这是有关分析系统的系列文章的第二部分(
链接至第1部分 )。

如今,毫无疑问,准确的数据处理和结果解释可以帮助几乎所有类型的业务。 在这方面,分析系统越来越多地加载参数,应用程序中触发器和用户事件的数量也在增长。
因此,公司为分析人员提供了越来越多的“原始”信息以进行分析,并将其转变为正确的决策。 不应低估分析系统对公司的重要性,并且系统本身必须可靠且可持续。
客户分析
客户分析是公司通过官方SDK连接到其网站或应用程序的服务,集成到其自己的代码库中并选择事件触发器。 这种方法有一个明显的缺点:由于任何选定服务的限制,所有收集的数据都无法完全按照您的意愿进行处理。 例如,在一个系统中,运行MapReduce任务并不容易,而在另一个系统中,您将无法运行模型。 另一个缺点将是定期的(令人印象深刻的)服务账单。
市场上有许多客户端分析解决方案,但分析师迟早面临这样一个事实,即没有一项适用于任何任务的通用服务(而所有这些服务的价格都在不断上涨)。 在这种情况下,公司通常决定使用所有必要的自定义设置和功能来创建自己的分析系统。
服务器分析
服务器分析是一项服务,可以在公司内部(通常)通过自己的努力在公司内部的服务器上进行部署。 在此模型中,所有用户事件都存储在内部服务器上,从而使开发人员可以尝试使用不同的数据库进行存储并选择最方便的体系结构。 即使您仍想使用第三方客户端分析来完成某些任务,仍然可以实现。
服务器分析可以两种方式部署。 首先:选择一些开源实用程序,在您的计算机上部署并开发业务逻辑。
| 优点 | 缺点 |
| 您可以自定义任何内容 | 通常这很困难,需要个人开发人员。 |
第二:采用SaaS服务(亚马逊,谷歌,Azure),而不是自己部署它。 关于SaaS的详细信息,我们将在第三部分中讲述。
| 优点 | 缺点 |
| 中等数量的产品可能会便宜一些,但是如果增长迅速,它仍然会变得太昂贵 | 无法控制所有参数 |
| 管理完全转移到服务提供商的肩膀上 | 并不总是知道服务内部的内容(可能不需要) |
如何收集服务器分析
如果我们想摆脱使用客户端分析并组装我们自己的分析,那么我们首先需要考虑新系统的体系结构。 下面,我将逐步告诉您要考虑的内容,为何需要执行每个步骤以及可以使用哪些工具。
1.数据采集
与客户分析一样,公司分析师首先选择他们想在将来研究的事件类型,然后将其收集到列表中。 通常,这些事件以一定顺序发生,这称为“事件模式”。
接下来,假设移动应用程序(网站)具有普通用户(设备)和许多服务器。 为了将事件从设备安全地传输到服务器,需要一个中间层。 根据体系结构,可能会出现几个不同的事件队列。
Apache Kafka是一个
发布/子队列 ,用作收集事件的队列。
根据2014 年Kvor上的一篇文章 ,Apache Kafka的创建者决定以Franz Kafka的名字命名该软件,因为“这是一个为录音而优化的系统”,并且他喜欢Kafka的作品。 - 维基百科
在我们的示例中,有许多数据生产者及其使用者(设备和服务器),而Kafka帮助将它们彼此连接。 消费者将在接下来的步骤中更详细地描述,他们将成为主要参与者。 现在,我们将仅考虑数据生产者(事件)。
Kafka封装了队列和分区的概念;更具体地说,最好在其他地方阅读(例如,在
文档中 )。 无需赘述,可以想象为两个不同的操作系统启动了移动应用程序。 然后,每个版本都会创建自己的单独事件流。 生产者将事件发送到Kafka,并记录在适当的队列中。
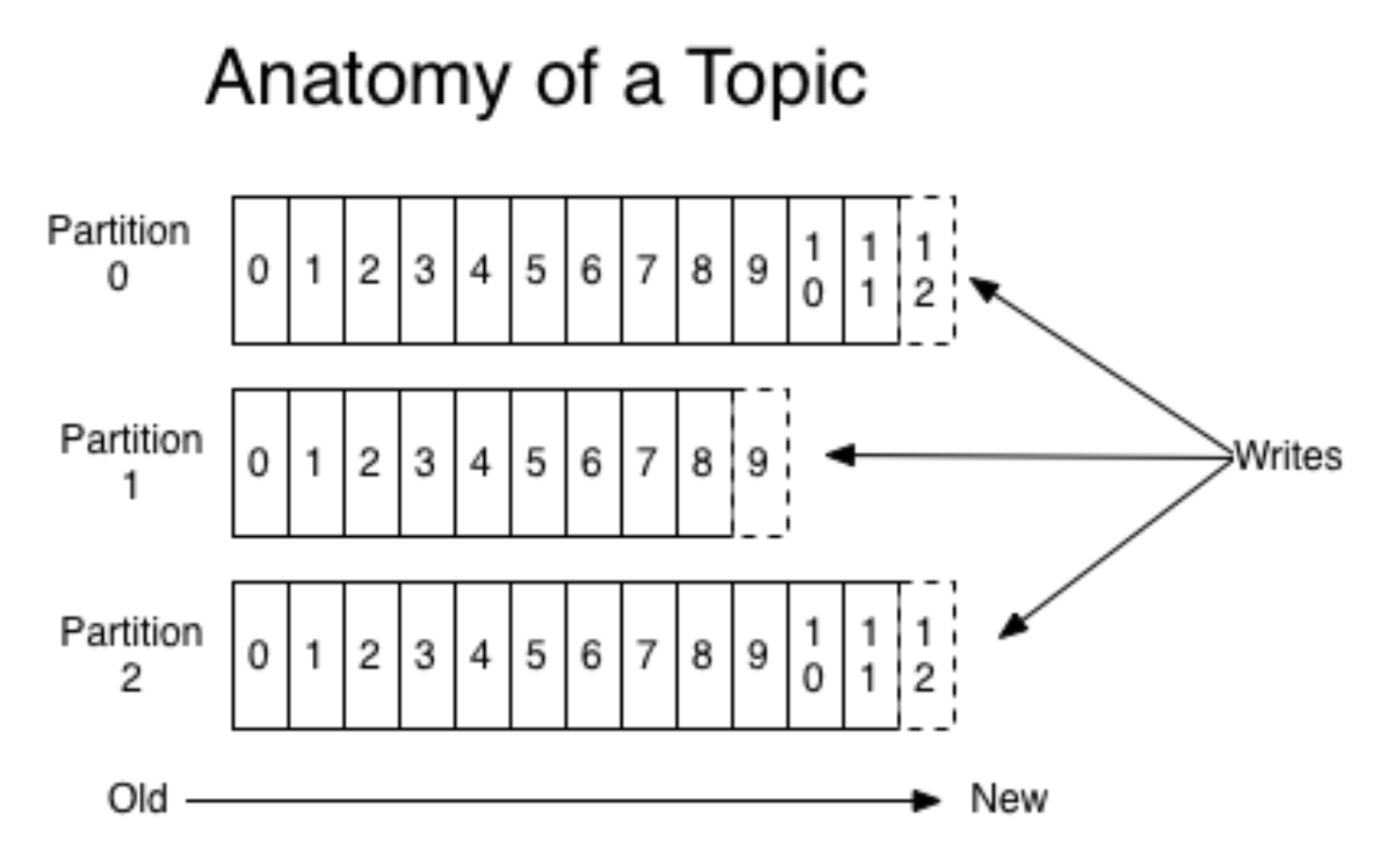
(图片
来自这里 )
同时,Kafka允许您阅读片段并使用迷你蝙蝠处理事件的流程。 Kafka是一个非常方便的工具,可以根据不断增长的需求(例如,通过事件的地理位置)很好地进行扩展。
通常一个分片就足够了,但是由于缩放(一如既往),事情变得更加困难。 可能没有人会在生产中只使用一个物理分片,因为该架构必须是容错的。 除Kafka外,还有另一种著名的解决方案-RabbitMQ。 我们没有在生产中将它用作事件分析的队列(如果您有这样的经验,请在评论中告诉我们!)。 但是,他们使用了AWS Kinesis。
在继续下一步之前,我们需要提到系统的另一层-原始日志的存储。 这不是必需的层,但是如果出现问题并且重置了Kafka中的事件队列,它将很有用。 原始日志的存储不需要复杂且昂贵的解决方案;您只需按正确的顺序(即使在硬盘驱动器上)将它们记录在某个地方。

2.事件流处理
准备好所有事件并将它们放入合适的队列后,我们进入处理步骤。 在这里,我将讨论两个最常见的处理选项。
第一个选项是在Apache系统上启用Spark Streaming。 所有Apache产品都生活在HDFS(一种安全的文件副本文件系统)中。 Spark Streaming是一个易于使用的工具,可以处理流数据并很好地扩展。 但是,维护起来可能有点困难。
另一种选择是构建自己的事件处理程序。 为此,例如,您需要编写一个Python应用程序,在docker中构建它,然后订阅Kafka队列。 当触发器到达泊坞窗中的处理程序时,处理将开始。 使用这种方法,您需要保持不断运行的应用程序。
假设我们选择了上述选项之一,然后继续进行处理。 处理器应首先检查数据的有效性,过滤垃圾和“中断”事件。 为了进行验证,我们通常使用
Cerberus 。 之后,您可以进行数据映射:将来自不同来源的数据进行标准化和标准化,以添加到常规标签中。
3.数据库
第三步是维护标准化事件。 在使用现成的分析系统时,我们经常需要与他们联系,因此选择方便的数据库很重要。
如果数据适合固定模式,则可以选择
Clickhouse或其他某些列数据库。 因此,聚合将非常快速地工作。 缺点是该方案被严格固定,因此折叠任何对象而不进行细化都会失败(例如,当发生非标准事件时)。 但是您可以算得很快。
对于非结构化数据,可以采用NoSQL,例如
Apache Cassandra 。 它可以在HDFS上运行,可以很好地复制,可以引发许多实例,具有容错能力。
您可以选择更简单的东西,例如
MongoDB 。 这是相当慢的,并且体积很小。 但优点是它非常简单,因此适合启动。
4.汇总
仔细保存所有事件后,我们希望从随后的批处理中收集所有重要信息并更新数据库。 在全球范围内,我们希望获得相关的仪表板和指标。 例如,从事件中收集用户个人资料并以某种方式衡量行为。 事件将被汇总,收集并再次保存(已在用户表中)。 同时,您可以构建系统,以便也将过滤器连接到聚合器-协调器:仅从特定事件类型中收集用户。
之后,如果团队中的某人仅需要高级分析,则可以连接外部分析系统。 您可以再次服用Mixpanel。 但由于费用很高,因此不发送所有用户事件,而只发送所需的事件。 为此,您需要创建一个协调器,该协调器会将一些原始事件或我们自己之前汇总的某些事件传输到外部系统,API或广告平台。
5.前端
您需要将前端连接到创建的系统。 一个很好的例子是
redash服务,它是用于帮助构建面板的数据库GUI。 互动方式:
- 用户进行SQL查询。
- 作为回应,收到一台平板电脑。
- 她为她创建了“新可视化”,并获得了可以自己保存的漂亮时间表。
服务中的可视化是自动更新的,您可以配置和跟踪监视。 Redash是免费的,如果是自托管的,那么SaaS每月将花费50美元。

结论
完成上述所有步骤之后,您将创建服务器分析。 请注意,这不是简单连接客户端分析的简单方法,因为所有内容都需要独立配置。 因此,在创建自己的系统之前,有必要将对严肃的分析系统的需求与您准备投入的资源进行比较。
如果您计算了所有内容并认为成本太高,那么在下一部分中,我将讨论如何制作更便宜的服务器分析版本。
感谢您的阅读! 我很乐意在评论中提出问题。