
大家好! 我叫Sergey Kostanbaev,在交易所,我正在开发交易系统的核心。
当纽约证券交易所在好莱坞电影中放映时,它总是像这样:人群大声喊叫,挥舞着纸片,完全混乱。 我们从来没有在莫斯科交易所上交易过,因为几乎从一开始,交易都是以电子方式进行的,并且基于两个主要平台-光谱(衍生品市场)和ASTS(货币,股票和货币市场)。 今天,我想谈谈ASTS交易和清算系统架构的发展,以及各种解决方案和发现。 这个故事很长,所以我不得不将其分为两个部分。
我们是世界上为数不多的可交易所有类别资产并提供全方位交易所服务的交易所之一。 例如,去年,我们在债券交易量方面排名世界第二,在所有证券交易所中排名第二十五,在公共交易所中的资本总额排名中排名第十三。
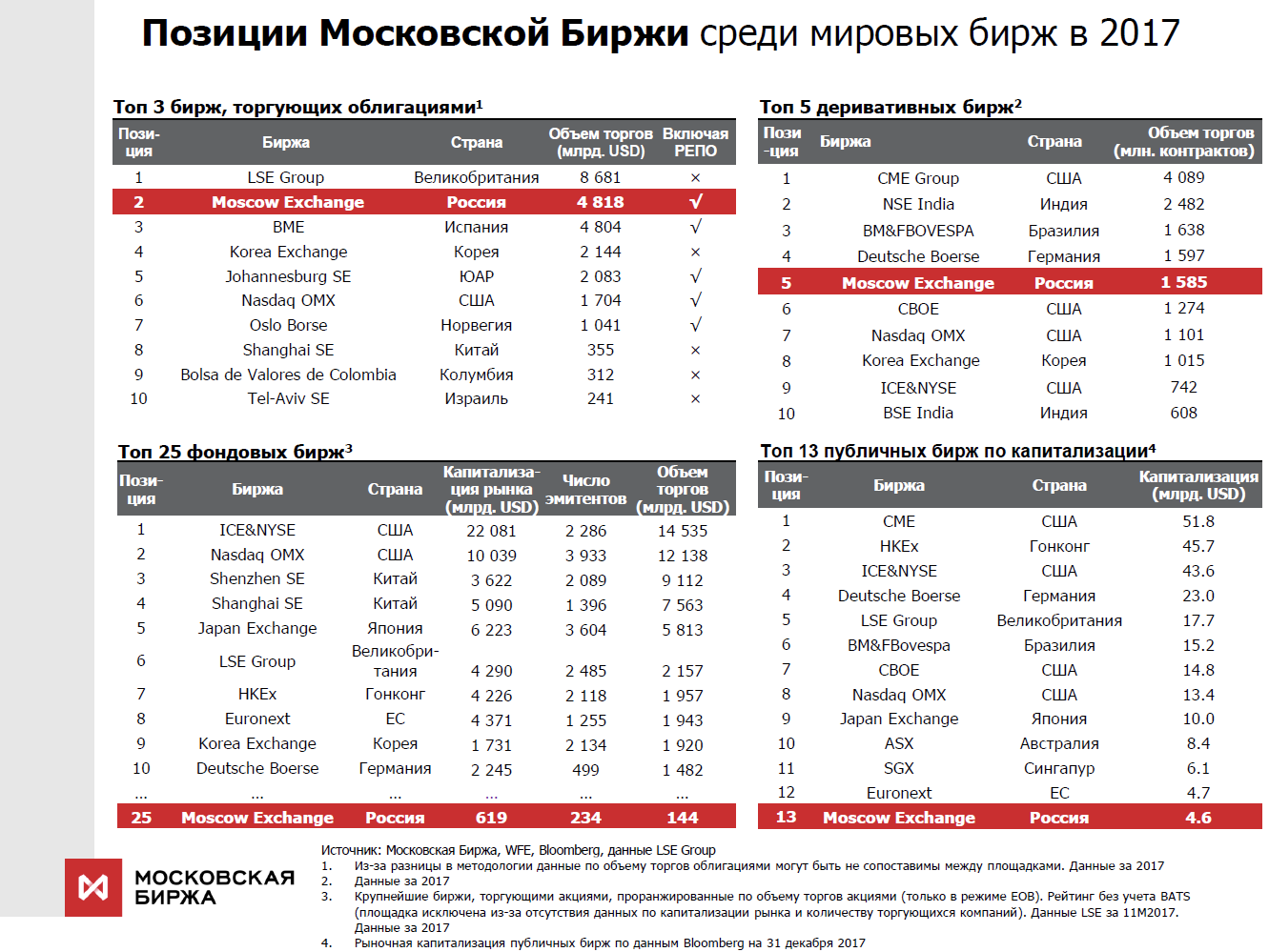
对于专业竞标者而言,诸如响应时间,时间分布的稳定性(抖动)和整个建筑群的可靠性等参数至关重要。 目前,我们每天处理数千万笔交易。 系统核心对每个事务的处理需要数十微秒。 当然,在新年期间使用移动运营商或使用搜索引擎,负载本身要比我们高,但就负载而言,再加上上述特征,在我看来,很少有人能与我们相比。 同时,对我们来说重要的是,系统不会减速一秒钟,绝对稳定,并且所有用户都处于相同的条件下。
一点历史
1994年,在莫斯科银行间货币兑换(MICEX)上启动了澳大利亚ASTS系统,从这一刻起您就可以了解俄罗斯的电子交易历史。 1998年,交易所的体系结构进行了现代化,以引入互联网交易。 从那时起,在所有系统和子系统中引入新解决方案和体系结构更改的速度才刚刚开始。
在那些年中,交换系统在高端硬件上运行-高度可靠的HP Superdome 9000服务器(基于
PA-RISC架构 ),其中几乎所有内容都被复制:输入输出子系统,网络,RAM(实际上,RAM中有RAID阵列) ),处理器(支持热插拔)。 可以在不停止机器的情况下更改服务器的任何组件。 我们依靠这些设备,认为它们几乎没有故障。 操作系统是类Unix的HP UX。
但是从2010年左右开始,出现了简单地说就是交换机器人的高频交易(HFT)或高频交易之类的现象。 在短短2.5年内,我们服务器上的负载增加了140倍。
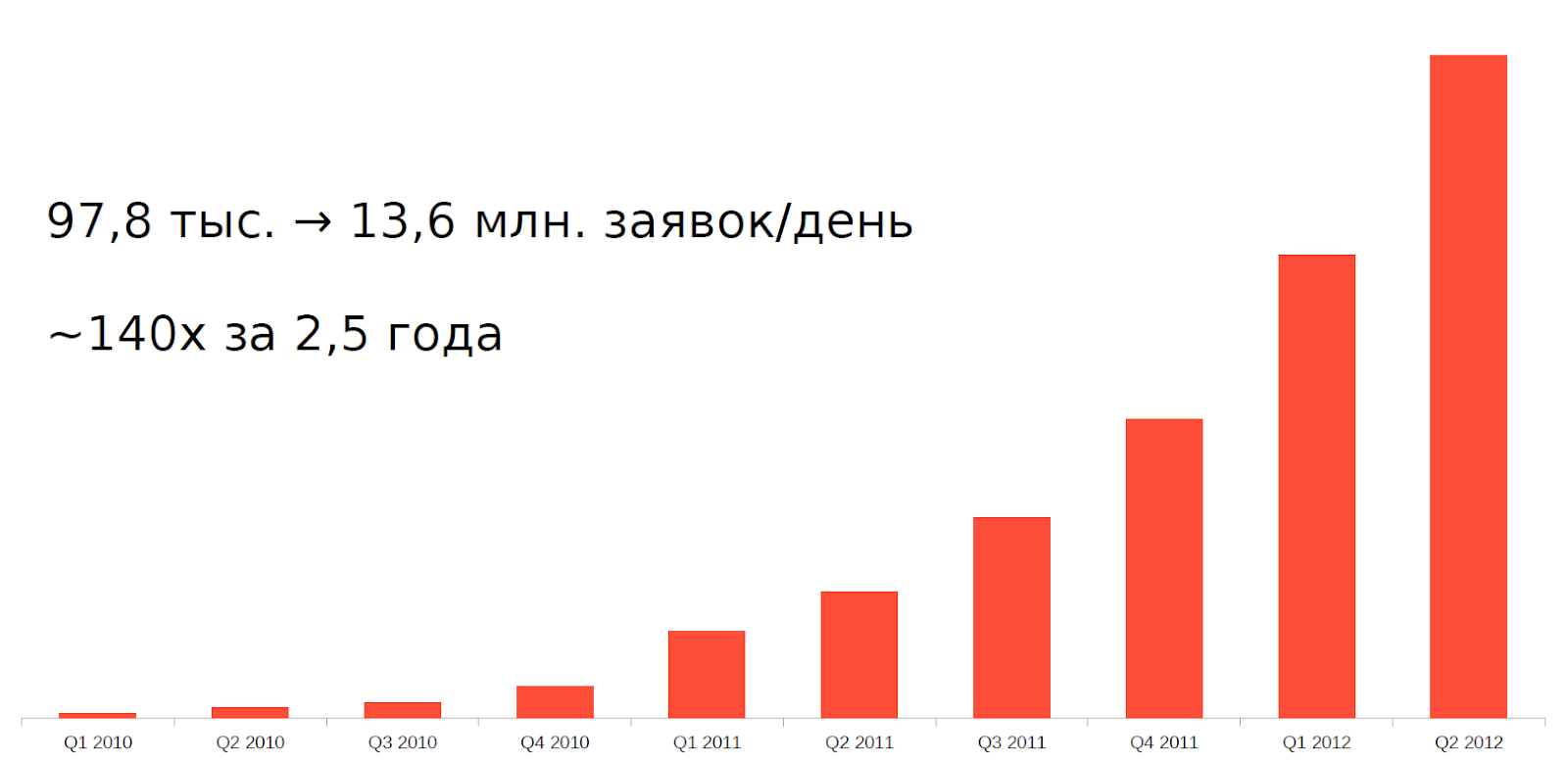
用旧的体系结构和设备来承受这样的负担是不可能的。 有必要以某种方式进行调整。
开始
到交换系统的请求可以分为两种类型:
- 交易次数 如果您想购买美元,股票或其他东西,请将交易发送到交易系统并获得成功的响应。
- 信息请求。 如果您想知道当前价格,请查看订单簿或索引,然后发送信息请求。
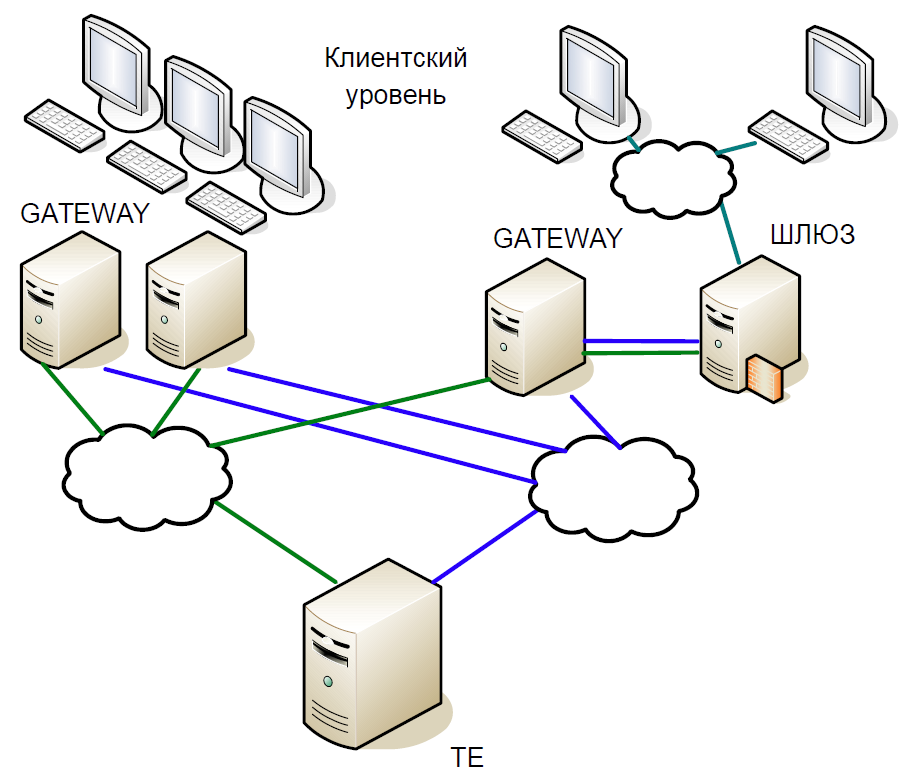
从原理上讲,系统的核心可以分为三个级别:
- 经纪人和客户工作所在的客户级别。 它们都与访问服务器交互。
- 访问服务器(网关)是在本地处理所有信息请求的缓存服务器。 是否想知道Sberbank股票现在的交易价格? 该请求将发送到访问服务器。
- 但是,如果您想购买股票,则请求已在中央服务器(交易引擎)上。 每种市场都有一个这样的服务器,它们扮演着至关重要的角色,正是出于他们的缘故,我们创建了这个系统。
交易系统的核心是一个棘手的内存数据库,其中所有交易都是交易所交易。 该库使用C语言编写,外部依赖项只有libc库,并且完全没有动态内存分配。 为了减少处理时间,系统从一组静态数组和一组静态数据开始:首先,将当天的所有数据加载到内存中,然后再无磁盘访问,所有工作仅在内存中完成。 当系统启动时,所有参考数据均已排序,因此搜索非常有效,并且在运行时花费的时间很少。 所有表都由用于动态数据结构的侵入式列表和树组成,因此它们在运行时不需要内存分配。
让我们简要回顾一下交易和清算系统的发展历史。
交易和清算系统架构的第一个版本建立在所谓的Unix交互基础上:使用共享内存,信号量和队列,并且每个进程都由一个线程组成。 这种方法在1990年代初期很普遍。
该系统的第一个版本包含两个级别的网关和交易系统的中央服务器。 工作方案如下:
- 客户端发送一个命中网关的请求。 他检查格式的有效性(但不检查数据本身),并拒绝错误的事务。
- 如果已发送信息请求,则在本地执行; 如果是事务,则将其重定向到中央服务器。
- 然后,交易引擎处理交易,更改本地内存并向交易及其本身发送响应,以使用单独的复制机制进行复制。
- 网关从中央节点接收响应,并将其重定向到客户端。
- 一段时间后,网关使用复制机制接收事务,这次它将在本地执行该事务,更改其数据结构,以便以下信息请求显示实际数据。
实际上,这里描述了复制模型,其中网关完全重复了在交易系统中执行的操作。 单独的复制通道在多个访问节点上提供了相同的事务执行顺序。
由于代码是单线程的,因此使用具有分叉进程的经典方案为许多客户端提供服务。 但是,为整个数据库创建一个分叉非常昂贵,因此使用了轻量级的服务进程,该进程从TCP会话收集数据包并将其传输到一个队列(SystemV消息队列)。 