
机器学习软件代码通常很复杂且令人困惑。 检测并消除其中的错误是一项资源密集型任务。 即使是最简单的
直接连接神经网络,也都需要认真的方法来构建网络体系结构,权重初始化和网络优化。 小错误可能会导致令人不快的问题。
本文是关于神经网络的调试算法的。
Skillbox建议: 从零开始的 动手课程Python开发人员 。
我们提醒您: 对于所有“ Habr”读者来说,使用“ Habr”促销代码注册任何Skillbox课程时均可享受10,000卢布的折扣。
该算法包括五个阶段:
- 简单的开始;
- 损失确认;
- 验证中间结果和化合物;
- 参数诊断;
- 工作控制。
如果您觉得其他事情比其他事情更有趣,则可以直接转到这些部分。
轻松启动
与常规网络相比,具有复杂体系结构,正则化和学习速度计划器的神经网络更难启用。 我们这里有些棘手,因为项目本身与调试有间接关系,但这仍然是重要的建议。
一个简单的开始就是创建一个简化的模型并将其训练在一个数据集(点)上。
首先,我们创建一个简化的模型为了快速入门,请创建一个具有单个隐藏层的小型网络,并检查一切是否正常。 然后,我们逐步使模型复杂化,检查其结构的每个新方面(附加层,参数等),然后继续进行。
我们在单个数据集(点)上训练模型为了快速测试项目的运行状况,您可以使用一个或两个数据点进行培训,以确认系统是否正常运行。 神经网络应显示100%的训练和验证准确性。 如果不是这种情况,则说明模型太小或您已经有错误。
即使一切顺利,在继续进行之前,请为一个或多个时代的过去做好准备。
损失估计
损失估计是改善模型性能的主要方法。 您需要确保损失与任务相对应,并以正确的比例评估损失函数。 如果使用的损失类型不止一种,请确保它们的阶次相同且正确缩放。
注意初始损失很重要。 如果模型以随机假设开始,请检查实际结果与预期的接近程度。
Andrei Karpati的
工作提出以下建议 :“请确保在开始使用少量参数时能获得预期的结果。 最好立即检查数据丢失(正则化程度设置为零)。 例如,对于具有Softmax分类器的CIFAR-10,我们预期初始损失为2.302,因为每个类别的预期扩散概率为0.1(因为有10个类别),而Softmax的损失是正确类别的负对数概率为- ln(0.1)= 2.302。”
对于二进制示例,只需对每个类进行类似的计算。 例如,这里是数据:20%0和80%1。 预期的初始损失将高达–0.2ln(0.5)–0.8ln(0.5)= 0.693147。 如果结果大于1,则可能表明神经网络的权重未正确平衡或数据未标准化。
检查中间结果和连接
为了调试神经网络,有必要了解网络中进程的动态以及各个中间层的作用,因为它们是相连的。 这是您可能会遇到的一些常见错误:
- 梯度更新的表达式不正确
- 体重更新不适用;
- 渐变消失或爆炸。
如果梯度值为零,则意味着优化器中的学习速度太慢,或者您遇到了不正确的表达式来更新梯度。
另外,有必要监视激活功能的值,每个层的权重和更新。 例如,参数更新的值(权重和偏移量)
应为1-e3 。
当研究大的负偏权重值后,ReLU神经元将输出零时,会出现一种称为“死亡ReLU”或
“消失的梯度问题”的现象。 这些神经元再也不会在任何数据位置被激活。
您可以使用梯度测试通过使用数值方法逼近梯度来检测这些误差。 如果它接近计算得出的梯度,则可以正确实现反向传播。 要创建渐变检查,请
