大数据的任何操作都需要大量的计算能力。 从数据库到Hadoop的典型数据转移可能要花费数周的时间,也可能要花费飞机机翼的费用。 不想等待和挥霍? 平衡不同平台上的负载。 一种方法是下推式优化。
我请俄罗斯领先的Informatica产品开发和管理培训师Alexei Ananyev谈谈Informatica大数据管理(BDM)中的下推优化功能。 是否学会过使用Informatica产品? Alex最有可能向您介绍了PowerCenter的基本知识,并解释了如何构建映射。
DIS集团培训主管Alexey Ananiev
什么是下推式?
你们中的许多人已经熟悉Informatica大数据管理(BDM)。 该产品可以集成来自不同来源的大数据,在不同系统之间移动大数据,提供对它们的轻松访问,允许您对其进行概要分析等等。
用熟练的手,BDM可以创造奇迹:任务将以最少的计算资源快速完成。
你也要吗 了解如何使用BDM中的下推功能在各个平台之间分配计算负载。 下推技术使您可以将映射转换为脚本并选择运行该脚本的环境。 这种选择的可能性使您可以组合不同平台的优势并实现其最大性能。
要配置脚本运行时,请选择下推类型。 该脚本可以完全在Hadoop上运行,也可以部分分布在源和接收者之间。 有4种可能的下推类型。 映射不能转换为脚本(本机)。 映射可以在源(源)上尽可能多地执行,也可以在源(完整)上完全执行。 映射也可以转换为Hadoop(无)脚本。
下推式优化
列出的4种类型可以以不同的方式组合-针对系统的特定需求优化下推。 例如,通常更建议使用数据库自身的功能从数据库中提取数据。 并通过Hadoop转换数据,以使数据库本身不会过载。
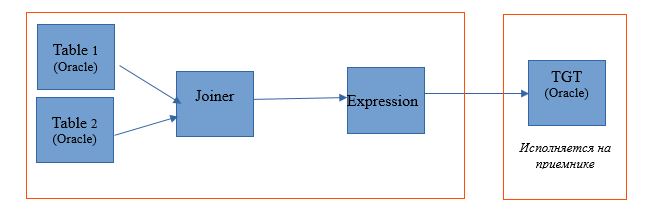
让我们看一下源和接收者都在数据库中并且可以选择转换执行平台的情况:根据设置,它将是Informatica,数据库服务器或Hadoop。 这样的例子将使得最准确地理解该机制的技术方面成为可能。 自然,在现实生活中不会出现这种情况,但是最适合于演示其功能。
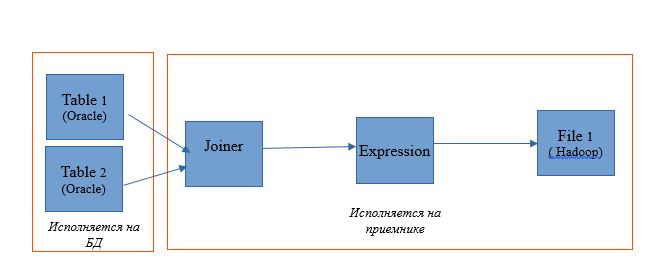
进行映射以读取单个Oracle数据库中的两个表。 并将读取结果写入同一数据库中的表中。 映射方案如下:

以Informatica BDM 10.2.1上的映射形式,它看起来像这样:
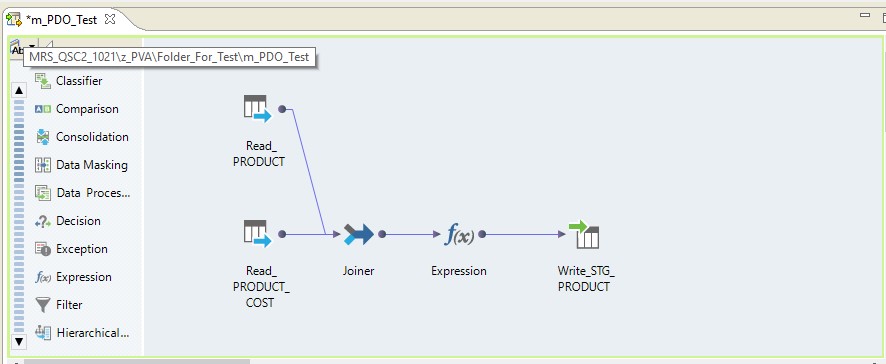
类型下推-本机
如果选择下推本机类型,则映射将在Informatica服务器上执行。 将从Oracle服务器读取数据,将其传输到Informatica服务器,在那里进行转换并传输到Hadoop。 换句话说,我们得到了常规的ETL过程。
类型下推-源
选择类型源时,我们将有机会在数据库服务器(DB)和Hadoop之间分配我们的流程。 使用此设置执行流程时,从表中选择数据的请求将转到数据库。 其余的将以Hadoop上的步骤的形式完成。
执行方案将如下所示:
以下是设置运行时的示例。
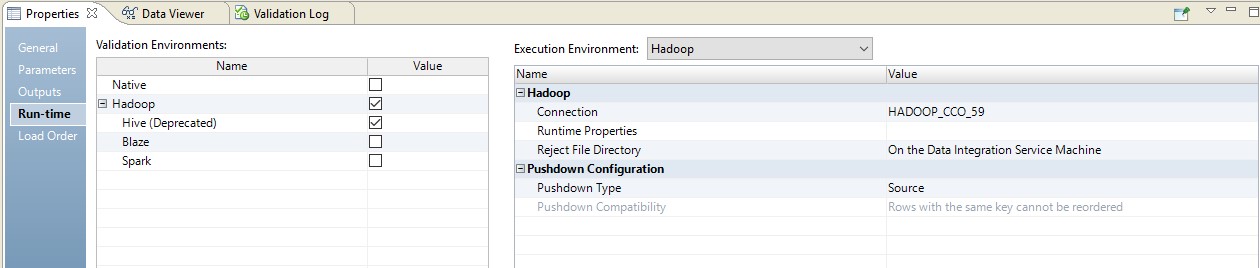
在这种情况下,映射将分两个步骤执行。 在他的设置中,我们将看到他变成了将发送到源代码的脚本。 此外,表和数据转换的组合将在源头以覆盖查询的形式执行。
在下图中,我们看到了BDM和源上的优化映射-被覆盖的请求。
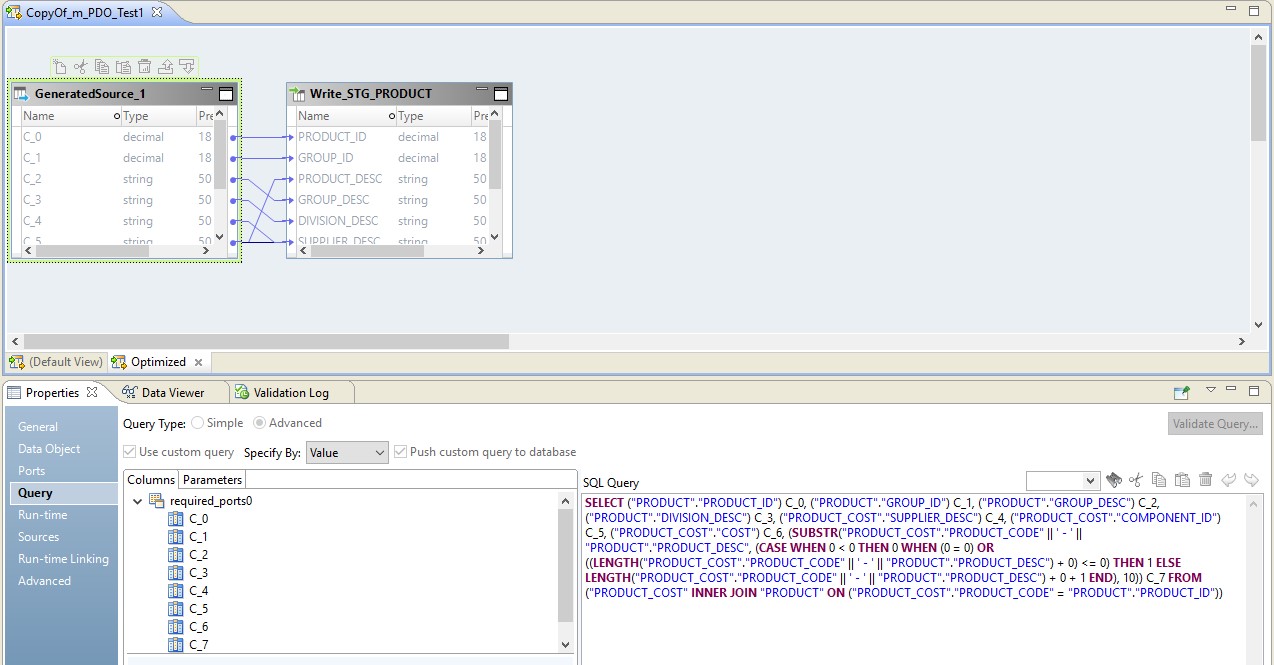
Hadoop在此配置中的作用归结于管理数据流-进行数据流管理。 请求的结果将发送到Hadoop。 读取后,来自Hadoop的文件将被写入接收器。
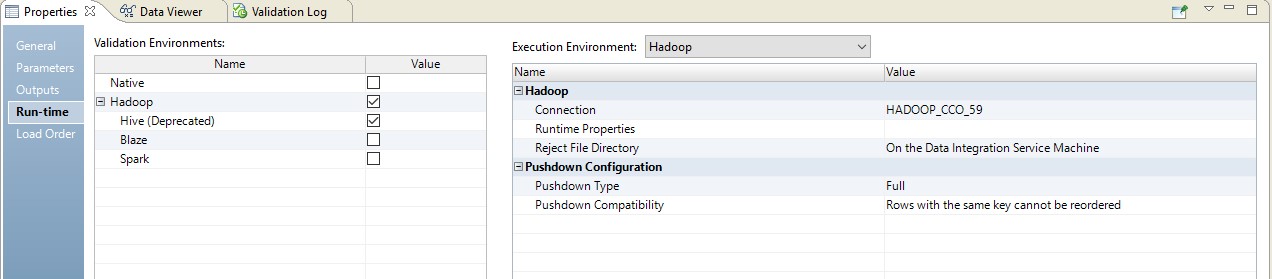
类型下推-完整
选择完整类型时,映射将完全转变为数据库请求。 并将查询结果定向到Hadoop。 这种过程的示意图如下所示。
设置示例如下所示。
结果,我们得到了与上一个相似的优化映射。 唯一的区别是,所有逻辑都以覆盖其插入的形式传输到接收器。 优化映射的示例如下所示。
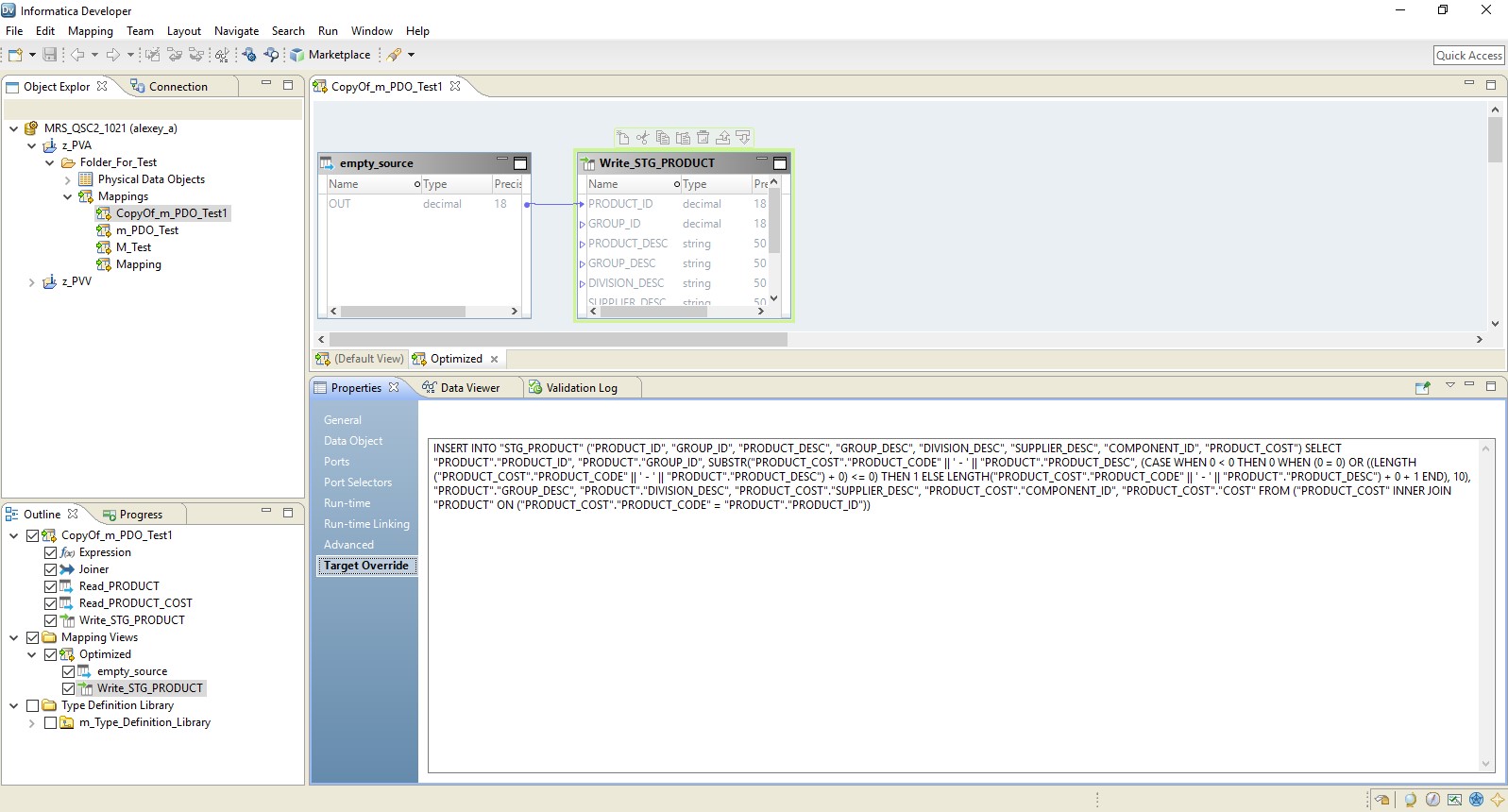
在这里,与前面的情况一样,Hadoop充当了指挥者。 但是这里完整地读取了源,然后在接收器级别执行了数据处理逻辑。
输入下推式-空
好吧,最后一个选项是下推类型,在其中我们的映射将变成Hadoop脚本。
现在,优化的映射将如下所示:
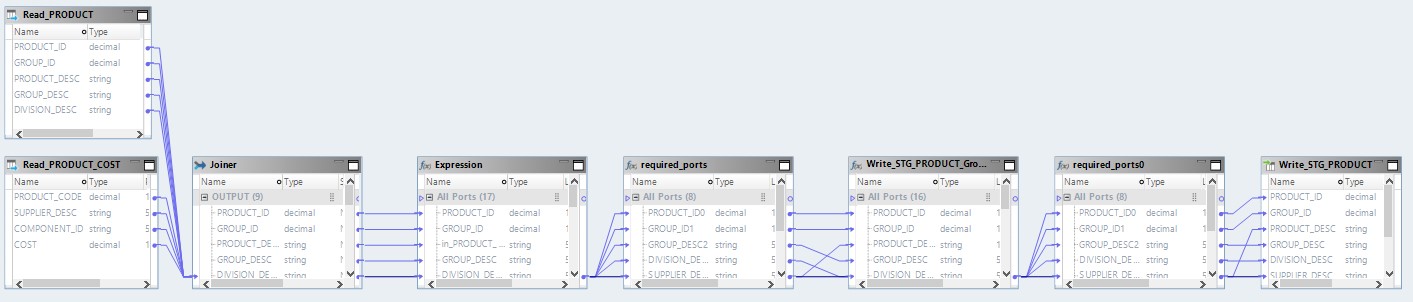
在这里,来自源文件的数据将首先在Hadoop上读取。 然后,以他自己的方式,将这两个文件合并。 之后,数据将被转换并上传到数据库。
了解下推优化的原理,您可以非常有效地组织许多处理大数据的流程。 因此,就在最近,一家大型公司在短短几周内就将大数据从存储设备上传到了Hadoop,而该公司已经收集了好几年。