ASN.1是描述结构化信息以及该信息的编码规则的语言的标准(ISO,ITU-T,GOST)。 对于我作为程序员而言,这只是用于序列化和呈现数据以及JSON,XML,XDR和其他格式的另一种格式。 它在我们的日常生活中极为常见,并且遇到了很多人:在蜂窝,电话,VoIP通信(UMTS,LTE,WiMAX,SS7,H.323),网络协议(LDAP,SNMP,Kerberos)中,关于银行卡和生物特征护照中的加密(X.509,CMS,PKCS标准)等等。
本文讨论了
PyDERASN :Python ASN.1库,该库在
Atlas中的加密相关项目中得到了积极使用。
实际上,不建议为加密任务推荐ASN.1:ASN.1及其编解码器很复杂。 这意味着代码将不会很简单,但它始终是额外的攻击手段。 只需查看ASN.1库
中的漏洞
列表即可 。 Bruce Schneier在其
密码学工程学中,也不建议使用此标准,因为它很复杂:“最著名的TLV编码是ASN.1,但是它非常复杂,我们回避了。” 但是,不幸的是,今天我们拥有有效使用
X.509证书 ,CRL,OCSP,TSP,CMP,
CMC ,
CMS消息和大量
PKCS标准的
公钥基础结构 。 因此,如果您要进行与密码学相关的操作,则必须能够使用ASN.1。
ASN.1可以通过多种方式/编解码器进行编码:
- BER (基本编码规则)
- CER (规范编码规则)
- DER (杰出编码规则)
- GSER (通用字符串编码规则)
- JER (JSON编码规则)
- LWER(轻量级编码规则)
- OER (Octet编码规则)
- PER (打包编码规则)
- SER(信令专用编码规则)
- XER (XML编码规则)
和其他一些。 但实际上,在加密任务中,使用了两种:BER和DER。 即使在签名的XML文档(
XMLDSig ,
XAdES )中,仍然会有Base64编码的ASN.1 DER对象,以及Let's Encrypt的基于JSON的
ACME协议。 您可以在文章和书中更好地理解所有这些编解码器以及BER / CER / DER编码原理:
简单的单词是
ASN.1 ,
ASN.1-Olivier Dubuisson的异构系统之间的通信 ,
ASN.1由John Larmouth教授完成 。
BER是面向二进制字节(例如,PER,在移动通信中很流行-面向比特)的TLV格式。 每个元素都以以下形式编码:标记(
T ag),用于标识要编码的元素的类型(整数,字符串,日期等),内容的长度(长度)和内容本身(值)。 BER(可选)允许您通过设置特殊的不确定长度值并以八位字节结尾消息结尾来不指定长度值。 除了长度编码之外,BER在编码数据类型的方法上还有很多可变性,例如:
- 整数,对象标识符,位字符串和元素的长度可能未标准化(未以最小形式编码);
- BOOLEAN适用于任何非零内容;
- BIT STRING可能包含“额外”零位;
- 可以将BIT STRING,OCTET STRING及其所有派生的字符串类型(包括日期/时间)划分为可变长度的块(块),这些块的长度在(de)编码期间是未知的;
- UTCTime / GeneralizedTime可以使用不同的方法来设置时区偏移和“额外”零秒。
- DEFAULT SEQUENCE值可以编码也可以不编码;