在此处和
此处查看这些出色的CS231资源,以及有关该主题的Andrew Nga的教程。
Fayzan Sheikh指出了可视化神经网络的三种主要方法:
- 初步-向我们展示训练模型的一般结构的简单方法。 它们包括神经网络各个层的形式或过滤器的输出以及每个层中的参数。
- 基于激活。 在它们中,我们破译单个神经元或神经元组的激活,以了解其功能。
- 基于渐变。 这些方法在训练模型时(包括重要性图和类激活图)倾向于操纵从通道来回形成的梯度。
有几种有用的工具可用于可视化各个图层的激活和连接,例如
ConX和
Tensorboard 。
参数诊断
神经网络具有许多相互影响的参数,这使优化变得复杂。 实际上,本节是专家们积极研究的主题,因此,以下建议仅应作为建议,您可以将其作为起点。
数据包大小 (批量大小)-如果您希望数据包大小足够大以获取对误差梯度的准确估计,但又要足够小以使随机梯度下降(SGD)可以简化您的网络。 由于学习过程中的噪音以及将来的优化困难,包装的小尺寸将导致快速收敛。 这将在
此处更详细地描述。
学习速度 -太慢会导致收敛缓慢或陷入局部低谷的风险。 同时,较高的学习速度会导致优化方面的差异,因为您冒着跳入深层但同时狭窄的损失功能的风险。 尝试在神经网络训练期间使用速度计划来降低速度。 CS231n
在这个问题上有很大一部分 。
梯度修剪 -在反向传播期间以最大值或极限范数修剪参数的梯度。 对于解决第三段中可能遇到的任何爆炸梯度的问题很有用。
批量归一化 -用于归一化每一层的输入数据,这可以解决内部协变偏移的问题。 如果您同时使用Dropout和Batch Norma,
请参阅
本文 。
随机梯度下降(SGD)-SGD有多种变体,它们使用动量,自适应学习速度和Nesterov的方法。 同时,它们在训练效率和泛化方面都没有明显的优势(
请参见此处 )。
正则化 -对于构建通用模型至关重要,因为
正则化会增加模型复杂性或极端参数值的代价。 这是在不显着增加模型位移的情况下减小模型方差的一种方法。 更多
信息在这里 。
为了自己评估所有内容,您需要禁用正则化并自己检查数据丢失的梯度。
辍学是简化网络以防止拥塞的另一种方法。 在训练期间,仅通过以一定的概率p(超参数)维持神经元的活动或在相反情况下将其设置为零来发生丢失。 结果,网络必须为每个培训方使用不同的参数子集,这减少了成为主导的某些参数的变化。
重要:如果同时使用辍学和批处理规范化,则请注意这些操作的顺序,甚至要同时使用它们。 所有这一切仍在积极地讨论和补充。 这是
关于Stackoverflow和
Arxiv的两个重要讨论。
工作控制
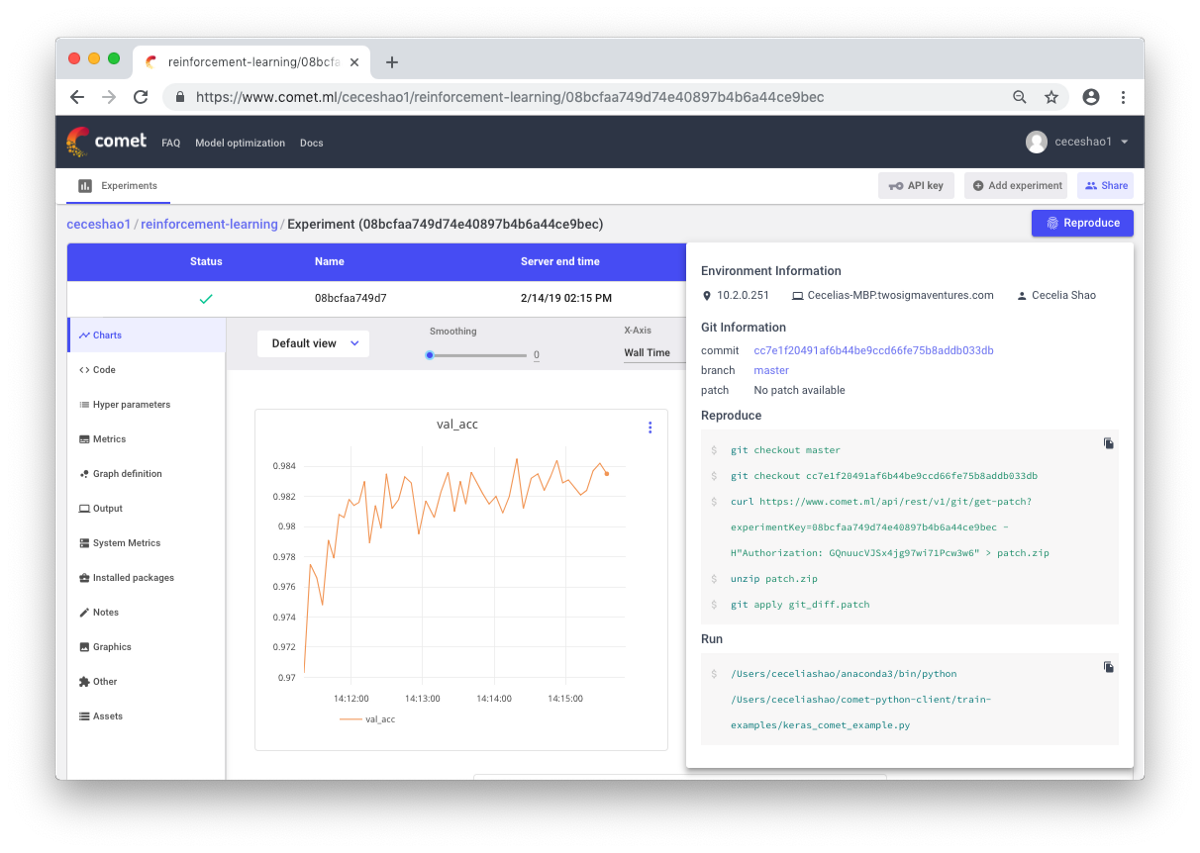
它是关于记录工作流程和实验的。 如果您什么都没记录,则可以忘记,例如,使用哪种训练速度或班级重量。 由于有了该控件,您可以轻松查看和复制以前的实验。 这样可以减少重复实验的次数。
诚然,在进行大量工作的情况下,手动文档记录可能会充满挑战。 这里的Comet.ml等工具可帮助您自动记录数据集,代码更改,实验历史记录和生产模型,包括有关模型的关键信息(超参数,模型性能指标和环境信息)。
神经网络对很小的变化可能非常敏感,这将导致模型性能下降。 跟踪和记录工作是使环境和建模标准化的第一步。
我希望这篇文章可以成为您开始调试神经网络的起点。
Skillbox建议: