Yandex提供了一个搜索组件开发服务,该服务可以在MapReduce上构建搜索基础,提供用于排版的数据,生成算法和数据结构,并解决质量增长的ML任务。 该服务其中一个小组的负责人Alexey Shlyunkin解释了搜索运行时的组成以及我们如何对其进行管理。
想要在ML中戳-戳戳。 您只需要MapReduce-好的。 想要运行时-运行时。
-今天的搜索是什么? Yandex首先进行搜索,然后进行开发。 20年过去了。 我们有数千亿个文档的搜索库。
我们将文档称为Internet上的任何页面,但实际上不仅如此。 仍然-它的内容,关于哪些用户喜欢它的统计数据,其中有多少用户。 加上我们计算出的数据。
它们也是数以万计的实例,它们响应每个请求来处理数据,搜索某些内容并丰富搜索响应。 有些实例正在寻找图片,有些实例正在寻找普通的文本文档,有些实例正在寻找视频,等等。也就是说,为您的每个请求激活了成千上万的机器。 他们都试图找到一些东西,并改善显示给您的结果。 因此,成千上万的机器每秒处理数千个请求。 数以万计的实例被组合到旨在解决问题的数百个服务中。

有一个搜索核心-网络搜索服务。 并且,存在视频搜索服务等。因此,存在一种将不同搜索的答案结合起来并试图选择以何种顺序显示的更好的方式。 如果这是对音乐的某种要求,则最好先显示Yandex.Music,然后再显示有关此音乐组的页面,可能会更好。 这称为搅拌机。 这样的服务已经有成百上千种,它们还会为每个请求做一些事情,并尝试以某种方式帮助用户。 而且,当然,所有这些都使用了各种机器学习,从一些简单的统计数据,线性模型到梯度提升,神经网络等。
我现在将谈论基础架构和ML。
我的组称为新的运行时开发组,它是搜索组件开发服务的一部分。 为了让您有个主意,我将简单介绍一下我们服务的作用。

其实对每个人来说。 如果您提交搜索,那么从建立搜索基础开始,我们几乎可以接触到所有内容。 也就是说,我们拥有MapReduce,我们在那里收集有关文档的所有数据,将其煮沸,构建各种数据结构,以便在查询它们时可以高效地进行计算。 因此,当文档刚到达我们时,我们从底部开始工作;从这些文档得到某些东西并对其进行排名时,我们从头开始工作;直到布局接收条件JSON并用所有图片和漂亮的东西绘制它为止,我们一直在最顶层工作。 从下到上,我们正在整个堆栈上进行开发。
但是我们不仅在编写代码,因此,我们也在基础架构中完成所有这些工作。 实际上,我们正在训练神经网络,CatBoost。 我们还教您可以想象和燃烧的其他ML内容。 另外,由于我们有大量的负载和大数据,因此,我们当然会遍历算法和数据结构,而从不束手无策。 例如,在几个地方,我们使用段树。 我们对构建硼的索引进行了自己的压缩,并据此考虑了如何最佳构建字典的动态。
总的来说,在处理如此庞大的搜索任务时,我们就被如此简单的任务所饱和。 因此,我们当然喜欢复杂,新颖的事物,这些事物挑战着我们。 而且我们不仅像往常一样去编写十行代码。 我们需要考虑一些实验。 通常,我们自己设定的任务通常处于虚构的边缘。 有时您会认为:这可能是不可能的。 但是,然后,您也许以某种方式进行了实验-实验可能需要花费整整一年的时间-但最终会有所结果。 然后我们开始介绍,重做一些东西。
除了任何项目,技能等等,总体而言,我们是Yandex中最具雄心和发展最快的团队之一。 例如,我两年前来,是我们服务的第九个人。 现在我们有将近60个人的服务。 实际上,这是实习生的情况,但总体而言,我们在两年内成长了四倍。 这是为了让您了解我们的服务正在做什么。
现在,我想告诉您一些有关我们任务的顶部以及在我看来在不久的将来我们将变得越来越重要的方向。 但是为此,您必须首先简要描述最基本的搜索层是如何工作的。
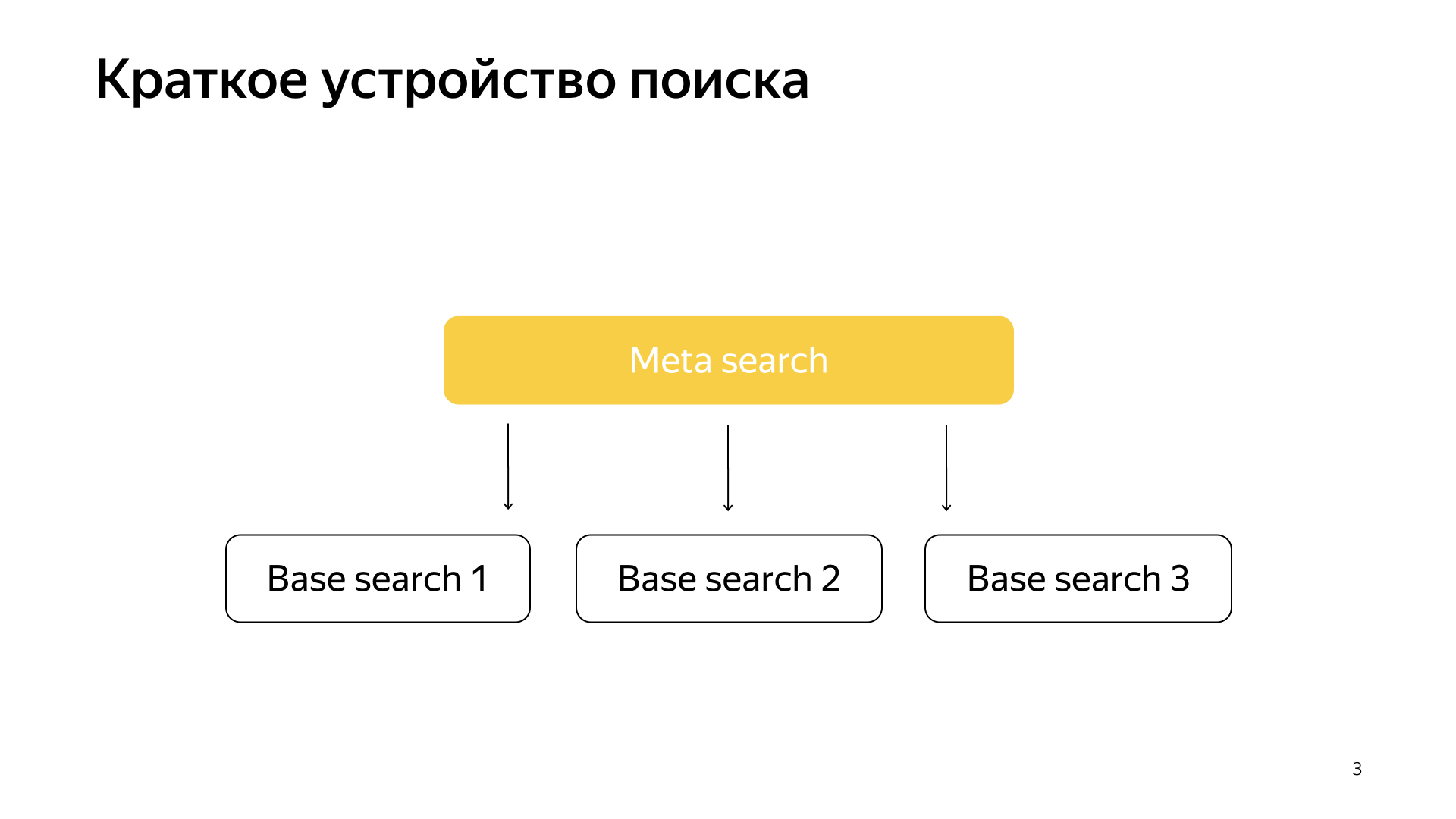
一般来说,一切都非常简单。 我们有我们的搜索基础,我们有所有文件,我们将所有这些文件或多或少地平均分为N个部分。 它们称为碎片。 在该分片上启动了一个名为“基本搜索”的程序。 因此,她的任务是在互联网上进行搜索。 也就是说,她知道如何搜索,对其他Internet一无所知。 我们有N个这样的碎片。 在其上方启动基本搜索,因此,在此基础上进行了元搜索。 用户的请求落入该请求中,因此,它仅访问所有分片,每个分片执行搜索,然后每个分片返回结果,并执行某种合并并给出答案。
这样的搜索几乎是整整20年的时间安排,而且一般来说,很长一段时间以来,他们一直认为这样做会保持下去,没有更好的办法。 但是,一切都在变化,新技术不断涌现,并且机器学习现在不仅可以提高质量,还可以解决某种基础设施问题。 最近,在我们的搜索中,很多项目都在基础设施和机器学习的交界处进行了拍摄。 当两个这样的桅杆合并时,将获得非常有趣的结果。

最近,神经网络已经出现。 我们有请求的文本,有文档的文本。 我们想从请求中获取一些数字向量,从文档中获取一些数字向量,以便标量积预测我们想要的值。 例如,我们要训练标量积,以预测用户单击此文档的可能性。 完全可以理解的事情。
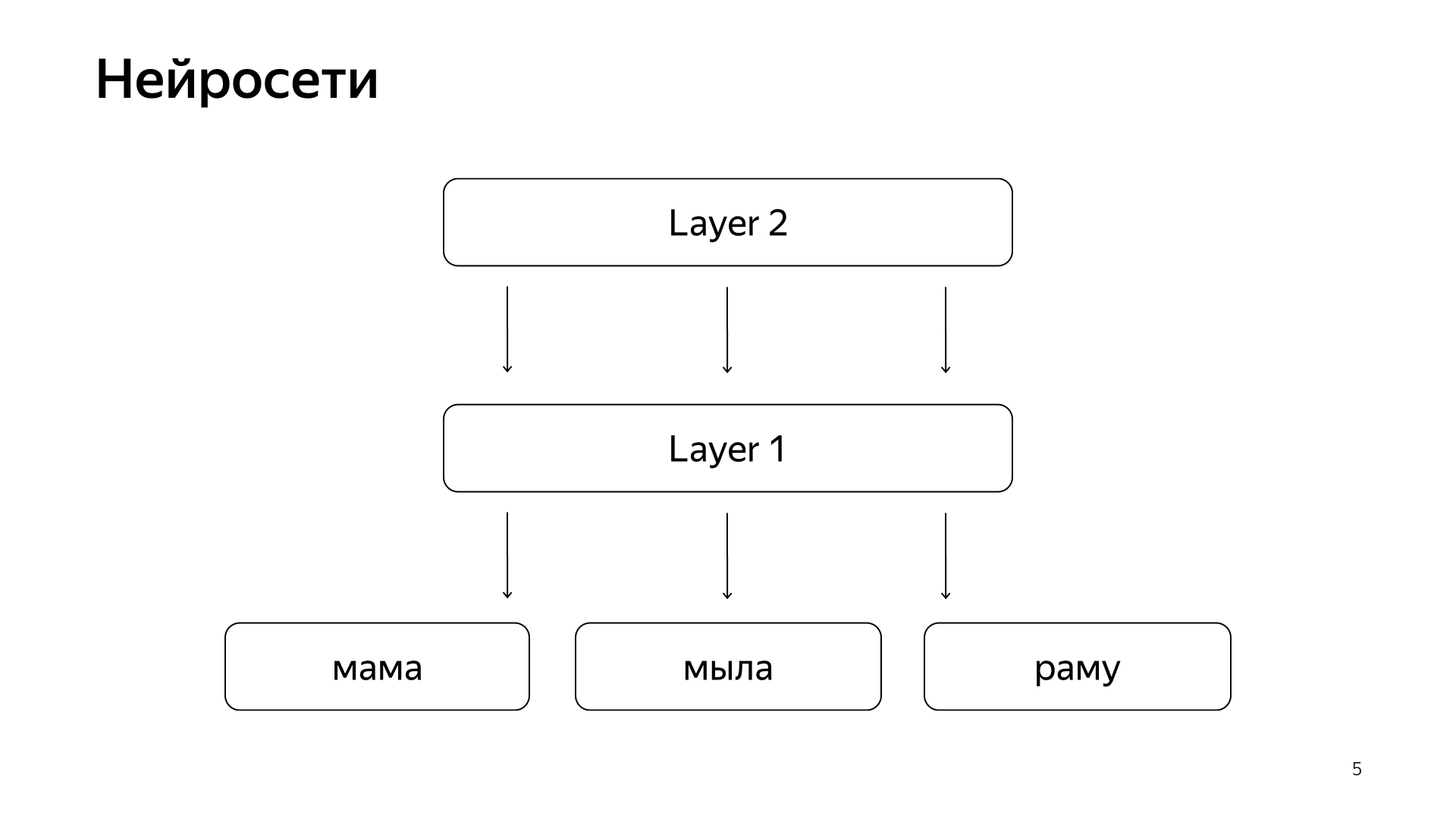
这样安排。 如果非常非常粗鲁,那么我们在底层有一些话,然后是网络的几层。 实际上,每一层都将向量作为其输入。 也就是说,底层是这样的稀疏向量,其中每个单词都是一个请求。 将其乘以一个矩阵,得到某种矢量,然后相应地对每个分量应用一些非线性,然后执行几次。 最后一层,这就是我们刚刚接受请求的向量,应用了这些层,在这里,最后一层就是请求向量。
因此,近年来,这些神经网络已被积极地引入搜索中,它们为质量带来了很多好处。 但是它们有一个问题,就是我们要预测的所有值都是好的,但足够粗糙,因为为了训练这样的神经网络,底层非常大-所有单词都来自千万个单词,因此您需要能够编写她输入了数十亿个数据。
例如,我们可以训练一些用户点击,等等。 但是,在我们的搜索中被认为最重要的主要信号是特殊人员的手动标记。 他们接受请求,阅读文档,阅读文档,了解其效果并打上标记,即该文档符合该要求的程度。 长期以来,我们无法通过神经网络预测如此巨大的幅度,因为我们仍有数百万个估算值,因为雇用整个星球不断对其进行标记非常昂贵。 因此,我们做了一些修改。
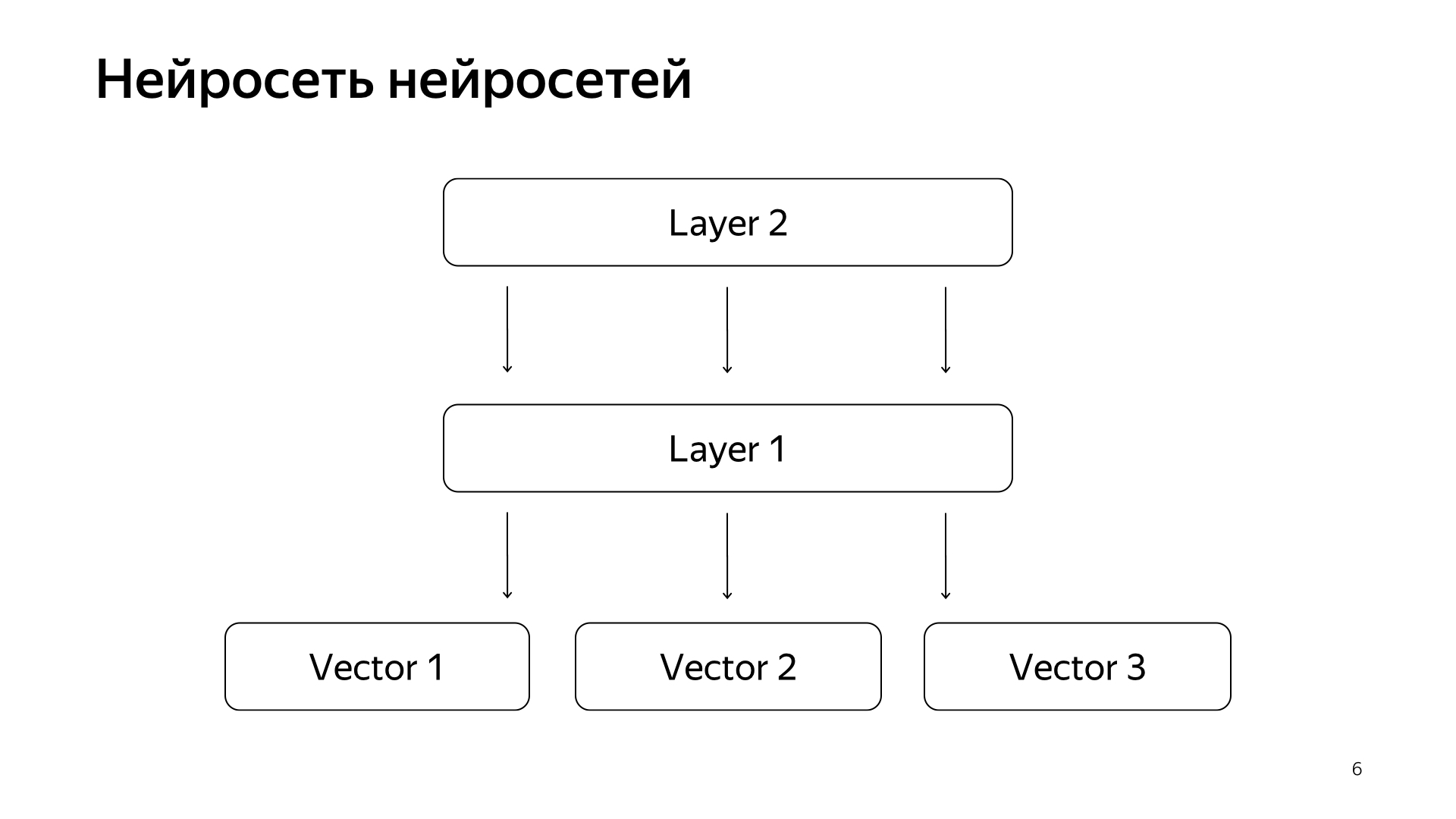
神经网络的神经网络。 在过去的几年中,我们已经积累了很多神经网络,它们可以预测良好的信号,但是比对特殊人群的评估要粗糙一些。 因此,我们决定将这些网络的现成向量提交给下层,然后训练神经网络以预测我们在较小数据网络上的搜索相关性。
结果是一个很好的模型。 她将文档的请求带入向量,它们的标量积直接预测了我们长期以来一直希望预测的真实相关性。
此外,我们有了一个想法,如何稍微重做搜索。 该项目称为KNN基础(英语k-最近邻居,k-最近邻居方法)。

基本思想是这样。 我们有一个查询向量和一个文档向量。 我们需要找到最近的一个。 我们用矢量表示每个文档。 让我们突出显示N个群集,它们代表了整个文档空间。 粗略地讲。 远小于文档的数量,但是例如,它们描述主题的特征。 简而言之,这里有猫群,杂货群,编程群等等。
因此,我们不会像以前那样将文档随机分散在分片中,而是将文档放入该分片中,即其质心最接近文档。 因此,我们将按主题将此类文档按碎片分类。
而且,仅针对一个请求,现在我们不能访问所有分片,而只能访问最接近此请求的那些子集。
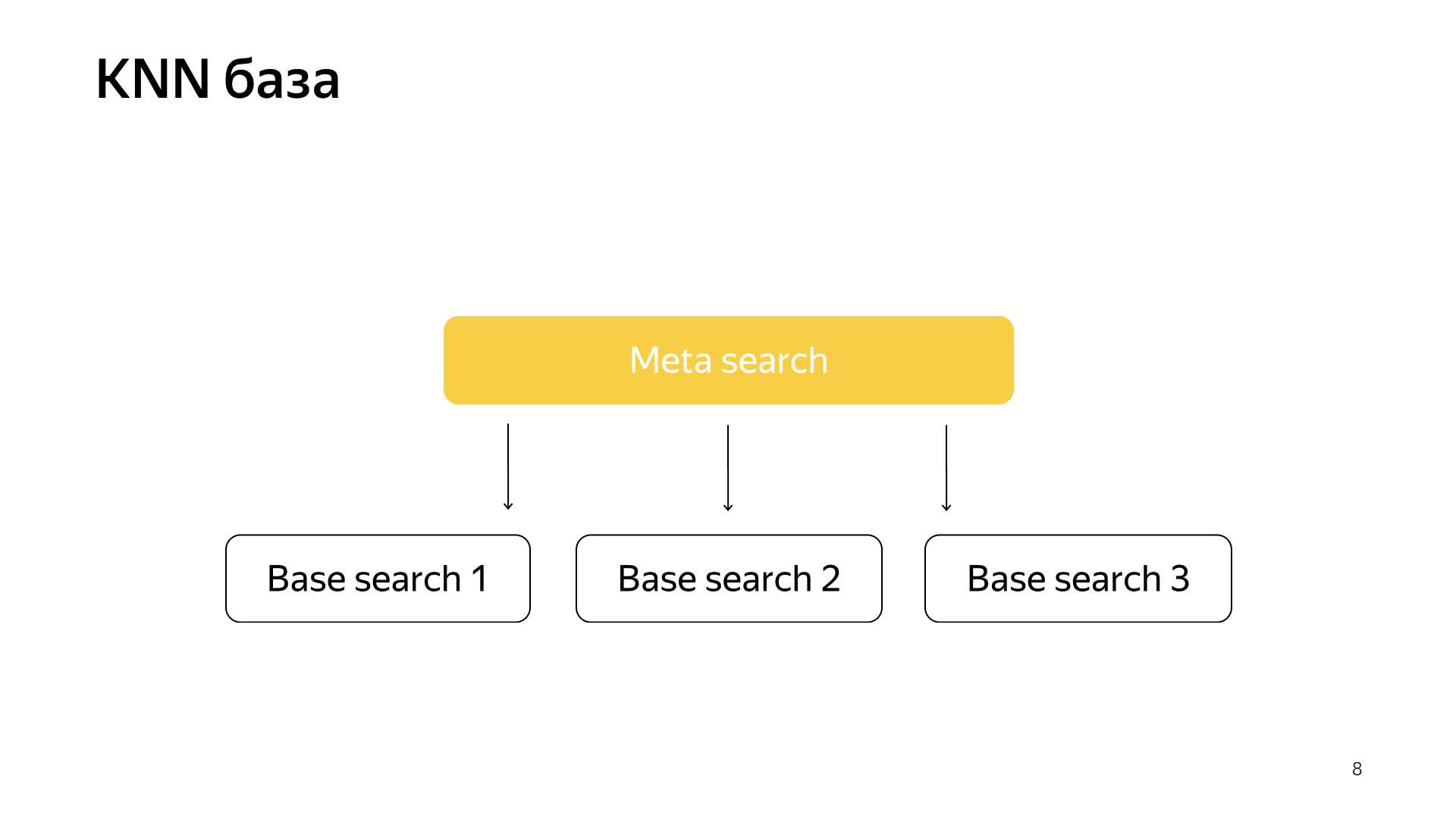
因此,我们有这样一个方案,元搜索包括在所有分片中。 现在,他需要的数量要少得多,与此同时,我们仍将寻找最近的文档。
我们实际上从这种设计中得到什么? 仅仅因为我们去了更少的集群,它就大大减少了计算资源的消耗。 正如我已经说过的那样,我认为这是我们服务的亮点之一,这是基础设施和机器学习的融合,其结果是前所未有的。

最后,这只是一件很有趣的事情,因为您在这里得到了模型,然后又去了,重新进行了整个搜索,关闭了PB的数据,搜索工作量消耗的资源减少了十倍。 您为公司节省了10亿美元,每个人都很高兴。

我谈到了出现在我们搜索中的一个项目,该项目正在与已暂停一年的所有实验一起实施和完成。 我们的其他典型任务是使搜索基础增加一倍,因为Internet一直在增长,我们希望赶上它并在Internet的所有页面上进行搜索。 当然,这是基础层的加速度,在这种情况下,大多数情况下是大多数铁。 例如,将基本搜索速度提高百分之一意味着节省约一百万美元。
我们还作为启动孵化器从事搜索。 我会解释。 搜索已经进行了20年。 它已经做了很多事情,很多时候我们遇到了一个死胡同,认为什么也做不了。 然后进行了一系列的实验。 我们再次突破了这一死胡同。 在这段时间里,我们在如何做大而酷的事情上积累了很多专业知识。 相应地,现在Yandex中的大多数新方向都是在搜索中完成的,因为搜索人员已经知道如何进行所有操作,因此要求他们至少设计一些新系统是合乎逻辑的。 并且最大程度地-自己动手做。
现在,我希望您对我们的工作有所了解。 我将快速讲讲我的故事中有关实习生服务的主题部分。 我们非常爱他们。 我们有很多人,去年夏天仅在我的团队中有20名学员,我认为这很好。 当您雇用一到三个实习生时,他们会感到有些孤独,有时他们害怕问问年长的同志。 而且当他们很多时,他们以不幸的同志彼此交流。 如果他们害怕问开发人员一些事情,他们会走了,他们会在角落里抱怨。 这样的气氛有助于有效地完成所有工作。
我们有一百万个任务,团队不是很大,所以我们的实习生已满负荷工作。 我们并没有要求学员总是坐在日志上,编写测试,重构代码,而是立即给出一些复杂的生产任务:加快搜索速度,改善索引压缩。 当然可以。 我们知道这一切都有回报,因此我们很高兴分享我们的专业知识。 由于我们的活动领域非常广泛,因此我们每个人都会根据自己的喜好找到一项任务。 想要在ML中戳-戳戳。 您只需要MapReduce-好的。 想要运行时-运行时。 有什么
您需要什么才能联系我们? 我们主要使用C ++和Python来完成所有工作。 不必两者都知道,一个人可以知道一件事。 我们欢迎了解算法。 它形成了一定的思维方式,对您有很大帮助。 但这也不是必须的:同样,我们已经准备好教所有东西,准备投资我们的时间,因为我们知道它会有所回报。 我们的座右铭是,我们最重要的要求是不要害怕任何事情和很多数字。 不要害怕降低产量,不要害怕开始做复杂的事情。 因此,我们需要不惧怕任何事物并且也准备转身的人。 非常感谢