tidyr软件包是R语言-tidyverse中最受欢迎的库之一的核心部分。
该软件包的主要目的是使数据外观整洁。
在Habré上已经有专门针对此软件包的出版物 ,但是它可以追溯到2015年。 我想告诉您最相关的更改,几天前其作者哈德利·威克汉姆(Hadley Wickham)宣布了这一更改。
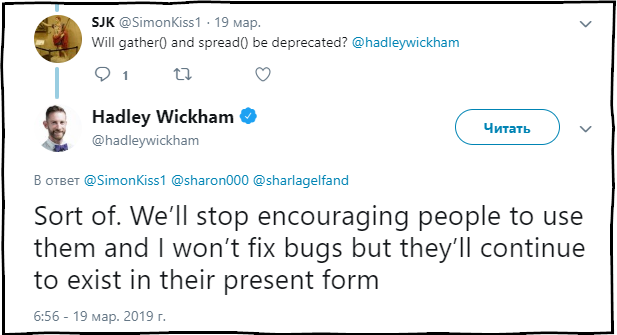
SJK :是否会不建议使用 collect()和spread()函数?
哈德利·威克姆(Hadley Wickham) :在某种程度上。 我们将不再建议使用这些功能并更正它们中的错误,但它们将继续以当前状态出现在包装中。
目录内容
TidyData概念
tidyr的目的是帮助您将数据呈现为所谓的整洁外观。 准确的数据是其中的数据:
- 每个变量都在一列中。
- 每个观察结果都是一条线。
- 每个值都是一个单元格。
赋予整洁数据的数据在分析过程中使用起来更简单,更方便。
tidyr软件包中包含的主要功能
tidyr包含一组用于转换表的函数:
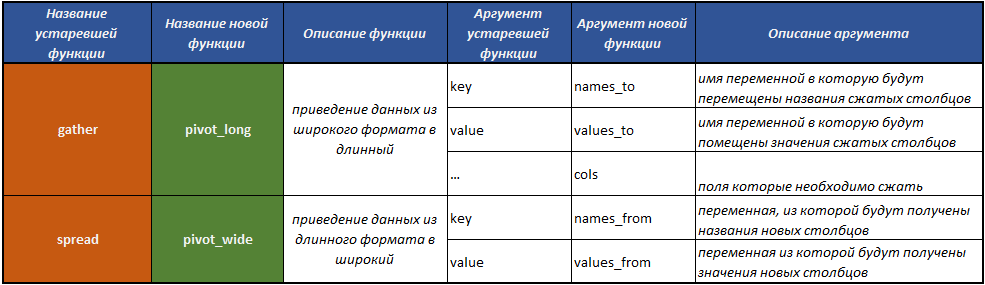
fill() -用先前的值填充列中的缺失值;separate() -通过分隔符将一个字段分成多个字段;unite() -执行将几个字段组合为一个字段的操作,与split separate()函数相反。pivot_longer() -一种将数据从宽格式转换为长格式的函数;pivot_wider() -一种将数据从长格式转换为宽格式的函数。 该操作与pivot_longer()函数执行的操作相反。- 不推荐使用
gather() -一种将数据从宽格式转换为长格式的函数; - 不推荐使用split
spread() -一种将数据从长格式转换为宽格式的函数。 gather()函数执行的操作的相反操作。
以前,函数gather()和spread()用于这种转换。 多年来,这些功能的存在对所有用户(包括程序包的作者)而言,这些功能的名称及其参数都不是很明显,并且在查找它们以及理解这些功能中的哪些使日期范围从宽到长方面造成了困难。格式,反之亦然。
在这方面, tidyr中添加了两个新的重要功能,这些功能旨在转换日期范围。
新功能pivot_longer()和pivot_wider()的灵感来自John Mount和Nina Zumel创建的cdata包中的某些功能。
安装最新版本的tidyr 0.8.3.9000
要安装新的最新版本的tidyr 0.8.3.9000 软件包 (其中提供了新功能),请使用以下代码。
devtools::install_github("tidyverse/tidyr")
在撰写本文时,这些功能仅在GitHub上的软件包的dev版本中可用。
切换到新功能
实际上,转移旧脚本以使用新功能并不难,为了更好地理解,我将以旧函数的文档为例,并说明如何使用新的pivot_*()函数执行相同的操作。
将宽格式转换为长格式。
收集功能文档中的示例代码 # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
将长格式转换为宽格式。
扩展功能文档中的示例代码 # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
因为 在上面使用pivot_longer()和pivot_wider()示例中,在源表库中, names_to和values_to参数中未列出任何列,它们的名称必须用引号引起来。
在表格的帮助下,您可以最轻松地弄清楚如何切换到使用新的tidyr概念。
作者注
下面的所有文本都是适应性的,我什至要说说tidyverse库的官方网站上的小插图的免费翻译。
pivot_longer () -通过减少列数和增加行数来使数据集更长。

要运行本文中提供的示例,您必须首先连接必要的程序包:
library(tidyr) library(dplyr) library(readr)
假设我们有一张表,其中有一项调查结果,其中(其中包括)询问人们其宗教信仰和年收入:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
该表按行包含受访者的宗教数据,收入水平分散在各列名称中。 来自每个类别的受访者数量存储在宗教和收入水平相交的单元格值中。 要将表格调整为整洁,正确的格式,只需使用pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
参数pivot_longer()
- 第一个参数cols描述要合并的列。 在这种情况下,除time外的所有列。
- names_to参数给出将从我们合并的列名称创建的变量的名称。
- values_to给出将从存储在联接列的单元格值中的数据创建的变量的名称。
技术指标
这是tidyr软件包的新功能,以前在使用过时的功能时不可用。
规范是一个数据框,其每一行对应于新的输出日期框中的一列,以及两个以下列开头的特殊列:
- .name包含列的原始名称。
- .value包含单元格值将进入的列的名称。
规范的其余列反映了.name中可压缩列的名称将如何在新列中显示。
该规范描述了存储在列名中的元数据,每一列一行,每一个变量与列名组合在一起,这一定义现在看来似乎令人困惑,但是考虑了几个示例之后,一切将变得更加清晰。
该规范的含义是您可以检索,修改和设置转换后的数据框的新元数据。
当将表从宽格式转换为长格式时, pivot_longer_spec()函数pivot_longer_spec()处理规范。
该函数如何工作,需要任何日期框架,并如上所述生成其元数据。
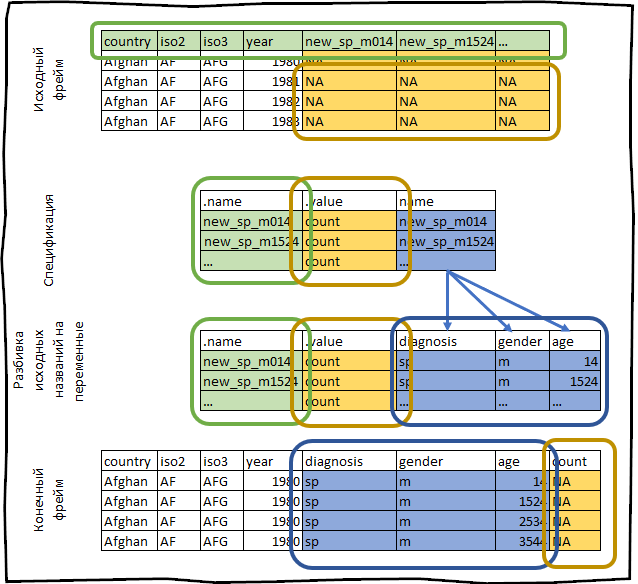
例如,让我们看一下tidyr包随附的who数据集。 该数据集包含国际卫生组织提供的有关结核病发病率的信息。
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
我们构造它的规范。
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
字段country , iso2 , iso3已经是变量。 我们的任务是将列从new_sp_m014翻转到newrel_f65 。
这些列的名称存储以下信息:
- 前缀
new_表示该列包含有关结核病新病例的数据,当前日期框架仅包含有关新疾病的信息,因此该前缀在当前上下文中不具有任何意义。 sp / rel / sp / ep描述了一种诊断疾病的方法。m / f患者性别。014患者的年龄范围。
我们可以使用带有正则表达式的extract()函数来分隔这些列。
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
请注意, .name列必须保持不变,因为这是我们在源数据集的列名中的索引。
性别和年龄(“ 性别和年龄”列)具有固定的已知值,因此建议将这些列转换为因子:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
最后,为了将我们创建的规范应用于who框架的原始日期,我们需要在pivot_longer()函数中使用spec参数。
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
我们刚才所做的一切都可以用以下方式示意性地描述:
使用多个值(.value)的规范
在上面的示例中, .value规范列仅包含一个值,在大多数情况下会发生这种情况。
但是有时候,当您需要从值中具有不同数据类型的列中收集数据时,可能会出现一种情况。 使用不推荐使用的spread()函数,这将非常困难。
以下示例是从小插图中借用的data.table包。
让我们创建一个训练数据框架。
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
每行中创建的日期框架包含有关一个家庭的孩子的数据。 家庭可以有一个或两个孩子。 对于每个孩子,都提供了有关出生日期和性别的数据,并且每个孩子的数据都在不同的列中,我们的任务是将这些数据转换为正确的格式以进行分析。
请注意,我们有两个变量,其中包含有关每个孩子的信息:他的性别和出生日期(带有前缀dop的列包含出生日期,带有前缀性别的列包含该孩子的性别)。 在预期的结果中,它们应该放在单独的列中。 为此,我们可以生成一个规范,其中.value列将具有两个不同的值。
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
因此,让我们逐步完成上述代码执行的步骤。
pivot_longer_spec(-family) -创建一个规范,以压缩除family列之外的所有可用列。separate(col = name, into = c(".value", "child")) -分开.name列,其中包含源字段的名称,加下划线,然后将值放入.value和child列中。mutate(child = parse_number(child)) -将子字段的值从文本转换为数字数据类型。
现在,我们可以将接收到的规范应用于初始数据帧,并将表调整为所需的形式。
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
我们使用参数na.rm = TRUE ,因为当前数据形式迫使我们为不存在的观察创建额外的行。 因为 家族2只有一个孩子, na.rm = TRUE确保家族2在输出中只有一行。
pivot_wider() -是逆变换,反之亦然,它通过减少行数来增加框架日期中的列数。
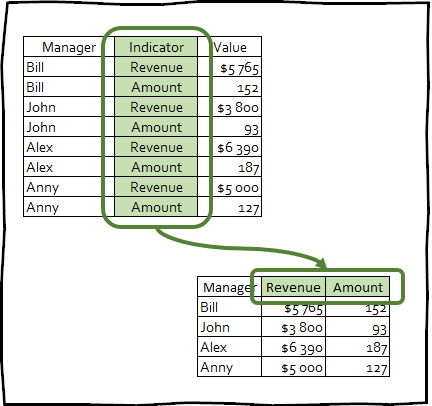
这种转换很少用于使数据外观整洁,但是,此技术对于创建演示文稿中使用的数据透视表或与任何其他工具集成很有用。
实际上,功能pivot_longer()和pivot_wider()是对称的,并且它们执行相反的操作,即: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec)和df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec)将返回原始df。
为了演示pivot_wider()函数的操作,我们将使用fish_encounters数据集 ,该数据集存储有关各个站点如何记录鱼沿河运动的信息。
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
在大多数情况下,如果您在单独的列中提供每个站点的信息,则该表将更具信息性且易于使用。
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
该数据集仅在站检测到鱼时才记录信息,即 如果某个站点没有固定任何鱼类,则该数据将不在表格中。 这意味着输出将由NA填充。
但是,在这种情况下,我们知道缺少记录意味着没有注意到鱼,因此我们可以在pivot_wider()函数中使用values_fill参数,并用零填充这些缺失的值:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
从多个源变量生成列名
想象一下,我们有一个包含产品,国家和年份组合的表格。 要生成测试日期,可以运行以下代码:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
我们的任务是扩展日期范围,以使一列包含产品和国家/地区每种组合的数据。 为此,只需将包含要连接的字段名称的向量传递到names_from参数中。
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
您还可以将规范应用于pivot_wider()函数。 但是,当将数据馈送到pivot_wider()规范执行与pivot_longer()相反的pivot_longer() : .name中指定的列是使用.value和其他列中的值创建的。
对于此数据集,如果希望国家和产品的每种可能组合都有自己的列,而不仅仅是数据中存在的列,则可以生成用户规范:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
一些使用新潮汐概念的高级示例
以美国收入和租金普查数据集为例,使数据整洁
us_rent_income数据集包含有关2017年美国各州平均收入和租金的信息(该数据集可在tidycensus软件包中找到)。
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
以us_rent_income 数据集中的数据的存储形式来使用它们非常不便,因此我们想创建一个包含以下列的数据集: rent , rent_moe , come , income_moe 。 创建此规范的方法有很多,但是最主要的是,我们需要生成变量值和估算值/ moe的每种组合,然后生成列名。
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
提供此规格给pivot_wider()为我们提供所需的结果:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
世界银行
有时,将数据集转换为正确的格式需要几个步骤。
world_bank_pop 数据集包含世界银行关于2000年至2018年每个国家人口的数据。
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
我们的目标是创建一个整洁的数据集,其中每个变量都在单独的列中。 目前尚不清楚哪些步骤是必需的,但我们将从最明显的问题开始:年份分布在几列中。
为了解决此问题,您必须使用pivot_longer()函数。
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
结论
, tidyr , spread() gather() . pivot_longer() pivot_wider() .