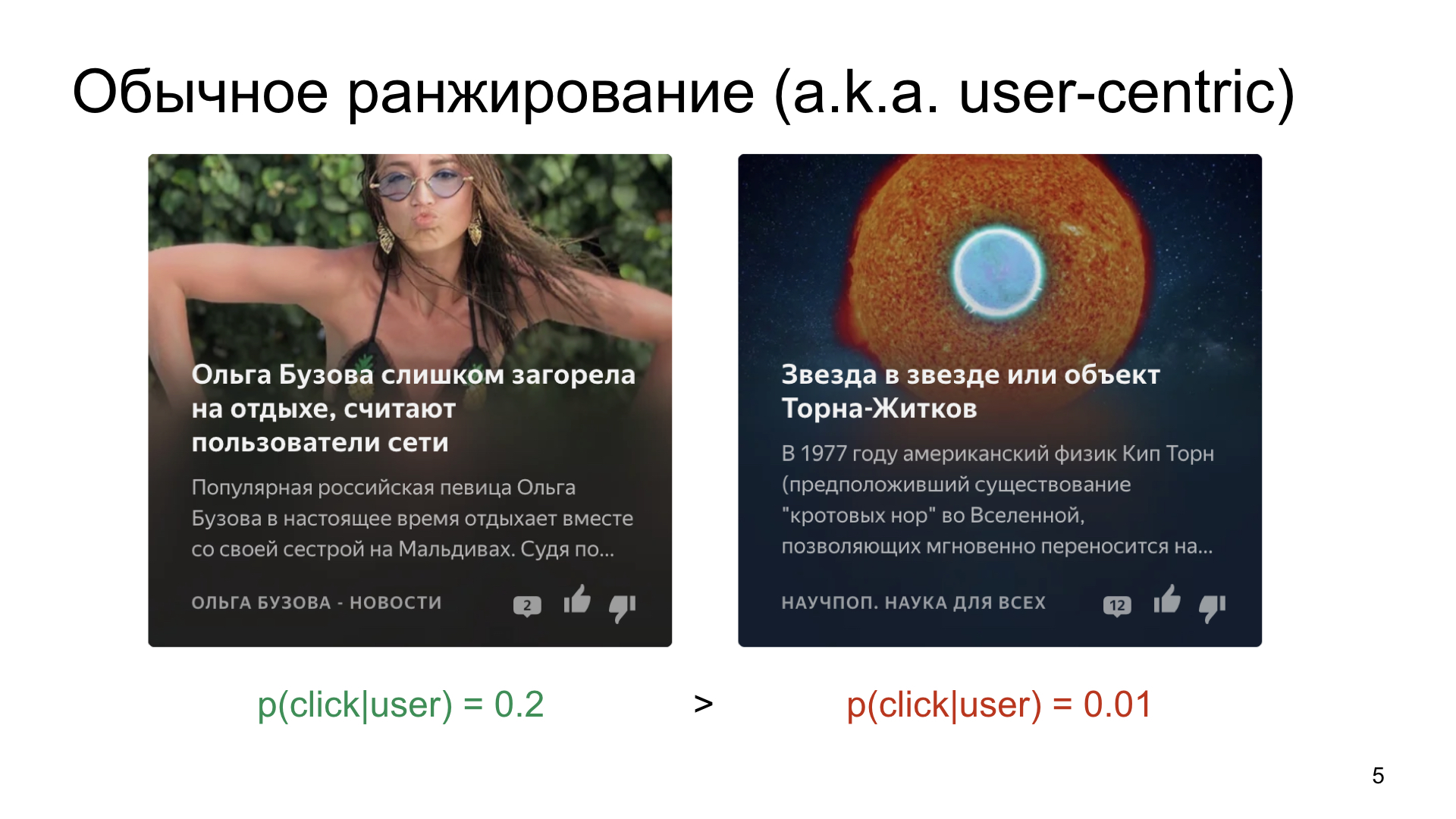
假设我们从两张要显示给用户的卡片中进行选择。
这就是世界的运作方式和人们的工作方式,这是平均水平,点击的可能性平均为20%,还有一些更利基的东西,例如有关科学或太空的文章。
如果我们只是简单地根据点击的可能性对卡片进行排名,那么,当然,更多可点击和更简单的内容将获得大量的印象,即使是一篇关于科学的很好的文章也不会。 当然,我们不要这样。 我们甚至希望找到利基渠道的感兴趣的受众。

为什么要这样做? 实际上,有两个原因。 首先是杂货店。 也就是说,我们希望Zen成为某种互联网的割据。 因此,用户可以在Zen上找到在大型Internet上可以找到的所有内容以及他感兴趣的内容。 这样他就能收到他感兴趣的东西。
科学频道有自己的受众。 但是有一个细微的差别。 如果科学爱好者展示了科学和受欢迎的内容,那么他们更可能点击它而不是点击科学。 但是,如果您只向他们展示科学,他们也会点击科学,他们甚至不会后悔。 问题是如何找到这样的人以及如何显示内容,而不是关注用户,而是关注作者。

怎么做? 通常的排名公式可预测点击的可能性,但在这里对我们无济于事,因为平均而言,更多利基文章会流失。 但是,您可以采用另一种方法-分配一些配额,并在其中分配给作者一些印象,或多或少地平均分配印象,为他们提供最小的保证。 可以做到这一点,这会使作者更加快乐,但是,不幸的是,这会使我们的用户不满意。 用户点击的次数会减少,烦恼会更多,然后离开。 当然,我们不要这个。
怎么会在这里?
