 ProxylessNAS直接针对特定任务和设备优化神经网络的体系结构,与以前的代理方法相比,可以显着提高生产率。 在ImageNet数据集上,神经网络的设计时间为200个GPU小时(是其同类产品的200到378倍),并且针对移动设备自动设计的CNN模型达到了与MobileNetV2 1.4相同的准确度,工作速度提高了1.8倍。
ProxylessNAS直接针对特定任务和设备优化神经网络的体系结构,与以前的代理方法相比,可以显着提高生产率。 在ImageNet数据集上,神经网络的设计时间为200个GPU小时(是其同类产品的200到378倍),并且针对移动设备自动设计的CNN模型达到了与MobileNetV2 1.4相同的准确度,工作速度提高了1.8倍。麻省理工学院的消息说,麻省理工学院的研究人员开发了一种有效的算法,可以针对特定的硬件自动设计高性能神经网络。
机器学习系统的自动设计算法是AI领域的一个新研究领域。 这种技术称为神经体系结构搜索(NAS),被认为是一项艰巨的计算任务。
自动设计的神经网络比人类开发的神经网络具有更准确,更有效的设计。 但是寻找神经体系结构需要大量的计算。 例如,由Google最近开发的可在GPU上运行的现代NASNet-F算法需要48,000小时的GPU计算来创建一个卷积神经网络,用于对图像进行分类和检测。 当然,Google可以并行运行数百个GPU和其他专用硬件。 例如,在一千个GPU上,此计算仅需两天。 但是,并非所有研究人员都拥有这样的机会,如果您在Google计算云中运行该算法,那么它可能会花很多钱。
麻省理工学院的研究人员为
将于2019年 5月6日至9日举行的国际学习代表大会
ICLR 2019准备了一篇文章。
ProxylessNAS:目标任务和硬件上的直接神经体系结构搜索文章介绍了ProxylessNAS算法,该算法可以直接为特定的硬件平台开发专用的卷积神经网络。
当在大量图像数据上运行时,该算法仅需200小时的GPU操作即可设计出最佳架构。 这比使用其他算法的CNN架构的开发快两个数量级(请参见表)。
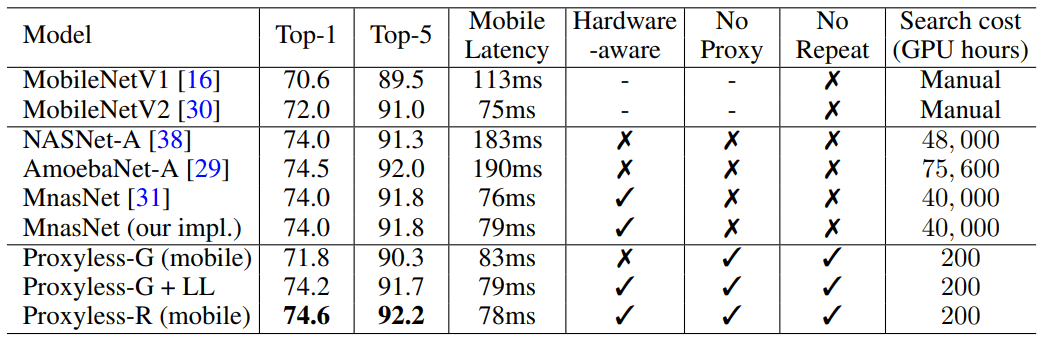
资源有限的研究人员和公司将从该算法中受益。 麻省理工学院微系统技术实验室的电子工程和计算机科学助理教授,歌曲作者宋涵说,更普遍的目标是“使人工智能民主化”。
Khan补充说,这样的NAS算法永远不会取代工程师的智力工作:“目标是减轻设计和改进神经网络体系结构带来的重复而繁琐的工作。”
在他们的工作中,研究人员找到了删除神经网络不必要部分,减少计算时间并仅使用部分硬件内存来运行NAS算法的方法。 这样可以确保开发的CNN在特定的硬件平台(CPU,GPU和移动设备)上更有效地工作。
CNN体系结构由具有可调整参数的图层(称为“过滤器”)及其之间可能的关系组成。 滤镜处理正方形像素(例如3×3、5×5或7×7)中的图像像素,其中每个滤镜覆盖一个正方形。 实际上,滤镜会在图像周围移动并将像素网格的颜色合并为一个像素。 在不同的层中,过滤器的大小不同,它们以不同的方式连接以交换数据。 CNN输出产生一个由所有滤镜组合而成的压缩图像。 由于可能的架构数量(所谓的“搜索空间”)非常大,因此使用NAS在大量图像数据集上创建神经网络需要大量资源。 通常,开发人员在较小的数据集(代理)上运行NAS,然后将生成的CNN架构传输到目标。 但是,此方法降低了模型的准确性。 此外,相同的体系结构适用于所有硬件平台,从而导致性能问题。
麻省理工学院的研究人员针对直接在ImageNet数据集中对图像进行分类的任务训练并测试了该新算法,该网络包含一千个类别的数百万个图像。 首先,他们创建了一个搜索空间,其中包含CNN候选对象的所有可能“路径”,以便该算法在其中找到最佳架构。 为了使搜索空间适合GPU的内存,他们使用了一种称为路径级二值化的方法,该方法一次仅保存一条路径,并且将内存节省一个数量级。 二值化与路径级修剪相结合,该方法传统上研究了可以安全地删除神经网络中的哪些神经元而不会损害系统的方法。 NAS算法仅去除神经元,而没有去除整个路径,从而彻底改变了体系结构。
最后,该算法将切断所有不太可能的路径,并仅以最高概率保存路径-这是最终的CNN架构。
该图显示了ProxylessNAS为GPU,CPU和移动处理器(分别从上到下)开发的用于分类图像的神经网络样本。