- 可以选择对BIT STRING中最后一位的命名值进行编码;
- SEQUENCE(OF)/ SET(OF)可以具有任意顺序的元素。
对于上述所有情况,并非总是可以对数据进行编码,使其与原始格式相同。 因此,发明了规则的一个子集:DER是仅对一种有效编码方法的严格规定,这对于加密任务至关重要,例如,更改一位将使签名或校验和无效。 DER有一个很大的缺点:在编码期间必须预先知道所有元素的长度,这不允许数据的流序列化。 CER编解码器摆脱了这一缺点,类似地保证了数据的明确表示。 不幸的是(幸运的是,我们还没有更复杂的解码器?),它没有流行。 因此,在实践中,我们遇到了BER和DER编码数据的“混合”使用。 由于CER和DER都是BER的子集,因此任何BER解码器都能够对其进行处理。
pyasn1的问题
在工作中,我们编写了许多与密码学有关的Python程序。 几年前,几乎没有免费库可供选择:这些库是非常低级的库,可让您简单地进行编码/解码,例如,整数和结构头,或者是
pyasn1库。 我们使用它已有几年了,最初感到非常满意,因为它允许您将ASN.1结构作为高级对象使用:例如,解码的X.509证书对象允许您通过字典接口访问其字段:cert [“ tbsCertificate”] [“ SerialNumber”]将向我们显示此证书的序列号。 同样,您可以通过与列表,字典一起使用来“收集”复杂的对象,然后仅调用pyasn1.codec.der.encoder.encode函数并获得文档的序列化表示。
但是,发现了弱点,问题和局限性。 不幸的是,仍然存在pyasn1中的错误:在撰写本文时,在pyasn1中,基本类型之一GeneralizedTime被
错误地解码和编码。
在我们的项目中,为了节省空间,我们通常只存储文件的路径,要引用的对象的偏移量和长度(以字节为单位)。 例如,任意签名文件都很可能位于CMS SignedData ASN.1结构中:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL 751 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9
我们可以在65字节长751字节的偏移量处获得原始签名文件。 pyasn1不在其解码对象中存储此信息。 编写了所谓的TLVSeeker-一个小型库,它使您可以解码对象的标签和长度,在我们的界面中,我们命令“转到下一个标签”,“转到标签内”(转到对象的SEQUENCE内),“转到下一个标签”,“告诉您的偏移量和对象所在位置的长度。” 这是对ASN.1 DER序列化数据的“手动”操作。 但是不可能像这样使用BER序列化的数据,因为例如字节字符串OCTET STRING可以编码为几个块。
pyasn1任务的另一个缺点是无法从解码的对象了解SEQUENCE中是否存在给定的字段。 例如,如果结构包含“字段SEQUENCE OF Smth OPTIONAL”字段,则在接收到的数据中它可能会完全不存在(“ OPTIONAL”),但可能存在,但同时长度为零(空列表)。 在一般情况下,这无法澄清。 对于严格检查接收到的数据的有效性,这是必需的。 想象一下,从ASN.1方案的角度来看,证书颁发机构将颁发带有“不完全”有效数据的证书! 例如,证书颁发机构TÜRKTRUSTElektronik Sertifika HizmetSağlayıcısı在其根证书中超出了主题组件的长度所允许的
RFC 5280边界-无法根据方案进行诚实地解码。 DER编解码器要求在传输过程中不对值为DEFAULT的字段进行编码-这样的文档在生活中会遇到,并且PyDERASN的第一个版本甚至出于向后兼容的目的,甚至有意识地允许这种无效的行为(从DER的角度来看)。
另一个限制是无法轻松找出结构中的对象以哪种形式(BER / DER)编码。 例如,CMS标准说该消息是BER编码的,但是用于形成加密签名的signedAttrs字段应该位于DER中。 如果我们使用DER解码,那么我们将依靠CMS本身的处理,如果我们使用BER解码,我们将不知道signedAttrs的形式。 结果,将有必要让TLVSeeker(其类似物不在pyasn1中)搜索每个signedAttrs字段的位置,并且应该由DER从序列化视图中对其进行单独解码。
对于我们来说,非常需要自动处理DEFINED BY字段的可能性非常普遍。 解码ASN.1结构后,可能还有许多ANY字段,应根据根据结构字段中指定的OBJECT IDENTIFIER选择的方案,进一步处理这些字段。 在Python代码中,这意味着编写一个if,然后为ANY字段调用解码器。
PyDERASN的到来
在Atlas中,我们会发现任何问题或修改已使用的免费程序,定期将补丁发送到顶部。 在pyasn1中,我们多次发送了改进,但是pyasn1代码不是最容易理解的,有时其中发生了不兼容的API更改,这使我们感到震惊。 另外,我们习惯用生成式测试来编写测试,而pyasn1中不是这种情况。
有一天,我决定必须忍受这一点,是时候尝试使用__slot __s,offset s和精美显示的blob编写自己的库了! 仅仅创建一个ASN.1编解码器是不够的-您需要将我们所有的依赖项目转移到它,而这是成千上万行代码,其中涉及ASN.1-结构的工作量很大。 这是它的要求之一:易于翻译当前pyasn1代码。 在度过整个假期后,我编写了这个库,并将所有项目转移到该库中。 由于它们的测试覆盖率几乎为100%,因此这也意味着该库可以完全正常运行。
同样,PyDERASN具有几乎100%的测试覆盖率。 生成测试与奇妙的
假设库一起使用。 还对32台核电机进行了
模糊测试。 尽管事实上我们几乎没有剩余的Python2代码,但PyDERASN仍然保持与之的兼容性,因此,它只有
六个依赖项。 此外,还针对
ASN.1:2008符合性测试套件进行了
测试 。
使用它的原理类似于pyasn1-使用高级Python对象。 ASN.1电路的描述与此类似。
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), )
但是,PyDERASN具有强类型的外观。 在pyasn1中,如果该字段的类型为CMSVersion(INTEGER),则可以将其分配为int或INTEGER。 PyDERASN严格要求分配的对象必须是CMSVersion。 除了编写Python3代码外,我们还使用
