自首个KOMPAS 3D版本-V5.11发行以来已经过去了20年。 在这段时间里,我们意识到用户的需求与KOMPAS-3D的功能成正比增长,就像KOMPAS的功能与用户的需求成比例地增长一样。 只有一个障碍:建立了多年的技术部分,我们在处理复杂的大型项目时遇到了性能问题。 现在,这条线已被克服,我们准备告诉我们如何通过30多个基本操作来加速KOMPAS-3D。

耐心不能被加速
我们如何理解是时候“加速”了?
如果12年前有足够的工作来处理多达数千个零部件的装配体,那么现在KOMPAS的用户想要进行的复杂项目涉及一个装配体中300,000个零部件,而只有几百万个零部件。
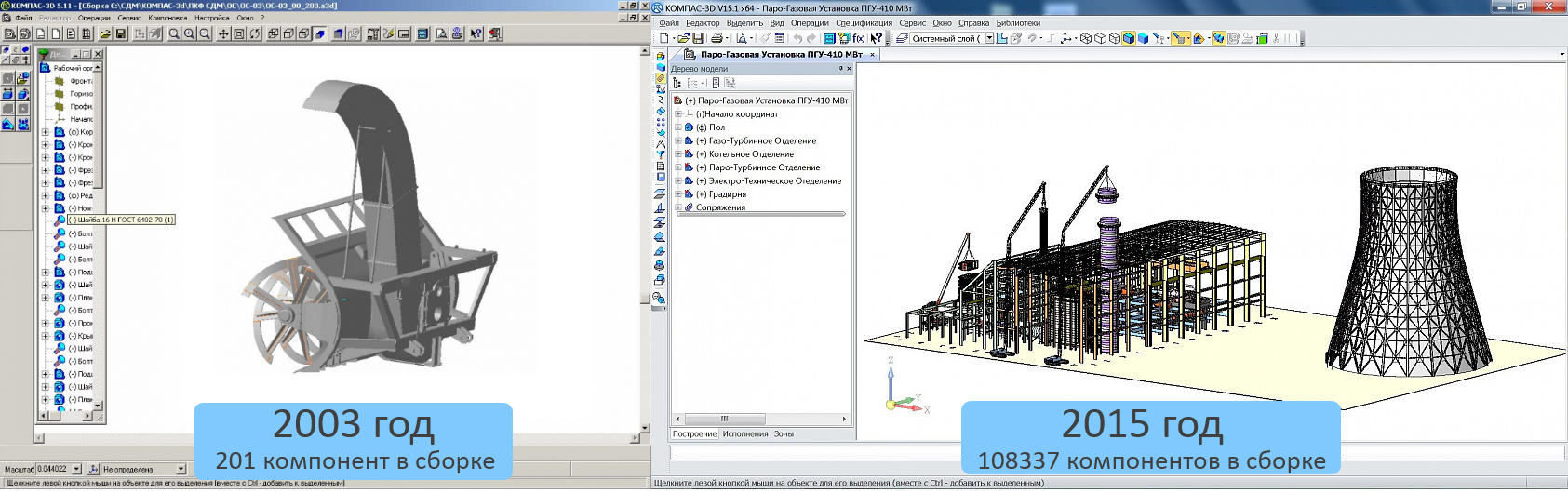 KOMPAS-3D用户项目的演变:左侧为K-700A,K-703MBA拖拉机的除雪铣刨和转子设备,右侧为蒸汽燃气装置PGU-410 MW 。 如果很难看到,请单击图片。
KOMPAS-3D用户项目的演变:左侧为K-700A,K-703MBA拖拉机的除雪铣刨和转子设备,右侧为蒸汽燃气装置PGU-410 MW 。 如果很难看到,请单击图片。在ServiceDesk(技术支持)中,我们收到了“我无法在早上打开工厂”和“模型已打开但无法旋转”的样式的请求。
只有一个结论-COMPAS需要认真修改。
第一次变化
主要任务是在使用大型装配体时提高系统性能。 而不是有条件地增加10-30%,而是增加几倍。
为了解决这些问题,我们在2015年成立了一个工作组来加速KOMPAS-3D。 一种快速反应的程序员,测试人员和分析人员。
 我们的速度队
我们的速度队帮助:之前我们一直在进行加速工作-这些既是优化又是新功能,可以使我们解决大型装配体中的某些问题。 但是,这些任务并不像现在这样雄心勃勃,而且工作也不是那么繁琐。
您如何选择加速标准?
我们选择了5个加速方向:
- 渲染(模型图像的旋转,移动和缩放),
- 向大型装配体添加零件
- 组装开口
- 在装配中进行编辑,
- 投影。
在选择这些区域时,我们依赖于以下几个方面:
- 自己的经验和研究,
- 对技术支持请求的分析和对错误基础的分析(在我们的工具中有一个特殊的标签“性能”,其中指出了对性能至关重要的问题),
- 用户调查结果(用户通常在ASCON活动中填写此类问卷),
更高的权力 。
 在这里,我们正在讨论一些东西。
在这里,我们正在讨论一些东西。与工作组的成立一起,我们创建了自己的信息空间-知识库-我们写下了那里的所有任务,收集了可能加速领域中的想法并将其系统化。 结果,需求开始随着进一步工作的场景而形成,因此可以控制性能。
我们在处理版本时采用的另一个公理是:生产力不能简单地加以提高,然后就被遗忘了。 需要测量并记录当前状态,然后我们才能从中击退。 那时,起点是V16版本(我们的故事仍在2015年),需要由我们的TK脚本控制。 几个关键点的性能是手动控制的,但是现在有了POI,该过程是自动化的。
 程序员,团队负责人Anton Sidyakin:
程序员,团队负责人Anton Sidyakin:
“由于实施了POI(兴趣点)系统,我们使流程自动化。 这些是位于源代码中的特殊标记。 根据他们的说法,用用户语言描述的KOMPAS-3D执行脚本,您不仅可以获得程序员可以理解的报告,还可以得到测试人员的分析人员可以理解的报告,并有助于找出KOMPAS-3D在特定时刻的工作以及花费了多少时间。 然后可以自动处理此信息并将其与源数据进行比较。”
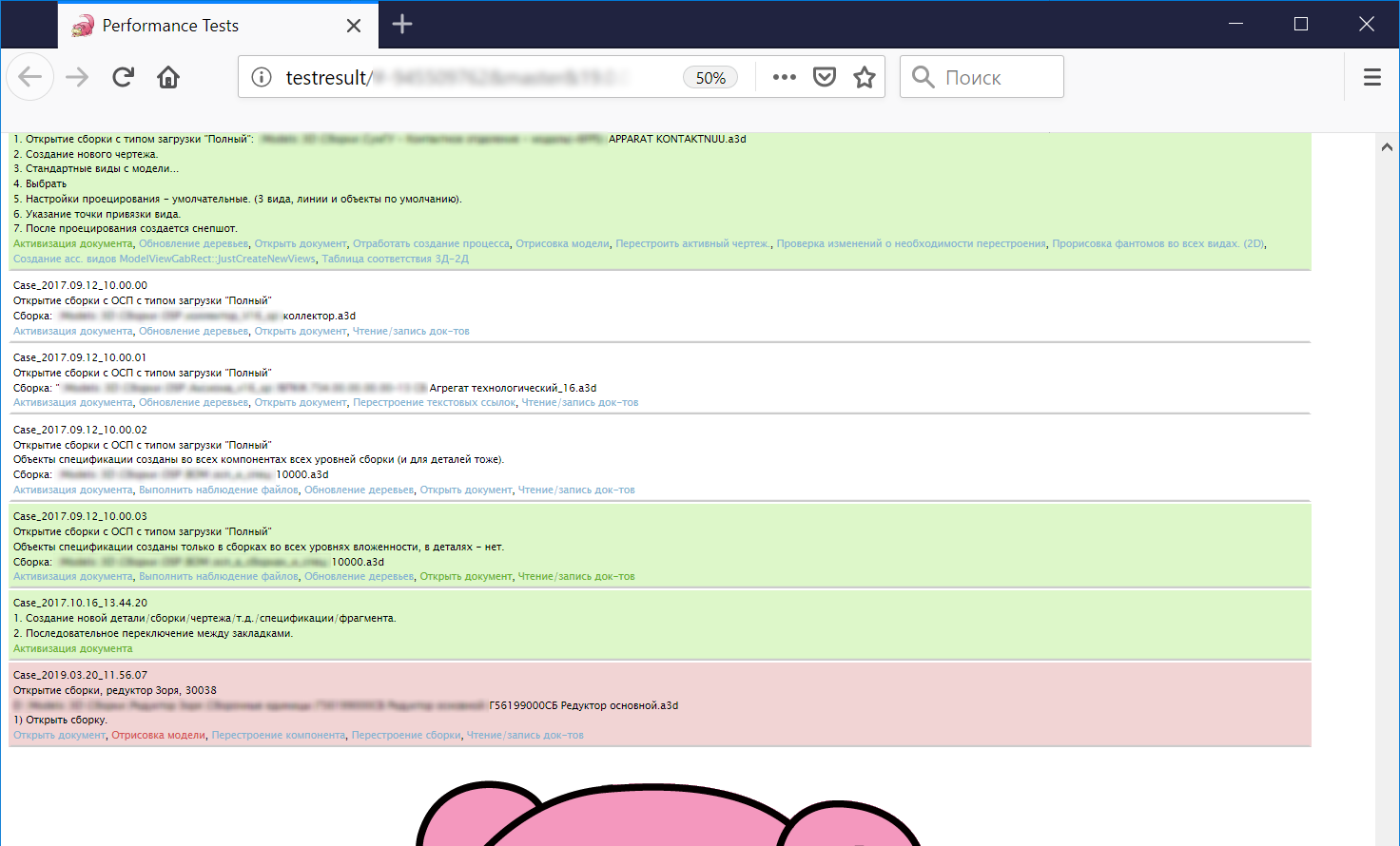
自动性能测试的结果。 顺便说一句,读过这个地方的人现在知道KDPV平板是我们加速器团队的象征。 他们将慢代码视为慢代码)
比较中使用了哪些模型?
