在之前的文章中,我们讨论了PostgreSQL
索引引擎 ,
访问方法的接口以及两种访问方法:
哈希索引和
B-tree 。 在本文中,我们将描述GiST索引。
要点
GiST是“广义搜索树”的缩写。 这是一个平衡的搜索树,就像前面讨论的“ b树”一样。
有什么区别? “ Btree”索引严格地与比较语义相关:它支持“更大”,“更少”和“相等”运算符(但非常强大!)。但是,现代数据库存储这些运算符所针对的数据类型毫无意义:地理数据,文本文档,图像等
GiST索引方法对这些数据类型有帮助。 它允许定义规则以在平衡树上分布任意类型的数据,以及允许使用此表示形式供某些操作员访问的方法。 例如,对于空间数据,GiST索引可以在相对位置算符(位于左侧,右侧,包含等)的支持下“容纳” R树,而在相交或包含算符的支持下为集合的RD树。
由于可扩展性,可以在PostgreSQL中从头开始创建一种全新的方法:为此,必须实现与索引引擎的接口。 但是,这不仅需要对索引逻辑的预想,还需要对数据结构映射到页面,锁的有效实现以及对预写日志的支持。 所有这些都需要具备很高的开发人员技能和巨大的人力资源。 GiST通过接管低级问题并提供其自己的界面来简化任务:几种功能与技术无关,而与应用程序领域有关。 从这个意义上讲,我们可以将GiST视为构建新访问方法的框架。
结构形式
GiST是由节点页面组成的高度平衡树。 节点由索引行组成。
通常,叶节点的每一行(叶行)都包含一些
谓词 (布尔表达式)和对表行(TID)的引用。 索引数据(键)必须符合此谓词。
内部节点的每一行(内部行)还包含一个
谓词和对子节点的引用,并且子子树的所有索引数据都必须满足此谓词。 换句话说,内部行的谓词包括所有子行的谓词。 GiST索引的这一重要特征取代了B树的简单排序。
GiST树中的搜索使用专门的
一致性功能 (“ consistent”)-接口定义的功能之一,并且以自己的方式为每个受支持的操作员系列实现。
为索引行调用一致性函数,并确定该行的谓词是否与搜索谓词(指定为“
索引字段运算符表达式 ”)一致。 对于内部行,此函数实际上确定是否需要下降到相应的子树,对于叶行,此函数确定索引的数据是否满足谓词。
搜索从根节点开始,就像普通的树搜索一样。 一致性功能允许找出有意义的子节点(可能有多个)可以输入,而哪些子节点不需要。 然后对找到的每个子节点重复该算法。 如果节点是叶子,则由一致性函数选择的行将作为结果之一返回。
搜索是深度优先的:算法首先尝试到达叶节点。 这样可以在可能的情况下尽快返回第一结果(如果用户只对几个结果感兴趣,而不对所有结果感兴趣,这可能很重要)。
让我们再一次注意一下,一致性函数与“更大”,“更少”或“相等”运算符无关。 一致性函数的语义可能完全不同,因此,不假定索引以特定顺序返回值。
我们不会讨论GiST中值的插入和删除算法:更多
接口函数执行这些操作。 然而,有一点很重要。 将新值插入索引后,将选择该值在树中的位置,以便其父行的谓词尽可能少地扩展(理想情况下完全不扩展)。 但是,当删除值时,父行的谓词不再减少。 仅在以下情况下会发生这种情况:将页面分为两部分(当页面没有足够的空间来插入新的索引行时),或者从头开始重新创建索引(使用REINDEX或VACUUM FULL命令)。 因此,用于频繁更改数据的GiST索引的效率会随着时间的推移而降低。
此外,我们将考虑一些有关GiST的各种数据类型和有用属性的索引示例:
- 点(和其他几何实体)和最近邻居的搜索。
- 间隔和排除约束。
- 全文搜索。
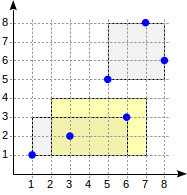
点的R树
我们将通过一个平面中的点的索引示例来说明上述内容(我们也可以为其他几何实体建立类似的索引)。 常规的B树不适合这种数据类型的数据,因为没有为点定义比较运算符。
R-tree的想法是将平面划分为矩形,这些矩形总共覆盖所有索引的点。 索引行存储一个矩形,并且可以这样定义谓词:“寻找的点位于给定的矩形内”。
R树的根将包含几个最大的矩形(可能相交)。 子节点将包含较小尺寸的矩形,这些矩形嵌入到父节点中,并且总覆盖所有基础点。
从理论上讲,叶节点必须包含要索引的点,但是所有索引行中的数据类型必须相同,因此,再次存储了矩形,但“折叠”成点。
为了可视化这种结构,我们提供了R树的三个级别的图像。 点是机场的坐标(类似于
演示数据库的“ airports”表中的坐标,但提供了来自
openflights.org的更多数据)。
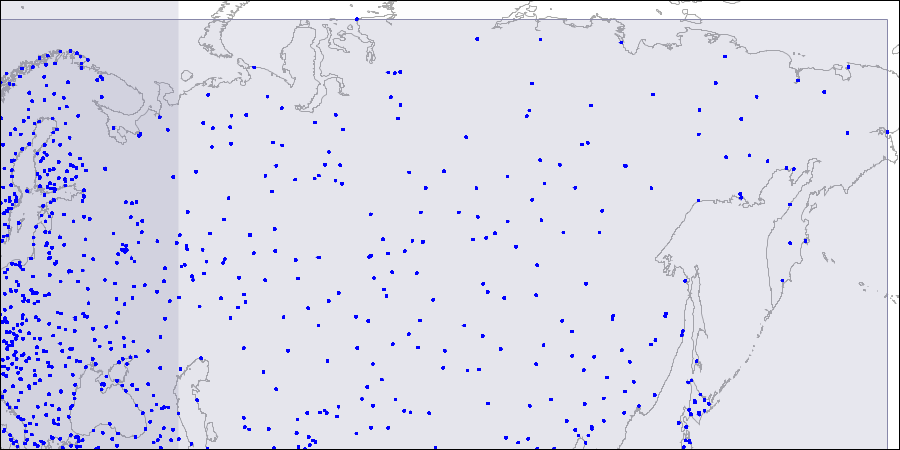 一级:两个大的相交矩形可见。
一级:两个大的相交矩形可见。 第二级:将大矩形分割成较小的区域。
第二级:将大矩形分割成较小的区域。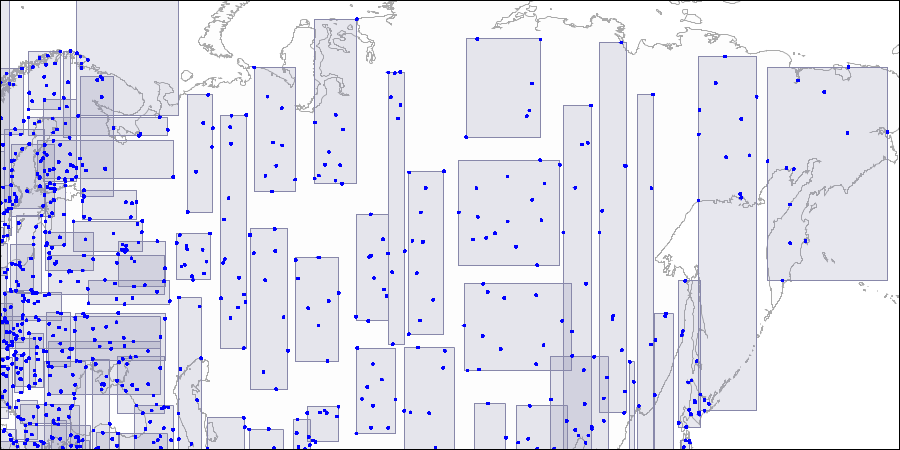 第三级:每个矩形包含的点数最多可以容纳一个索引页。
第三级:每个矩形包含的点数最多可以容纳一个索引页。现在让我们考虑一个非常简单的“一级”示例:
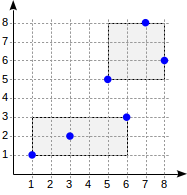
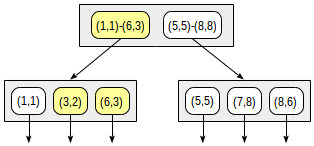
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index on points using gist(p);
通过这种拆分,索引结构将如下所示:
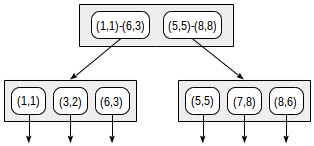
创建的索引可用于加快以下查询的速度,例如:“查找给定矩形中包含的所有点”。 此条件可以形式如下:
p <@ box '(2,1),(6,3)' (“ points_ops”家族的运算符
<@表示“包含于”):
postgres=# set enable_seqscan = off; postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN ---------------------------------------------- Index Only Scan using points_p_idx on points Index Cond: (p <@ '(7,4),(2,1)'::box) (2 rows)
运算符的一致性函数(“
索引字段 <@
表达式 ”,其中
索引字段是一个点,
表达式是一个矩形)定义如下。 对于内部行,如果其矩形与
表达式定义的矩形相交,则返回“是”。 对于叶行,如果该点的点(“折叠”矩形)包含在表达式定义的矩形中,则该函数返回“是”。
搜索从根节点开始。 矩形(2,1)-(7,4)与(1,1)-(6,3)相交,但不与(5,5)-(8,8)相交,因此不需要下降到第二个子树。
到达叶节点后,我们经过其中包含的三个点,并返回其中两个结果:(3.2)和(6.3)。
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p ------- (3,2) (6,3) (2 rows)
内部构造
不幸的是,常规的“ pageinspect”不允许查看GiST索引。 但是还有另一种方法可用:“ gevel”扩展。 它不包括在标准交付中,因此请参阅
安装说明 。
如果一切正确,将为您提供三个功能。 首先,我们可以获得一些统计信息:
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat ------------------------------------------ Number of levels: 4 + Number of pages: 690 + Number of leaf pages: 625 + Number of tuples: 7873 + Number of invalid tuples: 0 + Number of leaf tuples: 7184 + Total size of tuples: 354692 bytes + Total size of leaf tuples: 323596 bytes + Total size of index: 5652480 bytes+ (1 row)
显然,该索引在机场坐标上的大小为690页,并且该索引包括四个级别:上图显示了根级别和两个内部级别,而第四级是叶子。
实际上,八千点的索引会小很多:此处创建时使用了10%的填充因子,以保持清晰度。
其次,我们可以输出索引树:
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree ----------------------------------------------------------------------------------------- 0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) + 1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) + 1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) + 1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) + 2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) + 3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) + 4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) + ...
第三,我们可以输出存储在索引行中的数据。 请注意以下细微差别:函数的结果必须强制转换为所需的数据类型。 在我们的情况下,此类型为“框”(边界矩形)。 例如,注意顶层的五行:
postgres=# select level, a from gist_print('airports_coordinates_idx') as t(level int, valid bool, a box) where level = 1;
level | a -------+----------------------------------------------------------------------- 1 | (47.663586,80.803207),(-39.2938003540039,-90) 1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336) 1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047) 1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291) 1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088) (5 rows)
实际上,以上提供的数字仅是根据此数据创建的。
搜索和订购运营商
到目前为止讨论的运算符(例如谓词
p <@ box '(2,1),(7,4)' )可以称为搜索运算符,因为它们在查询中指定了搜索条件。
还有另一种运算符类型:订购运算符。 它们用于ORDER BY子句中排序顺序的规范,而不是列名的常规规范。 以下是此类查询的示例:
postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p ------- (5,5) (7,8) (2 rows)
p <-> point '(4,7)'是使用排序运算符
<->的表达式,它表示从一个参数到另一个参数的距离。 查询的意思是返回最接近该点(4.7)的两个点。 这样的搜索称为k-NN-k最近邻居搜索。
为了支持这种查询,访问方法必须定义一个附加的
distance函数 ,并且必须在适当的运算符类(例如,用于点的“ points_ops”类)中包括排序运算符。 以下查询显示了运算符及其类型(“ s”-搜索和“ o”-排序):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------+-------------+-------------- <<(point,point) | s | 1 strictly left >>(point,point) | s | 5 strictly right ~=(point,point) | s | 6 coincides <^(point,point) | s | 10 strictly below >^(point,point) | s | 11 strictly above <->(point,point) | o | 15 distance <@(point,box) | s | 28 contained in rectangle <@(point,polygon) | s | 48 contained in polygon <@(point,circle) | s | 68 contained in circle (9 rows)
还显示了策略的数量,并解释了其含义。 显然,比“ btree”策略要多得多,只有某些策略支持点数。 可以为其他数据类型定义不同的策略。
对索引元素调用distance函数,并且必须计算从表达式(“
indexed-field ordering-operator expression ”)定义的值到给定元素的距离(考虑到运算符的语义)。 对于叶元素,这只是到索引值的距离。 对于内部元素,该函数必须返回到子叶元素的最小距离。 由于遍历所有子行会非常昂贵,因此允许该函数乐观地低估距离,但以降低搜索效率为代价。 但是,绝对不允许该函数高估距离,因为这会破坏索引的工作。
distance函数可以返回任何可排序类型的值(
如前所述 ,PostgreSQL将使用来自“ btree”访问方法的适当运算符族的比较语义来排序值)。
对于平面中的点,以一种通常的意义解释距离:
(x1,y1) <-> (x2,y2)等于横坐标和纵坐标的差平方和的平方根。 从点到边界矩形的距离被认为是从点到该矩形的最小距离;如果点位于矩形内,则为零。 无需遍历子点即可轻松计算此值,并且该值肯定不大于到任何子点的距离。
让我们考虑以上查询的搜索算法。
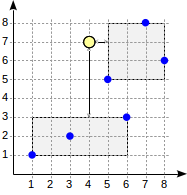
搜索从根节点开始。 该节点包含两个边界矩形。 到(1,1)-(6,3)的距离是4.0,到(5,5)-(8,8)的距离是1.0。
按照增加距离的顺序遍历子节点。 这样,我们首先下降到最近的子节点并计算到这些点的距离(我们将在图中显示数字以提高可见性):

该信息足以返回前两个点(5,5)和(7,8)。 由于我们知道到矩形(1,1)-(6,3)内的点的距离为4.0或更大,因此我们不必下降到第一个子节点。
但是,如果我们需要找到前三点呢?
postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
尽管第二个子节点包含所有这些点,但我们无法返回(8,6)而不查看第一个子节点,因为该节点可以包含更近的点(因为4.0 <4.1)。

对于内部行,此示例阐明了对距离函数的要求。 通过为第二行选择较小的距离(4.0而不是实际的4.5),我们降低了效率(算法不必要地开始检查额外的节点),但并未破坏算法的正确性。
直到最近,GiST还是唯一能够与订购运营商打交道的访问方法。 但是情况发生了变化:RUM访问方法(将进一步讨论)已经加入了这组方法,好的旧B树也不太可能会加入它们:我们的同事Nikita Glukhov开发的补丁正在由社区讨论。
从2019年3月开始,即将发布的PostgreSQL 12(也由Nikita创作)中为SP-GiST添加了k-NN支持。 B树的修补程序仍在进行中。
间隔的R树
使用GiST访问方法的另一个示例是间隔的索引,例如时间间隔(“ tsrange”类型)。 所有不同之处在于内部节点将包含边界间隔,而不是边界矩形。
让我们考虑一个简单的例子。 我们将出租一间小屋并将预订间隔存储在表格中:
postgres=# create table reservations(during tsrange); postgres=# insert into reservations(during) values ('[2016-12-30, 2017-01-09)'), ('[2017-02-23, 2017-02-27)'), ('[2017-04-29, 2017-05-02)'); postgres=# create index on reservations using gist(during);
索引可用于加快以下查询的速度,例如:
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during ----------------------------------------------- ["2016-12-30 00:00:00","2017-01-08 00:00:00") ["2017-02-23 00:00:00","2017-02-26 00:00:00") (2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN ------------------------------------------------------------------------------------ Index Only Scan using reservations_during_idx on reservations Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange) (2 rows)
&&区间运算符表示交集; 因此,查询必须返回与给定间隔相交的所有间隔。 对于这种运算符,一致性函数确定给定的间隔是与内部行还是叶行中的值相交。
请注意,尽管为间隔定义了比较运算符,但这并不是以一定顺序获取间隔。 我们可以使用“ btree”索引作为间隔,但是在这种情况下,我们将不得不在不支持以下操作的情况下进行操作:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'range_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------------+-------------+-------------- @>(anyrange,anyelement) | s | 16 contains element <<(anyrange,anyrange) | s | 1 strictly left &<(anyrange,anyrange) | s | 2 not beyond right boundary &&(anyrange,anyrange) | s | 3 intersects &>(anyrange,anyrange) | s | 4 not beyond left boundary >>(anyrange,anyrange) | s | 5 strictly right -|-(anyrange,anyrange) | s | 6 adjacent @>(anyrange,anyrange) | s | 7 contains interval <@(anyrange,anyrange) | s | 8 contained in interval =(anyrange,anyrange) | s | 18 equals (10 rows)
(相等性除外,该相等性包含在“ btree”访问方法的运算符类中。)
内部构造
我们可以使用相同的“ gevel”扩展名浏览内部。 我们只需要记住要更改对gist_print的调用中的数据类型:
postgres=# select level, a from gist_print('reservations_during_idx') as t(level int, valid bool, a tsrange);
level | a -------+----------------------------------------------- 1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00") 1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00") 1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00") (3 rows)
排除约束
GiST索引可用于支持排除约束(EXCLUDE)。
排除约束确保在某些运算符方面,任何两个表行的给定字段都不会彼此“对应”。 如果选择“等于”运算符,我们将精确地获得唯一约束:任意两行的给定字段都不相等。
索引和唯一性约束均支持排除约束。 我们可以选择任何运算符,以便:
- 索引方法支持它的“ can_exclude”属性(例如,“ btree”,GiST或SP-GiST,但GIN不支持)。
- 它是可交换的,即满足条件:运算符b = b运算符a。
这是合适的策略和操作符示例的列表(我们记得,操作符可以具有不同的名称,并且不适用于所有数据类型):
- 对于“ btree”:
- 对于GiST和SP-GiST:
请注意,我们可以在排除约束中使用相等运算符,但这是不切实际的:唯一约束将更加有效。 这就是为什么我们在讨论B树时没有触及排除约束的原因。
让我们提供一个使用排除约束的示例。 不允许保留相交的间隔是合理的。
postgres=# alter table reservations add exclude using gist(during with &&);
创建排除约束后,我们可以添加行:
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
但是尝试在表中插入相交的间隔将导致错误:
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl" DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
“ Btree_gist”扩展
让问题复杂化。 我们扩展了不起眼的业务,并打算出租几栋小屋:
postgres=# alter table reservations add house_no integer default 1;
我们需要更改排除约束,以便考虑房屋号码。 但是,GiST不支持整数的相等运算:
postgres=# alter table reservations drop constraint reservations_during_excl; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist" HINT: You must specify an operator class for the index or define a default operator class for the data type.
在这种情况下,“
btree_gist ”扩展名将有所帮助,它增加了对B树固有的操作的GiST支持。 GiST最终可以支持任何运算符,那么为什么我们不应该教导它支持“更大”,“更少”和“相等”的运算符?
postgres=# create extension btree_gist; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
现在我们仍然无法在同一日期预订第一座小屋:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
但是,我们可以保留第二个:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
但是请注意,尽管GiST可以以某种方式支持“更大”,“更少”和“相等”运算符,但B树仍然可以做到这一点。 因此,仅在本质上需要GiST索引的情况下才值得使用此技术,例如在我们的示例中。
RD-tree用于全文搜索
关于全文搜索
让我们从对PostgreSQL全文搜索的极简介绍开始(如果您了解,可以跳过本节)。
全文搜索的任务是从
文档集中选择
与搜索查询
匹配的那些文档。 (如果有很多匹配的文档,找到
最佳匹配是很重要的,但是在这一点上我们什么也不会说。)
出于搜索目的,文档被转换为特殊类型“ tsvector”,其中包含
词素及其在文档中的位置。 词素是转换为适合搜索形式的单词。 例如,单词通常会转换为小写字母,并且变量的结尾会被截断:
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile');
to_tsvector ----------------------------------------- 'crook':4,10 'man':5 'mile':11 'walk':8 (1 row)
我们还可以看到,某些单词(称为
停用词 )被完全丢弃(“那里”,“是”,“一个”,“和”,“他”),因为它们可能出现得过于频繁,以至于使搜索变得没有意义。 当然可以配置所有这些转换,但这是另一回事了。
搜索查询用另一种类型表示:“ tsquery”。 大致上,查询由一个或几个连接词连接的词素组成:“和”,“或” |,“不”!..我们还可以使用括号来阐明操作优先级。
postgres=# select to_tsquery('man & (walking | running)');
to_tsquery ---------------------------- 'man' & ( 'walk' | 'run' ) (1 row)
全文搜索仅使用一个匹配运算符
@@ 。
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (walking | running)');
?column? ---------- t (1 row)
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (going | running)');
?column? ---------- f (1 row)
目前该信息已足够。 在下一篇介绍GIN索引的文章中,我们将对全文搜索进行更深入的研究。
RD树
为了进行快速的全文搜索,首先,该表需要存储“ tsvector”类型的列(以避免每次搜索时进行昂贵的转换),其次,必须在此列上建立索引。 GiST是一种可能的访问方法。
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# create index on ts using gist(doc_tsv); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc);
当然,将触发器委托给最后一步(将文档转换为“ tsvector”)很方便。
postgres=# select * from ts;
-[ RECORD 1 ]---------------------------------------------------- doc | Can a sheet slitter slit sheets? doc_tsv | 'sheet':3,6 'slit':5 'slitter':4 -[ RECORD 2 ]---------------------------------------------------- doc | How many sheets could a sheet slitter slit? doc_tsv | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 -[ RECORD 3 ]---------------------------------------------------- doc | I slit a sheet, a sheet I slit. doc_tsv | 'sheet':4,6 'slit':2,8 -[ RECORD 4 ]---------------------------------------------------- doc | Upon a slitted sheet I sit. doc_tsv | 'sheet':4 'sit':6 'slit':3 'upon':1 -[ RECORD 5 ]---------------------------------------------------- doc | Whoever slit the sheets is a good sheet slitter. doc_tsv | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 -[ RECORD 6 ]---------------------------------------------------- doc | I am a sheet slitter. doc_tsv | 'sheet':4 'slitter':5 -[ RECORD 7 ]---------------------------------------------------- doc | I slit sheets. doc_tsv | 'sheet':3 'slit':2 -[ RECORD 8 ]---------------------------------------------------- doc | I am the sleekest sheet slitter that ever slit sheets. doc_tsv | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 -[ RECORD 9 ]---------------------------------------------------- doc | She slits the sheet she sits on. doc_tsv | 'sheet':4 'sit':6 'slit':2
索引应如何组织? 不能直接使用R树,因为尚不清楚如何为文档定义“边界矩形”。 但是我们可以对这种方法进行一些修改,即所谓的RD树(RD代表“俄罗斯娃娃”)。 在这种情况下,集合被理解为词素集合,但是通常,集合可以是任何集合。
RD树的想法是用边界集(即包含子集的所有元素的集)替换边界矩形。
一个重要的问题提出了如何在索引行中表示集合。 最直接的方法就是枚举集合中的所有元素。 可能如下所示:

然后,例如,对于条件
doc_tsv @@ to_tsquery('sit')访问,我们只能下降到包含“ sit”
doc_tsv @@ to_tsquery('sit')那些节点:
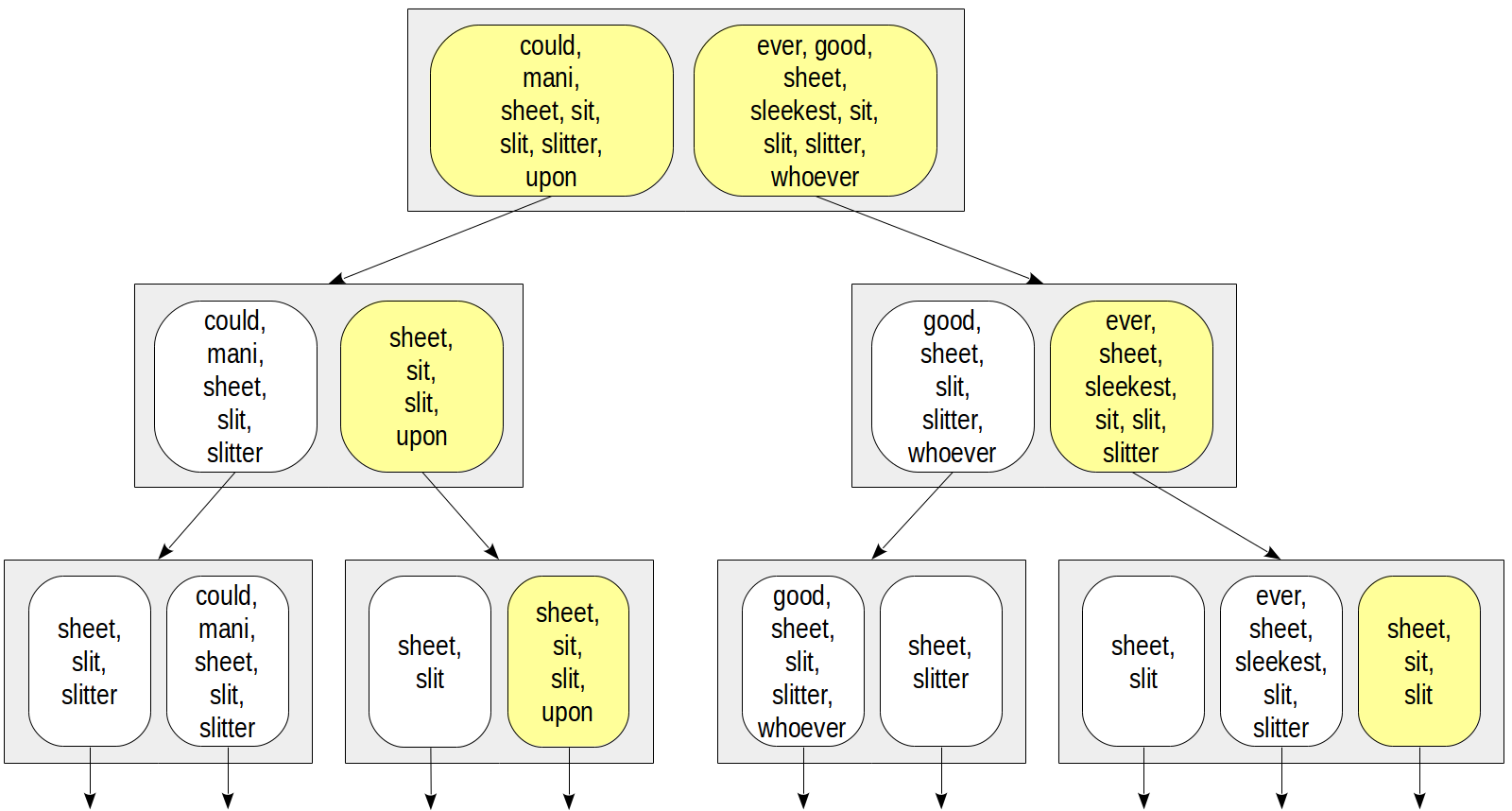
这种表示存在明显的问题。 文档中的词素数量可能非常大,因此索引行将具有较大的大小并进入TOAST,从而使索引的效率大大降低。 即使每个文档只有很少的词素,集合的并集仍然可能非常大:根目录越高,索引行就越大。
有时会使用这样的表示形式,但用于其他数据类型。 全文搜索使用另一个更紧凑的解决方案-所谓的
签名树 。 所有处理Bloom过滤器的人都非常熟悉它的想法。
每个词素都可以用其
签名表示:一定长度的位串,其中除一位以外的所有位均为零。 该位的位置由lexeme的哈希函数的值确定(我们之前已讨论过哈希函数的内部)。
文档签名是所有文档词素签名的按位或。
让我们假设以下词素签名:
可能1,000,000
曾经0001000
好0000010
玛尼0000100
工作表0000100
光滑0100000
坐0010000
狭缝0001000
分切器0000001
在0000010之后
谁0010000
然后,文档签名如下:
分页机可以分页吗? 0001101
分切机可以切几张纸? 1001101
我切了一张纸,我切了一张纸。 0001100
我坐在一张切开的床单上。 0011110
切开纸张的人都是很好的切纸机。 0011111
我是切纸机。 0000101
我切了床单。 0001100
我是有史以来最光滑的切纸机。 0101101
她劈开她坐在的床单。 0011100
索引树可以表示如下:
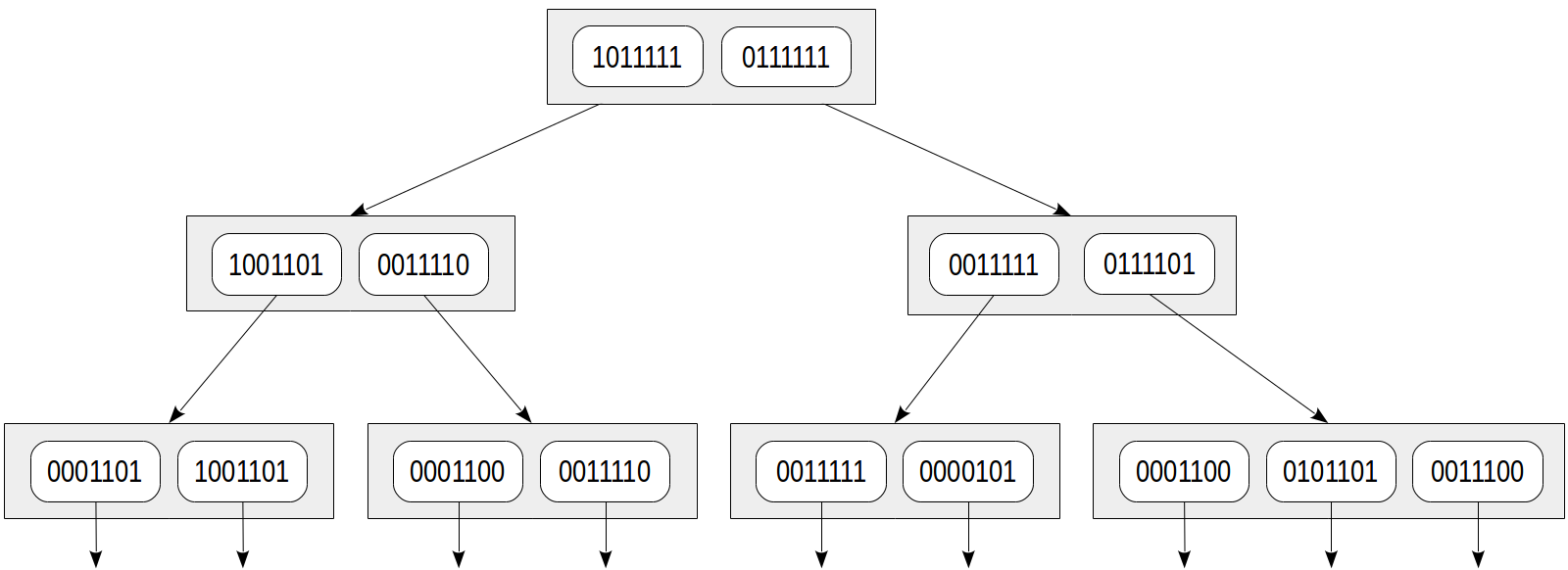
这种方法的优点显而易见:索引行的大小相等,并且这样的索引紧凑。 但缺点也很明显:准确性牺牲了紧凑性。
让我们考虑相同的条件
doc_tsv @@ to_tsquery('sit') 。 让我们以与文档相同的方式计算搜索查询的签名:在这种情况下为0010000。 一致性函数必须返回其签名至少包含查询签名一位的所有子节点:

与上图比较:我们可以看到树变成了黄色,这意味着出现误报,并且在搜索过程中经过了过多的节点。 在这里,我们拾取了“谁”词素,但不幸的是,其签名与“ sit”词素的签名相同。 重要的是,模式中不会出现误报,也就是说,我们确保不要错过所需的值。
此外,可能会发生这样的情况,即不同的文档也将获得相同的签名:在我们的示例中,不幸的文档是“我切了一张纸,我切了一张纸”和“我切了几张纸”(都具有0001100的签名)。 并且,如果叶索引行未存储“ tsvector”的值,则索引本身将给出假肯定。 当然,在这种情况下,该方法将要求索引引擎使用表重新检查结果,因此用户不会看到这些误报。 但是搜索效率可能会受到影响。
实际上,签名在当前实现中为124字节大,而不是图中的7位,因此与示例相比,上述问题发生的可能性要小得多。 但实际上,还有更多文档也被索引了。 为了以某种方式减少索引方法的误报次数,该实现有些棘手:被索引的“ tsvector”存储在叶索引行中,但前提是其大小不大(小于1/16。一页,对于8 KB的页面大约为半KB)。
例子
若要查看对实际数据进行索引的方式,让我们获取“ pgsql-hackers”电子邮件的存档。
该示例中
使用的版本包含356125条消息,其中包含发送日期,主题,作者和文本:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------ id | 1572389 parent_id | 1562808 sent | 1997-06-24 11:31:09 subject | Re: [HACKERS] Array bug is still there.... author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov> body_plain | Andrew Martin wrote: + | > Just run the regression tests on 6.1 and as I suspected the array bug + | > is still there. The regression test passes because the expected output+ | > has been fixed to the *wrong* output. + | + | OK, I think I understand the current array behavior, which is apparently+ | different than the behavior for v1.0x. + ...
添加并填充“ tsvector”类型的列并构建索引。 在这里,我们将三个值合并在一个向量中(主题,作者和消息文本),以表明文档不必是一个字段,而是可以包含完全不同的任意部分。
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
如我们所见,由于大小太大而丢弃了一定数量的单词。 但是该索引最终会创建,并且可以支持搜索查询:
fts=# explain (analyze, costs off) select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN ---------------------------------------------------------- Index Scan using mail_messages_tsv_idx on mail_messages (actual time=0.998..416.335 rows=898 loops=1) Index Cond: (tsv @@ to_tsquery('magic & value'::text)) Rows Removed by Index Recheck: 7859 Planning time: 0.203 ms Execution time: 416.492 ms (5 rows)
我们可以看到,与符合条件的898行一起,访问方法返回了7859多行,这些行通过重新检查表而被过滤掉。 这证明了准确性损失对效率的负面影响。
内部构造
为了分析索引的内容,我们将再次使用“ gevel”扩展名:
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a -------+------------------------------- 1 | 992 true bits, 0 false bits 2 | 988 true bits, 4 false bits 3 | 573 true bits, 419 false bits 4 | 65 unique words 4 | 107 unique words 4 | 64 unique words 4 | 42 unique words ...
存储在索引行中的特殊类型“ gtsvector”的值实际上是签名加上源“ tsvector”。 如果向量可用,则输出包含词素(唯一字)的数量,否则,包含签名中的真和假位的数量。
显然,在根节点中,签名退化为“全1”,即一个索引级别变得绝对无用(另外一个索引级别变得几乎无用,只有四个错误位)。
物产
让我们看一下GiST访问方法的属性(
先前提供了查询):
amname | name | pg_indexam_has_property --------+---------------+------------------------- gist | can_order | f gist | can_unique | f gist | can_multi_col | t gist | can_exclude | t
不支持值的排序和唯一约束。 如我们所见,索引可以建立在几列上,并用于排除约束中。
以下索引层属性可用:
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | f
最有趣的属性是列层的属性。 一些属性独立于运算符类:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f search_array | f search_nulls | t
(不支持排序;索引不能用于搜索数组;支持NULL。)
但是剩下的两个属性“ distance_orderable”和“ returnable”将取决于所使用的运算符类。 例如,对于积分,我们将得到:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | t returnable | t
第一个属性表明距离运算符可用于搜索最近的邻居。 第二个告诉索引可以用于仅索引扫描。 尽管叶索引行存储矩形而不是点,但是访问方法可以返回所需的内容。
以下是间隔的属性:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | t
对于间隔,没有定义距离函数,因此无法搜索最近的邻居。
对于全文搜索,我们得到:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | f
仅索引扫描的支持已丢失,因为叶行只能包含签名,而不能包含数据本身。 但是,这是一个很小的损失,因为无论如何都不会有人对“ tsvector”类型的值感兴趣:该值用于选择行,而它是需要显示的源文本,但无论如何都不会从索引中丢失。
其他数据类型
最后,除了已经讨论过的几何类型(以点为例),间隔和全文本搜索类型之外,我们还将提及GiST访问方法当前支持的其他几种类型。
在标准类型中,这是IP地址的“
inet ”类型。 所有其余的都通过扩展添加:
- cube为多维多维数据集提供“多维数据集”数据类型。 对于这种类型,就像在平面中的几何类型一样,定义了GiST运算符类:R树,支持搜索最近的邻居。
- seg为间隔指定间隔的“ seg”数据类型提供了一定的精度,并为此数据类型(R树)添加了GiST索引支持。
- intarray扩展了整数数组的功能,并增加了对它们的GiST支持。 实现了两个运算符类:“ gist__int_ops”(带有索引行中键的完整表示的RD树)和“ gist__bigint_ops”(签名RD树)。 第一类可用于小型阵列,第二类可用于较大尺寸。
- ltree为树状结构添加了“ ltree”数据类型,并为此数据类型(RD-tree)提供了GiST支持。
- pg_trgm添加了一个专门的运算符类“ gist_trgm_ops”,以便在全文搜索中使用三字组。 但这将与GIN索引一起进一步讨论。
继续阅读 。