对于那些懒于阅读所有内容的人:建议驳斥七个流行的神话,截至2019年2月,这在机器学习研究领域通常被认为是正确的。本文可
在pdf格式的ArXiv网站上找到 (英文)。
误解1:TensorFlow是一个张量库。
误区二:图像数据库反映了自然界发现的真实照片。
误解3:MO研究人员不使用测试套件进行测试。
误解四:神经网络训练使用所有输入数据。
误解5:批量标准化需要训练非常深的残差网络。
误解6:关注网络比卷积更好。
误解7:重要性图是解释神经网络的可靠方法。
现在了解详细信息。
神话1:TensorFlow是一个张量库
实际上,这是一个处理矩阵的库,这种区别非常重要。
在
计算矩阵和张量表达式的高阶导数时。 Laue等。 NeurIPS 2018作者展示了他们基于真实张量演算的自动微分库具有更紧凑的表达树。 事实是张量演算使用索引符号,这使您可以在正向和反向模式下同等工作。
矩阵编号隐藏索引以方便表示法,这就是为什么自动差异表达树通常变得过于复杂的原因。
考虑矩阵乘法C = AB。 我们有
用于直接模式和
相反。 要正确执行乘法,您需要严格遵守连字符的顺序和使用。 从记录的角度来看,这对于参与MO的人员来说是令人困惑的,但是从计算的角度来看,这是该程序的额外负担。
另一个例子,不那么琐碎:c = det(A)。 我们有
用于直接模式和
相反。 在这种情况下,由于两种模式都由不同的运算符组成,因此显然不可能对两种模式都使用表达式树。
通常,TensorFlow和其他库(例如Mathematica,Maple,Sage,SimPy,ADOL-C,TAPENADE,TensorFlow,Theano,PyTorch,HIPS autograd)的实现方式是自动区分的,这导致了正向和反向的事实该模式中构建了不同且无效的表达式树。 张量编号由于索引符号引起的乘法的可交换性而避免了这些问题。 有关其工作原理的详细信息,请参见科学论文。
作者通过在三个不同的任务中执行反向过程的自动区分(也称为反向传播)来测试他们的方法,并测量了计算Hessians所花费的时间。

在第一个问题中,对二次函数x
T Ax进行了优化。 第二步,计算逻辑回归,第三步,矩阵分解。
在CPU上,他们的方法比TensorFlow,Theano,PyTorch和HIPS autograd等流行的库快了两个数量级。
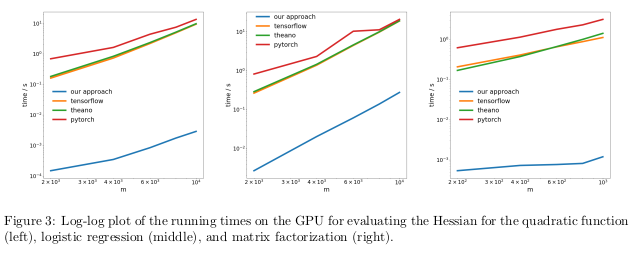
在GPU上,他们观察到更大的加速度,多达三个数量级。
结果:从计算的角度来看,使用当前的深度学习库来计算二阶或更高阶函数的导数过于昂贵。 其中包括计算一般的四阶张量,例如Hessians(例如,在MAML和Newton的二阶优化中)。 幸运的是,二次公式在深度学习中很少见。 但是,它们经常在“经典”机器学习中找到-SVM,最小二乘法,LASSO,高斯过程等。
误区二:图像数据库反映真实照片
许多人喜欢认为神经网络比人能更好地识别物体。 事实并非如此。 它们可以基于选定的图像(例如ImageNet)领先于人,但是在从普通生活中的真实照片中识别物体的情况下,它们绝对无法超越普通成年人。 这是因为当前数据集中的图像选择与现实中自然会遇到的所有可能图像的选择不一致。
在相当古老的作品中,《
无偏看数据集偏差》。 Torralba和Efros。 CVPR2011。作者建议研究十二个流行数据库中与一组图像相关的失真,以找出是否有可能训练分类器来确定从中获取该图像的数据集。

偶然猜出正确数据集的几率是1/12≈8%,而科学家们自己则以超过75%的成功率应对了这一任务。
他们在
方向梯度直方图 (HOG)上训练了SVM,发现分类器在39%的情况下完成了任务,大大超过了随机命中。 如果今天我们使用最先进的神经网络重复此实验,则肯定会看到分类器准确性的提高。
如果图像数据库正确显示了真实世界的真实图像,则我们将不必确定特定图像来自哪个数据集。

但是,数据中的某些特征会使每组图像彼此不同。 ImageNet有许多赛车,它们不可能整体上描述“理论上”的平均赛车。

作者还通过测量在一个集合上训练的分类器与其他集合的图像的结合程度,来确定每个数据集的价值。 根据此度量标准,LabelMe和ImageNet数据库的偏向最小,使用“货币篮子”方法的评级为0.58。 事实证明,所有值均小于1,这意味着在不同数据集上进行训练总是会导致性能下降。 在没有偏集的理想世界中,一些数字应该超过一个。
作者悲观地得出以下结论:
那么,针对现实世界设计的训练算法的现有数据集的价值是什么? 得到的答案可以描述为“总比没有好,但不多”。
误区三:MO研究人员不使用测试套件进行测试
在关于机器学习的教科书中,我们被教导将数据集分为训练,评估和验证。 在训练集上进行训练并在评估中进行评估的模型的有效性,可以帮助MO的人员微调模型,以最大程度地提高其实际使用效率。 在完成调整以提供对模型在现实世界中的真实有效性的公正评估之前,无需触摸测试集。 如果某人在训练或评估阶段使用测试集作弊,则该模型冒着过于适应特定数据集的风险。
在MO研究的竞争异常激烈的世界中,新算法和模型通常会根据其与验证数据一起工作的有效性来进行判断。 因此,研究人员撰写或发表描述无法与测试数据集配合使用的方法的论文是没有意义的。 从本质上讲,这意味着整个莫斯科地区的社区都使用测试集进行评估。
这场骗局的后果是什么?
 CIFAR-10分类器的
CIFAR-10分类器的作者
是否推广到CIFAR-10? Recht等。 ArXiv 2018通过为CIFAR-10创建新的测试套件来研究此问题。 为此,他们从Tiny Images中选择了一些图像。
他们之所以选择CIFAR-10,是因为它是MO中最常用的数据集之一,在NeurIPS 2017中排名第二(仅次于MNIST)。 为CIFAR-10创建数据集的过程也得到了很好的描述,并且是透明的,在大型Tiny Images数据库中有很多详细的标签,因此您可以重现新的测试集,从而最大程度地减少分布偏移。

他们发现,新测试集上的大量不同模型的神经网络显示出准确性显着下降(4%-15%)。 但是,每个模型的相对性能等级仍然相当稳定。
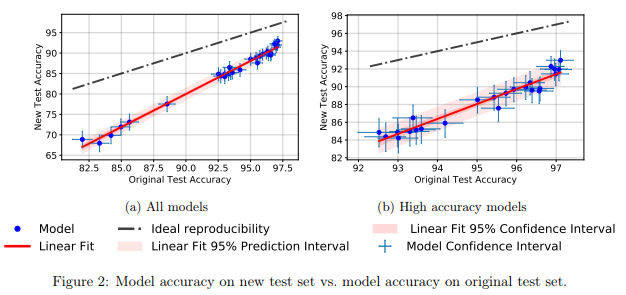
通常,性能较差的模型与性能较差的模型相比,精度下降较低。 这很好,因为可以得出结论,即随着社区发明了改进的MO方法和模型,至少在CIFAR-10的情况下,由于作弊而导致的模型通用性损失减少了。
误解四:神经网络训练使用所有输入
人们普遍认为
数据是一种新油 ,而我们拥有的数据越多,我们就越能训练出效率低下且参数过多的深度学习模型。
在
深度神经网络学习过程中遗忘示例的实证研究中。 Toneva等。 ICLR 2019作者展示了几种常见的小图像集的显着冗余。 令人惊讶的是,可以简单地删除CIFAR-10中30%的数据,而不会显着改变检查的准确性。
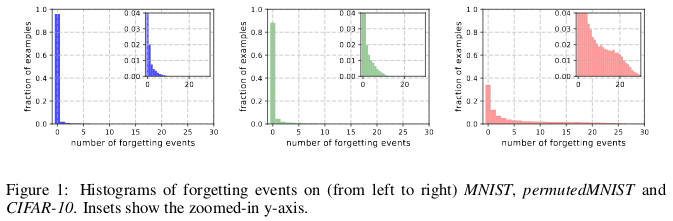 MNIST,permutedMNIST和CIFAR-10(从左到右)的遗忘历史。
MNIST,permutedMNIST和CIFAR-10(从左到右)的遗忘历史。当神经网络在时间t + 1对图像进行错误分类时,而在时间t,它能够正确分类图像,则会发生遗忘。 时间流是通过SGD更新来衡量的。 为了追踪遗忘,作者在每次SGD更新后,在一个小的数据集上启动了他们的神经网络,而不是在数据库中可用的所有示例上启动了它们的神经网络。 不可忘记的例子称为难忘的例子。
他们发现91.7%MNIST,75.3%排列的MNIST,31.3%CIFAR-10和7.62%CIFAR-100是令人难忘的例子。 这在直觉上是可以理解的,因为增加数据集的多样性和复杂性会使神经网络忘记更多示例。

与难忘的例子相比,难忘的例子似乎表现出更多罕见和奇怪的功能。 作者将它们与SVM中的支持向量进行了比较,因为它们似乎画出了决策边界的轮廓。
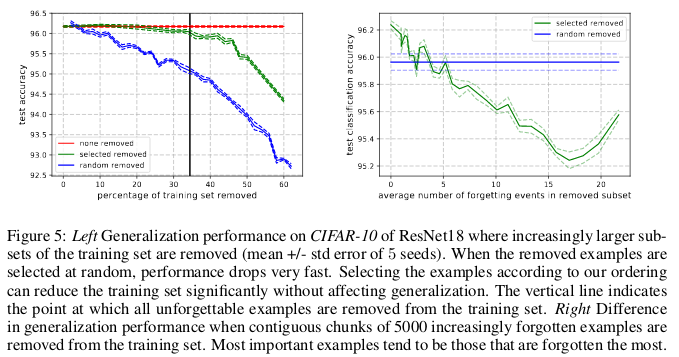
难忘的示例依次编码大多数冗余信息。 如果按难忘程度对示例进行排序,则可以通过删除最难忘的数据来压缩数据集。
可以删除30%的CIFAR-10数据,而不会影响检查的准确性,而删除35%的数据会导致检查的准确性略有下降0.2%。 如果您随机选择30%的数据,则将其删除会导致1%的验证准确性大幅度下降。
同样,可以从CIFAR-100中删除8%的数据,而不会降低验证准确性。
这些结果表明,与SVM训练类似,用于训练神经网络的数据存在大量冗余,其中可以去除不支持向量的向量,而不会影响模型决策。
结果:如果我们可以在开始训练之前确定哪些数据是难忘的,那么我们可以通过删除它们和节省时间来节省空间,而无需在训练神经网络时使用它们。
误解5:批量标准化需要训练非常深的残差网络。
长期以来,人们认为“从随机参数开始使用梯度下降来训练仅用于受控目的(例如,正确分类的对数概率)的用于直接优化的深度神经网络效果不佳”。
从那时起,出现了许多随机初始化,激活函数,优化技术和其他创新(例如残差连接)的巧妙方法,从而促进了使用梯度下降方法进行深度神经网络的训练。
但是,在引入批量归一化(以及其他顺序归一化技术)之后,发生了真正的突破,限制了网络每一层的激活大小,从而消除了消失和爆炸性梯度的问题。
在最近的工作中,
修正初始化:没有标准化的残差学习。 张等。 ICLR 2019表明,可以使用纯SGD训练具有10,000层的网络,而无需应用任何规范化。

作者比较了在CIFAR-10上不同深度的残差神经网络训练,发现标准初始化方法不适用于100层,而Fixup和批处理归一化方法成功用于10,000层。

他们进行了理论分析,结果表明“某些层的梯度归一化受到来自深层网络的无限增加的数量的限制”,这是爆炸梯度的问题。 为避免这种情况,使用了Foxup,其关键思想是根据m和L,按每个剩余分支L的m层缩放权重。

Fixup帮助在CIFAR-10上训练了一个具有110层的深层残差网络,其学习速度可与使用批量归一化训练的类似架构的网络的行为相媲美。
作者还使用ImageNet数据库以及英语到德语的翻译功能,使用网络上的Fixup在没有任何规范的情况下显示了相似的测试结果。
误解6:关注网络优于卷积网络。
“注意力”机制优于卷积神经网络的想法在MO研究者社区中越来越流行。 在
Vaswani及其同事的工作中,我们注意到“可分离卷积的计算成本等于自我注意层和逐点前馈层的组合。”
在对远程依存关系进行建模时,甚至高级生成竞争性网络也显示出比标准卷积更具自我注意的优势。
贡献者
通过轻量级和动态卷积支付较少的注意力。 Wu等。 ICLR 2019在对远程依存关系进行建模时,对自我注意的参数效率和有效性提出了质疑,并提供了部分受自我注意启发的卷积新选项,在参数方面更有效。
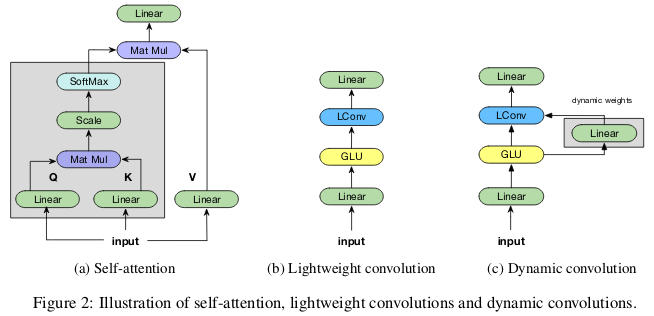
“轻量级”卷积在深度上是可分离的,在时间维度上是softmax-归一化的,在通道维度上由权重分开,并在每个时间步重复使用相同的权重(作为循环神经网络)。 动态卷积是轻量级卷积,在每个时间步使用不同的权重。
这种技巧使轻量级和动态卷积比标准不可分卷积更有效几个数量级。

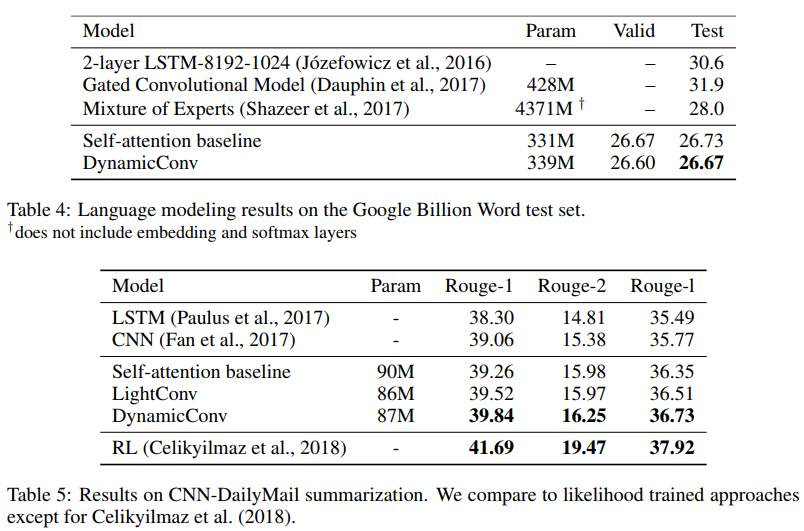
作者表明,使用相同或更少的参数,这些新的卷积在机器翻译,语言建模,抽象求和问题中对应或超过自吸收网络。
误解7:意义卡-解释神经网络的可靠方法
尽管有一种观点认为神经网络是黑匣子,但是已经有许多尝试来解释它们。 其中最流行的是重要性图,或将重要性评估分配给功能部件或训练示例的其他类似方法。
令人难以置信的是,由于图像的某些部分对神经网络很重要,因此可以得出结论:给定的图像已经以某种方式进行了分类。 为了计算重要性图,有几种方法经常使用给定图像中神经网络的激活以及通过网络的梯度。
在
解释神经网络是脆弱的。 Ghorbani等。 AAAI 2019作者表明,他们可以在图片中引入难以捉摸的变化,但是这会扭曲其重要性图。

神经网络不是通过蝴蝶翅膀上的图案来确定帝王蝶,而是因为在照片的背景下存在不重要的绿叶。

多维图像通常更接近于深度神经网络做出的决策边界,因此它们对对抗性攻击的敏感性。 而且,如果竞争性攻击将图像移动到解决方案的边界之外,则竞争性解释性攻击会将图像沿着解决方案的边界移动,而不会离开相同解决方案的范围。
作者开发的基本方法是对快速梯度标记的Goodfello方法的改进,它是最早成功的竞争性攻击方法之一。 可以假设,也可以将其他更新,更复杂的攻击用于对神经网络解释的攻击。
结果:由于深度学习在医学成像等关键应用领域中的日渐普及,因此重要的是仔细研究由神经网络做出的决策的解释。 例如,尽管如果卷积神经网络能够将MRI图像上的斑点识别为恶性肿瘤会很棒,但是如果这些结果基于不可靠的解释方法,则不应信任这些结果。