
这是关于我们艰难的道路的长篇故事的延续,这是我们艰难的道路上的工作,以创建一个功能强大的,高负载的系统来确保Exchange的运行。
第一部分在这里 。
神秘的错误
经过大量测试后,更新的交易和清算系统投入运行,我们遇到了一个错误,关于写一个神秘的侦探故事是正确的。
在主服务器上启动后不久,其中一个事务已处理,但出现错误。 同时,一切都在备份服务器上进行。 事实证明,在主服务器上计算指数的简单数学运算会因有效参数而给出负结果! 继续进行调查,并在SSE2寄存器中发现一位的差异,这是在使用浮点数时四舍五入的原因。
他们编写了一个简单的测试实用程序,用于计算设置了舍入位的指数。 事实证明,在我们使用的RedHat Linux版本中,当插入错误的位时,使用数学函数存在一个错误。 过一会儿,我们从RedHat上报告了此补丁并将其滚动。 该错误不再发生,但是不清楚该位来自何处? 我们由C的
fesetround函数负责,我们仔细分析了代码,以查找所谓的错误:检查所有可能的情况; 考虑了所有使用舍入的函数; 尝试播放失败的会话; 使用具有不同选项的不同编译器; 用于静态和动态分析。
找不到错误的原因。
然后他们开始检查硬件:他们进行了处理器的负载测试; 检查RAM; 甚至针对一个单元中发生多比特错误的极不可能的情况进行了测试。 无济于事。
最后,他们采用了高能物理世界的理论:一些高能粒子飞入了我们的数据中心,冲破了机壳的壁,撞击了处理器,并使触发闩锁卡在同一位。 这种荒谬的理论被称为“中微子”。 如果您离基本粒子物理学还很远:中微子几乎不会与外界相互作用,并且当然它们不会影响处理器。
由于无法找到故障原因,以防万一他们将“延迟”服务器排除在外。
一段时间后,我们开始改进热备用系统:我们引入了所谓的“暖备用”(异步副本)。 他们收到了可能在不同数据中心中的交易流,但是warm不支持与其他服务器的主动交互。
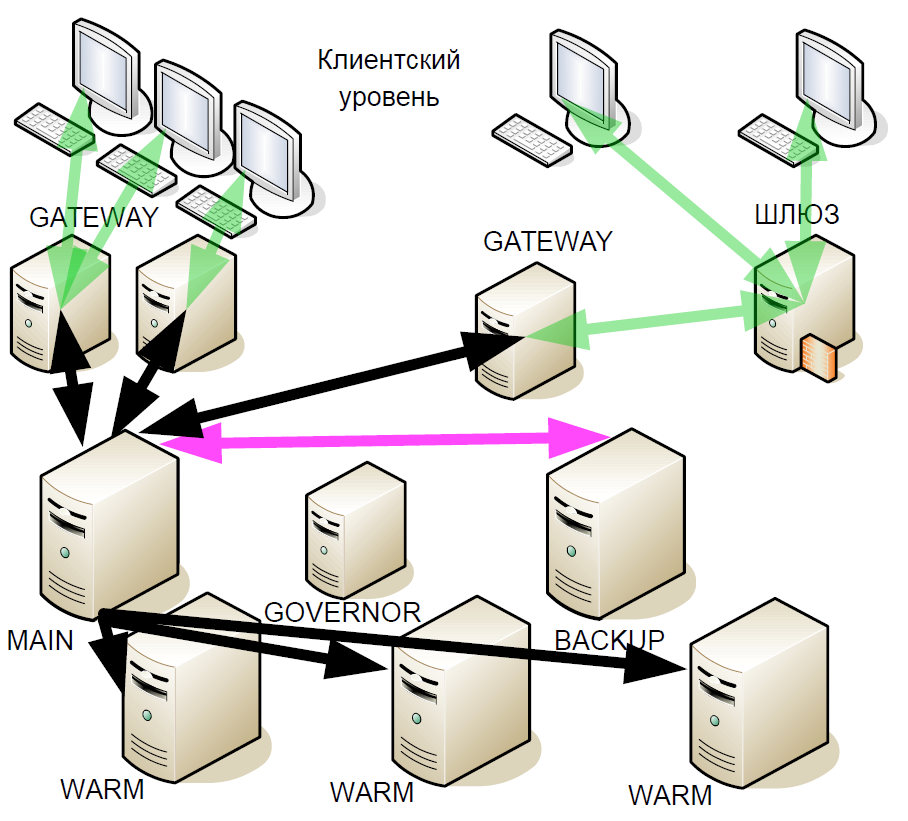
为什么这样做? 如果备份服务器发生故障,则热绑定到主服务器将成为新的备份。 也就是说,在发生故障之后,直到与一台主服务器的交易会话结束,系统才会保留下来。
当新版本的系统经过测试并投入运行时,再次发生了带有舍入位的错误。 此外,随着热服务器数量的增加,错误开始更加频繁地出现。 在这种情况下,由于没有具体证据,供应商无可奉告。
在对情况进行下一次分析时,出现了理论认为该问题可能与操作系统有关。 我们编写了一个简单的程序,该程序在无限循环中调用
fesetround函数,记住当前状态并通过睡眠对其进行检查,这是在许多竞争线程中完成的。 选择了睡眠参数和线程数后,在实用程序运行约5分钟后,我们开始稳定地重现位故障。 但是,Red Hat支持无法复制它。 对我们其他服务器的测试表明,只有那些安装了某些处理器的服务器受此错误影响。 同时,向新内核的过渡解决了该问题。 最后,我们只是更换了操作系统,该错误的真正原因仍不清楚。
去年突然间,一篇文章发表在哈布雷(Habré)上“
我如何发现英特尔Skylake处理器中的错误 ”。 其中描述的情况与我们的情况非常相似,但是作者在调查中进一步提出了建议,并提出了错误在微代码中的理论。 而且,在更新Linux内核时,制造商也会更新微码。
系统的进一步发展
尽管我们摆脱了错误,但这个故事使我们再次重新考虑了系统的体系结构。 毕竟,我们并没有受到保护,避免重复出现此类错误。
以下原则构成了进一步改进备份系统的基础:
- 你不能相信任何人。 服务器可能无法正常工作。
- 多数冗余。
- 共识建设。 作为多数冗余的逻辑补充。
- 可能会出现双重故障。
- 活力。 新的热备用方案应该不会比以前的方案差。 交易应该顺利进行到最后一个服务器。
- 延迟略有增加。 任何停机时间都会造成巨大的财务损失。
- 网络交互最少,以使延迟尽可能低。
- 在几秒钟内选择一个新的主服务器。
市场上没有可用的解决方案适合我们,并且Raft协议还处于起步阶段,因此我们创建了自己的解决方案。

网络连接
除了备份系统,我们还开始对网络连接进行现代化。 I / O子系统是多个进程,以最坏的方式影响了抖动和延迟。 由于拥有数百个处理TCP连接的进程,我们不得不在它们之间不断进行切换,并且在微微秒的规模上,这是一个相当长的操作。 但是最糟糕的是,当进程接收到要处理的数据包时,会将其发送到一个SystemV队列,然后等待来自另一个SystemV队列的事件。 但是,对于大量节点,一个过程中新TCP数据包的到达和另一个过程中队列中数据的接收代表了OS的两个竞争事件。 在这种情况下,如果两个任务都没有可用的物理处理器,则将处理一个,而第二个将处于等待队列中。 无法预测后果。
在这种情况下,您可以应用动态进程优先级控制,但这将需要使用资源密集型系统调用。 结果,我们使用经典的epoll切换到一个线程,这大大提高了速度并减少了事务处理时间。 我们还摆脱了某些网络交互过程以及通过SystemV进行交互的过程,大大减少了系统调用次数,并开始控制操作的优先级。 仅使用一个I / O子系统,就可以节省大约8-17微秒,具体取决于场景。 此单线程方案此后未更改,一个带有余量的epoll流足以服务所有连接。
交易处理
我们系统上日益增长的负载要求对其几乎所有组件进行现代化。 但是,不幸的是,近年来处理器时钟速度的增长停滞不前,这使我们不再能够“直面”扩展流程。 因此,我们决定将Engine流程分为三个级别,其中最重的是风险验证系统,该系统评估帐户中资金的可用性并自行创建交易。 但是钱可以是不同的货币,因此有必要弄清楚划分请求处理的原则。
合理的解决方案是按货币划分:一台服务器以美元交易,另一台服务器以英镑交易,第三台欧元交易。 但是,如果采用这种方案,发送了两笔交易以购买不同的货币,那么就会出现钱包不同步的问题。 并且同步是困难且昂贵的。 因此,分别在钱包和工具上分片是正确的。 顺便说一下,在大多数西方交易所中,检查风险的任务并不像我们的任务那么紧急,因此大多数情况下都是脱机完成的。 我们需要实施在线检查。
让我们举例说明。 交易者想购买30美元,然后请求验证交易:我们检查该交易者是否被允许进入这种交易模式,他是否具有必要的权利。 如果一切正常,则请求转到风险验证系统,即 验证资金是否足够完成交易。 请注意,目前已冻结所需的金额。 此外,请求被重定向到交易系统,该交易系统批准或不批准该交易。 假设交易被批准-然后风险验证系统注意到这笔钱已解锁,卢布被转换成美元。
通常,风险验证系统包含复杂的算法,并且执行大量非常耗费资源的计算,并且乍一看似乎并不仅仅检查“帐户余额”。
当我们开始将Engine流程划分为多个级别时,我们遇到了一个问题:当时在验证和验证阶段可用的代码主动使用了相同的数据数组,这需要重写整个代码库。 结果,我们借用了一种从现代处理器中处理指令的方法:每个处理器都被划分为多个小阶段,并且在一个周期内并行执行多个动作。
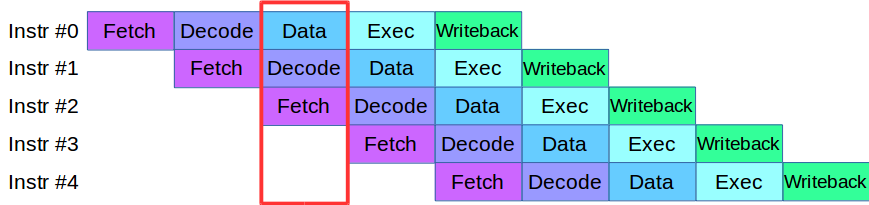
稍作修改后,我们创建了一个用于并行处理事务的管道,其中将事务分为四个阶段:网络交互,验证,执行和结果发布

考虑一个例子。 我们有两个处理系统,串行和并行。 第一个事务到达,并且在两个系统中都进行验证。 然后第二个事务到达:在并行系统中,它立即被使用,在顺序系统中,它被排队等待第一个事务通过当前处理阶段。 也就是说,流水线的主要优点是我们可以更快地处理事务队列。
因此,我们获得了ASTS +系统。
没错,对于传送带来说,并非一切都那么顺利。 假设我们有一个事务会影响相邻事务中的数据数组,这是交换的典型情况。 此类事务无法在管道中执行,因为它会影响其他事务。 这种情况称为数据危险,这种事务将简单地单独处理:当队列中的“快速”事务结束时,流水线停止,系统处理“慢”事务,然后再次启动管道。 幸运的是,此类事务在总流量中所占的份额很小,因此管道停止的次数很少,因此不会影响整体性能。

然后我们开始解决同步三个执行线程的问题。 结果,诞生了基于具有固定大小单元的圆形缓冲区的系统。 在此系统中,一切都取决于处理速度,不会复制数据。
- 所有传入的网络数据包都进入分配阶段。
- 我们将它们放置在数组中,并标记它们可用于第1阶段。
- 第二笔交易来了,它又可用于第一阶段。
- 第一个处理流程查看可用的事务,对其进行处理,然后将其转移到第二个处理流程的下一个阶段。
- 然后,它处理第一个事务,并用Deleted标志标记相应的单元格-现在可以用于新用途。
因此,整个队列得到处理。
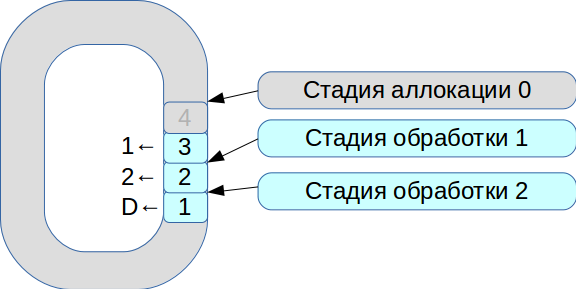
每个阶段的处理需要花费单位或数十微秒。 而且,如果您使用标准的OS同步方案,那么我们将在同步本身上浪费更多时间。 因此,我们开始使用自旋锁。 但是,这在实时系统中是一个非常糟糕的音调,RedHat强烈建议不要这样做,因此我们使用自旋锁100毫秒,然后进入信号量模式以排除出现死锁的可能性。
结果,我们实现了每秒约800万笔交易的性能。 仅仅两个月后,在有关LMAX Disruptor的
文章中 ,他们看到了具有相同功能的电路的描述。
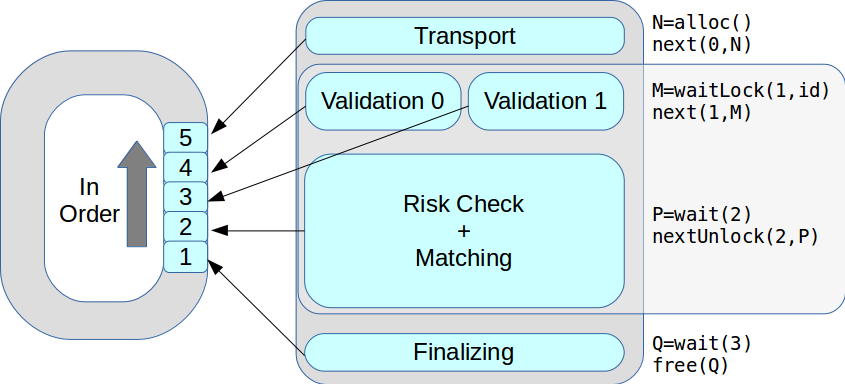
现在在某一阶段可能会有多个执行线程。 所有事务按接收顺序依次处理。 结果,最高性能从每秒18000个增加到5万个事务。
外汇风险管理系统
完美无止境,不久我们又开始现代化:在ASTS +的框架内,我们开始将风险管理系统和结算业务转移到自治的组件中。 我们开发了灵活的现代体系结构和新的分层风险模型,并尽可能尝试使用
fixed_point类而不是
double 。
但是立即出现了问题:如何同步已经使用了多年的所有业务逻辑并将其转移到新系统? 结果,必须放弃新系统原型的第一版。 目前正在生产中的第二个版本基于在交易部分和风险部分中均有效的相同代码。 在开发过程中,最困难的是使git在两个版本之间合并。 我们的同事Evgeny Mazurenok每周都会执行此操作,并且每次都被诅咒很长时间。
在选择新系统时,我们立即必须解决交互问题。 选择数据总线时,必须确保稳定的抖动和最小的延迟。 为此,InfiniBand RDMA网络最适合:平均处理时间比10 G以太网少4倍。 但是真正的区别在于百分位数-99和99.9。
当然,InfiniBand有其自身的困难。 首先,另一个API是ibverbs而不是套接字。 其次,几乎没有广泛可用的开源消息传递解决方案。 我们试图制造原型,但事实证明这非常困难,因此我们选择了一种商业解决方案-Confinity低延迟消息传递(以前称为IBM MQ LLM)。
然后出现了风险系统正确分离的问题。 如果您仅取出风险引擎而不是中间节点,则可以混合来自两个来源的交易。
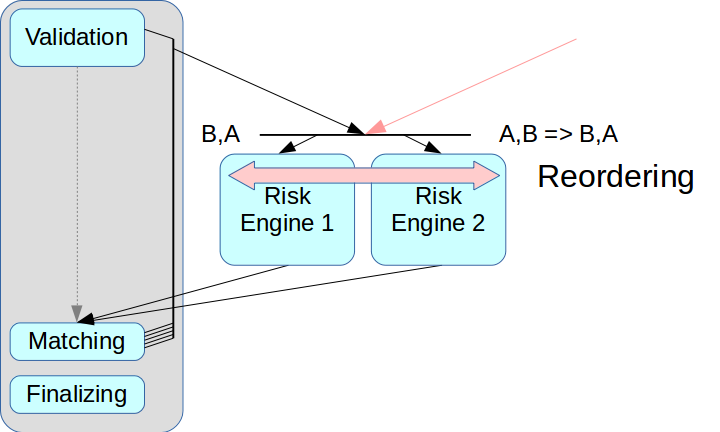