键入注释 ,因此我们的函数将不会具有诸如def func(序列,内容)之类的难以理解的参数,而是def func(序列:CertificateSerialNumber,内容:EncapsulatedContentInfo),而PyDERASN有助于跟踪此类信息代码。
同时,PyDERASN对此打字非常方便。 pyasn1不允许SubjectKeyIdentifier()子类型(implicitTag = Tag(...))分配SubjectKeyIdentifier()对象(没有必需的IMPLICIT TAG),并且通常仅由于更改了IMPLICIT / EXPLICIT标签而不得不复制和重新创建对象。 PyDERASN严格遵守基本类型-它会自动替换现有ASN.1结构中的标签。 这大大简化了应用程序代码。
如果在解码过程中发生错误,则在pyasn1中很难准确地了解发生错误的位置。 例如,在已经提到的土耳其语证书中,我们得到以下错误:UTF8String(tbsCertificate:issuer:rdnSequence:3:0:value:DEFINED BY 2.5.4.10:utf8String)(at 138)不满意的范围:1⇐77⇐64编写ASN时.1结构可能会出错,并且有助于更轻松地调试应用程序或找出另一面的编码文档问题。
PyDERASN的第一个版本不支持BER编码。 它出现的时间要晚得多,仍然不支持带时区的UTCTime / GeneralizedTime处理。 这将在将来出现,因为该项目主要是在空闲时间编写的。
同样在第一个版本中,没有使用DEFINED BY字段。 几个月后,这种
机会出现并开始被积极使用,从而大大减少了应用程序代码-在一次解码操作中,可以将整个结构分解到最深处。 为此,在方案中,定义哪些字段“确定”。 例如,CMS模式的描述:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), )
表示如果contentType包含带有id_signedData的OID,则需要使用SignedData方案对内容字段(位于同一SEQUENCE中)进行解码。 为什么会有这么多的括号? 一个字段可以同时“定义”多个字段,就像EnvelopedData结构中的情况一样。 定义的字段由所谓的解码路径标识-它设置所有元素在所有结构中的确切位置。
立即将这些定义引入电路中并不总是希望也并非总是可能。 在特定于应用程序的情况下,仅在第三方项目中才知道OID和结构。 PyDERASN提供了在解码结构时指定这些定义的能力:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)})
在这里,我们说在CMS SignedData中为所有附加的证书解码所有扩展名(AuthorityKeyIdentifier,BasicConstraints,SubjectSignTool等)。 我们通过解码路径指示要“替换”的元素是定义的,就像在电路中定义的一样。
最后,PyDERASN能够
从命令行工作以解码ASN.1文件,并具有丰富的
漂亮打印效果 。 您可以解码任意的ASN.1,也可以指定明确定义的方案,然后看到类似以下内容的内容:
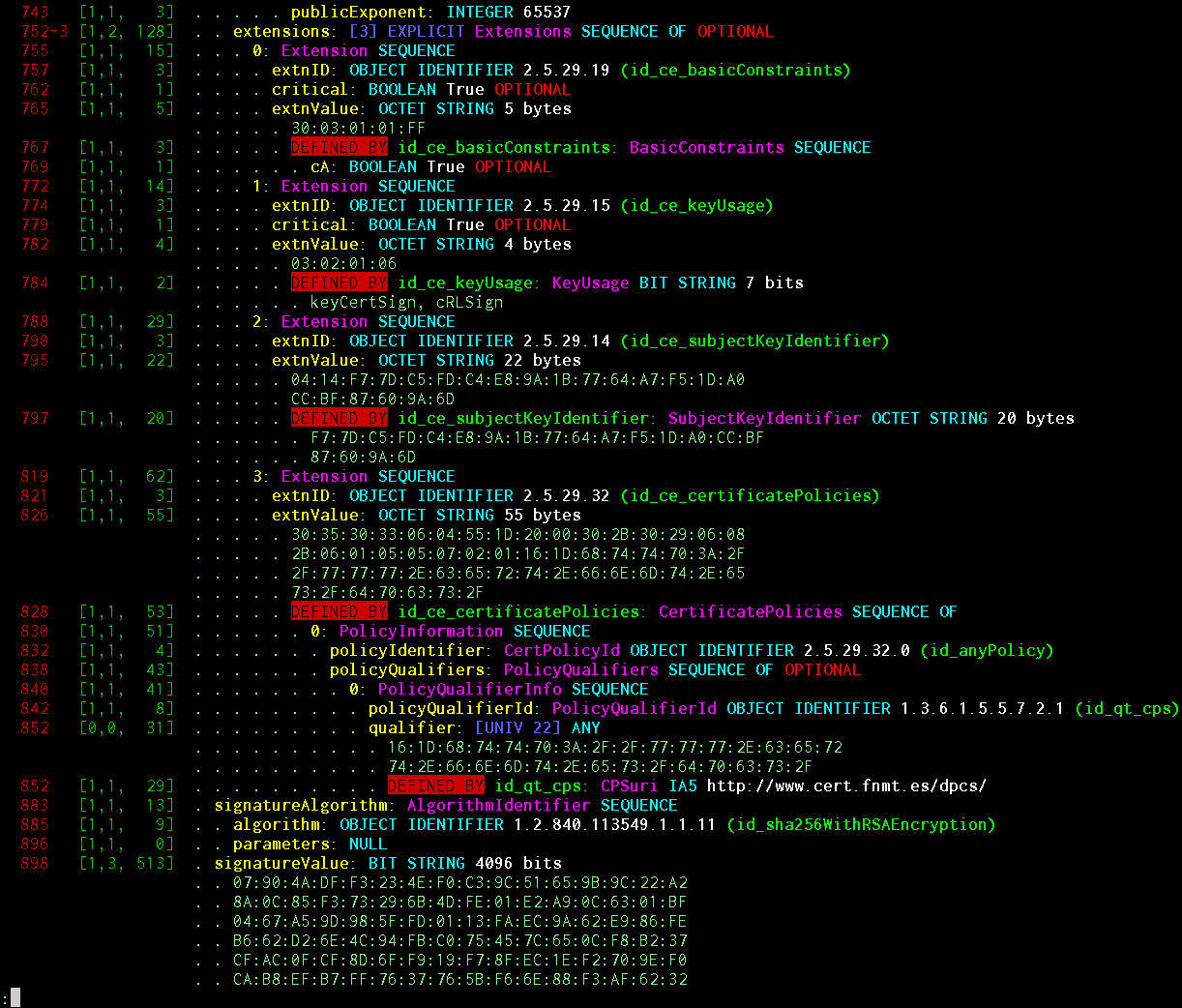
显示的信息:对象偏移量,标签长度,长度长度,内容长度,是否存在EOC(八位字节结尾),BER编码标志,不定长度编码标志,EXPLICIT标签长度和偏移量(如果有),对象嵌套深度结构,IMPLICIT / EXPLICIT标签值,根据方案的对象名称,其基本ASN.1类型,SEQUENCE / SET OF中的序列号,值选择(如果有),根据方案可读的名称INTEGER / ENUMERATED / BIT STRING,任何基本类型的值,电路中的DEFAULT / OPTIONAL标志,表明该对象已自动解码为DEFINED BY 总经理OID和它发生了,chelovekochitaemy OID。
漂亮的打印系统是专门制作的,因此它会生成一系列的PP对象,这些对象已经通过单独的方式进行了可视化处理。 屏幕截图以纯彩色文本显示了渲染器。 有JSON / HTML格式的渲染器,因此可以在
asn1js项目中的ASN.1浏览器中突出显示。
其他图书馆
这不是目标,但PyDERASN的
速度明显高于pyasn1。 例如,解码兆字节大小的CRL文件可能花费很长时间,因此您必须考虑用于存储数据的中间格式(快速)并更改应用程序的体系结构。 pyasn1在我的笔记本电脑上解码CRL
CACert.org超过20分钟,而PyDERASN只需28秒! 有一个
asn1crypto项目旨在快速处理密码结构:它在29秒内(完全而不是偷懒地)解码相同的CRL,但是在Python3下运行时它消耗几乎两倍的RAM(983 MiB与498),在Python2下是3.5倍(1677对488),而pyasn1的消耗则是4.3倍(2093对488)。
我没有提到asn1crypto,我们没有考虑,因为该项目尚处于起步阶段,我们还没有听说过。 现在他们也不会朝他的方向看,因为我立即发现他不接受相同的GeneralizedTime,并且在序列化期间他默默地删除了几分之一秒。 这对于使用X.509证书是可以接受的,但是通常不起作用。
目前,PyDERASN是我所知道的最严格的免费Python / Go DER解码器。 在我最喜欢的Go语言的encoding / asn1库中,
没有严格检查 OBJECT IDENTIFIER和UTCTime / GeneralizedTime字符串。 有时严格性可能会造成干扰(首先,由于与没有人会解决的旧应用程序的向后兼容性),因此在PyDERASN解码期间,您可以通过
各种削弱
设置的设置 。
项目代码尝试尽可能简单。 整个库是一个文件。 该代码的编写着重于易于理解,没有不必要的性能和DRY代码优化。 正如我已经说过的那样,它不支持UTCTime / GeneralizedTime字符串以及REAL,RELATIVE OID,EXTERNAL,INSTANCE OF,EMPDDDED PDV,CHARACTER STRING数据类型的完整BER解码。 就其他所有情况而言,我个人没有理由在Python中使用其他库。
像我所有的项目一样,例如
PyGOST ,
GoGOST ,
NNCP ,
GoVPN ,PyDERASN是根据
LGPLv3 +条款分发的完全
免费的软件 ,可以免费下载。 在
PyGOST测试中可以
找到使用示例。
Sergey Matveev ,
密码银行 ,
开放社会 基金会基金会成员,Python / Go-developer,
FSUE“ STC Atlas”首席专家。