我们决定专注于符合“大型装配体”标准的实际用户模型。
计算机3D建模Aces竞赛
的模型数据库非常有用。
以下是我们最喜欢的模型的屏幕截图。 当然,这还不是全部,而且,我们有信心,近年来的顶级机型很快就会变得熟悉,KOMPAS不仅可以在常规的高速模式下与其配合使用,而且还可以使用它们。
当需要进一步加载系统时,除了这些模型之外,还使用了特殊的“预制大杂烩”,例如:
我们还使用了综合模型:在某些情况下,某些问题在它们上更明显,并且更便于调试和测试。
关于发展和取得的成果
画图
首先,他们试图加快渲染速度(参与调查的大多数用户也要求这样做)。
在放置模型或更改其显示的所有过程中,渲染速度至关重要。 这不仅是模型的旋转,移动或缩放。 在更新模型图像的过程中,渲染速度也很重要:
- 将零部件添加到装配体
- 选择对象的基本对象(面部,边缘等),
- 突出显示模型的选定部分(组件,面),
- 更改对象的可见性(隐藏/显示组件)。
这些远非使用可视化子系统的所有情况。 因此,很明显,为什么渲染加速已成为我们的首要任务。
同时,重要的是不仅要使用生产效率高的现代视频卡的功能,而且不要忘记那些使用功能不强的现代硬件的人。
工作的结果是实现了两个渲染选项:
- 基本-启用Open GL 2.0扩展。 对视频卡性能的要求较低。 提供良好的渲染加速,
- “改进”-使用OpenGL 4.5的现代扩展。 对视频卡的特性要求很高。 在现代地图上提供最大的渲染加速
提示: v18的渲染设置。
v18的渲染设置。默认情况下,“自动检测”有效-根据支持的OpenGL扩展选择所需的选项。
 Yuri Korchagin,程序员:
Yuri Korchagin,程序员:
“在显示大型场景的性能问题上,很明显,很多资源都花在了场景周围和计算显示图元时所用的参数上。
另一个问题与大量的绘制调用(对OpenGL API的调用,导致将几何图形输出到帧缓冲区)有关。
初始状态还假定所有数据都从RAM传输到视频卡。 对于大型装配体,这些是数百万个三角形。
由于需要多次提高生产率,因此在此无需进行外观校正。 因此,决定很大程度上重写可视化模块。
第一步是使用视频内存来缓存图形数据(三角剖分,线框,面)。 通过将这些数据移至GPU,我们成功地将FPS提升了2至3倍。
然后创建适合可视化的数据模型。 也就是说,我们摆脱了对3D模型的要求,因为它可能会占用大量资源,这也带来了积极的效果。
下一步是研究三角剖分的质量和数量。 通常,小细节的显示精度过高,反之亦然-在某些情况下,用户会在屏幕上看到“切碎”的模型,而不是光滑的表面。
我们决定使用多个细节级别,并考虑角度偏差来应用图元的近似值。 这样一来,两只鸟被一块石头杀死了:它们提高了质量并消除了GPU上的过多负载。”
扰流器:关于三角剖分
由分析工程师Nikita Batyanov指定:
为了使模型更正确且总体上令人满意,我们决定以最大角度偏差补充三角测量参数。 以前,我们仅使用最大线性偏差参数。
让我提醒您:为了使视频卡能够绘制我们对物体的理论表示,必须将它们分成三角形。 这样的三角形越多,图像看起来越像“理想”,但视频卡上的负载越强。
使用最大角度偏差的三角剖分算法可让您更准确地显示某些模型,而不会像仅使用最大线性偏差那样增加三角形的数量。
“我们可以绘制相对于整个模型尺寸较小的对象,同时稍微夸大三角形的数量。”
Yuri Korchagin,程序员:
“嗯,显示模型已经变得更快,但没有我们想要的那么快。 在此阶段,我们意识到无法从这种方法中获得更多收益。
另一方面,使用最新方法将需要最新的视频卡,这与兼容性要求背道而驰,并且某些用户显然不喜欢它。 因此,上述改进已可以用作“基本”渲染选项。
然后乐趣就开始了……”
在下一部分中,我们将继续介绍渲染,并展示在装配旋转期间测量渲染速度,MTC计算,向装配中添加零部件以及讲述局部载荷类型的外观的结果。
对于甜点,他们还留下了一段视频供您比较,以比较船舶动力装置的减速器在旋转,缩放和移动期间的渲染速度。
第一部分结束。 待续 。