我们考虑了很长时间,并提出了一个新概念。 我们称其为作者的自动中心排名或印象。
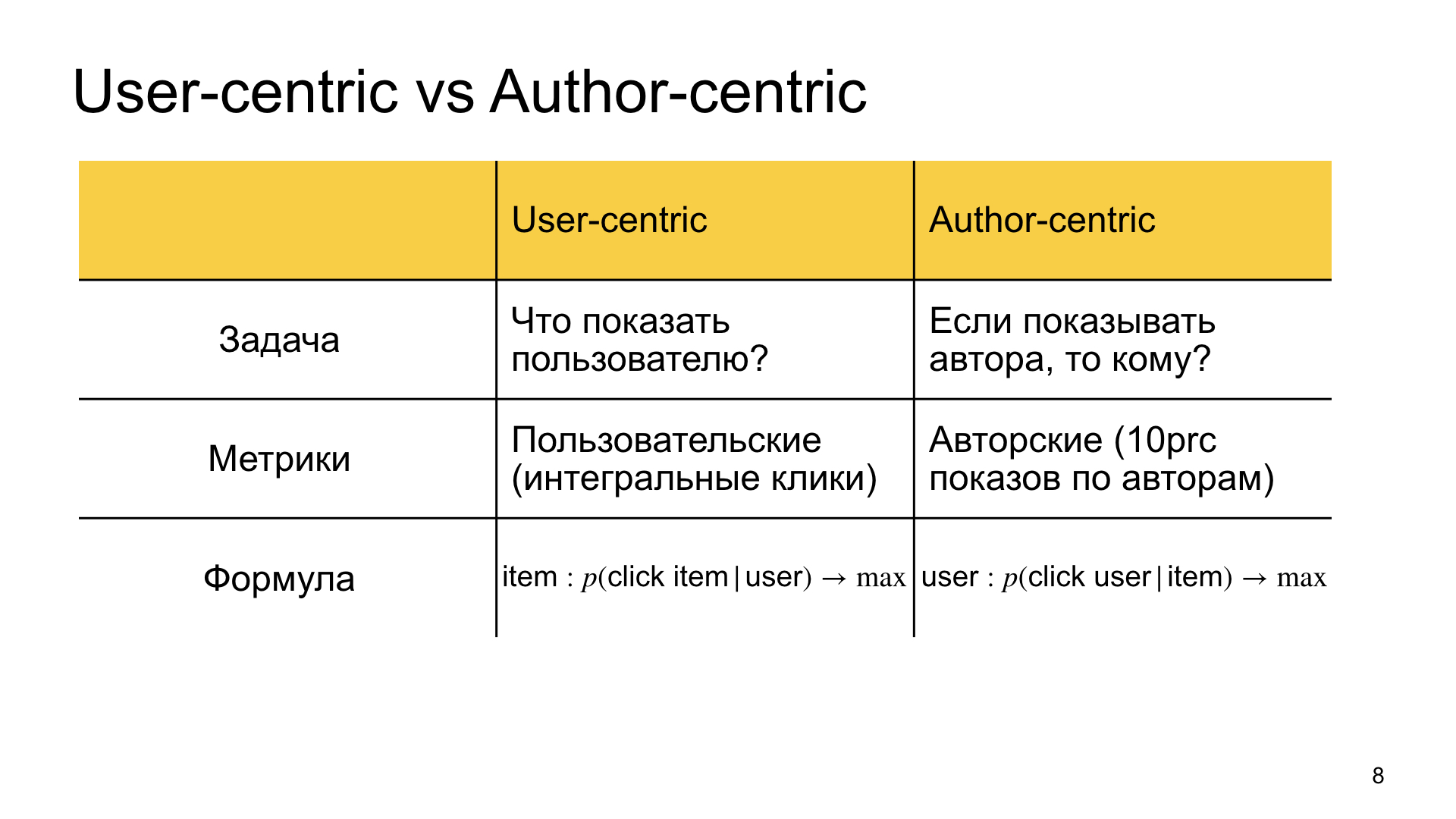
我们将定期排名称为“以用户为中心”的目标是什么? 查找与用户最相关的材料。 我们回答向用户显示什么的问题。
在自动中心排名中,我们有点推翻问题陈述,说我们想向这位作者展示,而问题是向谁展示他,与谁最相关。 因此,度量标准有所不同。 在第一种情况下,我们对自定义指标更感兴趣,即自定义指标,Zen中的积分时间等。 在第二种情况下,我们对所谓的作者指标感兴趣。 例如,我们衡量Zen的生活水平,例如,最低的10%的作者。 如果他们生活得足够好,那么其他人也都会高兴。

我们该怎么做? 假设我们有通常的排名公式。 为简单起见,假设它预测用户单击给定卡上给定项目的可能性。 我们该怎么办? 现在,为每篇文章进行修复,并在理想情况下将本文的模型应用于所有用户(实际上,适用于某种用户样本)。 然后,我们将建立得分的分布,即用户针对每篇文章点击某篇文章的可能性的估计值。 现在,对于每篇文章,我们都具有图表上的分布(上面的幻灯片-大约编辑)。 之后,我们将为用户对文章进行排名,并不仅根据点击的可能性,还根据该用户在本文中所占的百分比来选择顶部。 也就是说,我们估算点击的可能性,查看用户在此分布中所处的位置,并根据此值进行排列。

在这里,我们有两张相同的卡片,其中一张的点击率更高,为20%,另一张的点击率不到1%。 现在,如果您选择的是特定用户,则有可能出现这种情况,即他有可能单击流行程度较高的卡而不是流行程度较低的卡,例如10%对3%。 但是,由于点击流行卡片的平均概率为20%,而用户的点击率为10%,因此,他与该出版物的相关性平均要比普通Zen用户低。 而在另一种情况下,情况恰恰相反:他有3%的点击机会,但平均文章有1%的机会。 因此,与其他Zen用户相比,它是与该文章更相关的普通读者。 因此,这里的关键见解是,即使单击文章的可能性较小,如果用户是该出版物最受信任的核心,那么在这样的框架的帮助下,我们就有机会展示不太受欢迎的文章。

如果用户或多或少地平均地来找我们,那么给定的分数(即我们排名的分数)(即每个用户所占的百分比)将平均分配给用户。 这意味着,如果以这种方式对所有文章进行排名,那么它们都会或多或少地收集相同数量的展示次数。 相较于一些不太相关的卡片,只有10次展示不会产生数千万次展示。 因此,通过平衡以用户为中心的排名和以自动为中心的排名,我们可以达到我们认为正确的用户满意度和作者满意度之间的比率。
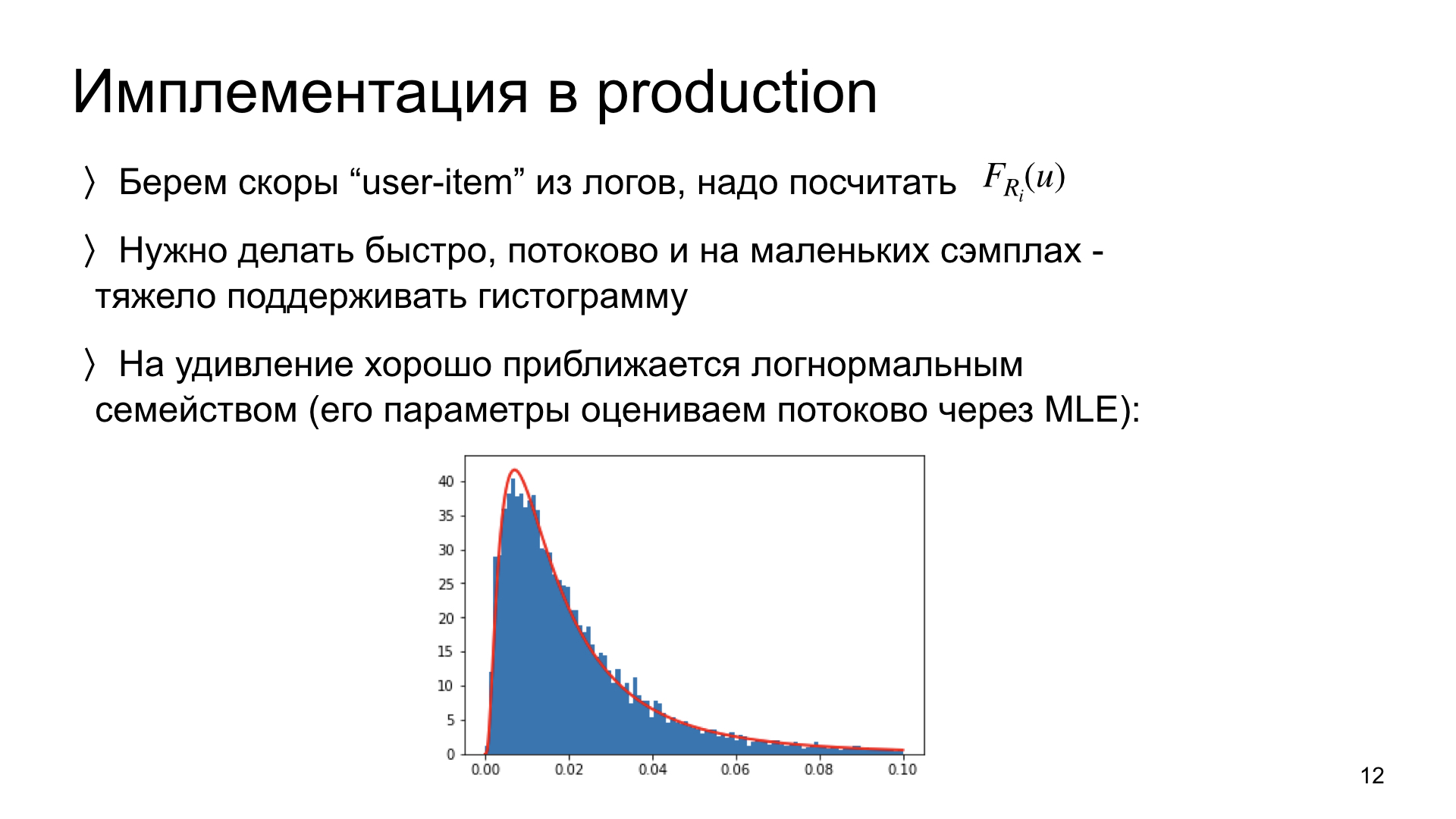
关于我们如何在生产中实现这一点的几句话。 我们需要查看我们的日志并从中计算每篇文章的分布。 一个重要的限制:首先,我们需要能够以流模式进行此操作。 也就是说,理想情况下,为了更新新数据的分布估计,我们需要在内存中不保存所有先前的数据,而只保存当前的估计。 这样的系统是可扩展的,这样的方案有效。 理想情况下,我们需要能够对小数据执行此操作。 如果任何一篇文章只有300次印象,那么我们需要能够充分估计这么多观察值的分布。
我们进行了实验,发现这种分数分布出奇地接近对数正态分布。 也就是说,这是一个经验观察。 如果是这样,那么我们可以仅评估该分布的两个参数,而不是非参数地估计分布的整个直方图。 而且,我们可以仅使用当前参数估计和新观测值在流中执行此操作。 这样的方案非常快并且效果很好。 现在她正在和我们一起生产。
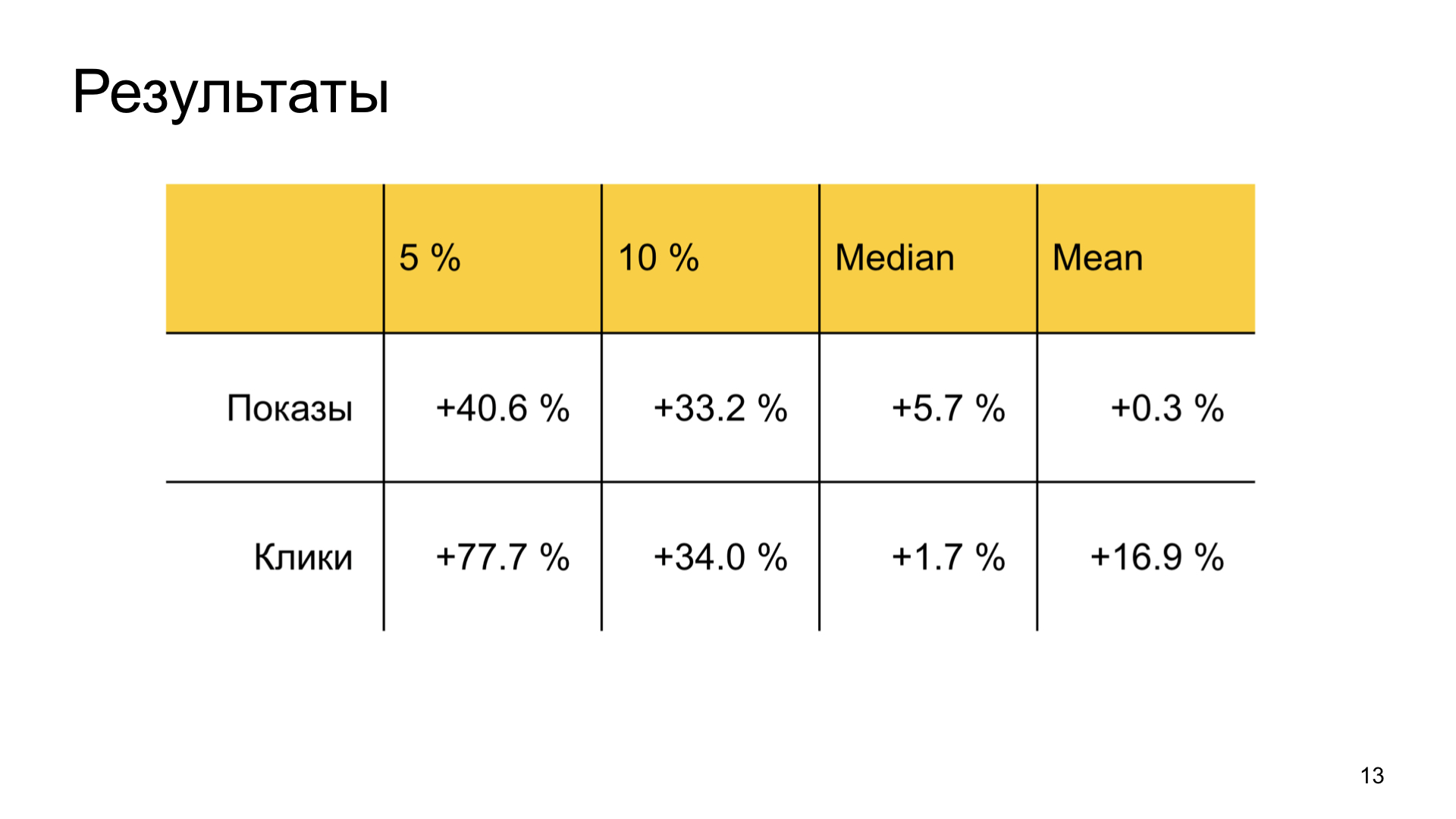
结果也不错。 我们极大地提高了Zen中被忽视的优秀作者的幸福感,并且不浪费常见的用户指标。 即,业务任务已完全实现。
我现在显示了我们可以处理的任务示例之一。 当然,这些任务很多,而每一项任务我们都需要您的帮助。 我们真的希望您能
与我们合作 。 最后,我会说几句话,说明我们对实习生的期望以及我们对实习生的期望。 从学员那里,我们期望最重要的事情-编写代码的能力。 我们没有纯粹的科学家提供服务。 我们都是ML工程师,他们必须能够完成整个任务周期。 他们必须能够在生产中实施他们的解决方案,并应用ML。 也就是说,我们希望您可以在基本级别上编写代码,了解方法,了解算法,数据结构和机器学习的基础。
我们对实习生没有什么期望? 首先,我们不期望对任何语言或框架有深入的了解。 也就是说,如果您不知道协程在Python中的工作方式-没关系,我们将教您一切。 而且我们不希望您有太多经验。 我们期待您的知识,渴望工作。 如果没有经验,那没关系。 我们将教一切,一切都会好起来的。 谢谢你