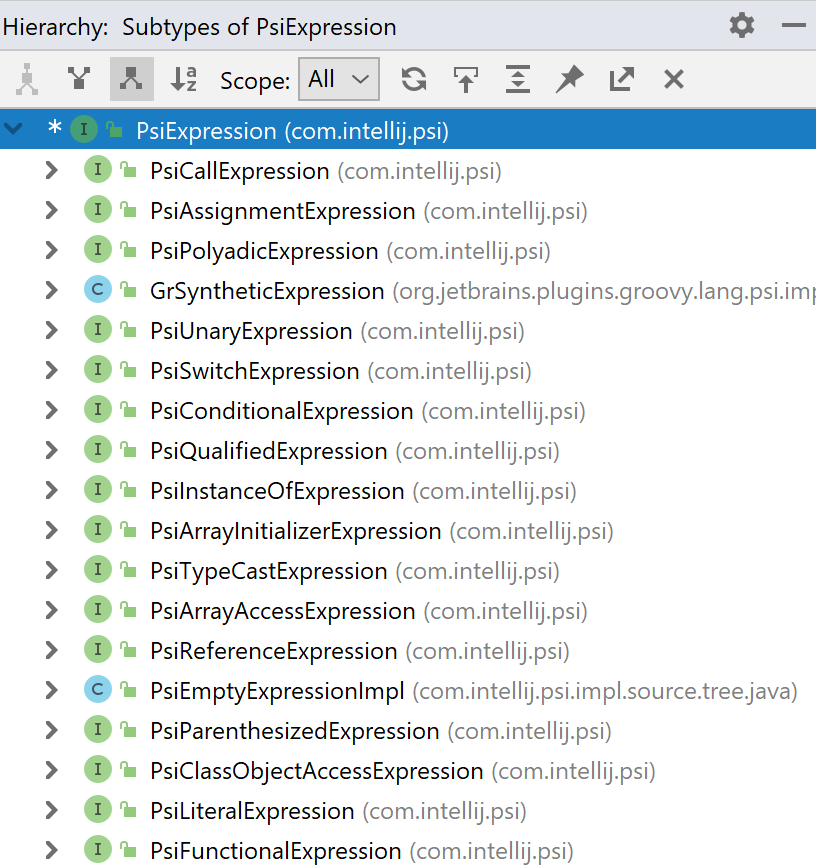
 任何IDE的重要功能都是在代码中进行搜索和导航。 常用的Java搜索选项之一是搜索此接口的所有实现。 通常,这种功能称为“类型层次”,其外观如右图所示。
任何IDE的重要功能都是在代码中进行搜索和导航。 常用的Java搜索选项之一是搜索此接口的所有实现。 通常,这种功能称为“类型层次”,其外观如右图所示。
调用此函数时,在项目的所有类中进行迭代效率很低。 您可以在编译时将完整的类层次结构保存到索引,因为无论如何编译器都会构建它。 如果编译是由IDE本身启动且未委托(例如在Gradle中),则我们将执行此操作。 但这仅在编译后模块中没有任何更改的情况下有效。 但是在一般情况下,源代码是最相关的信息源,索引建立在源代码上。
如果我们不处理功能接口,那么寻找直系继承人是一项简单的任务。 在寻找Foo接口的实现时,您需要找到所有带有implements Foo ,以及所有具有extends Foo接口,以及形式为new Foo(...) {...}匿名类。 为此,预先构建每个项目文件的语法树,找到相应的结构并将其添加到索引就足够了。
当然,这里有一些微妙之处:也许您在寻找com.example.goodcompany.Foo接口,但是实际上使用了org.example.evilcompany.Foo 。 是否可以在索引中预先放置父接口的全名? 这有困难。 例如,使用该接口的文件可能如下所示:
仅查看文件,我们无法理解真正的全名是Foo 。 您必须查看几个软件包的内容。 每个包都可以在多个位置定义(例如,在几个jar文件中)。 如果在分析此文件时必须对字符进行完全解析,则索引编制将花费很长时间。 但是主要的问题还不止于此,而是建立在MyFoo.java文件上的索引不仅取决于它,还取决于其他文件。 毕竟,我们可以将Foo接口的描述从org.example.foo包转移到org.example.bar包,并且不要更改MyFoo.java文件中的任何内容,并且Foo的全名将更改。
IntelliJ IDEA中的索引仅取决于单个文件的内容。 一方面,这非常方便:与特定文件相关的索引在此文件更改时变为无效。 另一方面,这对可以放置在索引中的内容施加了很大的限制。 例如,它不能可靠地将父类的全名存储在索引中。 但是,从原则上讲,这并不那么可怕。 在查询类型层次结构时,我们可以找到所有适合短名称的内容,然后对这些文件执行诚实的字符解析并确定其是否真正适合我们。 在大多数情况下,不会有太多多余的字符,这样的检查很快。
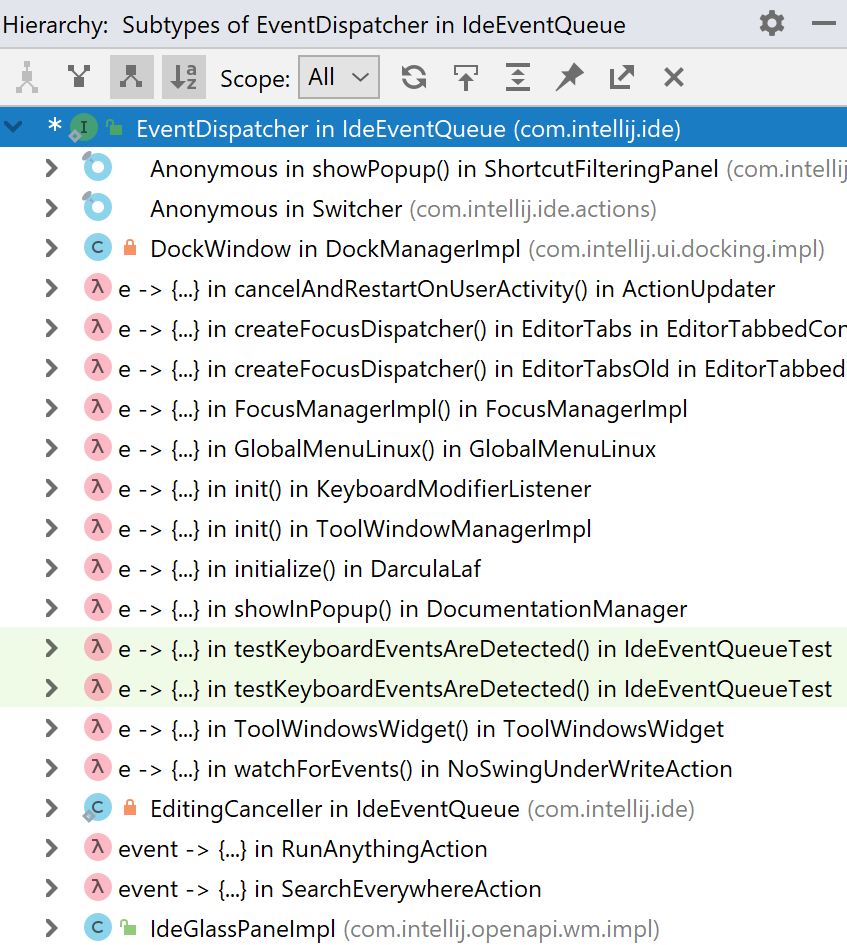 当我们要寻找其后代的类是一个功能接口时,情况将发生巨大变化。 然后,除了显式和匿名继承人之外,我们还获得lambda表达式和方法链接。 现在要输入什么索引,以及在搜索时直接计算什么?
当我们要寻找其后代的类是一个功能接口时,情况将发生巨大变化。 然后,除了显式和匿名继承人之外,我们还获得lambda表达式和方法链接。 现在要输入什么索引,以及在搜索时直接计算什么?
假设我们有一个功能接口:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
代码中有不同的lambda表达式。 例如:
() -> {}
也就是说,我们可以快速仅过滤那些参数数量错误或返回类型明显错误的lambda,例如void vs non-void。 通常不可能更精确地确定返回类型。 例如,在lambda s -> list.add(s) ,您需要解析字符list并add ,并且有可能启动完整的类型推断过程。 所有这些都是漫长的,并且需要固定其他文件的内容。
如果我们的功能接口接受五个参数,我们很幸运。 但是,如果只接受一个参数,则此类过滤器将留下大量额外的lambda。 方法引用更糟。 原则上,无论是否合适,都不能以任何方式表示对方法的引用。
也许您应该环顾lambda以了解某些内容? 是的,有时候可以。 例如:
在所有这些情况下,可以从当前文件中找到相应功能接口的简称,并将其放在功能表达式旁边的索引中,无论是lambda还是方法引用。 不幸的是,在实际项目中,这些情况仅占所有lambda的很小一部分。 在绝大多数情况下,lambda用作方法的参数:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
这三个lambda中的哪一个可以为StringConsumer类型? 程序员显然没有。 因为很明显,我们这里有Stream API链,而且标准库中只有功能接口,所以我们的类型不能在那里。
但是,IDE不应欺骗自己,而必须给出准确的答案。 如果list根本不是java.util.List ,而list.stream()根本不返回java.util.stream.Stream怎么办? 为此,您必须解析list符号,众所周知,仅根据当前文件的内容才能可靠地完成此操作。 即使我们安装了它,搜索也不应该依赖于标准库的实现。 也许我们专门在这个项目中用我们自己的java.util.List类替换了? 搜索必须对此做出响应。 好吧,当然,lambda不仅用于标准流中,而且还有许多其他传输方法。
结果,事实证明我们可以在索引中查询所有使用lambda的Java文件的列表,这些文件具有所需的参数数量和有效的返回类型(实际上,我们仅跟踪四个选项:void,non-void,boolean和any)。 然后呢? 对于这些文件中的每一个,构建一个完整的PSI树(它像一个解析树,但是具有字符解析,类型推断和其他巧妙的东西),并诚实地为lambda执行类型推断吗? 然后,在大型项目中,即使只有两个接口实现,也不会等待所有接口实现的列表。
事实证明,我们需要执行以下步骤:
- 询问指数(便宜)
- 建立PSI(昂贵)
- 打印lambda类型(非常昂贵)
在Java版本8和更高版本中,类型推断是一项非常昂贵的操作。 在一个复杂的调用链中,您可以具有许多通用通配符参数,这些值需要使用规范第18章中描述的激烈过程来确定。 对于正在编辑的当前文件,可以在后台完成此操作,但是对于成千上万个未打开的文件则很难做到这一点。
但是,您可以在这里进行一些操作:在大多数情况下,我们不需要最终类型。 如果没有将lambda传递给使用通用参数的方法,那么我们可以摆脱参数替换的最后一步。 假设,如果推导了lambda类型java.util.function.Function<T, R> ,则无法计算替换参数T和R :的值,因此很明显是否将其返回到搜索结果。 尽管在调用这样的方法时这不起作用:
static <T> void doSmth(Class<T> aClass, T value) {}
可以这样调用该方法: doSmth(Runnable.class, () -> {}) 。 然后,lambda类型将显示为T ,无论如何您都必须替换。 但这是一种罕见的情况。 因此,事实证明可以节省,但不超过10%。 问题没有得到根本解决。
另一个想法:如果确切的类型推断很复杂,那么让我们得出一个近似的结论。 让它仅对擦除的类类型起作用,并且不减少规范中所写的限制集,而只是遵循调用链。 只要擦除的类型不包含通用参数,一切都很好。 例如,从上面的示例中获取流,并确定最后一个lambda是否实现了我们的StringConsumer :
list变量->类型java.util.ListList.stream()方法- List.stream() java.util.stream.Stream类型Stream.filter(...)方法→输入java.util.stream.Stream ,我们什至不看过filter参数,有什么区别Stream.map(...)方法- Stream.map(...) java.util.stream.Stream类型,类似Stream.forEach(...)方法→有一个这样的方法,它的参数是Consumer类型,显然不是StringConsumer 。
好吧,他们没有进行完全类型推断。 但是,使用这种简单的方法,很容易遇到重载方法。 如果我们没有完全开始类型推断,那么您将无法选择正确的重载版本。 虽然不是,但有时方法参数的数量可能不同。 例如:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
在这里我们可以很容易地理解
- 有两个
CompletableFuture.supplyAsync方法,但是一个方法带有一个参数,第二个带有两个参数,因此请选择一个带有两个参数的方法。 它返回一个CompletableFuture 。 thenRunAsync方法也是两个,您可以从中类似地选择一个采用一个参数的方法。 相应的参数类型为Runnable ,这意味着它不是StringConsumer 。
