任何人的思维过程都很难数学化。 任何业务任务都会生成一组正式和非正式文档,这些信息会反映在公司存储库中。 生成任何信息过程的每个任务都会在其周围创建一组文档及其处理逻辑,这在公司存储环境中几乎没有形式化。 数据仓库内部应有结构以清除信息流。 Oracle Enterprise Data Quality产品旨在解决清理“脏”数据的任务,可以提供帮助。 但这不限于其使用。
1.随机数据库的概念。一个人的最开始的业务联系是通过正式和非正式文件来描述的,例如声明,声明,雇佣合同,安置申请,资源申请。 这些文档在业务流程之间建立了逻辑联系,但通常,它们是办公室经理思想的产物,并且形式化较差。
至少进行一些复杂的优化的任务不仅在于了解正式和非正式的规则,而且经常将不同的知识带入一个通用的信息库。
定义 随机数据库是一组事实,文档,手册,正式文档,这些文档是由人员针对特定业务流程处理的,但是由于人为因素的强大影响而无法完全自动处理。一个例子。 秘书正式接听电话。 呼叫者对产品或服务感兴趣。 呼叫者不了解CRM。 问题:呼叫者应该说什么才能被专家听到?
更准确地说:如果负责的专家不准备进行此类活动,秘书的业务指示中有多少可以进行有关业务的正式对话?
事实证明,我们再次谈到了随机数据库的定义。
也许它包含了秘书无法知道的更多事实。 但是其中收到的信息不能是多余的。 通常,当随机数据库的随机事实到达形式化系统的输入时,就会出现信息超载的情况-所有信息超载不仅会影响秘书的业绩,还会影响整个公司的业绩。
如果将其用于处理目的,则读取此信息状态的机器将基于与人相反的状态的逻辑结论-信息过载。 人为逻辑更加灵活。
2.将定义应用于实际任务。想象一下,一家商店中随机商品的价格标签明显偏高或偏低。 当您离开这家商店时,在没有经验的顾客的购物清单中,最受欢迎商品的价格为5-7(甚至3)英镑,该价格会影响总支票的大小。 事实证明,如果有可能知道买主最常回忆起的商品清单,那么其余的价格可以在相对较大的范围内变化。
您是否曾经想过,为什么在大斋节之前,肉首先变得便宜得多,然后价格急剧上涨,然后又消失了? 首先将人为加热的产品价格(其需求可能降至零),然后通过一定水平的需求,然后将其固定下来,并在一段时间后强制上涨,因为贪婪不允许以公平的价格提供流动性差的商品。
数据市场中存在着几乎类似的情况。 关于其适用性和可提取性的次要假设几乎总是隐藏最有用的信息。
在任何相对不受保护的资源上列出5000-7000人感兴趣的任何信息就足够了,肯定有复制粘贴站点。
或是电话代码为“谁叫我?”的著名游戏。 在Runet中,大约一千个站点仅由各种运营商的电话号码组成,目的是使搜索结果中的排名更高一些,从而尝试以某种方式出售域名并刊登更昂贵的广告。
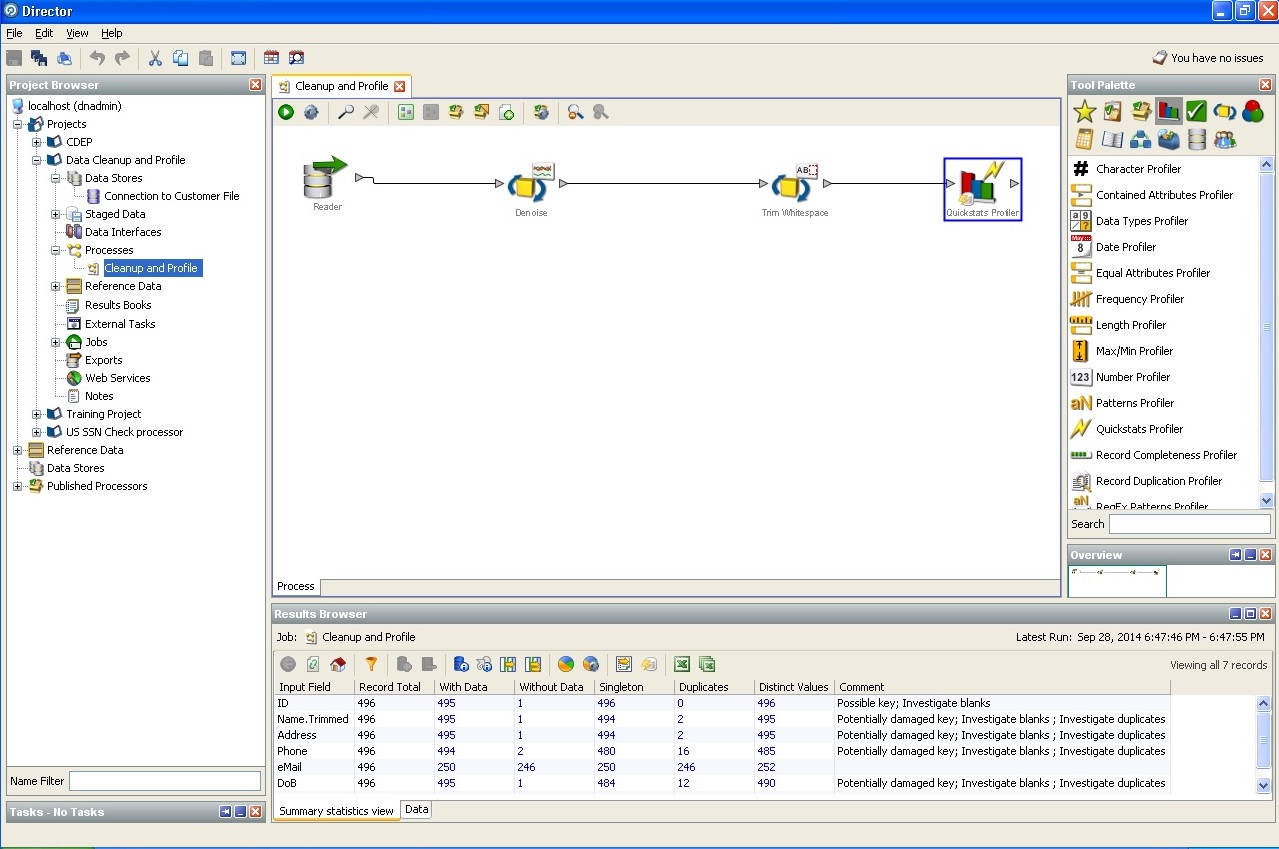
3.使用“脏”数据时的发行价。根据本文作者的研究,每个项目最多有10%的劳动力资源被用于编写某些数据清理程序。 如果您不完全关注普通的类型和长度,即唯一的标识符,数据库完整性规则和业务完整性规则,定量和定性的单位规模,劳动强度的单位系统以及任何其他状态,影响,过渡,则需要照常进行统计逻辑和认真的业务分析。 需求的形式化要求对事实维度关系进行形式化,以建立存储库和解决前端问题。
同意,如果ETL流程占用了任何存储的70%的工作时间,那么在有条件存储200,000个客户的情况下正确地清理数据节省了5-7%的资源已经是一个不错的选择了吗?
我们将介绍现成系统中的“脏”数据问题。 假设您通过邮件向1万名客户发送了国定假日的祝贺。 如果您在姓名,姓氏上输入错误或在表格中填写错误,有多少人会把您的信和最好的明信片扔到邮箱里? 您付出的代价可以将任何用户的情绪降低到零!
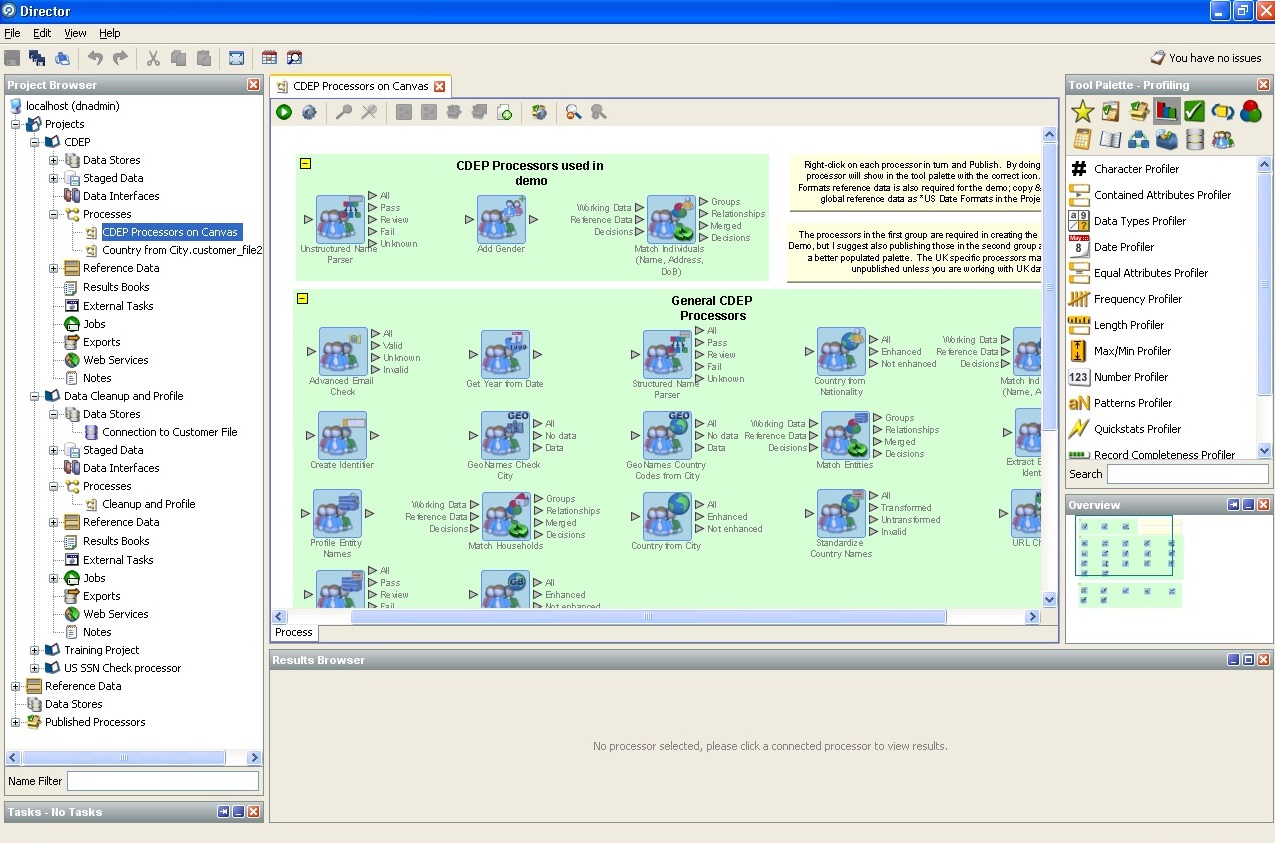
4. Oracle企业数据质量-企业存储的盾牌和剑。我们提供的屏幕快照描述了Oracle Enterprise Data Quality的功能。
因此,让某人在您的数据库或文本文档上洒水。
这是标准处理器的列表(允许您使用的逻辑单元
一个或另一个假设的数据,或搜索所需的):
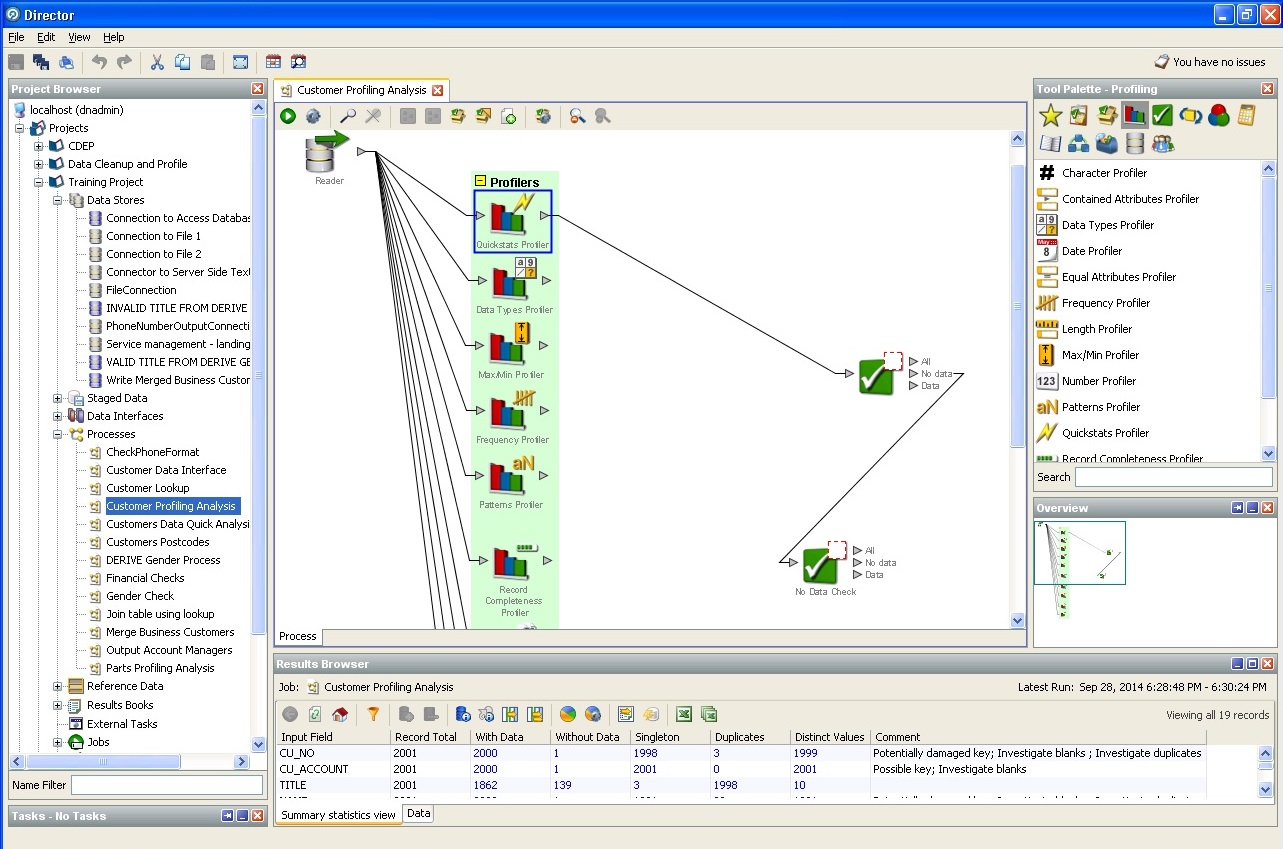
随机数据库探查器操作:
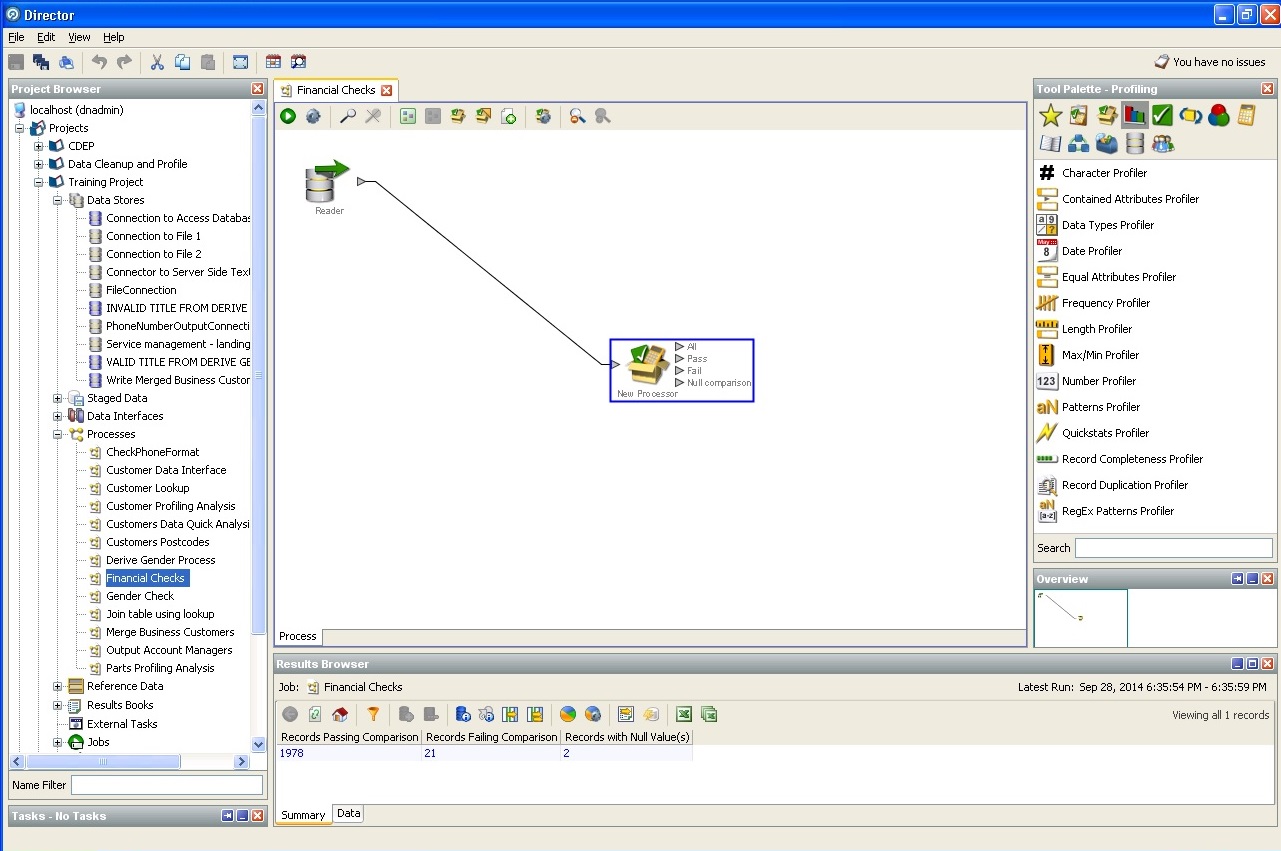
财务偿付能力基础审核:
使用邮政编码:
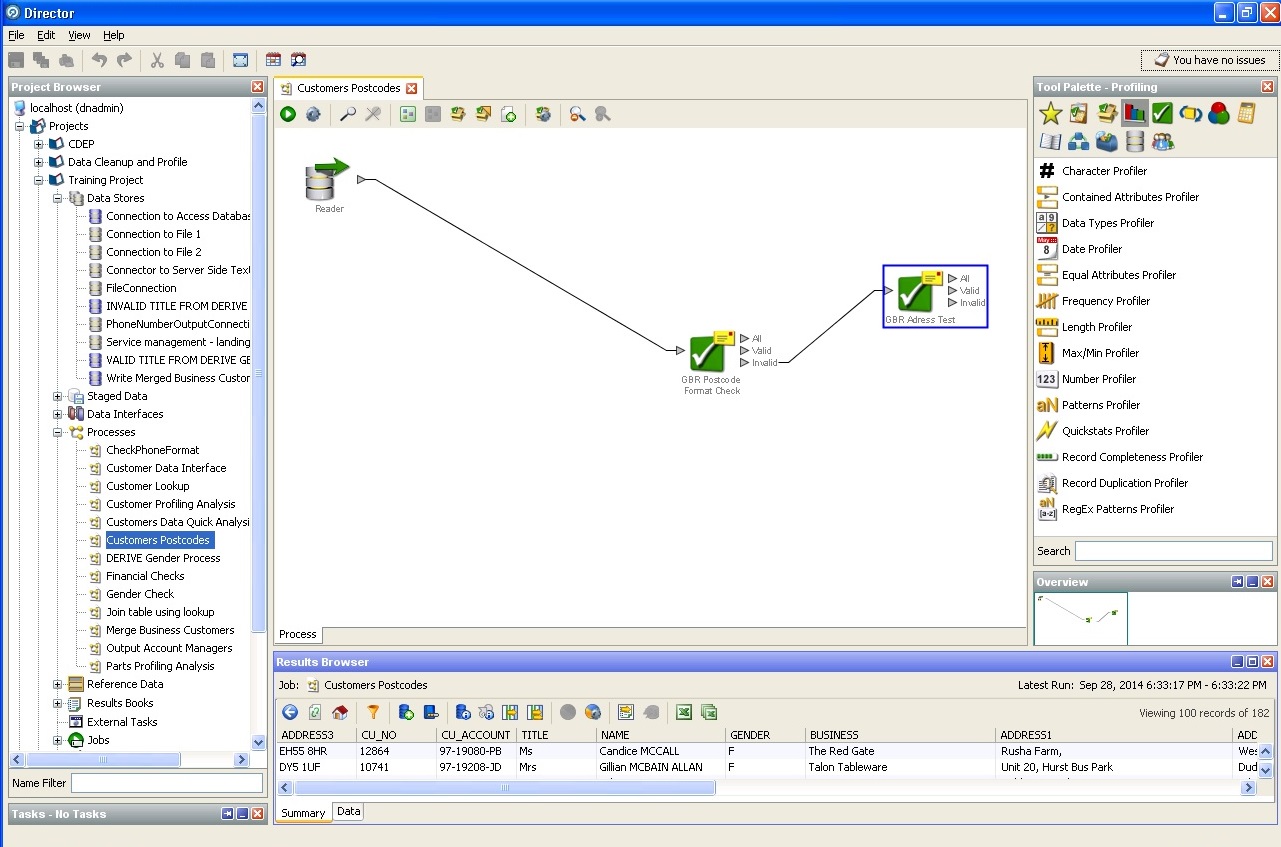
清洁邮寄地址:
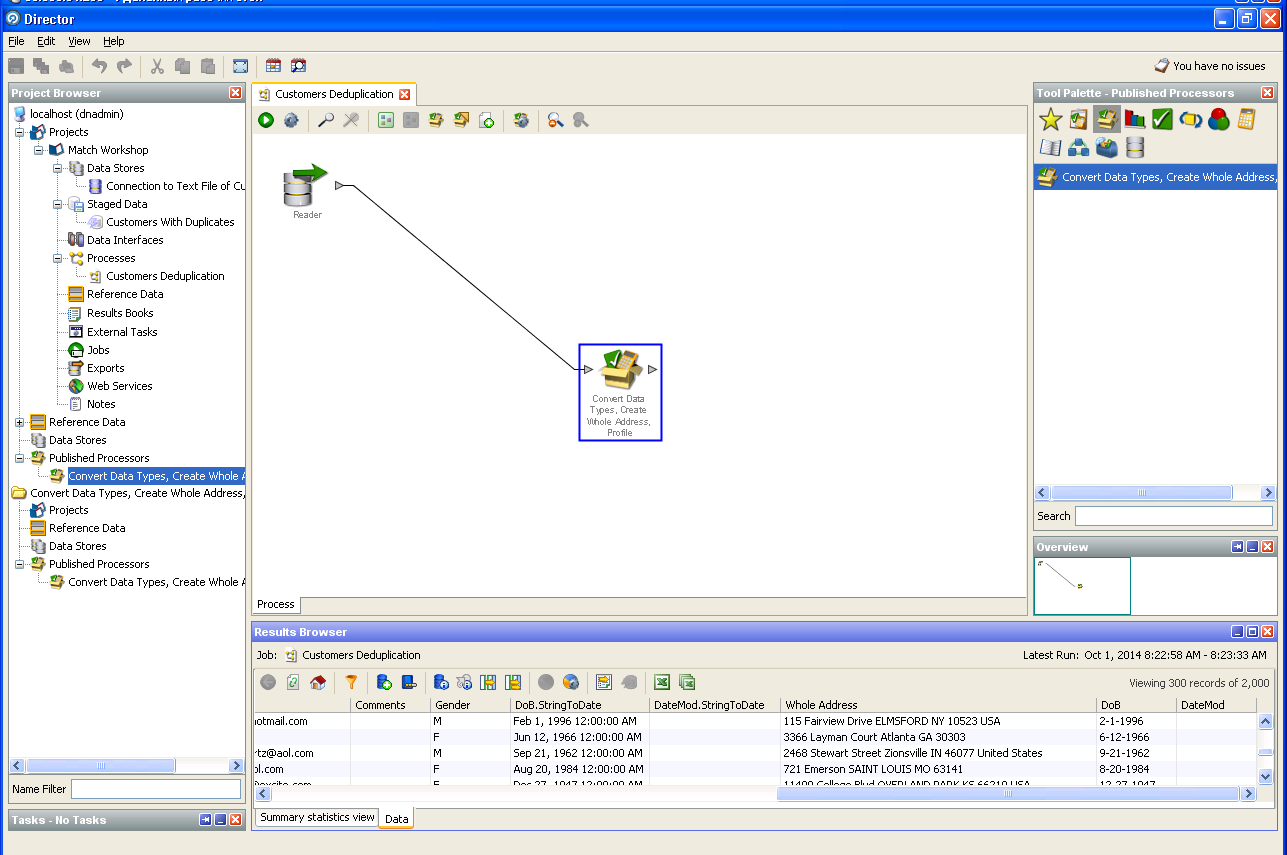
清除用户数据:
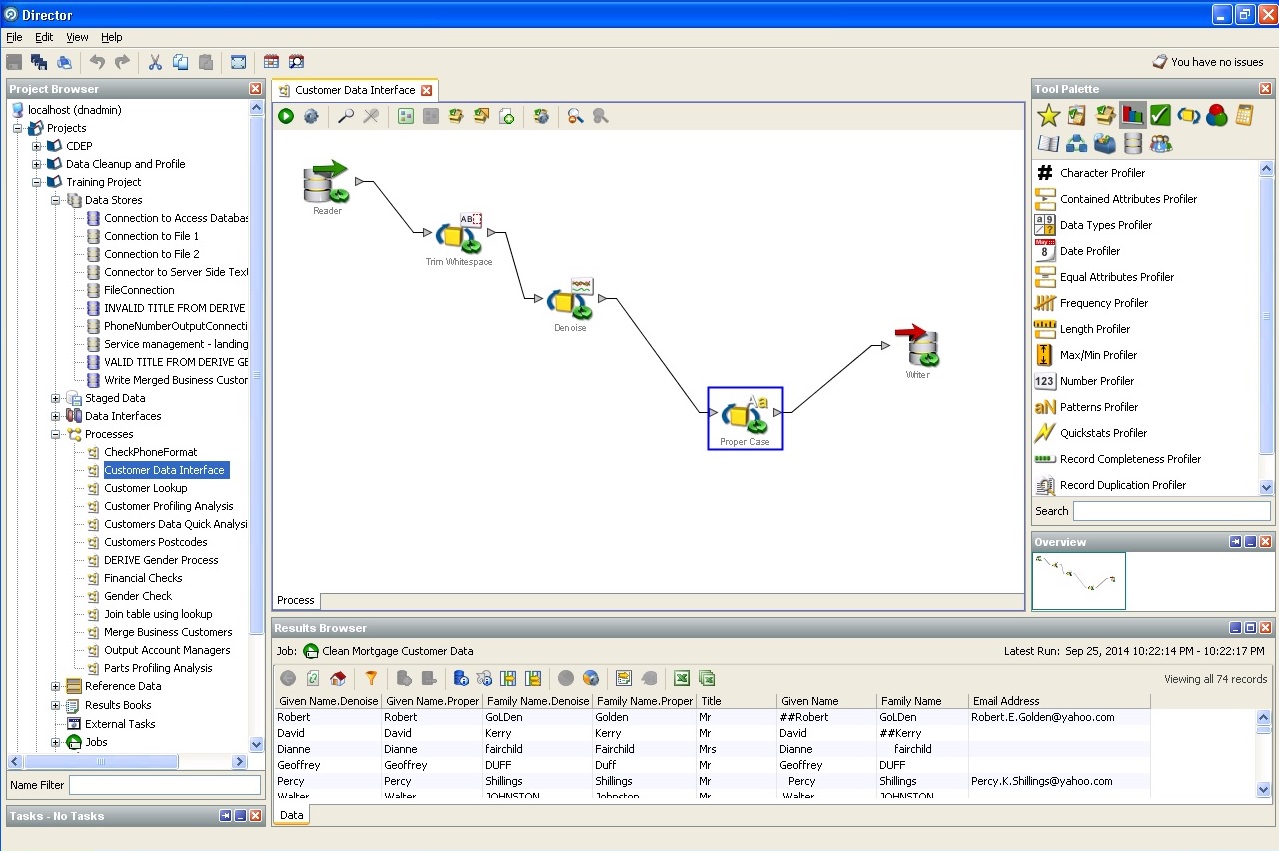
将记录分配给一个或另一个置信区间:
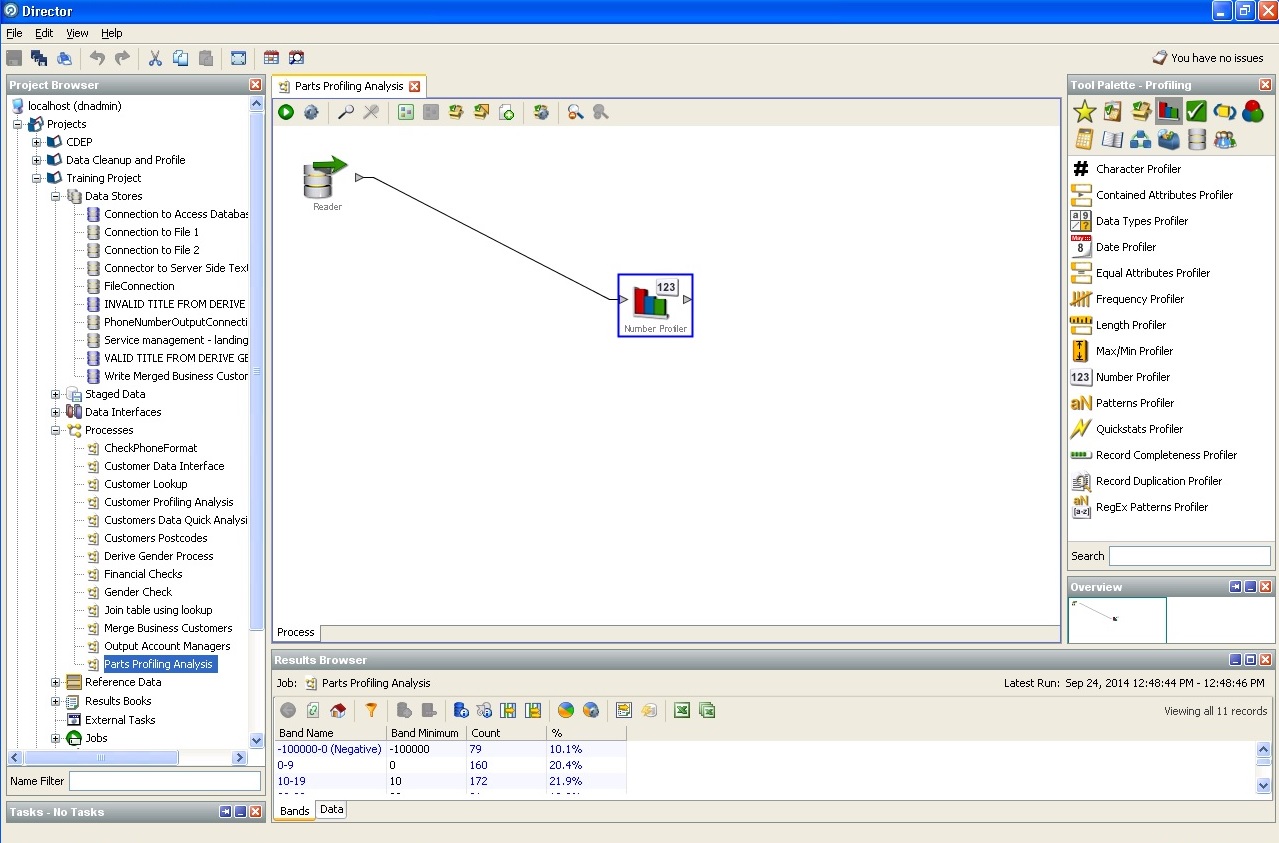
根据间接数据确定用户的性别:
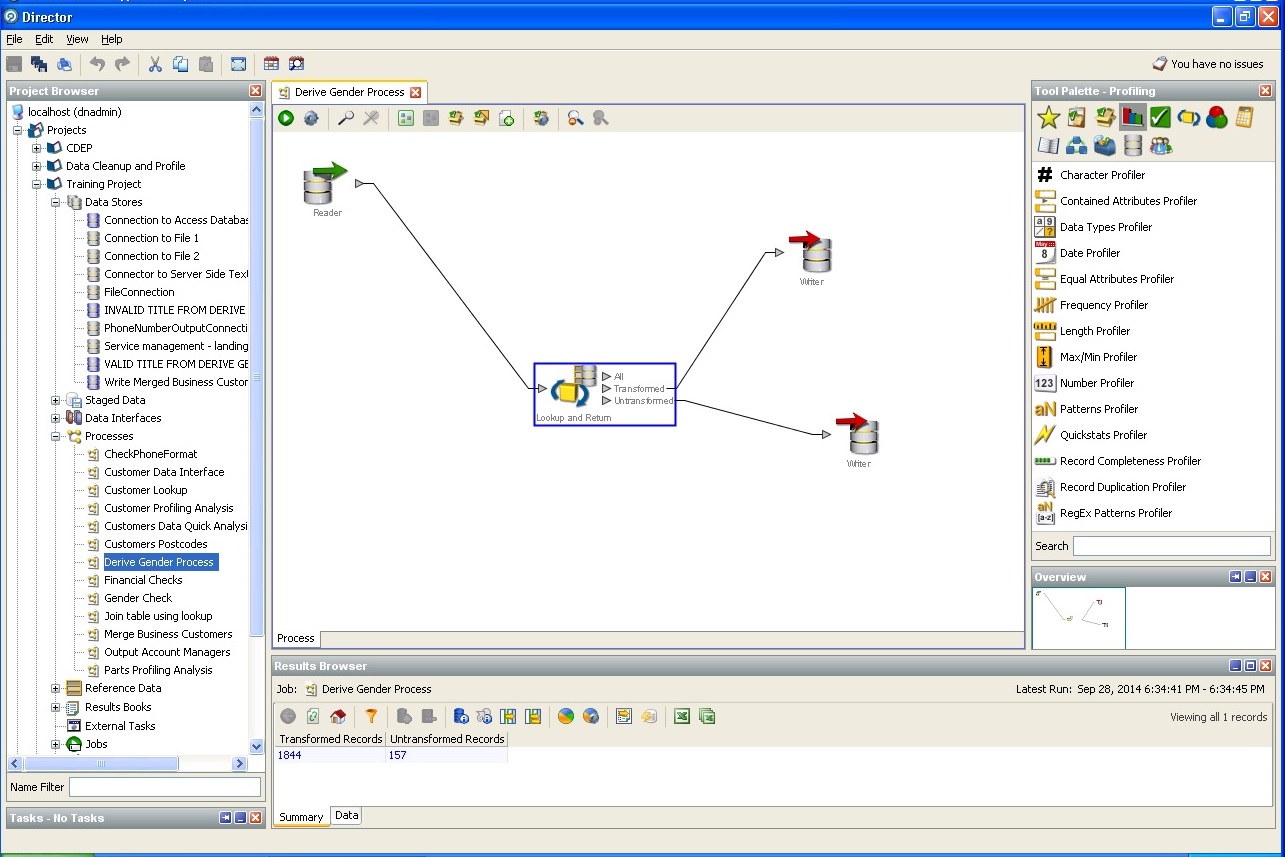
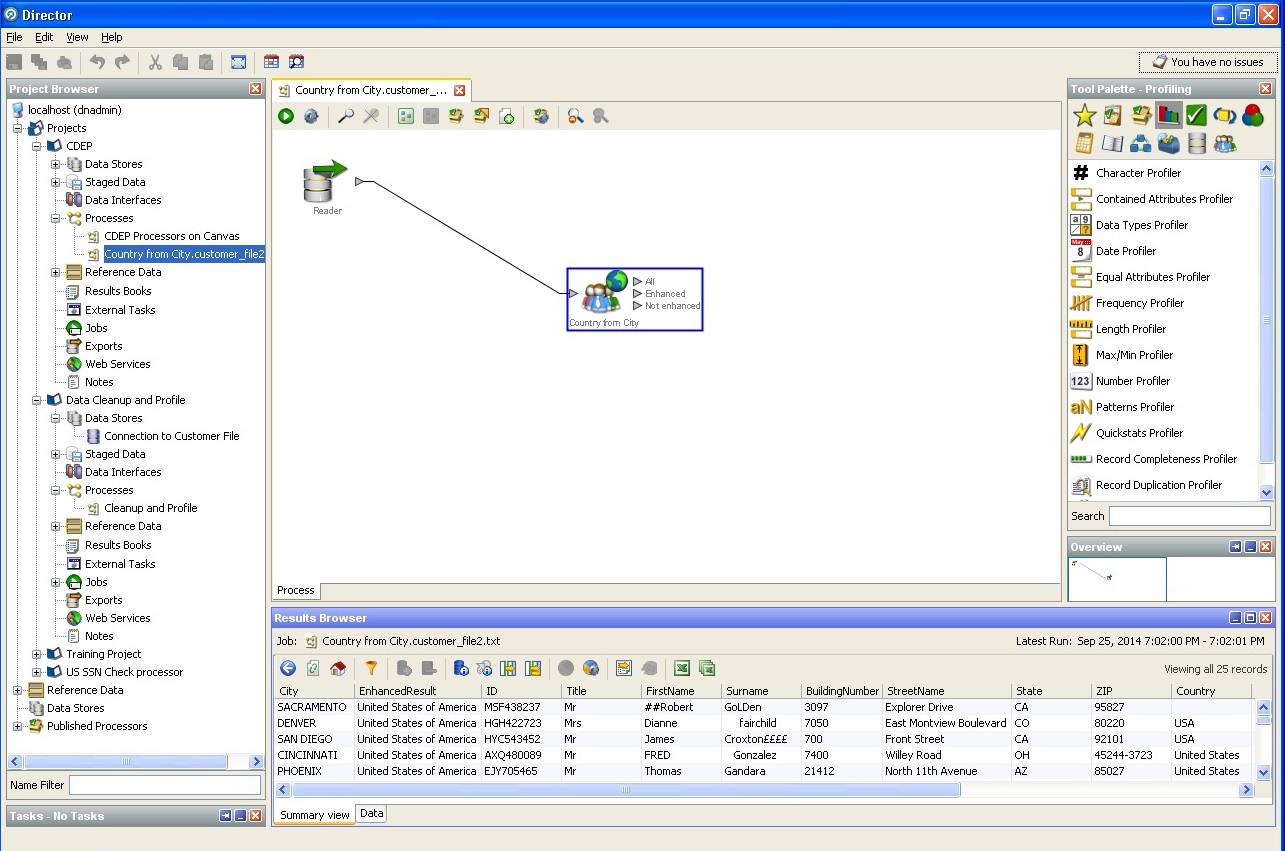
城市和国家/地区,州的定义:
随机数据库中最简单的密钥搜索:
用户数据重复数据删除:
 5.关于Oracle EDQ工作结果的有趣观察。
5.关于Oracle EDQ工作结果的有趣观察。比较作家和诗人对文学的贡献的原则之一是比较他们的诗歌和文学词典。 我们提供了一些空闲时间编译的字典,用于测试针对Oracle EDQ,Python,Java的现成解决方案。 如果评论中的语言学家发表了他们的结果,我们将不胜感激。
p.p.
| 这个词
| 发生频率
|
雄狮
托尔斯泰,战争与和平。 频率表的片段
版权词典。
| 我
乌拉尼亚布罗德斯基。
| 我
布罗德斯基全集,频率词典的一部分
作者。
| N.
涅克拉索夫,完整版频率词典的一部分
散文。
|
1。
| 和
| 10351
| 在
1037
| 在
5745
| 和
3420
|
3。
| 在
| 5185
| 和
647
| 和
4500
| 在
2108
|
4。
| 不
| 4292
| 不
391
| 不
3022
| 不
1726
|
5,
| 什么
| 3845
| 在
341
| 在
2239
| 我
1040
|
6。
| 他是
| 3730
| 怎么
329
| 怎么
1758
| 与
883
|
7
| 在
| 3305
| 与
237
| 与
1674
| 在
854
|
8。
| 与
| 3030
| 什么
168
| 什么
1531
| 怎么
763
|
9。
| 怎么
| 2097
| 到
148
| 和
1200
| 什么
693
|
10。
| 我
| 1896年
| 来自
147
| 我
1040
| 他是
644
|
11。
| 他的
| 1882
| 来自
104
| 到
922
| 你
475
|
12
| 到
| 1771年
| 我
90
| 来自
810
| 但是
472
|
13
| 然后
| 1600
| 在哪里
88
| 全部
748
| 但是
449
|
14。
| 她是
| 1564
| 比
88
| 由
744
| 所以
383
|
15
| 但是
| 1234
| 为
76
| 你
721
| 到
367
|
16。
| 是的
| 1208
| 由
74
| 在
713
| 全部
344
|
17。
| 说过
| 1135
| 但是
72
| 为
687
| 为
313
|
18岁
| 原为
| 1125
| 都不
70
| 来自
635
| 给我
309
|
19
| 所以
| 1032
| 会
69
| 但是
617
| 是的
294
|
20
| 王子
| 1012
| 然后
67
| 他是
592
| 他的
275
|
21
| 为
| 985
| 你
67
| 但是
584
| 然后
232
|
22
| 但是
| 962
| 关于
66
| 然后
540
| 原为
229
|
23。
| 给他
| 918
| 但是
63
| 关于
538
| 由
224
|
24
| 全部
| 908
| 在那边
61
| 是的
524
| 没有啦
223
|
25岁
| 由
| 895
| 我是
61
| 我是
489
| 都不
222
|
26
| 她的
| 885年
|
| 但是
463
| 关于
213
|
27。
| 来自
| 845
|
| 在哪里
449
| 他们的
212
|
28。
|
|
|
| 比
443
| 来自
209
|
29。
|
|
|
| 一
428
| 来自
207
|
30岁
|
|
|
| 一样的
422
| 我们是
206
|
结论:在过去的一百年里,在诗人中,俄语在单个单词出现频率方面的统计数据并没有太大变化-单词更为“悠扬”。 顺便说一句,达里亚·顿佐娃(Daria Dontsova)的统计数字在整个作品的频率词典领域中与托尔斯泰(Leo Tolstoy)吻合。
6.作为结论的几种正式计算。伊万诺夫·伊万诺夫·伊万诺维奇(Ivanov Ivanovich)居住在我国大约6万人。 假设在某个数据库中某个地方假设存储了100个表,每个表中有10个键字段,并且每个键可以采用6万个值,则我们得出数据库内部唯一键状态的总数约为6000万。 即使将两个键混合在一个表中,它们也可以在一个表中生成多达20个唯一状态。 总共多达数千个可以进入唯一状态的基础。 同意花10%的开发时间和5-7%的ETL执行时间来捕捉这些琐事是不被允许的吗?
UPD1如果您厌倦了为工作中的每个重要目录拖拽控制系统,那么MDM(主数据管理)系统将为您提供帮助。 当然,我们会向市场提供此类系统,包括免费软件版本。
UPD2在会议上,经常会问到一个问题:“如何创建更便宜的数据质量管理系统”。 我想请您考虑将本文作为该问题的简要介绍,并简化EDQ功能。 是的,但是,您可以采用一堆ODI + EDQ并做得很好,但这是进一步叙述的主题。