上一次我们讨论数据一致性时,通过用户的眼光看了不同级别的事务隔离之间的区别,并弄清了为什么了解它很重要。 现在,我们开始学习PostgreSQL如何实现基于快照的隔离和多版本化。
在本文中,我们将研究数据在文件和页面中的物理位置。 这使我们脱离了隔离的主题,但是这种离题对于理解更多的材料是必要的。 我们需要了解底层数据存储的工作方式。
关系
如果查看表和索引的内部,结果发现它们的排列方式相似。 两者和另一个-基础对象都包含一些由行组成的数据。
表格由行组成的事实是毋庸置疑的。 对于索引,这不太明显。 但是,想象一下B树:它由包含索引值的节点组成,并链接到其他节点或表行。 可以将这些节点视为索引行-实际上是这样。
实际上,仍然有许多对象以类似的方式排列:序列(本质上是单行表),物化视图(本质上是记住查询的表)。 然后是通常的视图,它们本身并不存储数据,但在所有其他意义上都类似于表。
PostgreSQL中的所有这些对象都称为通用单词
关系 。 这个词非常不幸,因为它是关系理论中的术语。 您可以在关系和表(视图)之间绘制一个平行线,但是当然不能在关系和索引之间绘制一个平行线。 但是事情确实发生了:PostgreSQL的学术根基让他们感到自己。 我认为起初它被称为表和视图,其余的随着时间的推移而增长。
此外,为简单起见,我们将仅讨论表和索引,但是其余
关系的结构完全相同。
图层(分叉)和文件
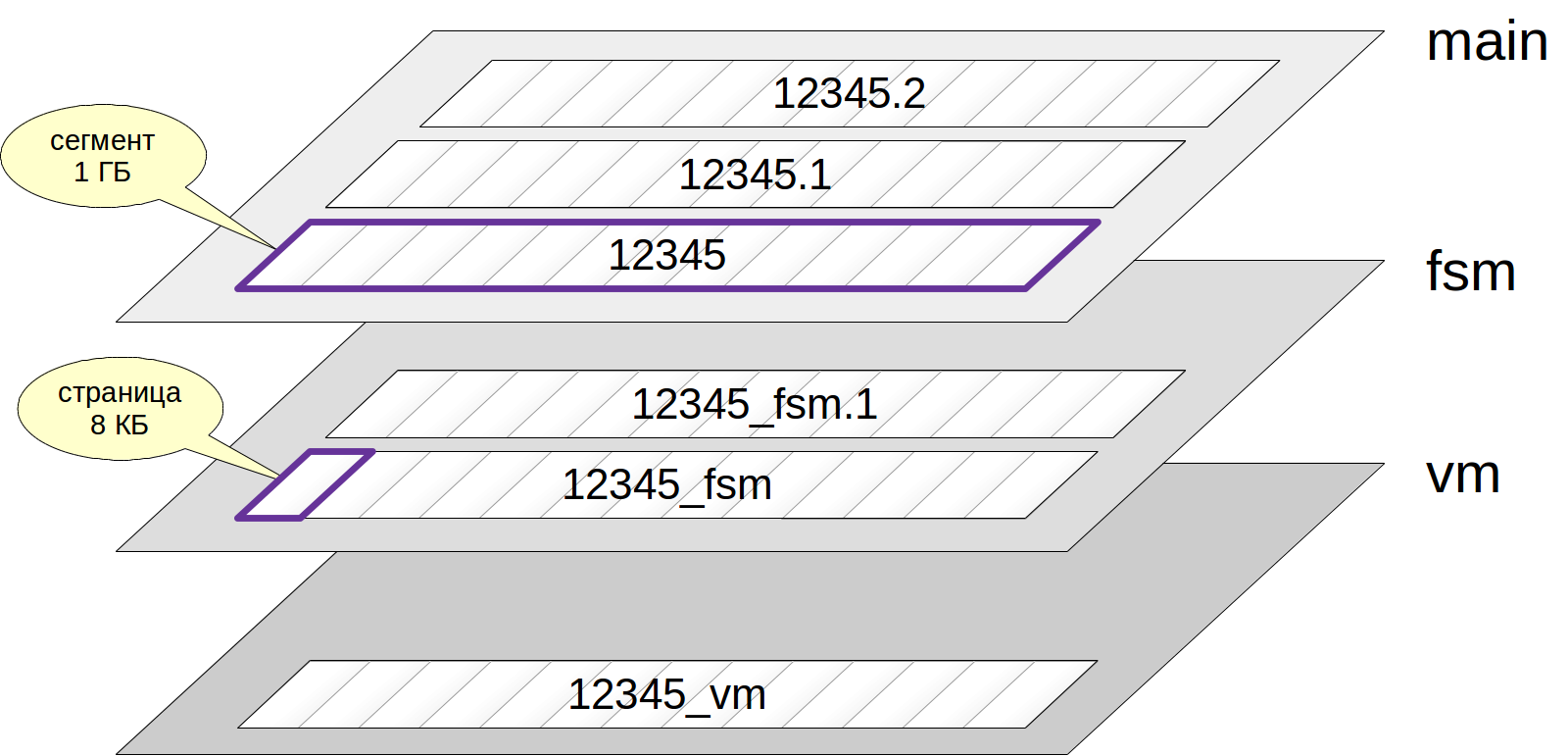
通常,每个关系都有多个
层次 (分支)。 图层有几种类型,每个图层都包含某种类型的数据。
如果存在一层,则首先由一个
文件表示。 文件名包含一个数字标识符,可以在其中添加与图层名称相对应的结尾。
文件逐渐增长,当其大小达到1 GB时,将创建同一层的下一个文件(此类文件有时称为
segment )。 段号附加在文件名的末尾。
历史上发生了1 GB的文件大小限制,以支持各种文件系统,其中一些无法处理大文件。 在构建PostgreSQL(
./configure --with-segsize )时可以更改此限制。
因此,几个文件可以对应于磁盘上的一个关系。 例如,对于一张小桌子,将有3个。
属于一个表空间和一个数据库的对象的所有文件都将放在一个目录中。 必须考虑到这一点,因为文件系统通常不能很好地处理目录中的大量文件。
请注意,这些文件又分为几
页 (或
块 ),通常为8 KB。 我们将在下面讨论页面的内部结构。
现在让我们看一下图层的类型。
主要层是数据本身:相同的表或索引行。 存在任何关系的主层(不包含数据的表示除外)。
主层中文件的名称仅包含一个数字标识符。 这是我们上次创建的表文件的示例路径:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
这些标识符从何而来? 基本目录对应于pg_default表空间,下一个子目录对应于数据库,并且我们感兴趣的文件已经在其中:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
该路径是相对的,它是从数据目录(PGDATA)中计数的。 而且,PostgreSQL中几乎所有的路径都是从PGDATA计算的。 因此,您可以安全地将PGDATA传输到另一个位置-它不保存任何内容(除非您可能需要在LD_LIBRARY_PATH中配置到库的路径)。
我们进一步研究文件系统:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
初始化层仅适用于非日记表(使用UNLOGGED创建)及其索引。 这些对象与普通对象没有什么不同,除了它们的操作未记录在预记录日志中。 因此,使用它们的速度更快,但是如果发生故障,则不可能以一致的状态还原数据。 因此,在恢复时,PostgreSQL仅删除此类对象的所有层,并将初始化层写入主层的位置。 结果是“虚拟”。 我们将详细讨论日志记录,但是会以不同的周期进行。
帐户表已记录日志,因此没有初始化层。 但是对于实验,您可以禁用日志记录:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
从示例中可以看出,启用和禁用即时日记功能的功能包括将数据覆盖到具有不同名称的文件中。
初始化层与主层同名,但后缀为“ _init”:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
可用空间地图(free space map)-一层,页面内有一个空白空间。 这个地方在不断变化:添加新版本的字符串时,它减少,而清洗时,它增加。 当插入新版本的行时,可以使用自由空间映射来快速找到要添加数据的合适页面。
可用空间图的后缀为“ _fsm”。 但是该文件不会立即显示,只有在必要时才显示。 实现此目的的最简单方法是清理表(为什么-让我们在适当的时候谈谈):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
可见性图是一层,其中仅包含当前版本的字符串的页面用一位标记。 粗略地说,这意味着当事务尝试从此类页面读取行时,可以在不检查其可见性的情况下显示该行。 在以下文章中,我们将详细研究这种情况。
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
页数
如前所述,文件在逻辑上分为页面。
通常,一个页面的大小为8 KB。 您可以在一定限制(16 KB或32 KB)内更改大小,但只能在组装过程中更改(
./configure --with-blocksize )。 组装并正在运行的实例只能使用一种尺寸的页面。
无论文件属于哪一层,服务器都以几乎相同的方式使用它们。 页面首先被读取到缓冲区高速缓存中,进程可以在其中读取和修改它们。 然后,如有必要,将页面推回磁盘。
每个页面都有内部标记,通常包含以下部分:
0 + ----------------------------------- +
| 标题|
24 + ----------------------------------- +
| 指向版本字符串的指针数组|
较低+ ----------------------------------- +
| 自由空间|
上层+ ----------------------------------- +
| 行版本|
特殊+ ----------------------------------- +
| 特殊区域|
页面大小+ ----------------------------------- +
通过“ research” pageinspect扩展可以很容易地找到这些部分的大小:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
在这里,我们看表的第一页(零)的
标题 。 除了剩余区域的大小之外,标题还包含有关页面的其他信息,但我们对此并不感兴趣。
页面底部是一个
特殊区域 ,在本例中为空白。 它仅用于索引,然后不用于所有人。 这里的“底部”对应于图片; 说“在高地址”可能更正确。
特殊区域之后是
行版本 -我们存储在表中的数据,以及一些开销信息。
目录的顶部是紧随标题之后的页面顶部:
指向页面可用行版本的
指针数组 。
在行和指针的版本之间可能有
可用空间 (在可用空间映射中标记)。 请注意,页面内部没有碎片,所有可用空间始终由一个碎片表示。
指针
为什么需要指向字符串版本的指针? 事实是,索引行必须以某种方式引用表中行的版本。 显然,链接应包含文件号,文件中的页码以及该行版本的某些指示。 从页面开始的偏移量可以用作这种指示,但这很不方便。 我们将无法在页面内移动该行的版本,因为它会破坏现有的链接。 这将导致页面内部空间的碎片化和其他不愉快的后果。 因此,索引是指索引号,指针是指行版本在页面中的当前位置。 原来是间接寻址。
每个指针正好占据4个字节,并包含:
- 链接到字符串的版本;
- 此字符串版本的长度;
- 几个位确定字符串的版本状态。
资料格式
磁盘上的数据格式与RAM中的数据表示完全一致。 该页面按原样读入缓冲区高速缓存,无需任何转换。 因此,来自一个平台的数据文件与其他平台不兼容。
例如,在x86体系结构中,字节顺序从最低有效位到最高字节(小端顺序)采用,z /体系结构使用反向顺序(大端顺序),在ARM中使用开关顺序。
许多架构都提供跨机器字边界的数据对齐方式。 例如,在x86 32位系统上,整数(整数类型,占4个字节)将在4字节字的边界以及双精度浮点数(双精度类型,8字节)的边界对齐。 在64位系统上,双精度值将在8字节字的边界对齐。 这是不兼容的另一个原因。
由于对齐,表行的大小取决于字段的顺序。 通常,这种影响不是很明显,但是在某些情况下,可能会导致尺寸显着增加。 例如,如果将char(1)和integer字段混合在一起,通常会在它们之间浪费3个字节。 您可以在尼古拉·夏普洛夫(Nikolai Shaplov)的演讲“
里面有什么 ”中看到有关此内容的更多信息。
字符串和TOAST版本
关于如何从内部排列字符串的版本,下一次我们将详细讨论。 到目前为止,对我们来说唯一重要的事情是每个版本都应该完全适合一页:PostgreSQL没有提供一种“继续”下一页内容的方法。 相反,使用了称为TOAST(超大属性存储技术)的技术。 该名称本身表明该线可以切成烤面包。
认真地说,TOAST涉及几种策略。 可以将“长”属性值发送到单独的服务表,该服务表先前已切成小块吐司。 另一个选择是压缩该值,以便该行的版本仍适合常规表格页面。 而且有可能同时存在另一个:首先进行压缩,然后才进行剪切和发送。
对于每个主表,如有必要,将创建一个单独的但对于所有属性的表,即TOAST表(及其专用索引)。 必要性取决于表中可能存在的长属性。 例如,如果一个表具有一列数字或文本类型的列,则即使不使用长值,也会立即创建一个TOAST表。
由于TOAST表本质上是一个常规表,因此它仍然具有相同的层集。 这使“服务”表的文件数量增加了一倍。
最初,策略由列数据类型确定。 您可以使用psql中的
\d+命令查看它们,但是由于它还会显示很多其他信息,因此我们将使用该请求到系统目录:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
策略的名称具有以下含义:
- plain-不使用TOAST(用于明显的“短”数据类型,例如整数);
- 扩展-压缩和存储都可以在单独的TOAST表中进行;
- 外部-长值未压缩地存储在TOAST表中;
- main-long值首先被压缩,并且如果压缩无济于事,则仅在TOAST表中进行压缩。
一般而言,算法如下。 PostgreSQL希望页面上至少有4行。 因此,如果行的大小超过页面的第四部分,请考虑到标题(对于正常的8K页面,这是2040字节),应将TOAST应用于部分值。 我们将按照以下描述的顺序进行操作,并在行停止超过阈值时立即停止:
- 首先,我们使用外部策略和扩展策略对属性进行分类,从最长到最短。 扩展属性将被压缩(如果有效果),并且如果该值本身超过页面的四分之一,则会立即将其发送到TOAST表。 外部属性的处理方式相同,但不进行压缩。
- 如果在第一次通过之后该行的版本仍然不适合,我们会将其余的属性以及外部和扩展策略发送到TOAST表。
- 如果这也无济于事,请尝试使用主策略压缩属性,同时将其保留在表页面中。
- 并且仅在此行还不够短之后,才将主要属性发送到TOAST表。
有时更改某些列的策略可能很有用。 例如,如果事先知道该列中的数据未压缩,则可以为其设置外部策略-这样可以节省无用的压缩尝试。 这样做如下:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
重复请求,我们得到:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
TOAST表和索引位于单独的pg_toast模式中,因此通常不可见。 对于临时表,使用pg_toast_temp_
N方案,类似于通常的pg_temp_N
。当然,如果需要的话,没有人会去窥视该过程的内部机制。 假设accounts表中有三个可能很长的属性,所以TOAST表必须是。 这是:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
对于将线切成的“吐司”,采用简单的策略是合乎逻辑的:第二层的TOAST不存在。
PostgreSQL索引更仔细地隐藏,但也很容易找到:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
客户列使用扩展策略:其中的值将被压缩。 检查:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
TOAST表中没有任何内容:重复字符被完美压缩,然后该值适合常规表页面。
现在,让客户端名称由随机字符组成:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
此序列无法压缩,并且属于TOAST表:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
如您所见,数据被切成2000字节的片段。
访问“长”值时,PostgreSQL会自动对应用程序透明,恢复原始值并将其返回给客户端。
当然,在切片压缩和后续恢复上花费了大量资源。 因此,在PostgreSQL中存储大量数据不是一个好主意,特别是如果它被积极使用并且不需要它们的交易逻辑(例如:会计凭证的原始扫描)。 一种更有利可图的替代方法是将此类数据存储在文件系统中,并在DBMS中存储相应文件的名称。
仅当引用“长”值时才使用TOAST表。 此外,toast表具有自己的版本控制:如果数据更新不影响“长”值,则该行的新版本将引用TOAST表中的相同值-这样可以节省空间。
请注意,TOAST仅适用于表,不适用于索引。 这对索引键的大小施加了限制。
您可以在文档中阅读有关内部数据组织的更多信息。
待续 。