仅在美国,就有300万人无法离开家园。 可以自动导航的辅助机器人可以通过将食物,药品和包装带给他们,使他们更加独立。 研究表明,深度学习与强化(OP)非常适合比较原始输入和动作,例如,用于学习
捕获对象或
移动机器人 ,但通常OP
代理缺乏对安全地定向到远方所需的大型物理空间的了解无需人工帮助和适应新环境的距离。
在最近的三部作品中,“
使用AOP从零开始的定向越野训练 ”,“
PRM-RL:结合强化学习和基于模式的计划来实现长距离机器人定向越野 ”和“
使用PRM-RL进行远程定向越野 ”,我们我们研究了将深层OP与长期规划相结合的易于适应新环境的自主机器人。 我们教当地的规划人员如何执行定向所需的基本动作,以及如何短距离移动而不与移动物体发生碰撞。 当地规划人员使用诸如一维激光雷达等传感器进行嘈杂的环境观察,这些传感器提供到障碍物的距离并提供线性和角速度来控制机器人。 我们使用自动强化学习(AOP)在模拟中训练本地计划员,该方法可自动搜索OP和神经网络的体系结构的奖励。 尽管10-15 m的范围有限,但本地规划人员仍可以很好地适应实际机器人和新的以前未知的环境。 这使您可以将它们用作在较大空间上定向的构建块。 然后,我们建立一个路线图,一个图,其中节点是独立的部分,并且只有当本地规划者能够很好地模仿使用噪音传感器和控件的真实机器人在它们之间移动时,边线才能将节点连接起来。
自动强化学习(AOP)
在
我们的第一项工作中,我们在小型静态环境中培训本地规划师。 但是,在使用标准深度OP算法(例如,深度确定性梯度(
DDPG ))进行学习时,存在一些障碍。 例如,本地规划师的真正目标是实现既定目标,因此他们将获得很少的回报。 在实践中,这要求研究人员花大量时间在算法的逐步实施和奖项的人工调整上。 研究人员还必须做出关于神经网络架构的决策,而没有清晰,成功的配方。 最后,诸如DDPG之类的算法学习不稳定,并且经常表现出
灾难性的健忘性 。
为了克服这些障碍,我们通过强化自动化了深度学习。 AOP是围绕深层OP的进化式自动包装程序,它通过
大规模超参数优化来寻求回报和神经网络架构。 它分两个阶段工作:寻找奖励和寻找建筑。 在寻找奖励的过程中,AOP同时培训了几代DDPG代理,并且每个代理都有其自己的略微修改的奖励功能,针对本地计划者的真正任务进行了优化:到达路径的终点。 在奖励搜索阶段的最后,我们选择最常导致代理商达成目标的目标。 在神经网络体系结构的搜索阶段,对于本次比赛,我们使用选定的奖励并调整网络层以优化累积奖励,重复此过程。
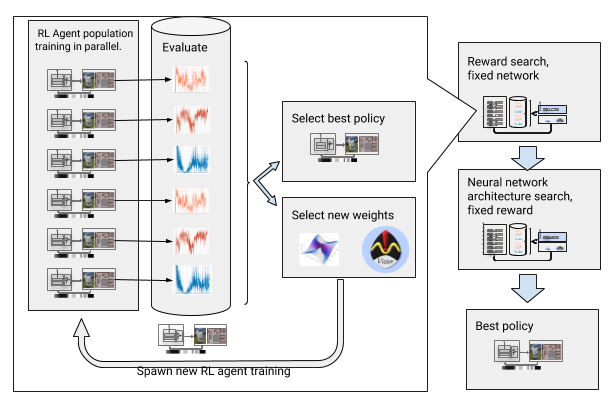 寻求奖励和神经网络架构的AOP
寻求奖励和神经网络架构的AOP但是,此分步过程使AOP在样本数量方面无效。 对10代100位代理商的AOP培训需要50亿个样本,相当于32年的学习经验! 优点是AOP之后,手动学习过程将自动进行,并且DDPG不会造成灾难性的遗忘。 最重要的是,最终策略的质量更高-它们可以抵抗来自传感器,驱动器和本地化的噪声,并且可以很好地推广到新环境中。 我们最好的政策是在我们的测试地点比其他定向方法成功26%。
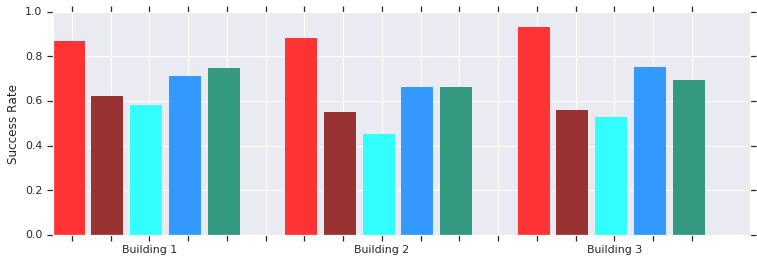 红色-AOP在短距离(最多10 m)内在几座以前未知的建筑物中成功。 与手动训练的DDPG(深红色),人工势场(蓝色),动态窗口(蓝色)和行为克隆(绿色)进行比较。本地AOP调度程序策略与真实非结构化环境中的机器人配合使用效果很好
红色-AOP在短距离(最多10 m)内在几座以前未知的建筑物中成功。 与手动训练的DDPG(深红色),人工势场(蓝色),动态窗口(蓝色)和行为克隆(绿色)进行比较。本地AOP调度程序策略与真实非结构化环境中的机器人配合使用效果很好而且,尽管这些政治人物仅能进行局部定向,但它们能够抵抗移动的障碍,并且在非结构化环境中被真正的机器人很好地容忍。 尽管他们接受了静态物体模拟方面的培训,但它们有效地应对了运动物体。 下一步是将AOP策略与基于样本的计划结合起来,以扩展其工作范围并教他们如何进行长距离导航。
使用PRM-RL进行长距离定向
基于模式的计划者可以长期定位,近似机器人的动作。 例如,机器人通过绘制各部分之间的过渡路径来构建
概率路线图 (PRM)。 在我们的
第二部作品中 ,该
作品在
ICRA 2018大会上获得了奖项,我们将PRM与手动调整的本地OP调度程序(无AOP)相结合,以在本地训练机器人,然后使其适应其他环境。
首先,对于每个机器人,我们在广义模拟中训练本地调度程序策略。 然后,我们将基于要使用该环境的地图,考虑此策略创建一个PRM,即所谓的PRM-RL。 我们希望在建筑物中使用的任何机器人都可以使用同一张卡。
要创建PRM-RL,仅当本地OP调度程序可以可靠且重复地在它们之间移动时,我们才将样本中的节点合并。 这是在蒙特卡洛模拟中完成的。 生成的地图适应特定机器人的功能和几何形状。 具有相同几何形状但具有不同传感器和驱动器的机器人卡将具有不同的连接性。 由于代理可以绕角落旋转,因此也可以打开不在直接视线内的节点。 但是,由于传感器噪声,与墙壁和障碍物相邻的节点将不太可能包含在地图中。 在运行时,OP代理在地图上从一个部分移动到另一部分。
 对于每个随机选择的节点对,使用三个Monte Carlo模拟创建一个映射
对于每个随机选择的节点对,使用三个Monte Carlo模拟创建一个映射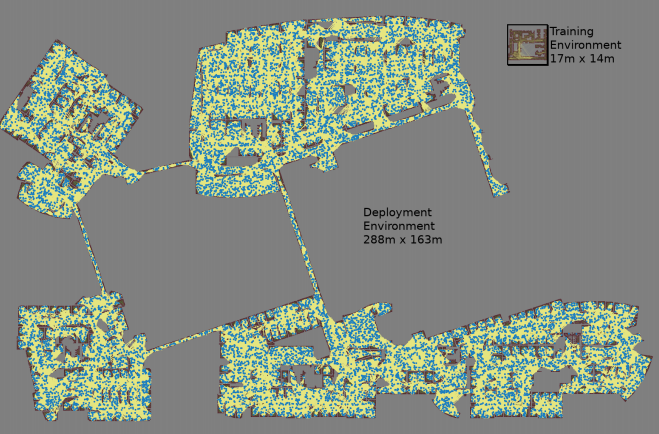 最大的地图尺寸为288x163 m,包含近700,000条边线。 300名工人进行了为期4天的收集,共进行了11亿次碰撞检查。第三项工作
最大的地图尺寸为288x163 m,包含近700,000条边线。 300名工人进行了为期4天的收集,共进行了11亿次碰撞检查。第三项工作对原始PRM-RL进行了一些改进。 首先,我们用本地AOP调度程序替换了手动调整的DDPG,这可以改善长距离定向。 其次,添加
了同时定位和标记 (
SLAM )的
地图 ,机器人在运行时将其用作构建路线图的源。 SLAM卡容易受到噪声的影响,从而消除了“模拟器与现实之间的鸿沟”,这是机器人技术中的一个众所周知的问题,由于该问题,在模拟中受过训练的特工在现实世界中的表现要差得多。 我们在仿真中的成功水平与真实机器人的成功水平相吻合。 最后,我们添加了分布式建筑地图,因此我们可以创建包含多达700,000个节点的非常大的地图。
我们在AOP代理的帮助下对这种方法进行了评估,AOP代理根据面积超过培训环境200倍的建筑物图纸(仅包括肋骨)创建了地图,这些图纸在20次尝试中成功完成了90%的情况。 我们将PRM-RL与各种方法进行了比较,最大距离为100 m,这大大超出了本地计划者的范围。 由于节点的正确连接(适合机器人的功能),PRM-RL的成功率是传统方法的2-3倍。
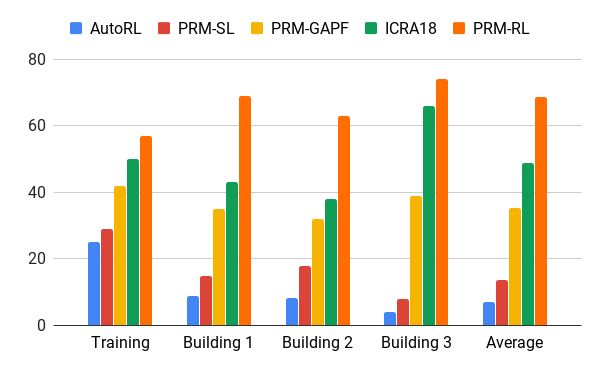 在不同建筑物中移动100 m的成功率。 蓝色-本地AOP调度程序,第一份工作; 红色-原始PRM; 黄色-人工势场; 绿色是第二工作; 红色-第三项工作,带有AOP的PRM。
在不同建筑物中移动100 m的成功率。 蓝色-本地AOP调度程序,第一份工作; 红色-原始PRM; 黄色-人工势场; 绿色是第二工作; 红色-第三项工作,带有AOP的PRM。我们在许多建筑物的许多真实机器人上测试了PRM-RL。 以下是测试套件之一; 除了SLAM卡以外最混乱的地方和区域以外,机器人几乎可以在所有地方可靠地移动。

结论
机器定向可以严重提高行动不便人士的独立性。 这可以通过开发可以轻松适应环境的自主机器人以及可基于现有信息在新环境中实现的方法来实现。 这可以通过使用AOP自动执行短距离的基本方向训练,然后将获得的技能与SLAM卡一起使用来创建路线图来完成。 路线图由通过肋骨连接的节点组成,机器人可以在这些节点上可靠地移动。 结果,开发了一种机器人行为策略,经过一次培训,该策略可以在不同的环境中使用,并发布专门针对特定机器人的路线图。