所谓的超低延迟解决方案具有重新排序模式:来自两个源的事务可以在收到后按正确的顺序排列,这是使用单独的通道交换有关序列的信息来实现的。 但是我们还没有应用这种模式:它使整个过程变得复杂,并且在某些解决方案中它根本不被支持。 另外,必须为每个事务分配适当的时间戳,在我们的方案中,此机制很难正确实现。 因此,我们将经典方案与消息代理一起使用,即与在Risk Engine之间分发消息的调度程序一起使用。
第二个问题与客户端访问有关:如果有多个风险网关,则客户端需要连接到它们中的每个网关,为此,您必须对客户端层进行更改。 我们希望在此阶段避免这种情况,因此在当前的Risk Gateway方案中,它们将处理整个数据流。 这严重限制了最大吞吐量,但大大简化了系统集成。
复制品
我们的系统不应有单点故障,也就是说,必须复制所有组件,包括消息代理。 我们使用CLLM系统解决了这个问题:它包含一个RCMS群集,其中两个调度程序可以在主从模式下工作,当一个调度程序发生故障时,系统会自动切换到另一个调度程序。
与备份数据中心一起使用
InfiniBand经过优化,可以用作本地网络,即连接机架安装设备,并且无法在两个地理上分散的数据中心之间铺设InfiniBand网络。 因此,我们实现了一个桥接器/调度程序,该桥接器/调度程序通过常规的以太网网络连接到消息存储,并将所有事务中继到第二个IB网络。 当您需要从数据中心迁移时,我们可以选择现在要使用的数据中心。
总结
上面的所有操作不是一次完成的,它花费了新架构开发的多次迭代。 我们在一个月内创建了原型,但花了两年多的时间才能确定工作条件。 我们试图在增加事务处理的持续时间和提高系统的可靠性之间达成最佳折衷。
由于系统已进行了大量更新,因此我们从两个独立的来源实施了数据恢复。 如果由于某种原因消息存储库无法正常运行,则可以从第二个来源(从Risk Engine)获取事务日志。 整个系统都遵循这一原则。
除其他事项外,我们设法保留了客户端API,以便经纪人或其他任何人都不需要对新架构进行重大更改。 我必须更改一些界面,但是不需要对工作模型进行重大更改。
我们将平台的最新版本称为Rebus-作为两种最著名的体系结构创新(Risk Engine和BUS)的缩写。
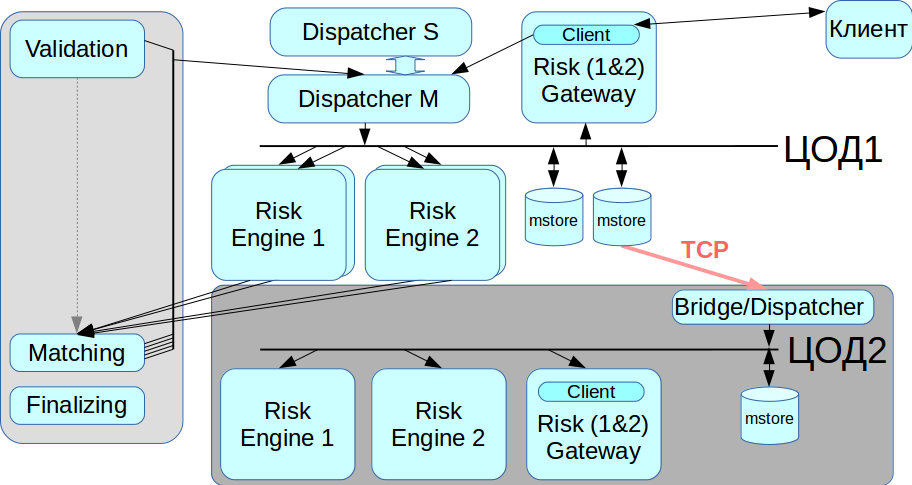
最初,我们只想突出显示清理部分,但是结果是一个庞大的分布式系统。 现在,客户可以同时与交易网关或清算或两者同时进行交互。
我们最终实现的目标:

减少了延迟水平。 由于交易量少,该系统的工作方式与以前的版本相同,但同时承受了更高的负载。
最高生产力从每秒5万笔增加到18万笔交易。 进一步的信息流阻碍了进一步的发展。
: matching Gateway. Gateway , .
, -: