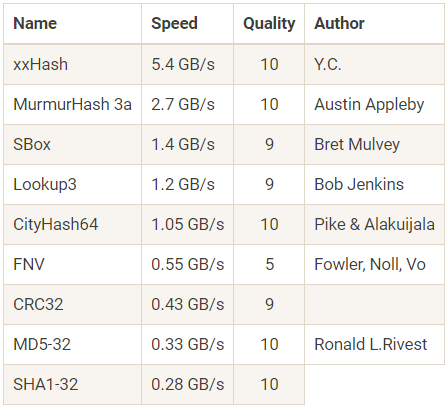
 程序SMHasher在Core 2 Duo 3.0 GHz上制定的基准
程序SMHasher在Core 2 Duo 3.0 GHz上制定的基准在哈布雷(Habré)上反复谈到
非加密哈希函数 ,该
函数比加密哈希函数快一个数量级。 它们用于速度很重要的地方,而使用慢速MD5或SHA1则毫无意义。 例如,构建具有键-值对存储的哈希表,或在传输大文件时快速检查校验和。
最受欢迎的方法之一是
xxHash系列哈希函数,大约在五年前出现。 尽管最初设想这些散列是在LZ4压缩过程中验证校验和,但它们开始用于各种任务。 可以理解:只需将上表与xxHash和其他一些哈希函数的性能进行比较即可。 在此测试中,xxHash在性能上胜过其最接近的竞争对手一半。
XXH3的新版本将标准
进一步提高。
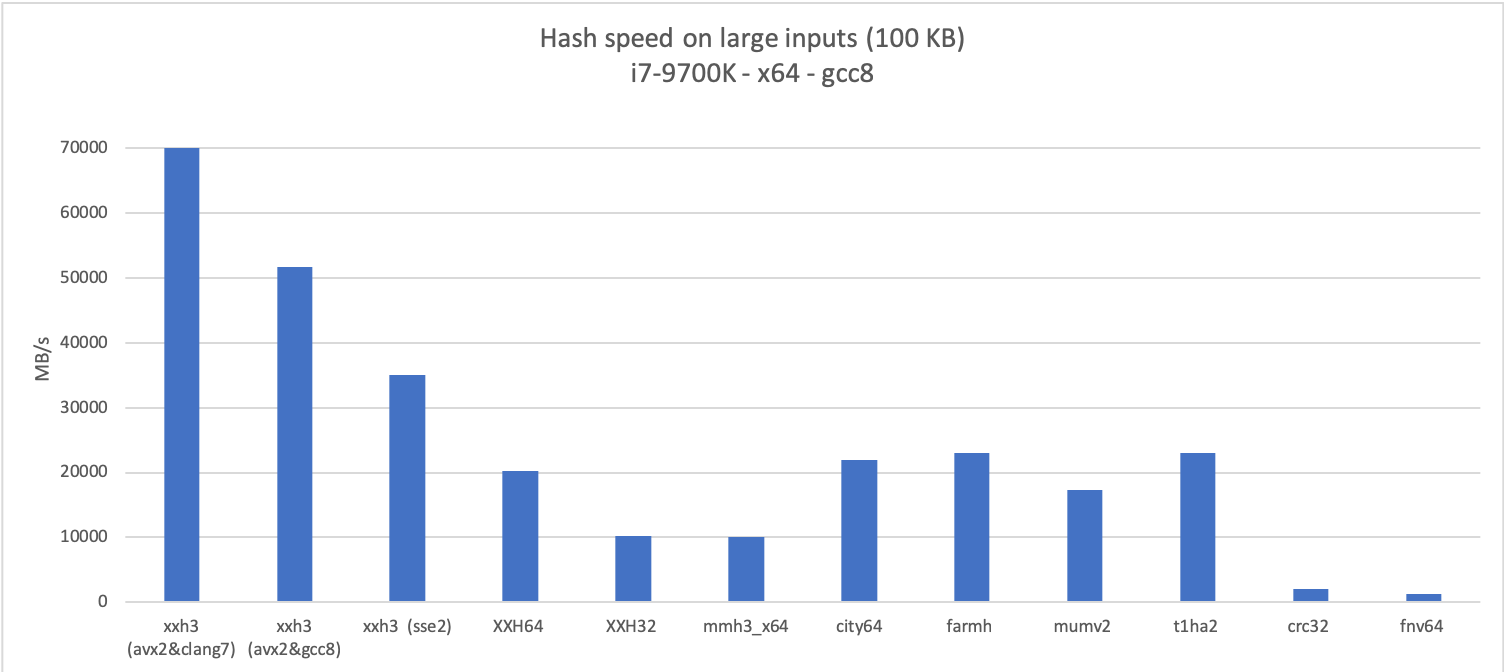 在下文中,可单击图表
在下文中,可单击图表程序作者Yann Collet
写道 ,改进算法的想法是在布隆过滤器的实现期间提出的,该方法需要基于小的可变长度输入数据快速生成64个伪随机位。 原则上,标准XXH64可以处理此问题,但是处理小型输入数据从来都不是其开发的优先事项。 换句话说,优化是可能的。 作为优化的结果,出现了一个新的哈希函数XXH3,其中实现了其他哈希算法的思想。 最有趣的是,XXH3的速度明显快于所有现有的xxHash变体,不仅在小输入数据上,而且在几乎所有使用情况下。
XXH3消除了XXH64的主要缺点-哈希限制为64位。 作者说,由于这个原因,经常有人要求他发布至少128位的版本。 因此,XXH3哈希函数在理论上能够生成高达256位的哈希。
在XXH3中,这是通过向量化最佳处理的内部循环。 因此,该功能在指令集SSE2,AVX2和NEON上使用了硬件支持。 性能取决于编译器。 出乎意料的是,clang编译的版本远远优于其他版本。 伊恩·科尔(Ian Colle)甚至认为哈希函数的性能会超出内存带宽。 图上的该版本对应于虚线。

结果,事实证明,支持AVX2的哈希函数具有比RAM高得多的吞吐量,因此缓存大小成为重要因素。 但是,在许多任务中,必须处理缓存中已存在的数据,因此以比内存更快的速度进行工作是很有意义的。
对SSE2指令的支持使新的哈希函数可以在现实世界中仍然很常见的32位应用程序(例如WASM字节码)上显着规避XXH32。
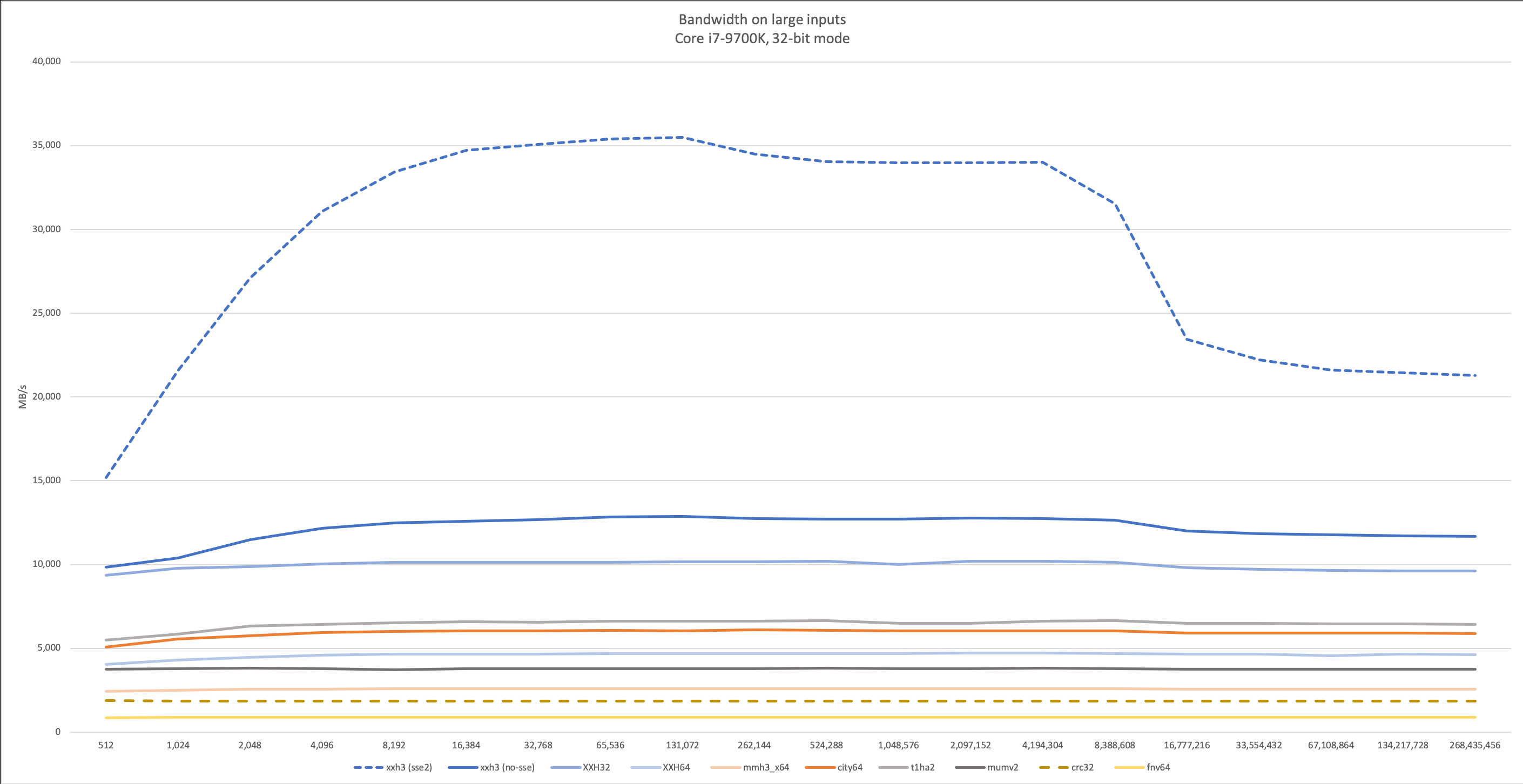
在较小的输入数据(20-30字节)上,XXH3哈希函数虽然不多,但仍然优于Google的
CityHash和FarmHash,后者曾经是明显的领导者。

下图显示了最实际的测试结果,其中输入数据的长度可变(随机变量从1到N)。

另一个测试考虑了
延迟 :此处的散列从信号开始。 这个想法是模拟一个实际的工作量,其中哈希函数不能连续工作,而是在某个时刻在其他进程中被调用。
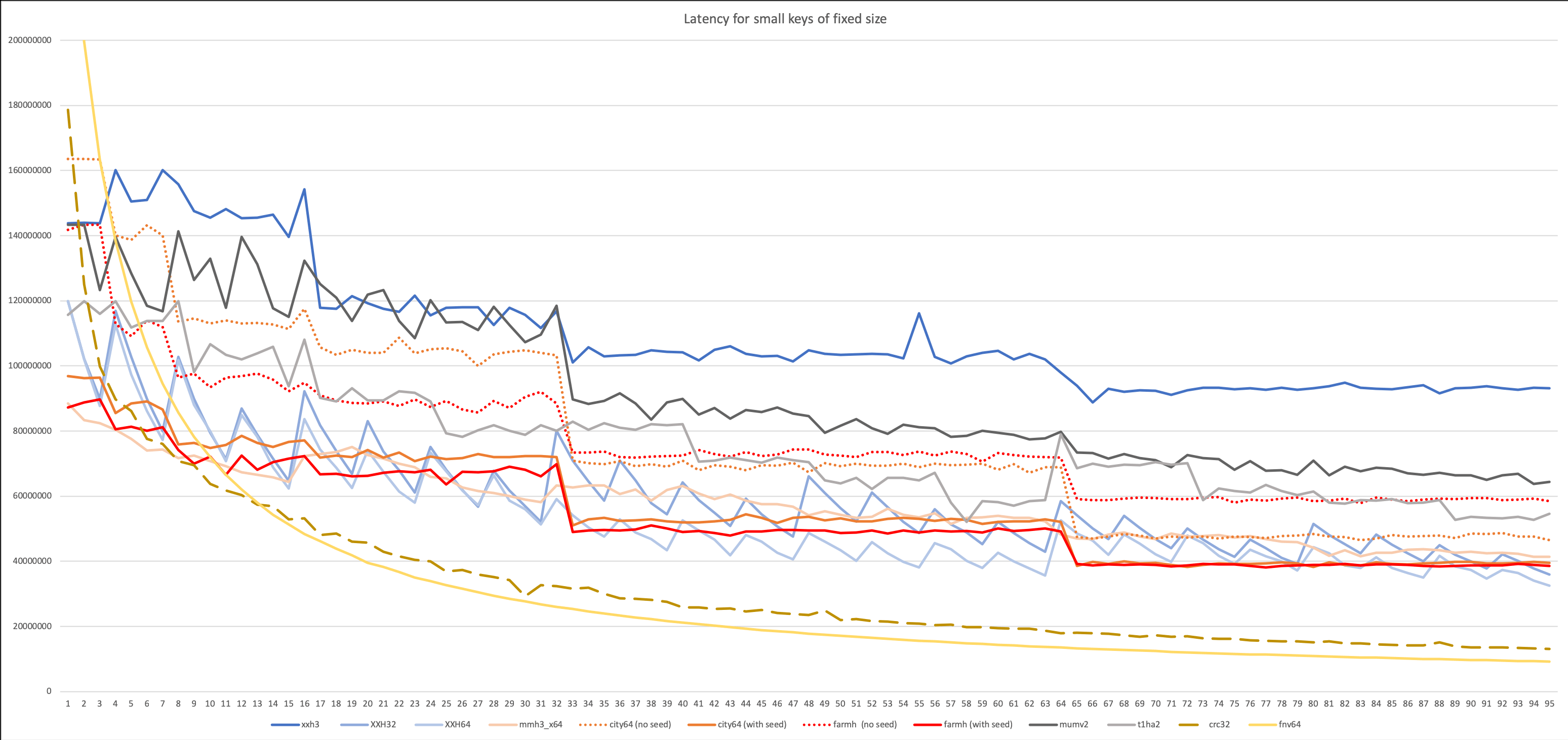
作者写道,这种乘以64×64 => 128位的乘法的测试更喜欢Vladimir Makarov的
mumv2算法和Leo
Yuryev的t1ha2 。

最后,这是最终也是最重要的图,其中显示了考虑到延迟的可变长度输入数据的哈希率。 它反映了哈希函数的实际用法,例如在数据库中。
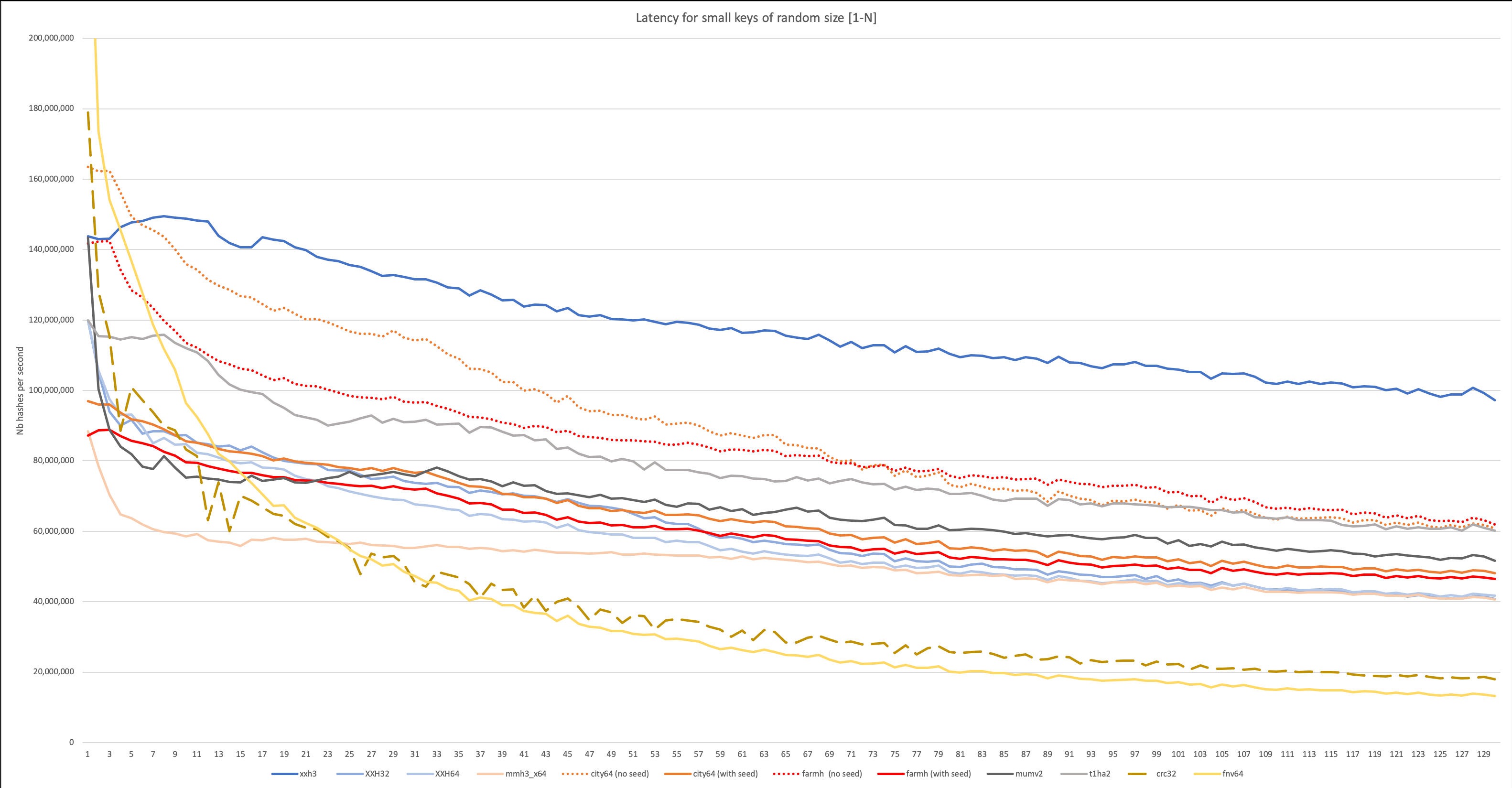
XXH3作为
xxHash v0.7.0软件包的一部分发布。 它带有“实验性”标记,要解锁,您需要使用宏
XXH_STATIC_LINKING_ONLY 。 作者解释说,到目前为止,哈希函数只能用于测试临时数据,而不能用于哈希的实际存储。 根据实验期的结果和用户评论的收集,XXH3功能将在下一版本的xxHash中获得稳定状态。