Gateway和Trade Engine仅与此队列配合使用,从那里获取要执行的交易。 已经不可能发送答案了,因为尚不清楚哪个服务进程应该读取它。 因此,我们采取了一种技巧:每个分叉的进程都会为其自身创建一个响应队列,并且当请求进入传入队列时,将立即为该响应队列添加一个标记。
从队列到大量数据的队列中不断复制会产生问题,尤其是信息请求的特征。 因此,我们利用了另一个技巧:除了响应队列,每个进程还创建了共享内存(SystemV共享内存)。 程序包本身被放置在其中,并且只有标记被保存在队列中,使您可以找到源程序包。 这有助于将数据存储在处理器缓存中。
SystemV IPC包括用于查看队列,内存和信号量对象状态的实用程序。 我们积极使用此功能是为了了解特定时刻系统中发生的情况,数据包正在累积,被阻塞等。
第一次现代化
首先,我们摆脱了单进程网关。 它的主要缺点是它可以处理来自客户端的一个复制事务或一个信息请求。 随着负载的增加,网关将处理更长的请求,并且将无法处理复制流。 另外,如果客户发送了交易,则您只需检查其有效性并进一步转发。 因此,我们用许多可以并行工作的组件代替了一个网关进程:多线程信息和事务进程,它们使用RW锁在公共内存区中彼此独立工作。 同时,我们引入了调度和复制过程。
高频交易的影响
以上版本的体系结构一直持续到2010年。 同时,我们对HP Superdome服务器的性能不再满意。 此外,PA-RISC体系结构实际上已经失效;供应商未提供任何重大更新。 结果,我们开始从HP UX / PA RISC切换到Linux / x86。 过渡始于适应访问服务器。
为什么我们必须再次更改架构? 事实是,高频交易已大大改变了系统核心的负载状况。
假设我们进行的一笔小交易导致价格发生了重大变化-有人购买了十亿美元。 几毫秒后,所有市场参与者都注意到了这一点并开始进行纠正。 自然,请求排成一个大队列,系统将长时间抽出这些队列。

以50毫秒的间隔,平均速度约为每秒16,000个事务。 如果将窗口减小到20毫秒,则平均速度为每秒9万笔事务,在高峰时将有20万笔事务。 换句话说,负载是不稳定的,具有尖锐的突发。 并且请求队列应始终快速处理。
但是,为什么要排队呢? 因此,在我们的示例中,许多用户注意到价格变化并发送了相应的交易。 那些进入网关,他将它们序列化,设置一定的顺序,然后将它们发送到网络。 路由器混合数据包并转发它们。 谁的包裹来得早,那笔交易“赢了”。 结果,交易所客户开始注意到,如果同一笔交易是从多个网关发送的,则其快速处理的机会就会增加。 不久,交换机器人开始用请求轰炸Gateway,并引发了大量的交易。

新一轮的发展
经过广泛的测试和研究,我们切换到了操作系统的实时内核。 为此,他们选择了RedHat Enterprise MRG Linux,其中MRG代表消息实时网格。 实时补丁程序的优势在于它们优化了系统,以实现最快的执行速度:所有进程都排列在FIFO队列中,您可以隔离内核,没有丢弃,所有事务都按照严格的顺序进行处理。
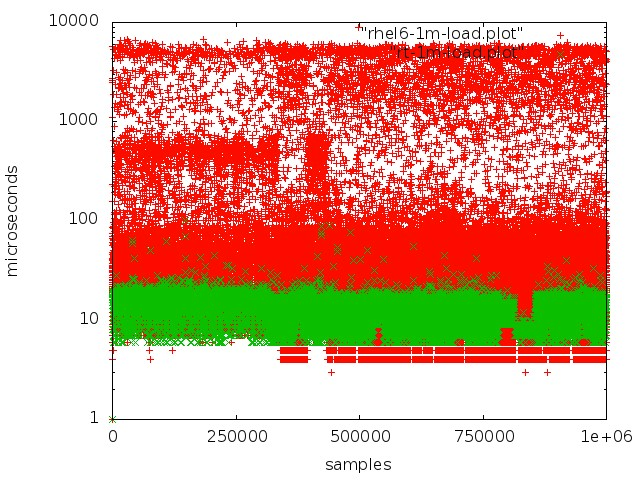 红色-在常规内核中使用队列,绿色-在实时内核中使用。
红色-在常规内核中使用队列,绿色-在实时内核中使用。但是在常规服务器上实现低延迟并不是那么简单:
- 在x86体系结构中,SMI模式是与重要外围设备一起工作的核心,它会产生很大的干扰。 固件以所谓的透明SMI模式执行处理各种硬件事件并管理组件和设备,在这种模式下,操作系统根本看不到固件在做什么。 通常,所有主要的供应商都为固件服务器提供特殊的扩展,从而可以减少SMI处理量。
- 不应动态控制处理器频率,这会导致额外的停机时间。
- 重置文件系统日志后,内核中会发生某些进程,这些进程会导致无法预测的延迟。
- 您需要注意诸如CPU Affinity,Interruptfinity,NUMA之类的事情。
我必须说,配置Linux硬件和内核以进行实时处理的主题值得一提。 在取得良好结果之前,我们花费了大量时间进行实验和研究。
从PA-RISC服务器切换到x86时,实际上我们不需要太多更改系统代码,我们只需对其进行修改和重新配置。 同时,修复了一些错误。 例如,很快出现了后果,即PA RISC是Big endian系统,而x86是Little endian系统:例如,数据未正确读取。 一个更棘手的错误是,PA RISC使用
顺序一致的内存访问,而x86可以对读取操作进行重新排序,因此在一个平台上绝对有效的代码在另一个平台上无法使用。
切换到x86后,生产率几乎提高了三倍,平均事务处理时间减少到60μs。
现在,让我们仔细研究一下对系统体系结构进行了哪些关键更改。
热备史诗
对于商品服务器,我们意识到它们的可靠性较差。 因此,在创建新架构时,我们先验地假设了一个或多个节点发生故障的可能性。 因此,我们需要一个能够快速切换到备份计算机的热备用系统。
此外,还有其他要求:
- 在任何情况下都不会丢失已处理的交易。
- 该系统必须对我们的基础架构绝对透明。
- 客户端不应看到连接中断。
- 预订不应引起明显的延迟,因为这是交换的关键因素。
在创建热备用系统时,我们并未将此类情况视为双重故障(例如,一台服务器上的网络停止工作且主服务器挂起)。 未考虑软件错误的可能性,因为它们是在测试期间发现的; 并没有考虑铁的故障。
结果,我们得出以下方案:
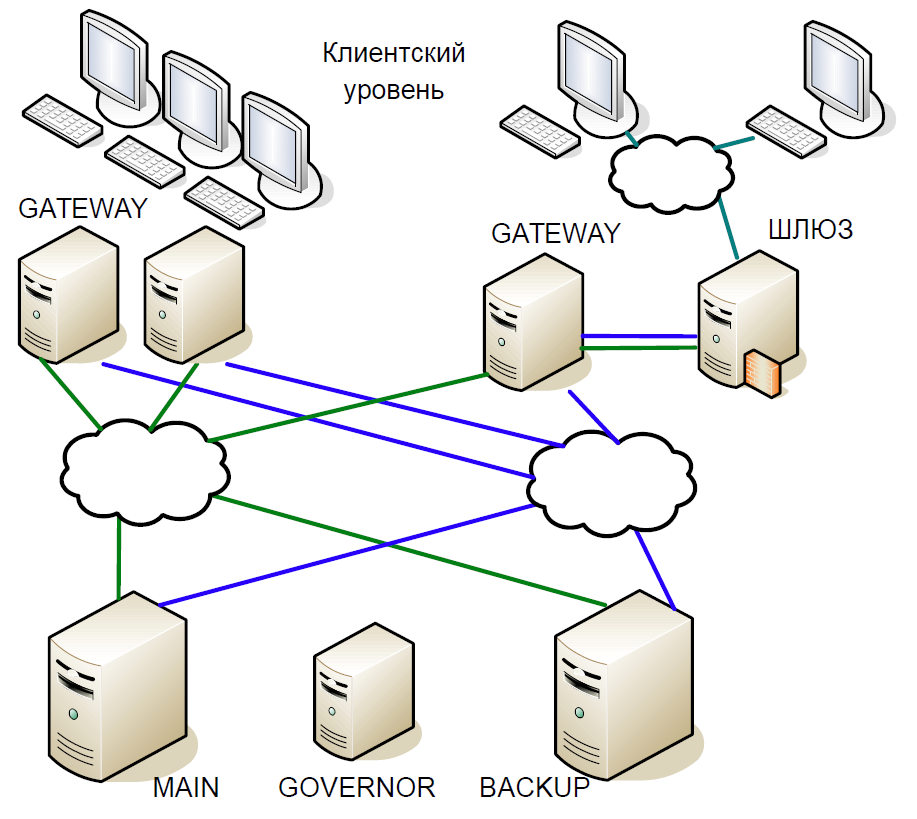
- 主服务器直接与网关服务器进行交互。
- 主服务器上收到的所有事务都立即通过单独的通道复制到备用服务器。 发生任何问题时,裁判(州长)协调开关。
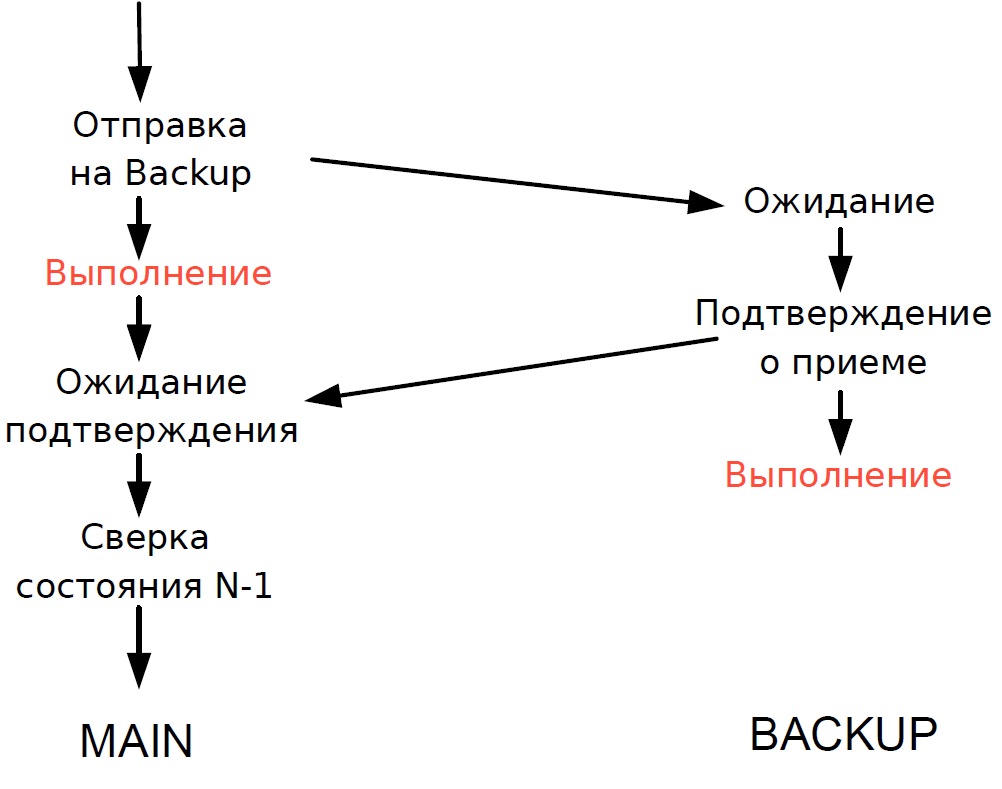
- 主服务器处理每个事务,并等待备份服务器的确认。 为了最大程度地减少延迟,我们拒绝等待备份服务器上的事务完成。 由于通过网络进行的事务处理的持续时间可与事务处理的持续时间相媲美,因此无需添加其他延迟。
- 我们只能验证前一个事务的主服务器和备用服务器的处理状态,而当前事务的处理状态是未知的。 由于此处仍使用单线程进程,因此等待Backup的响应会减慢整个处理流程,因此我们做出了合理的妥协:我们检查了上一个事务的结果。

该方案如下。
假设主服务器停止响应,但是网关继续通信。 在备用服务器上,将触发超时,该超时将变为总督,然后他为他分配了主服务器的角色,并且所有网关都切换到了新的主服务器。
如果主服务器恢复运行,则还会在其上触发内部超时,因为一段时间以来,网关都没有对服务器的调用。 然后,他也转向州长,将他排除在计划之外。 结果,该交换只能在一台服务器上工作,直到交易期结束。 由于服务器崩溃的可能性很小,因此这种方案被认为是可以接受的,它不包含复杂的逻辑并且易于测试。
待续。