如果几种方法接受相同数量的参数,或者某些方法具有可变数量的参数并且看起来也很合适,那么您将必须跟踪所有选项。 但是通常这也并不可怕。 例如:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder()显然会创建java.lang.StringBuilder 。 对于设计人员,我们仍然允许该链接,但是这里不需要复杂的类型推断。 即使有new Foo<>(x, y, z) ,我们也不显示典型参数的值,我们只对Foo感兴趣。- 有
StringBuilder.append采用一个参数StringBuilder.append方法,但是它们都返回类型java.lang.StringBuilder ,所以foo和bar什么类型都没有关系。 StringBuilder.chars方法StringBuilder.chars一种,它返回java.util.stream.IntStream 。IntStream.forEach方法IntStream.forEach一个,并且接受IntConsumer类型。
即使某些选项保留在某处,您也可以全部跟踪它们。 例如,传递给ForkJoinPool.getInstance().submit(...)的lambda的类型可以是Runnable或Callable ,但是如果我们正在寻找第三者,我们仍然可以丢弃该lambda。
当方法返回通用参数时,会发生不愉快的情况。 然后,该过程中断,您必须运行全类型推断。 但是,我们支持一种情况。 它在我的StreamEx库中显示得很好,该库具有一个抽象类AbstractStreamEx<T, S extends AbstractStreamEx<T, S>>其中包含S filter(Predicate<? super T> predicate) 。 通常,人们使用特定的类StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> 。 在这种情况下,可以执行type参数的替换,并找出S = StreamEx 。
好吧,在许多情况下,我们摆脱了非常昂贵的类型推断。 但是我们对PSI的构建一无所获。 只是将文件解析为五百行只是为了发现第480行中的lambda不适合我们的查询,这有点可耻。 让我们回到我们的流:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
如果list是当前类中的局部变量,方法参数或字段,则已经在索引阶段,我们可以找到其声明并确定类型的简称为
List 因此,在最后一个lambda的索引中,我们可以输入以下信息:
这个lambda的类型是一个参数的forEach方法的参数类型,一个参数调用map方法的结果,一个参数调用filter方法的结果,零参数调用stream方法的结果,并调用List类型的对象。
所有这些信息在当前文件上都可用,这意味着可以将其放置在索引中。 在搜索过程中,我们要求索引提供有关所有lambda的此类信息,并尝试在不构建PSI的情况下还原lambda类型。 首先,您必须对名为List班级进行全局搜索。 当然,我们不仅会发现java.util.List ,而且还会发现java.awt.List或用户项目代码中的某些内容。 此外,我们将所有这些类提交给我们之前使用的不准确的类型解析相同的过程。 通常,多余的类本身会很快被过滤掉。 例如,在java.awt.List中没有stream方法,因此将其进一步排除在外。 但是,即使最后有多余的东西,并且我们找到了几种lambda类型的候选者,也很有可能它们都不适合搜索查询,并且我们仍将避免构建完整的PSI。
全局搜索可能会太昂贵(项目中有很多List类),或者在一个文件的上下文中不允许链的开头(假设这是父类的字段),或者链会在某处中断,因为该方法返回一个通用参数。 然后,我们不会立即放弃,而是再次尝试从下一个链接方法的全局搜索开始。 例如,对于map.get(key).updateAndGet(a -> a * 2)链,以下语句进入了索引:
lambda的类型是updateAndGet方法的唯一参数的类型,该方法在具有一个参数的get方法的结果上调用,该方法在Map类型的对象上调用。
让我们幸运的是,在项目中只有一种java.util.Map 。 它确实具有get(Object)方法,但不幸的是它返回通用参数V 然后,我们删除该链,并在全局范围内查找具有一个参数的updateAndGet方法(当然使用索引)。 AtomicInteger ,项目中只有三种这样的方法,分别在AtomicInteger , AtomicLong和AtomicReference ,它们的参数类型分别为IntUnaryOperator , LongUnaryOperator和UnaryOperator 。 如果我们正在寻找其他任何类型,那么我们发现该lambda不适合并且无法构建PSI。
令人惊讶的是,这是该功能的生动示例,随着时间的流逝,其功能开始变得越来越慢。 例如,您正在寻找功能接口的实现,项目中只有三个,而IntelliJ IDEA会搜索它们十秒钟。 您会非常清楚地记得,三年前也有三个,您也在寻找它们,但是随后环境在同一台计算机上在两秒钟内给出了答案。 您的项目尽管庞大,却在三年内增长了,也许增长了5%。 当然,您会开始不满意这些开发人员所犯的错误,以至于IDE开始变得如此缓慢。 扯掉这些不幸的程序员的手。
也许我们什么都没做。 也许搜索工作与三年前相同。 就在三年前,您刚刚切换到Java 8,例如,您的项目中有一百个lambda。 现在,您的同事将匿名类转换为lambda,开始积极使用流或连接某种反应式库,结果lambda不再是一百,而是一万。 现在,为了找出三个必需的lambda,必须对IDE进行一百倍以上的搜索。
我说“也许”是因为,当然,我们会不时返回此搜索并尝试加快搜索速度。 但是在这里,您甚至不必划着小溪划船,而是划上瀑布。 我们尝试过,但是项目中的lambda数量正在迅速增长。